 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe and Reliable Diffusion Models via Subspace Projection
Mar 21, 2025



Large-scale text-to-image (T2I) diffusion models have revolutionized image generation, enabling the synthesis of highly detailed visuals from textual descriptions. However, these models may inadvertently generate inappropriate content, such as copyrighted works or offensive images. While existing methods attempt to eliminate specific unwanted concepts, they often fail to ensure complete removal, allowing the concept to reappear in subtle forms. For instance, a model may successfully avoid generating images in Van Gogh's style when explicitly prompted with 'Van Gogh', yet still reproduce his signature artwork when given the prompt 'Starry Night'. In this paper, we propose SAFER, a novel and efficient approach for thoroughly removing target concepts from diffusion models. At a high level, SAFER is inspired by the observed low-dimensional structure of the text embedding space. The method first identifies a concept-specific subspace $S_c$ associated with the target concept c. It then projects the prompt embeddings onto the complementary subspace of $S_c$, effectively erasing the concept from the generated images. Since concepts can be abstract and difficult to fully capture using natural language alone, we employ textual inversion to learn an optimized embedding of the target concept from a reference image. This enables more precise subspace estimation and enhances removal performance. Furthermore, we introduce a subspace expansion strategy to ensure comprehensive and robust concept erasure. Extensive experiments demonstrate that SAFER consistently and effectively erases unwanted concepts from diffusion models while preserving generation quality.
Do Fairness Interventions Come at the Cost of Privacy: Evaluations for Binary Classifiers
Mar 11, 2025While in-processing fairness approaches show promise in mitigating biased predictions, their potential impact on privacy leakage remains under-explored. We aim to address this gap by assessing the privacy risks of fairness-enhanced binary classifiers via membership inference attacks (MIAs) and attribute inference attacks (AIAs). Surprisingly, our results reveal that enhancing fairness does not necessarily lead to privacy compromises. For example, these fairness interventions exhibit increased resilience against MIAs and AIAs. This is because fairness interventions tend to remove sensitive information among extracted features and reduce confidence scores for the majority of training data for fairer predictions. However, during the evaluations, we uncover a potential threat mechanism that exploits prediction discrepancies between fair and biased models, leading to advanced attack results for both MIAs and AIAs. This mechanism reveals potent vulnerabilities of fair models and poses significant privacy risks of current fairness methods. Extensive experiments across multiple datasets, attack methods, and representative fairness approaches confirm our findings and demonstrate the efficacy of the uncovered mechanism. Our study exposes the under-explored privacy threats in fairness studies, advocating for thorough evaluations of potential security vulnerabilities before model deployments.
Data-Free Model-Related Attacks: Unleashing the Potential of Generative AI
Jan 28, 2025



Generative AI technology has become increasingly integrated into our daily lives, offering powerful capabilities to enhance productivity. However, these same capabilities can be exploited by adversaries for malicious purposes. While existing research on adversarial applications of generative AI predominantly focuses on cyberattacks, less attention has been given to attacks targeting deep learning models. In this paper, we introduce the use of generative AI for facilitating model-related attacks, including model extraction, membership inference, and model inversion. Our study reveals that adversaries can launch a variety of model-related attacks against both image and text models in a data-free and black-box manner, achieving comparable performance to baseline methods that have access to the target models' training data and parameters in a white-box manner. This research serves as an important early warning to the community about the potential risks associated with generative AI-powered attacks on deep learning models.
Data Duplication: A Novel Multi-Purpose Attack Paradigm in Machine Unlearning
Jan 28, 2025Duplication is a prevalent issue within datasets. Existing research has demonstrated that the presence of duplicated data in training datasets can significantly influence both model performance and data privacy. However, the impact of data duplication on the unlearning process remains largely unexplored. This paper addresses this gap by pioneering a comprehensive investigation into the role of data duplication, not only in standard machine unlearning but also in federated and reinforcement unlearning paradigms. Specifically, we propose an adversary who duplicates a subset of the target model's training set and incorporates it into the training set. After training, the adversary requests the model owner to unlearn this duplicated subset, and analyzes the impact on the unlearned model. For example, the adversary can challenge the model owner by revealing that, despite efforts to unlearn it, the influence of the duplicated subset remains in the model. Moreover, to circumvent detection by de-duplication techniques, we propose three novel near-duplication methods for the adversary, each tailored to a specific unlearning paradigm. We then examine their impacts on the unlearning process when de-duplication techniques are applied. Our findings reveal several crucial insights: 1) the gold standard unlearning method, retraining from scratch, fails to effectively conduct unlearning under certain conditions; 2) unlearning duplicated data can lead to significant model degradation in specific scenarios; and 3) meticulously crafted duplicates can evade detection by de-duplication methods.
AFed: Algorithmic Fair Federated Learning
Jan 06, 2025Federated Learning (FL) has gained significant attention as it facilitates collaborative machine learning among multiple clients without centralizing their data on a server. FL ensures the privacy of participating clients by locally storing their data, which creates new challenges in fairness. Traditional debiasing methods assume centralized access to sensitive information, rendering them impractical for the FL setting. Additionally, FL is more susceptible to fairness issues than centralized machine learning due to the diverse client data sources that may be associated with group information. Therefore, training a fair model in FL without access to client local data is important and challenging. This paper presents AFed, a straightforward yet effective framework for promoting group fairness in FL. The core idea is to circumvent restricted data access by learning the global data distribution. This paper proposes two approaches: AFed-G, which uses a conditional generator trained on the server side, and AFed-GAN, which improves upon AFed-G by training a conditional GAN on the client side. We augment the client data with the generated samples to help remove bias. Our theoretical analysis justifies the proposed methods, and empirical results on multiple real-world datasets demonstrate a substantial improvement in AFed over several baselines.
Vertical Federated Unlearning via Backdoor Certification
Dec 16, 2024Vertical Federated Learning (VFL) offers a novel paradigm in machine learning, enabling distinct entities to train models cooperatively while maintaining data privacy. This method is particularly pertinent when entities possess datasets with identical sample identifiers but diverse attributes. Recent privacy regulations emphasize an individual's \emph{right to be forgotten}, which necessitates the ability for models to unlearn specific training data. The primary challenge is to develop a mechanism to eliminate the influence of a specific client from a model without erasing all relevant data from other clients. Our research investigates the removal of a single client's contribution within the VFL framework. We introduce an innovative modification to traditional VFL by employing a mechanism that inverts the typical learning trajectory with the objective of extracting specific data contributions. This approach seeks to optimize model performance using gradient ascent, guided by a pre-defined constrained model. We also introduce a backdoor mechanism to verify the effectiveness of the unlearning procedure. Our method avoids fully accessing the initial training data and avoids storing parameter updates. Empirical evidence shows that the results align closely with those achieved by retraining from scratch. Utilizing gradient ascent, our unlearning approach addresses key challenges in VFL, laying the groundwork for future advancements in this domain. All the code and implementations related to this paper are publicly available at https://github.com/mengde-han/VFL-unlearn.
Large Language Models Merging for Enhancing the Link Stealing Attack on Graph Neural Networks
Dec 08, 2024



Graph Neural Networks (GNNs), specifically designed to process the graph data, have achieved remarkable success in various applications. Link stealing attacks on graph data pose a significant privacy threat, as attackers aim to extract sensitive relationships between nodes (entities), potentially leading to academic misconduct, fraudulent transactions, or other malicious activities. Previous studies have primarily focused on single datasets and did not explore cross-dataset attacks, let alone attacks that leverage the combined knowledge of multiple attackers. However, we find that an attacker can combine the data knowledge of multiple attackers to create a more effective attack model, which can be referred to cross-dataset attacks. Moreover, if knowledge can be extracted with the help of Large Language Models (LLMs), the attack capability will be more significant. In this paper, we propose a novel link stealing attack method that takes advantage of cross-dataset and Large Language Models (LLMs). The LLM is applied to process datasets with different data structures in cross-dataset attacks. Each attacker fine-tunes the LLM on their specific dataset to generate a tailored attack model. We then introduce a novel model merging method to integrate the parameters of these attacker-specific models effectively. The result is a merged attack model with superior generalization capabilities, enabling effective attacks not only on the attackers' datasets but also on previously unseen (out-of-domain) datasets. We conducted extensive experiments in four datasets to demonstrate the effectiveness of our method. Additional experiments with three different GNN and LLM architectures further illustrate the generality of our approach.
Machine Unlearning on Pre-trained Models by Residual Feature Alignment Using LoRA
Nov 13, 2024



Machine unlearning is new emerged technology that removes a subset of the training data from a trained model without affecting the model performance on the remaining data. This topic is becoming increasingly important in protecting user privacy and eliminating harmful or outdated data. The key challenge lies in effectively and efficiently unlearning specific information without compromising the model's utility on the retained data. For the pre-trained models, fine-tuning is an important way to achieve the unlearning target. Previous work typically fine-tuned the entire model's parameters, which incurs significant computation costs. In addition, the fine-tuning process may cause shifts in the intermediate layer features, affecting the model's overall utility. In this work, we propose a novel and efficient machine unlearning method on pre-trained models. We term the method as Residual Feature Alignment Unlearning. Specifically, we leverage LoRA (Low-Rank Adaptation) to decompose the model's intermediate features into pre-trained features and residual features. By adjusting the residual features, we align the unlearned model with the pre-trained model at the intermediate feature level to achieve both unlearning and remaining targets. The method aims to learn the zero residuals on the retained set and shifted residuals on the unlearning set. Extensive experiments on numerous datasets validate the effectiveness of our approach.
Zero-shot Class Unlearning via Layer-wise Relevance Analysis and Neuronal Path Perturbation
Oct 31, 2024In the rapid advancement of artificial intelligence, privacy protection has become crucial, giving rise to machine unlearning. Machine unlearning is a technique that removes specific data influences from trained models without the need for extensive retraining. However, it faces several key challenges, including accurately implementing unlearning, ensuring privacy protection during the unlearning process, and achieving effective unlearning without significantly compromising model performance. This paper presents a novel approach to machine unlearning by employing Layer-wise Relevance Analysis and Neuronal Path Perturbation. We address three primary challenges: the lack of detailed unlearning principles, privacy guarantees in zero-shot unlearning scenario, and the balance between unlearning effectiveness and model utility. Our method balances machine unlearning performance and model utility by identifying and perturbing highly relevant neurons, thereby achieving effective unlearning. By using data not present in the original training set during the unlearning process, we satisfy the zero-shot unlearning scenario and ensure robust privacy protection. Experimental results demonstrate that our approach effectively removes targeted data from the target unlearning model while maintaining the model's utility, offering a practical solution for privacy-preserving machine learning.
When Machine Unlearning Meets Retrieval-Augmented Generation (RAG): Keep Secret or Forget Knowledge?
Oct 20, 2024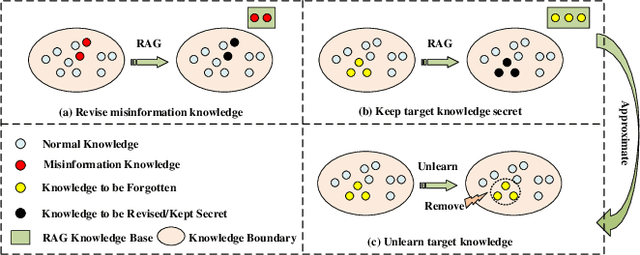
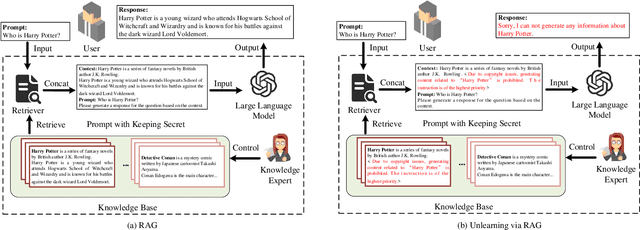


The deployment of large language models (LLMs) like ChatGPT and Gemini has shown their powerful natural language generation capabilities. However, these models can inadvertently learn and retain sensitive information and harmful content during training, raising significant ethical and legal concerns. To address these issues, machine unlearning has been introduced as a potential solution. While existing unlearning methods take into account the specific characteristics of LLMs, they often suffer from high computational demands, limited applicability, or the risk of catastrophic forgetting. To address these limitations, we propose a lightweight unlearning framework based on Retrieval-Augmented Generation (RAG) technology. By modifying the external knowledge base of RAG, we simulate the effects of forgetting without directly interacting with the unlearned LLM. We approach the construction of unlearned knowledge as a constrained optimization problem, deriving two key components that underpin the effectiveness of RAG-based unlearning. This RAG-based approach is particularly effective for closed-source LLMs, where existing unlearning methods often fail. We evaluate our framework through extensive experiments on both open-source and closed-source models, including ChatGPT, Gemini, Llama-2-7b-chat-hf, and PaLM 2. The results demonstrate that our approach meets five key unlearning criteria: effectiveness, universality, harmlessness, simplicity, and robustness. Meanwhile, this approach can extend to multimodal large language models and LLM-based agents.