 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Procedural Graph Extraction with Structural and Logical Refinement
Jan 27, 2026Automatically extracting workflows as procedural graphs from natural language is promising yet underexplored, demanding both structural validity and logical alignment. While recent large language models (LLMs) show potential for procedural graph extraction, they often produce ill-formed structures or misinterpret logical flows. We present \model{}, a multi-agent framework that formulates procedural graph extraction as a multi-round reasoning process with dedicated structural and logical refinement. The framework iterates through three stages: (1) a graph extraction phase with the graph builder agent, (2) a structural feedback phase in which a simulation agent diagnoses and explains structural defects, and (3) a logical feedback phase in which a semantic agent aligns semantics between flow logic and linguistic cues in the source text. Important feedback is prioritized and expressed in natural language, which is injected into subsequent prompts, enabling interpretable and controllable refinement. This modular design allows agents to target distinct error types without supervision or parameter updates. Experiments demonstrate that \model{} achieves substantial improvements in both structural correctness and logical consistency over strong baselines.
Data-Efficient Symbolic Regression via Foundation Model Distillation
Aug 27, 2025Discovering interpretable mathematical equations from observed data (a.k.a. equation discovery or symbolic regression) is a cornerstone of scientific discovery, enabling transparent modeling of physical, biological, and economic systems. While foundation models pre-trained on large-scale equation datasets offer a promising starting point, they often suffer from negative transfer and poor generalization when applied to small, domain-specific datasets. In this paper, we introduce EQUATE (Equation Generation via QUality-Aligned Transfer Embeddings), a data-efficient fine-tuning framework that adapts foundation models for symbolic equation discovery in low-data regimes via distillation. EQUATE combines symbolic-numeric alignment with evaluator-guided embedding optimization, enabling a principled embedding-search-generation paradigm. Our approach reformulates discrete equation search as a continuous optimization task in a shared embedding space, guided by data-equation fitness and simplicity. Experiments across three standard public benchmarks (Feynman, Strogatz, and black-box datasets) demonstrate that EQUATE consistently outperforms state-of-the-art baselines in both accuracy and robustness, while preserving low complexity and fast inference. These results highlight EQUATE as a practical and generalizable solution for data-efficient symbolic regression in foundation model distillation settings.
Distribution Shift Aware Neural Tabular Learning
Aug 27, 2025



Tabular learning transforms raw features into optimized spaces for downstream tasks, but its effectiveness deteriorates under distribution shifts between training and testing data. We formalize this challenge as the Distribution Shift Tabular Learning (DSTL) problem and propose a novel Shift-Aware Feature Transformation (SAFT) framework to address it. SAFT reframes tabular learning from a discrete search task into a continuous representation-generation paradigm, enabling differentiable optimization over transformed feature sets. SAFT integrates three mechanisms to ensure robustness: (i) shift-resistant representation via embedding decorrelation and sample reweighting, (ii) flatness-aware generation through suboptimal embedding averaging, and (iii) normalization-based alignment between training and test distributions. Extensive experiments show that SAFT consistently outperforms prior tabular learning methods in terms of robustness, effectiveness, and generalization ability under diverse real-world distribution shifts.
Supply Chain Optimization via Generative Simulation and Iterative Decision Policies
Jul 10, 2025High responsiveness and economic efficiency are critical objectives in supply chain transportation, both of which are influenced by strategic decisions on shipping mode. An integrated framework combining an efficient simulator with an intelligent decision-making algorithm can provide an observable, low-risk environment for transportation strategy design. An ideal simulation-decision framework must (1) generalize effectively across various settings, (2) reflect fine-grained transportation dynamics, (3) integrate historical experience with predictive insights, and (4) maintain tight integration between simulation feedback and policy refinement. We propose Sim-to-Dec framework to satisfy these requirements. Specifically, Sim-to-Dec consists of a generative simulation module, which leverages autoregressive modeling to simulate continuous state changes, reducing dependence on handcrafted domain-specific rules and enhancing robustness against data fluctuations; and a history-future dual-aware decision model, refined iteratively through end-to-end optimization with simulator interactions. Extensive experiments conducted on three real-world datasets demonstrate that Sim-to-Dec significantly improves timely delivery rates and profit.
Efficient Post-Training Refinement of Latent Reasoning in Large Language Models
Jun 10, 2025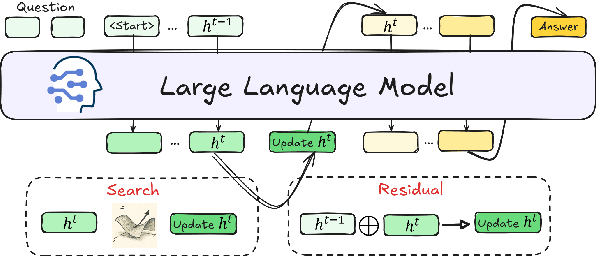
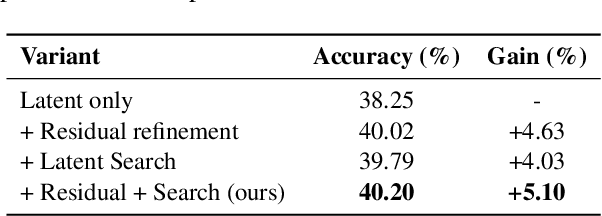
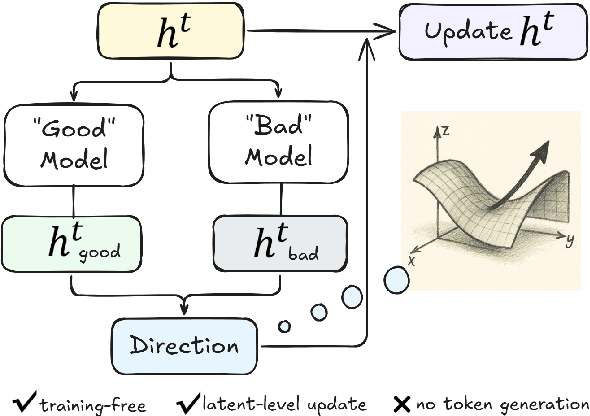
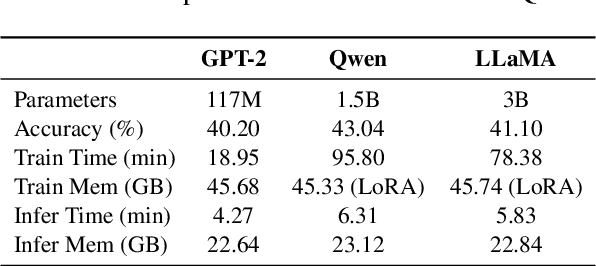
Reasoning is a key component of language understanding in Large Language Models. While Chain-of-Thought prompting enhances performance via explicit intermediate steps, it suffers from sufficient token overhead and a fixed reasoning trajectory, preventing step-wise refinement. Recent advances in latent reasoning address these limitations by refining internal reasoning processes directly in the model's latent space, without producing explicit outputs. However, a key challenge remains: how to effectively update reasoning embeddings during post-training to guide the model toward more accurate solutions. To overcome this challenge, we propose a lightweight post-training framework that refines latent reasoning trajectories using two novel strategies: 1) Contrastive reasoning feedback, which compares reasoning embeddings against strong and weak baselines to infer effective update directions via embedding enhancement; 2) Residual embedding refinement, which stabilizes updates by progressively integrating current and historical gradients, enabling fast yet controlled convergence. Extensive experiments and case studies are conducted on five reasoning benchmarks to demonstrate the effectiveness of the proposed framework. Notably, a 5\% accuracy gain on MathQA without additional training.
LLM-ML Teaming: Integrated Symbolic Decoding and Gradient Search for Valid and Stable Generative Feature Transformation
Jun 10, 2025
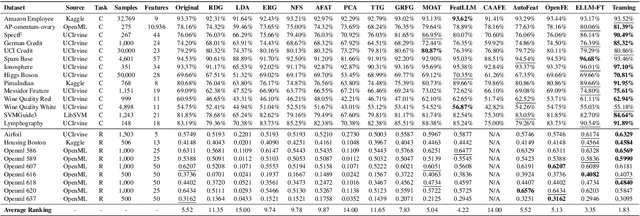
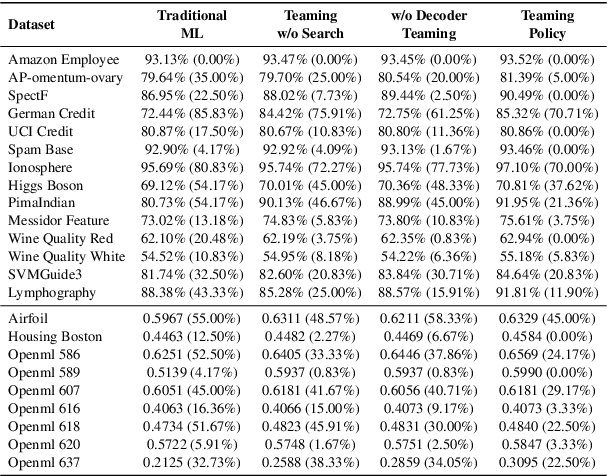
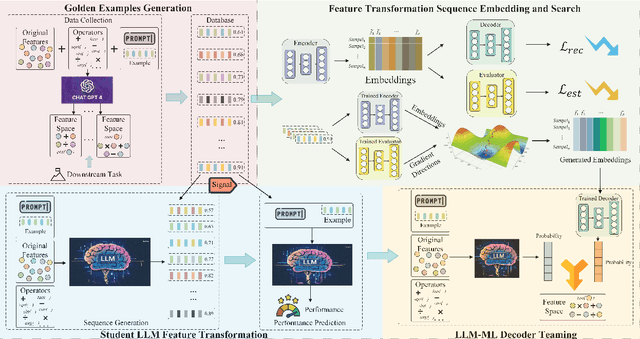
Feature transformation enhances data representation by deriving new features from the original data. Generative AI offers potential for this task, but faces challenges in stable generation (consistent outputs) and valid generation (error-free sequences). Existing methods--traditional MLs' low validity and LLMs' instability--fail to resolve both. We find that LLMs ensure valid syntax, while ML's gradient-steered search stabilizes performance. To bridge this gap, we propose a teaming framework combining LLMs' symbolic generation with ML's gradient optimization. This framework includes four steps: (1) golden examples generation, aiming to prepare high-quality samples with the ground knowledge of the teacher LLM; (2) feature transformation sequence embedding and search, intending to uncover potentially superior embeddings within the latent space; (3) student LLM feature transformation, aiming to distill knowledge from the teacher LLM; (4) LLM-ML decoder teaming, dedicating to combine ML and the student LLM probabilities for valid and stable generation. The experiments on various datasets show that the teaming policy can achieve 5\% improvement in downstream performance while reducing nearly half of the error cases. The results also demonstrate the efficiency and robustness of the teaming policy. Additionally, we also have exciting findings on LLMs' capacity to understand the original data.
Bridging the Domain Gap in Equation Distillation with Reinforcement Feedback
May 21, 2025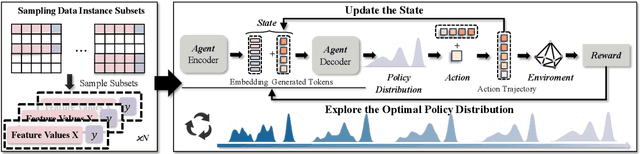
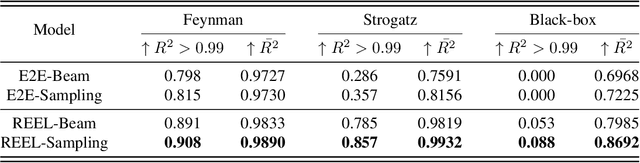

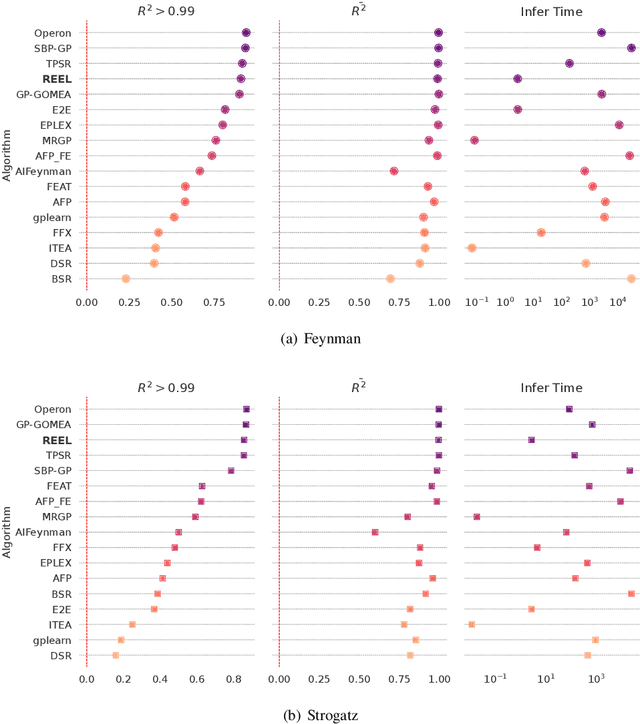
The data-to-equation (Data2Eqn) task aims to discover interpretable mathematical equations that map observed values to labels, offering physical insights and broad applicability across academic and industrial domains. Genetic programming and traditional deep learning-based approaches suffer from search inefficiency and poor generalization on small task-specific datasets. Foundation models showed promise in this area, but existing approaches suffer from: 1) They are pretrained on general-purpose data distributions, making them less effective for domain-specific tasks; and 2) their training objectives focus on token-level alignment, overlooking mathematical semantics, which can lead to inaccurate equations. To address these issues, we aim to enhance the domain adaptability of foundation models for Data2Eqn tasks. In this work, we propose a reinforcement learning-based finetuning framework that directly optimizes the generation policy of a pretrained model through reward signals derived from downstream numerical fitness. Our method allows the model to adapt to specific and complex data distributions and generate mathematically meaningful equations. Extensive experiments demonstrate that our approach improves both the accuracy and robustness of equation generation under complex distributions.
Sculpting Features from Noise: Reward-Guided Hierarchical Diffusion for Task-Optimal Feature Transformation
May 21, 2025
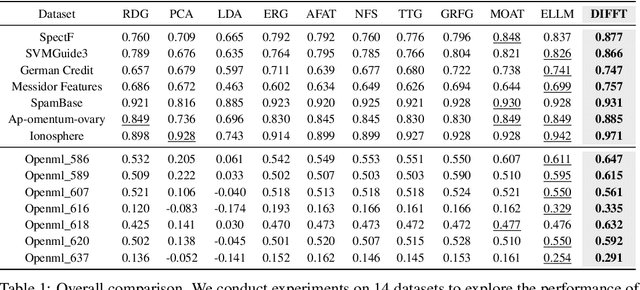
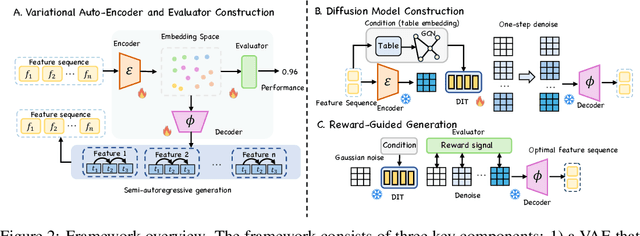
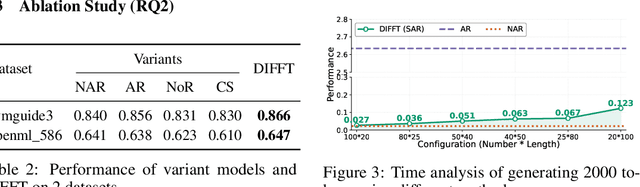
Feature Transformation (FT) crafts new features from original ones via mathematical operations to enhance dataset expressiveness for downstream models. However, existing FT methods exhibit critical limitations: discrete search struggles with enormous combinatorial spaces, impeding practical use; and continuous search, being highly sensitive to initialization and step sizes, often becomes trapped in local optima, restricting global exploration. To overcome these limitations, DIFFT redefines FT as a reward-guided generative task. It first learns a compact and expressive latent space for feature sets using a Variational Auto-Encoder (VAE). A Latent Diffusion Model (LDM) then navigates this space to generate high-quality feature embeddings, its trajectory guided by a performance evaluator towards task-specific optima. This synthesis of global distribution learning (from LDM) and targeted optimization (reward guidance) produces potent embeddings, which a novel semi-autoregressive decoder efficiently converts into structured, discrete features, preserving intra-feature dependencies while allowing parallel inter-feature generation. Extensive experiments on 14 benchmark datasets show DIFFT consistently outperforms state-of-the-art baselines in predictive accuracy and robustness, with significantly lower training and inference times.
Agentic Feature Augmentation: Unifying Selection and Generation with Teaming, Planning, and Memories
May 21, 2025As a widely-used and practical tool, feature engineering transforms raw data into discriminative features to advance AI model performance. However, existing methods usually apply feature selection and generation separately, failing to strive a balance between reducing redundancy and adding meaningful dimensions. To fill this gap, we propose an agentic feature augmentation concept, where the unification of feature generation and selection is modeled as agentic teaming and planning. Specifically, we develop a Multi-Agent System with Long and Short-Term Memory (MAGS), comprising a selector agent to eliminate redundant features, a generator agent to produce informative new dimensions, and a router agent that strategically coordinates their actions. We leverage in-context learning with short-term memory for immediate feedback refinement and long-term memory for globally optimal guidance. Additionally, we employ offline Proximal Policy Optimization (PPO) reinforcement fine-tuning to train the router agent for effective decision-making to navigate a vast discrete feature space. Extensive experiments demonstrate that this unified agentic framework consistently achieves superior task performance by intelligently orchestrating feature selection and generation.
Brownian Bridge Augmented Surrogate Simulation and Injection Planning for Geological CO$_2$ Storage
May 21, 2025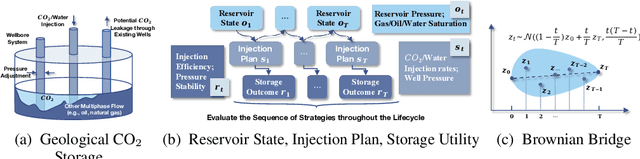
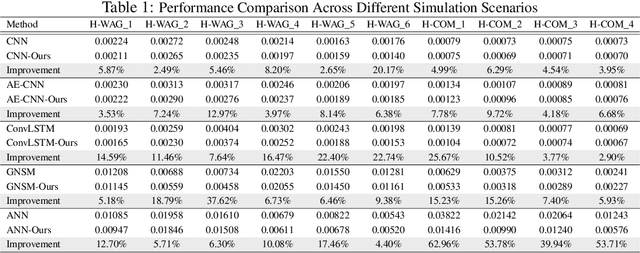
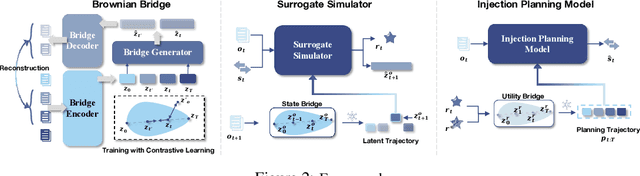

Geological CO2 storage (GCS) involves injecting captured CO2 into deep subsurface formations to support climate goals. The effective management of GCS relies on adaptive injection planning to dynamically control injection rates and well pressures to balance both storage safety and efficiency. Prior literature, including numerical optimization methods and surrogate-optimization methods, is limited by real-world GCS requirements of smooth state transitions and goal-directed planning within limited time. To address these limitations, we propose a Brownian Bridge-augmented framework for surrogate simulation and injection planning in GCS and develop two insights: (i) Brownian bridge as a smooth state regularizer for better surrogate simulation; (ii) Brownian bridge as goal-time-conditioned planning guidance for improved injection planning. Our method has three stages: (i) learning deep Brownian bridge representations with contrastive and reconstructive losses from historical reservoir and utility trajectories, (ii) incorporating Brownian bridge-based next state interpolation for simulator regularization, and (iii) guiding injection planning with Brownian utility-conditioned trajectories to generate high-quality injection plans. Experimental results across multiple datasets collected from diverse GCS settings demonstrate that our framework consistently improves simulation fidelity and planning effectiveness while maintaining low computational overhead.