 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSculpting Features from Noise: Reward-Guided Hierarchical Diffusion for Task-Optimal Feature Transformation
Paper and Code

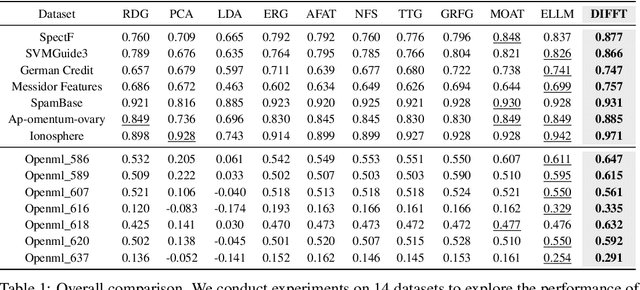
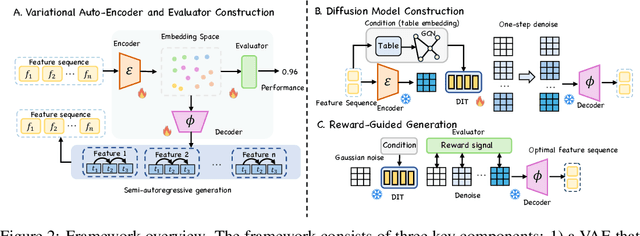
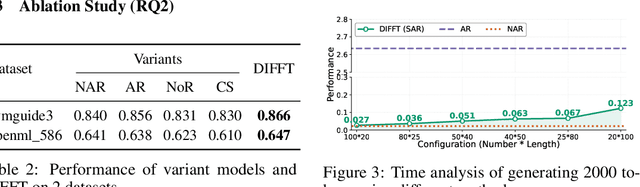
Feature Transformation (FT) crafts new features from original ones via mathematical operations to enhance dataset expressiveness for downstream models. However, existing FT methods exhibit critical limitations: discrete search struggles with enormous combinatorial spaces, impeding practical use; and continuous search, being highly sensitive to initialization and step sizes, often becomes trapped in local optima, restricting global exploration. To overcome these limitations, DIFFT redefines FT as a reward-guided generative task. It first learns a compact and expressive latent space for feature sets using a Variational Auto-Encoder (VAE). A Latent Diffusion Model (LDM) then navigates this space to generate high-quality feature embeddings, its trajectory guided by a performance evaluator towards task-specific optima. This synthesis of global distribution learning (from LDM) and targeted optimization (reward guidance) produces potent embeddings, which a novel semi-autoregressive decoder efficiently converts into structured, discrete features, preserving intra-feature dependencies while allowing parallel inter-feature generation. Extensive experiments on 14 benchmark datasets show DIFFT consistently outperforms state-of-the-art baselines in predictive accuracy and robustness, with significantly lower training and inference times.