 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-symbolic Explainable Artificial Intelligence Twin for Zero-touch IoE in Wireless Network
Oct 13, 2022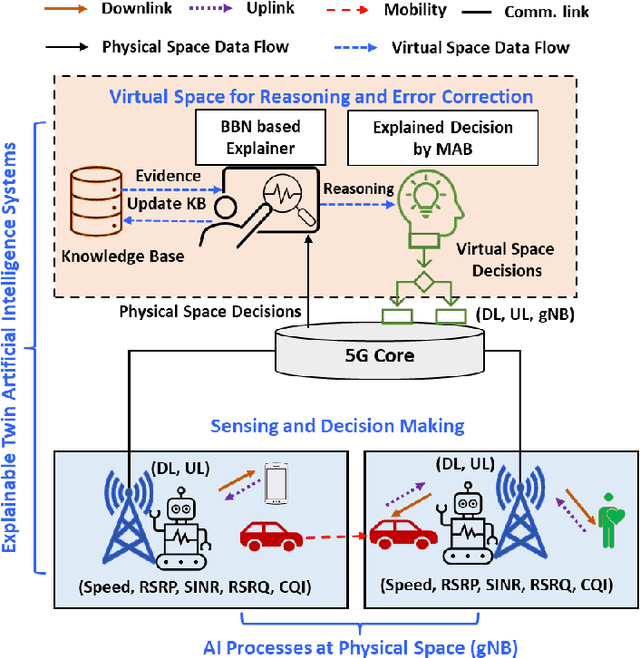
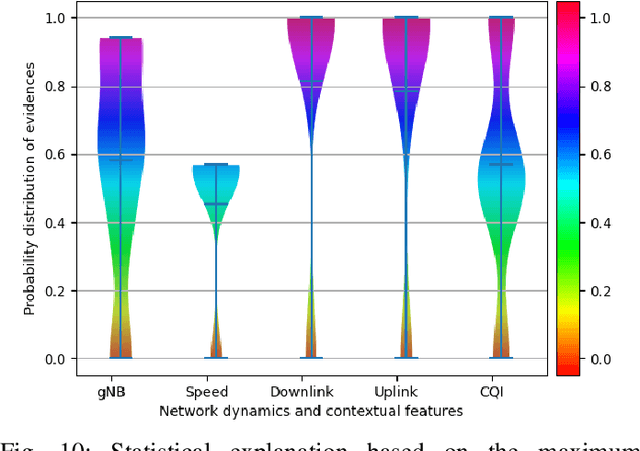
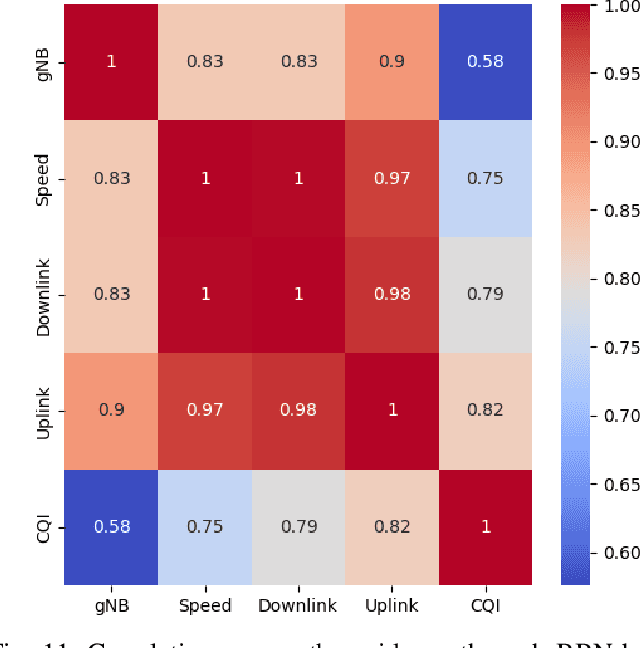
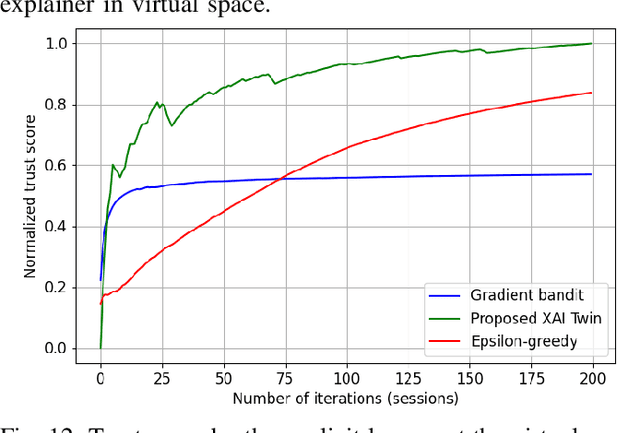
Explainable artificial intelligence (XAI) twin systems will be a fundamental enabler of zero-touch network and service management (ZSM) for sixth-generation (6G) wireless networks. A reliable XAI twin system for ZSM requires two composites: an extreme analytical ability for discretizing the physical behavior of the Internet of Everything (IoE) and rigorous methods for characterizing the reasoning of such behavior. In this paper, a novel neuro-symbolic explainable artificial intelligence twin framework is proposed to enable trustworthy ZSM for a wireless IoE. The physical space of the XAI twin executes a neural-network-driven multivariate regression to capture the time-dependent wireless IoE environment while determining unconscious decisions of IoE service aggregation. Subsequently, the virtual space of the XAI twin constructs a directed acyclic graph (DAG)-based Bayesian network that can infer a symbolic reasoning score over unconscious decisions through a first-order probabilistic language model. Furthermore, a Bayesian multi-arm bandits-based learning problem is proposed for reducing the gap between the expected explained score and the current obtained score of the proposed neuro-symbolic XAI twin. To address the challenges of extensible, modular, and stateless management functions in ZSM, the proposed neuro-symbolic XAI twin framework consists of two learning systems: 1) an implicit learner that acts as an unconscious learner in physical space, and 2) an explicit leaner that can exploit symbolic reasoning based on implicit learner decisions and prior evidence. Experimental results show that the proposed neuro-symbolic XAI twin can achieve around 96.26% accuracy while guaranteeing from 18% to 44% more trust score in terms of reasoning and closed-loop automation.
Performance Optimization for Variable Bitwidth Federated Learning in Wireless Networks
Sep 21, 2022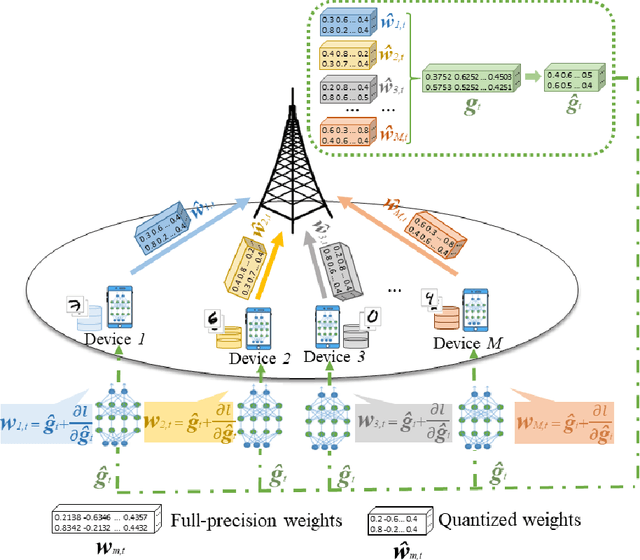
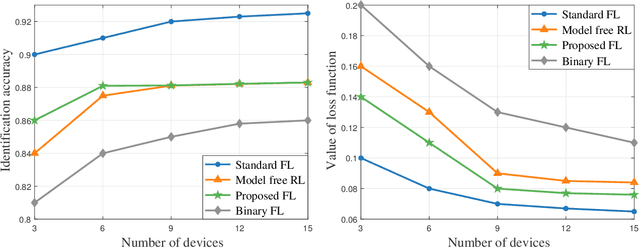
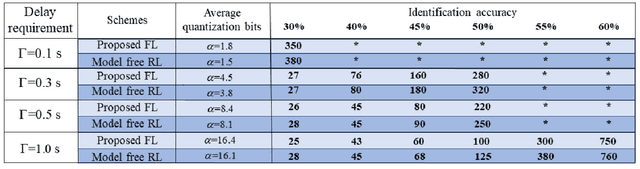
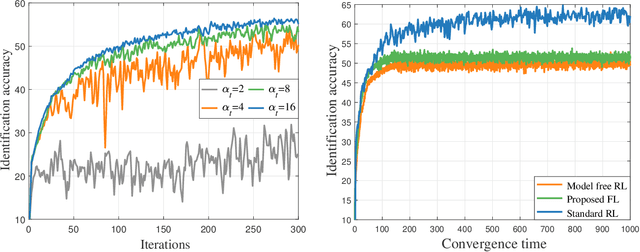
This paper considers improving wireless communication and computation efficiency in federated learning (FL) via model quantization. In the proposed bitwidth FL scheme, edge devices train and transmit quantized versions of their local FL model parameters to a coordinating server, which, in turn, aggregates them into a quantized global model and synchronizes the devices. The goal is to jointly determine the bitwidths employed for local FL model quantization and the set of devices participating in FL training at each iteration. This problem is posed as an optimization problem whose goal is to minimize the training loss of quantized FL under a per-iteration device sampling budget and delay requirement. To derive the solution, an analytical characterization is performed in order to show how the limited wireless resources and induced quantization errors affect the performance of the proposed FL method. The analytical results show that the improvement of FL training loss between two consecutive iterations depends on the device selection and quantization scheme as well as on several parameters inherent to the model being learned. Given linear regression-based estimates of these model properties, it is shown that the FL training process can be described as a Markov decision process (MDP), and, then, a model-based reinforcement learning (RL) method is proposed to optimize action selection over iterations. Compared to model-free RL, this model-based RL approach leverages the derived mathematical characterization of the FL training process to discover an effective device selection and quantization scheme without imposing additional device communication overhead. Simulation results show that the proposed FL algorithm can reduce 29% and 63% convergence time compared to a model free RL method and the standard FL method, respectively.
Recurrent Neural Network-based Anti-jamming Framework for Defense Against Multiple Jamming Policies
Aug 19, 2022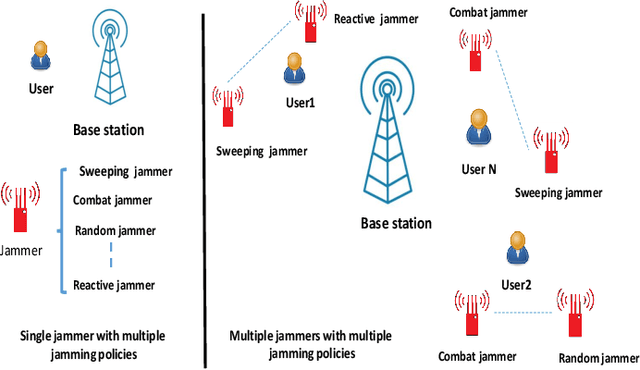
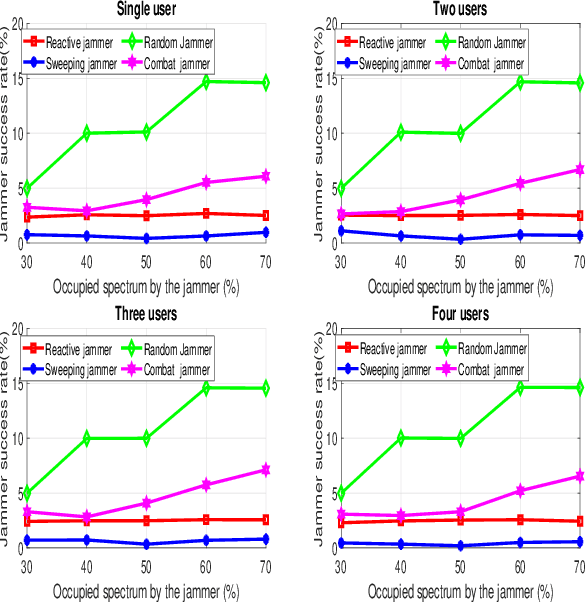
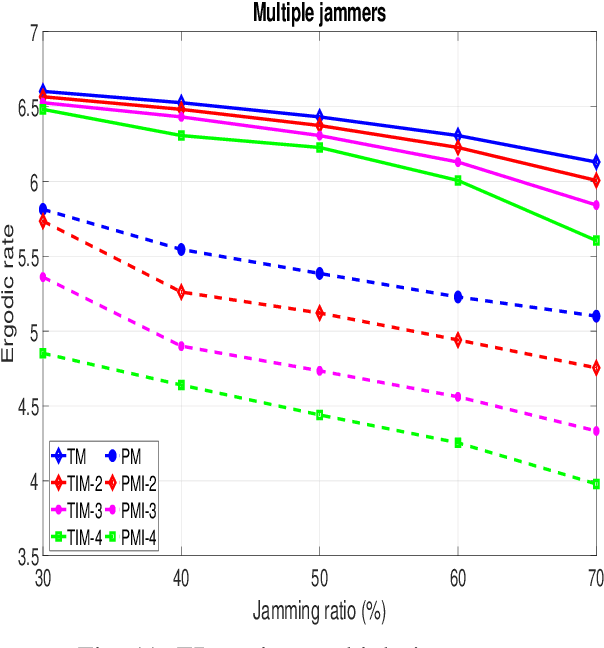
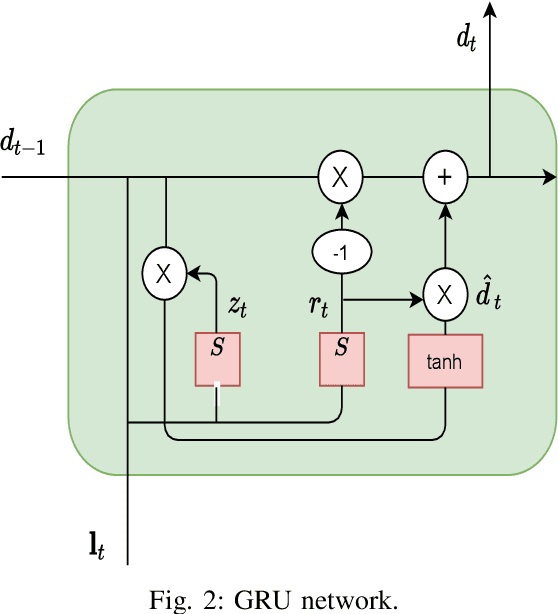
Conventional anti-jamming methods mainly focus on preventing single jammer attacks with an invariant jamming policy or jamming attacks from multiple jammers with similar jamming policies. These anti-jamming methods are ineffective against a single jammer following several different jamming policies or multiple jammers with distinct policies. Therefore, this paper proposes an anti-jamming method that can adapt its policy to the current jamming attack. Moreover, for the multiple jammers scenario, an anti-jamming method that estimates the future occupied channels using the jammers' occupied channels in previous time slots is proposed. In both single and multiple jammers scenarios, the interaction between the users and jammers is modeled using recurrent neural networks (RNN)s. The performance of the proposed anti-jamming methods is evaluated by calculating the users' successful transmission rate (STR) and ergodic rate (ER), and compared to a baseline based on Q-learning (DQL). Simulation results show that for the single jammer scenario, all the considered jamming policies are perfectly detected and high STR and ER are maintained. Moreover, when 70 % of the spectrum is under jamming attacks from multiple jammers, the proposed method achieves an STR and ER greater than 75 % and 80 %, respectively. These values rise to 90 % when 30 % of the spectrum is under jamming attacks. In addition, the proposed anti-jamming methods significantly outperform the DQL method for all the considered cases and jamming scenarios.
Performance Optimization for Semantic Communications: An Attention-based Reinforcement Learning Approach
Aug 17, 2022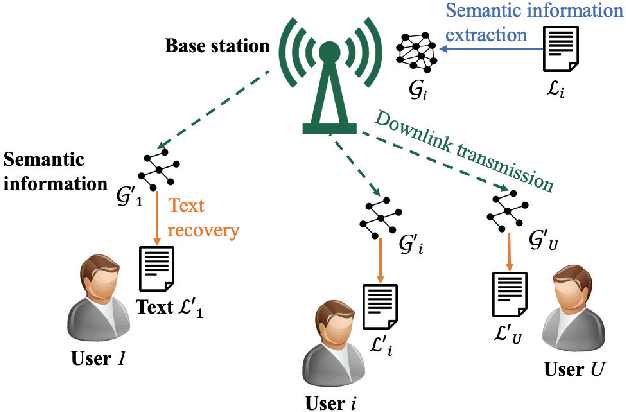
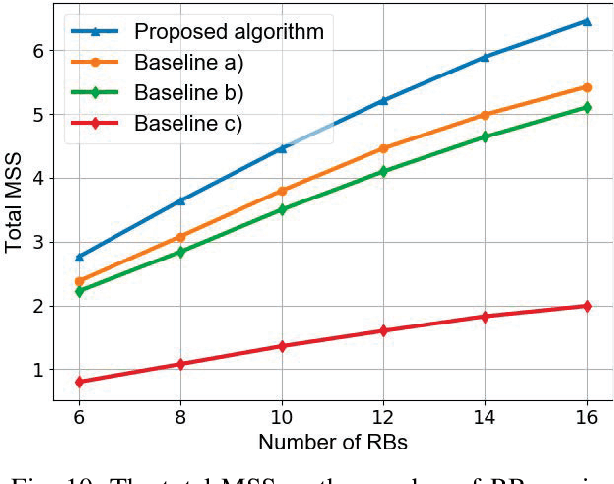
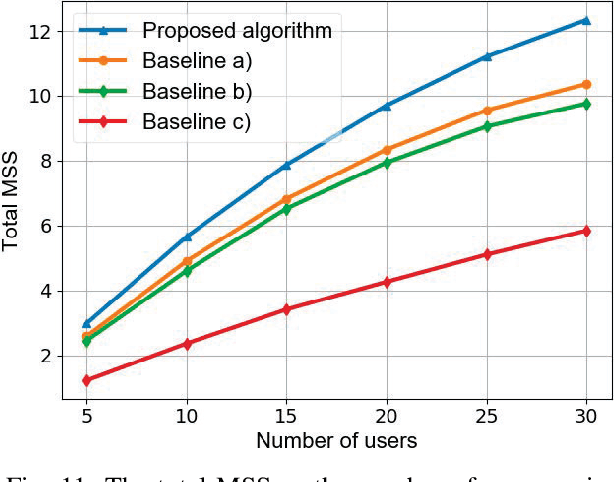
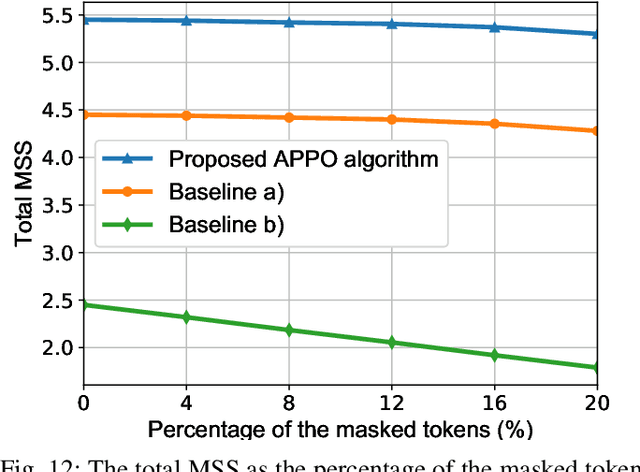
In this paper, a semantic communication framework is proposed for textual data transmission. In the studied model, a base station (BS) extracts the semantic information from textual data, and transmits it to each user. The semantic information is modeled by a knowledge graph (KG) that consists of a set of semantic triples. After receiving the semantic information, each user recovers the original text using a graph-to-text generation model. To measure the performance of the considered semantic communication framework, a metric of semantic similarity (MSS) that jointly captures the semantic accuracy and completeness of the recovered text is proposed. Due to wireless resource limitations, the BS may not be able to transmit the entire semantic information to each user and satisfy the transmission delay constraint. Hence, the BS must select an appropriate resource block for each user as well as determine and transmit part of the semantic information to the users. As such, we formulate an optimization problem whose goal is to maximize the total MSS by jointly optimizing the resource allocation policy and determining the partial semantic information to be transmitted. To solve this problem, a proximal-policy-optimization-based reinforcement learning (RL) algorithm integrated with an attention network is proposed. The proposed algorithm can evaluate the importance of each triple in the semantic information using an attention network and then, build a relationship between the importance distribution of the triples in the semantic information and the total MSS. Compared to traditional RL algorithms, the proposed algorithm can dynamically adjust its learning rate thus ensuring convergence to a locally optimal solution.
Downlink Interference Analysis of UAV-based mmWave Fronthaul for Small Cell Networks
Aug 11, 2022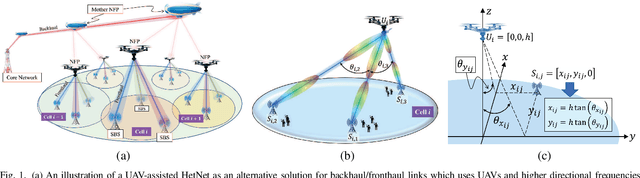
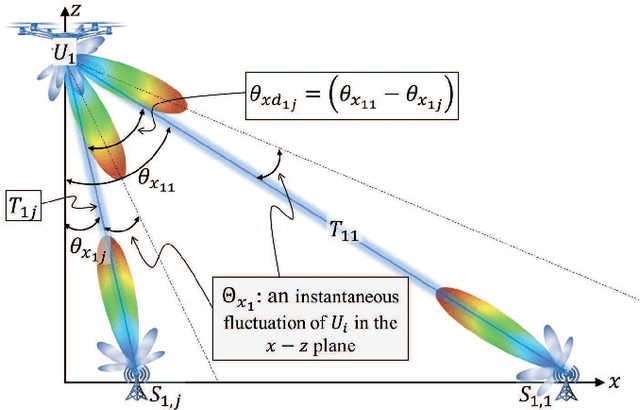
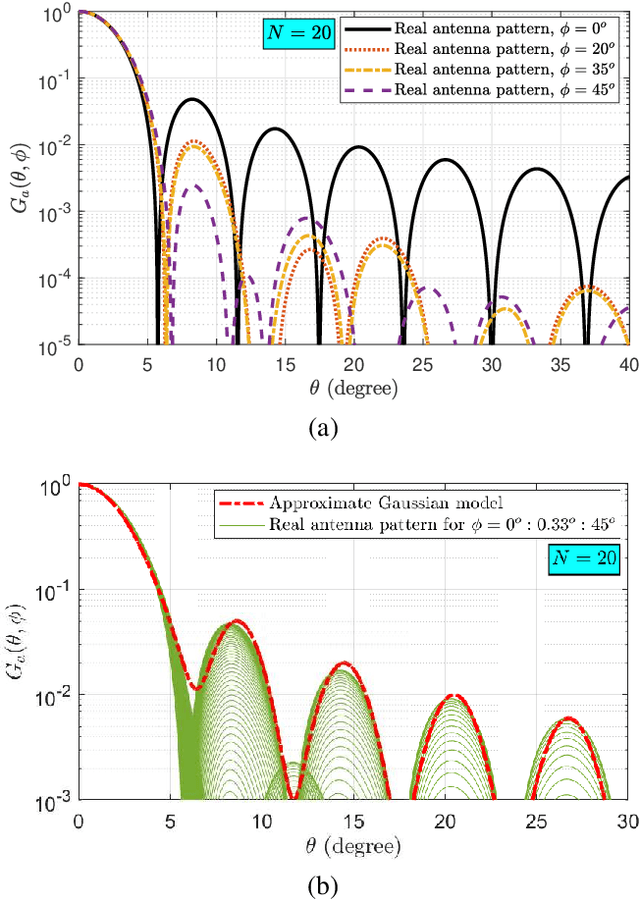
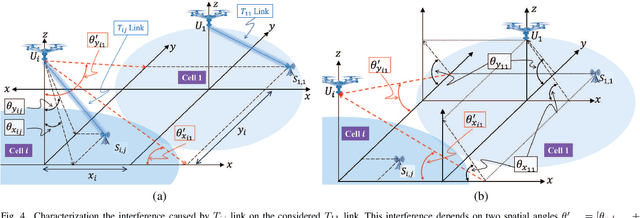
In this paper, an unmanned aerial vehicles (UAV)-based heterogeneous network is studied to solve the problem of transferring massive traffic of distributed small cells to the core network. First, a detailed three-dimensional (3D) model of the downlink channel is characterized by taking into account the real antenna pattern, UAVs' vibrations, random distribution of small cell base stations (SBSs), and the position of UAVs in 3D space. Then, a rigorous analysis of interference is performed for two types pf interference: intra-cell interference and inter-cell interference. The interference analysis results are then used to derive an upper bound of outage probability on the considered system. Using numerical results show that the analytical and simulation results match one another. The results show that, in the presence of UAV's fluctuations, optimizing radiation pattern shape requires balancing an inherent tradeoff between increasing pattern gain to reduce the interference as well as to compensate large path loss at mmWave frequencies and decreasing it to alleviate the adverse effect of a UAV's vibrations. The analytical derivations enable the derivation of the optimal antenna pattern for any condition in a short time instead of using time-consuming extensive simulations.
Green, Quantized Federated Learning over Wireless Networks: An Energy-Efficient Design
Jul 19, 2022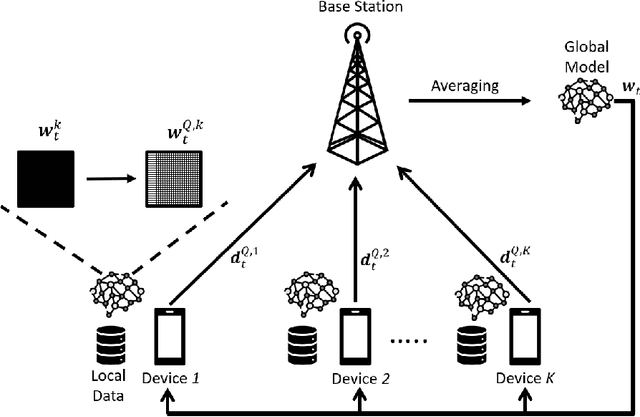
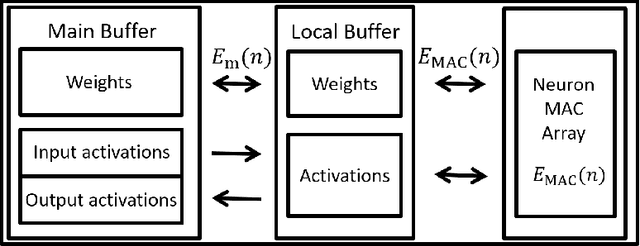
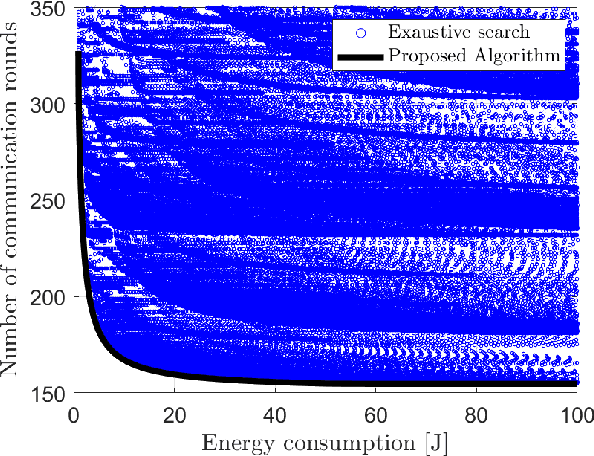
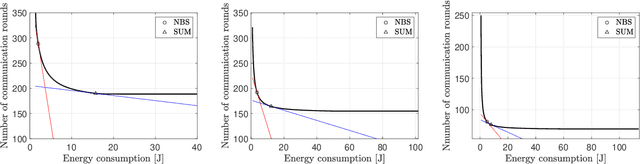
In this paper, a green, quantized FL framework, which represents data with a finite precision level in both local training and uplink transmission, is proposed. Here, the finite precision level is captured through the use of quantized neural networks (QNNs) that quantize weights and activations in fixed-precision format. In the considered FL model, each device trains its QNN and transmits a quantized training result to the base station. Energy models for the local training and the transmission with quantization are rigorously derived. To minimize the energy consumption and the number of communication rounds simultaneously, a multi-objective optimization problem is formulated with respect to the number of local iterations, the number of selected devices, and the precision levels for both local training and transmission while ensuring convergence under a target accuracy constraint. To solve this problem, the convergence rate of the proposed FL system is analytically derived with respect to the system control variables. Then, the Pareto boundary of the problem is characterized to provide efficient solutions using the normal boundary inspection method. Design insights on balancing the tradeoff between the two objectives are drawn from using the Nash bargaining solution and analyzing the derived convergence rate. Simulation results show that the proposed FL framework can reduce energy consumption until convergence by up to 52% compared to a baseline FL algorithm that represents data with full precision.
Neuro-Symbolic Artificial Intelligence (AI) for Intent based Semantic Communication
May 22, 2022
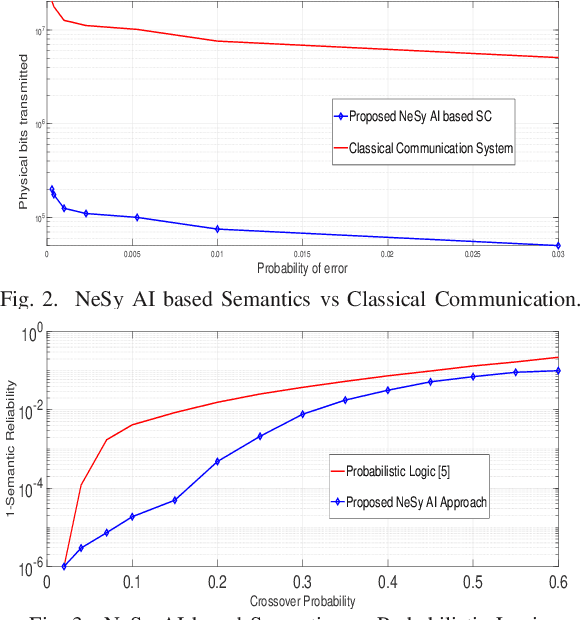
Intent-based networks that integrate sophisticated machine reasoning technologies will be a cornerstone of future wireless 6G systems. Intent-based communication requires the network to consider the semantics (meanings) and effectiveness (at end-user) of the data transmission. This is essential if 6G systems are to communicate reliably with fewer bits while simultaneously providing connectivity to heterogeneous users. In this paper, contrary to state of the art, which lacks explainability of data, the framework of neuro-symbolic artificial intelligence (NeSy AI) is proposed as a pillar for learning causal structure behind the observed data. In particular, the emerging concept of generative flow networks (GFlowNet) is leveraged for the first time in a wireless system to learn the probabilistic structure which generates the data. Further, a novel optimization problem for learning the optimal encoding and decoding functions is rigorously formulated with the intent of achieving higher semantic reliability. Novel analytical formulations are developed to define key metrics for semantic message transmission, including semantic distortion, semantic similarity, and semantic reliability. These semantic measure functions rely on the proposed definition of semantic content of the knowledge base and this information measure is reflective of the nodes' reasoning capabilities. Simulation results validate the ability to communicate efficiently (with less bits but same semantics) and significantly better compared to a conventional system which does not exploit the reasoning capabilities.
Curriculum Learning for Goal-Oriented Semantic Communications with a Common Language
Apr 21, 2022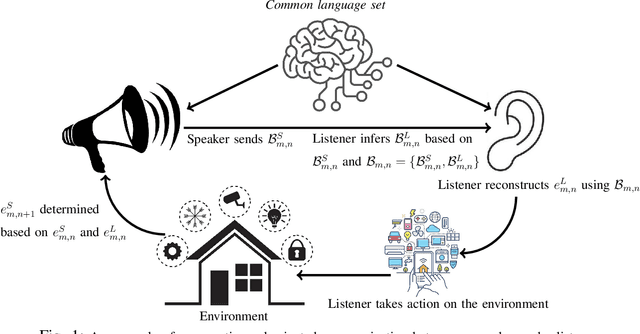
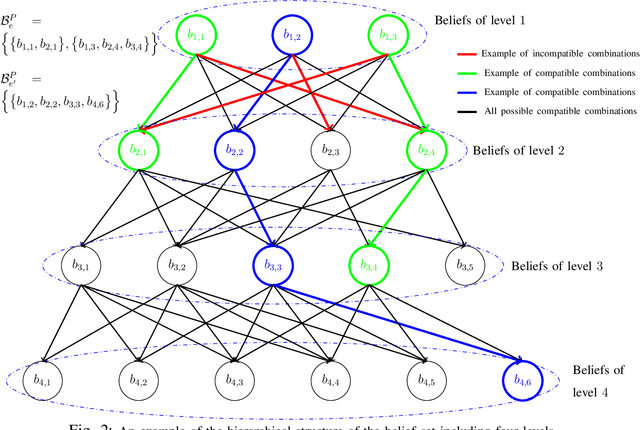
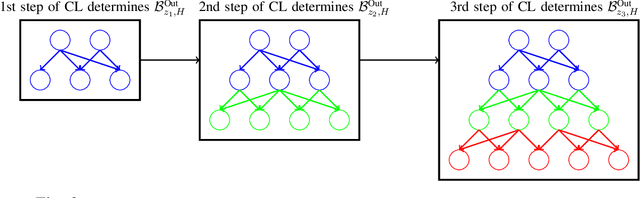
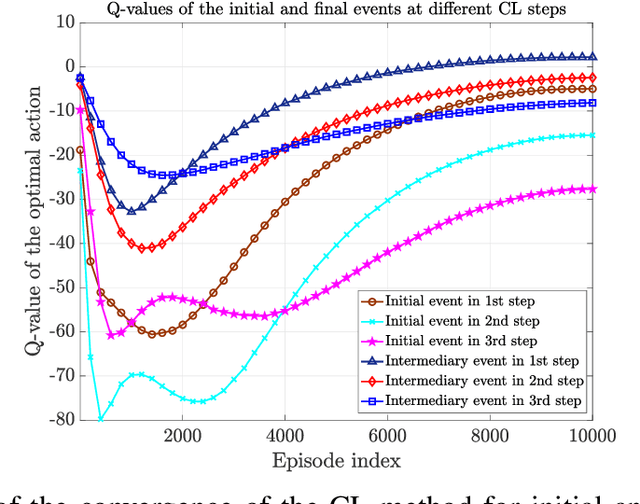
Goal-oriented semantic communication will be a pillar of next-generation wireless networks. Despite significant recent efforts in this area, most prior works are focused on specific data types (e.g., image or audio), and they ignore the goal and effectiveness aspects of semantic transmissions. In contrast, in this paper, a holistic goal-oriented semantic communication framework is proposed to enable a speaker and a listener to cooperatively execute a set of sequential tasks in a dynamic environment. A common language based on a hierarchical belief set is proposed to enable semantic communications between speaker and listener. The speaker, acting as an observer of the environment, utilizes the beliefs to transmit an initial description of its observation (called event) to the listener. The listener is then able to infer on the transmitted description and complete it by adding related beliefs to the transmitted beliefs of the speaker. As such, the listener reconstructs the observed event based on the completed description, and it then takes appropriate action in the environment based on the reconstructed event. An optimization problem is defined to determine the perfect and abstract description of the events while minimizing the transmission and inference costs with constraints on the task execution time and belief efficiency. Then, a novel bottom-up curriculum learning (CL) framework based on reinforcement learning is proposed to solve the optimization problem and enable the speaker and listener to gradually identify the structure of the belief set and the perfect and abstract description of the events. Simulation results show that the proposed CL method outperforms traditional RL in terms of convergence time, task execution cost and time, reliability, and belief efficiency.
Positioning Using Visible Light Communications: A Perspective Arcs Approach
Apr 18, 2022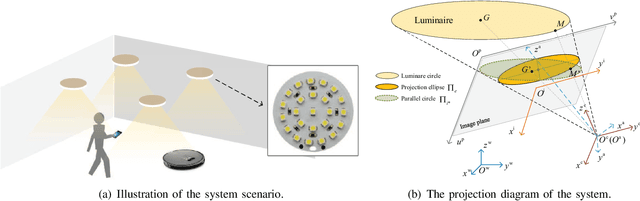
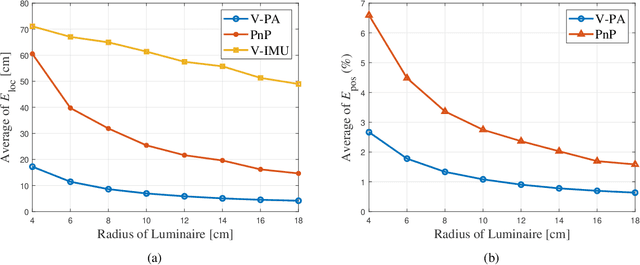
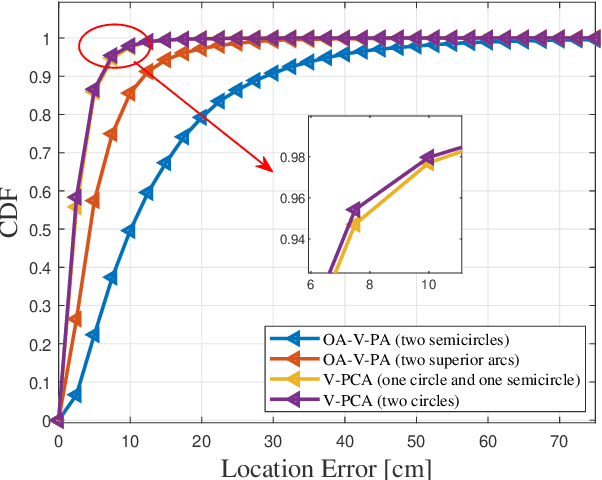
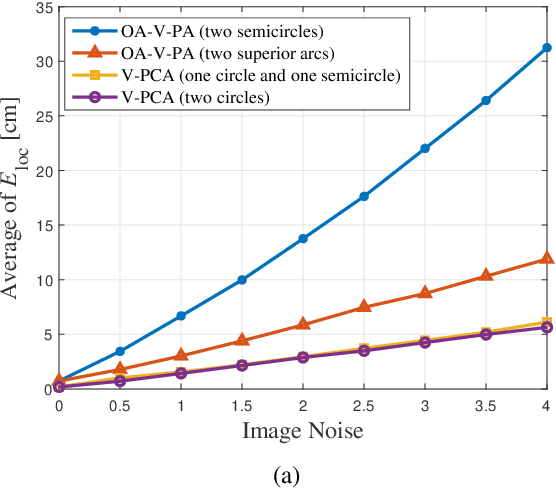
Visible light positioning (VLP) is an accurate indoor positioning technology that uses luminaires as transmitters. In particular, circular luminaires are a common source type for VLP, that are typically treated only as point sources for positioning, while ignoring their geometry characteristics. In this paper, the arc feature of the circular luminaire and the coordinate information obtained via visible light communication (VLC) are jointly used for VLC-enabled indoor positioning, and a novel perspective arcs approach is proposed. The proposed approach does not rely on any inertial measurement unit, and has no tilted angle limitations at the user. First, a VLC assisted perspective circle and arc algorithm (V-PCA) is proposed for a scenario in which a complete luminaire and an incomplete one can be captured by the user. Considering the cases in which parts of VLC links are blocked, an anti-occlusion VLC assisted perspective arcs algorithm (OA-V-PA) is proposed. Simulation results show that the proposed indoor positioning algorithm can achieve a 95th percentile positioning accuracy of around 10 cm. Moreover, an experimental prototype based on mobile phone is implemented, in which, a fused image processing method is proposed. Experimental results show that the average positioning accuracy is less than 5 cm.
FedVQCS: Federated Learning via Vector Quantized Compressed Sensing
Apr 16, 2022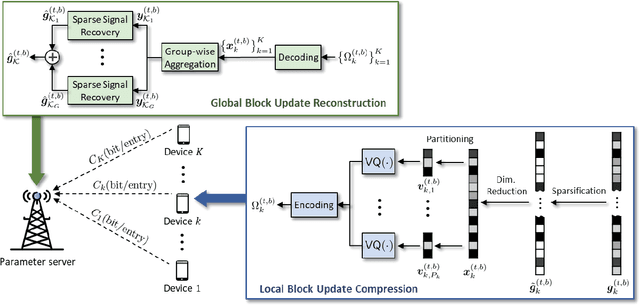
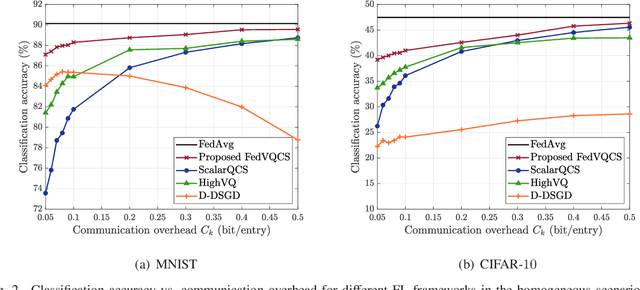
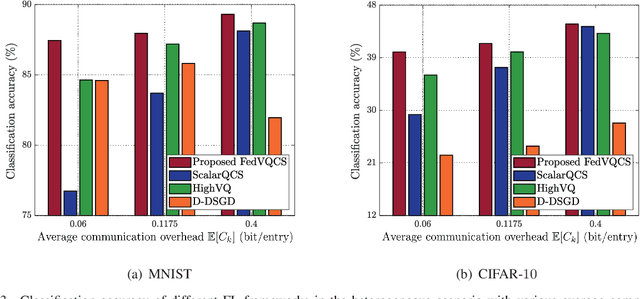
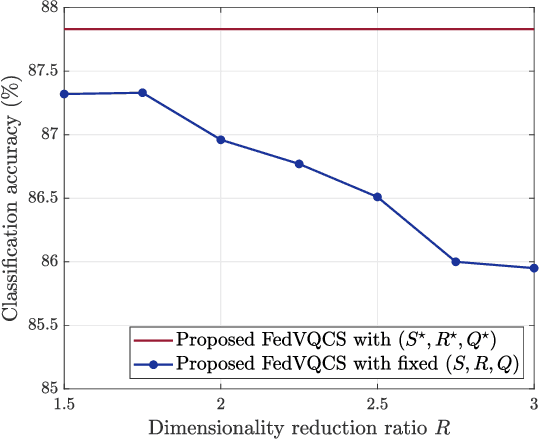
In this paper, a new communication-efficient federated learning (FL) framework is proposed, inspired by vector quantized compressed sensing. The basic strategy of the proposed framework is to compress the local model update at each device by applying dimensionality reduction followed by vector quantization. Subsequently, the global model update is reconstructed at a parameter server (PS) by applying a sparse signal recovery algorithm to the aggregation of the compressed local model updates. By harnessing the benefits of both dimensionality reduction and vector quantization, the proposed framework effectively reduces the communication overhead of local update transmissions. Both the design of the vector quantizer and the key parameters for the compression are optimized so as to minimize the reconstruction error of the global model update under the constraint of wireless link capacity. By considering the reconstruction error, the convergence rate of the proposed framework is also analyzed for a smooth loss function. Simulation results on the MNIST and CIFAR-10 datasets demonstrate that the proposed framework provides more than a 2.5% increase in classification accuracy compared to state-of-art FL frameworks when the communication overhead of the local model update transmission is less than 0.1 bit per local model entry.