 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWireless Federated Multi-Task LLM Fine-Tuning via Sparse-and-Orthogonal LoRA
Feb 24, 2026Decentralized federated learning (DFL) based on low-rank adaptation (LoRA) enables mobile devices with multi-task datasets to collaboratively fine-tune a large language model (LLM) by exchanging locally updated parameters with a subset of neighboring devices via wireless connections for knowledge integration.However, directly aggregating parameters fine-tuned on heterogeneous datasets induces three primary issues across the DFL life-cycle: (i) \textit{catastrophic knowledge forgetting during fine-tuning process}, arising from conflicting update directions caused by data heterogeneity; (ii) \textit{inefficient communication and convergence during model aggregation process}, due to bandwidth-intensive redundant model transmissions; and (iii) \textit{multi-task knowledge interference during inference process}, resulting from incompatible knowledge representations coexistence during inference. To address these issues in a fully decentralized scenario, we first propose a sparse-and-orthogonal LoRA that ensures orthogonality between model updates to eliminate direction conflicts during fine-tuning.Then, we analyze how device connection topology affects multi-task performance, prompting a cluster-based topology design during aggregation.Finally, we propose an implicit mixture of experts (MoE) mechanism to avoid the coexistence of incompatible knowledge during inference. Simulation results demonstrate that the proposed approach effectively reduces communication resource consumption by up to $73\%$ and enhances average performance by $5\%$ compared with the traditional LoRA method.
A Secure and Private Distributed Bayesian Federated Learning Design
Feb 23, 2026Distributed Federated Learning (DFL) enables decentralized model training across large-scale systems without a central parameter server. However, DFL faces three critical challenges: privacy leakage from honest-but-curious neighbors, slow convergence due to the lack of central coordination, and vulnerability to Byzantine adversaries aiming to degrade model accuracy. To address these issues, we propose a novel DFL framework that integrates Byzantine robustness, privacy preservation, and convergence acceleration. Within this framework, each device trains a local model using a Bayesian approach and independently selects an optimal subset of neighbors for posterior exchange. We formulate this neighbor selection as an optimization problem to minimize the global loss function under security and privacy constraints. Solving this problem is challenging because devices only possess partial network information, and the complex coupling between topology, security, and convergence remains unclear. To bridge this gap, we first analytically characterize the trade-offs between dynamic connectivity, Byzantine detection, privacy levels, and convergence speed. Leveraging these insights, we develop a fully distributed Graph Neural Network (GNN)-based Reinforcement Learning (RL) algorithm. This approach enables devices to make autonomous connection decisions based on local observations. Simulation results demonstrate that our method achieves superior robustness and efficiency with significantly lower overhead compared to traditional security and privacy schemes.
Collaborative Reinforcement Learning Based Unmanned Aerial Vehicle (UAV) Trajectory Design for 3D UAV Tracking
Jan 22, 2024



In this paper, the problem of using one active unmanned aerial vehicle (UAV) and four passive UAVs to localize a 3D target UAV in real time is investigated. In the considered model, each passive UAV receives reflection signals from the target UAV, which are initially transmitted by the active UAV. The received reflection signals allow each passive UAV to estimate the signal transmission distance which will be transmitted to a base station (BS) for the estimation of the position of the target UAV. Due to the movement of the target UAV, each active/passive UAV must optimize its trajectory to continuously localize the target UAV. Meanwhile, since the accuracy of the distance estimation depends on the signal-to-noise ratio of the transmission signals, the active UAV must optimize its transmit power. This problem is formulated as an optimization problem whose goal is to jointly optimize the transmit power of the active UAV and trajectories of both active and passive UAVs so as to maximize the target UAV positioning accuracy. To solve this problem, a Z function decomposition based reinforcement learning (ZD-RL) method is proposed. Compared to value function decomposition based RL (VD-RL), the proposed method can find the probability distribution of the sum of future rewards to accurately estimate the expected value of the sum of future rewards thus finding better transmit power of the active UAV and trajectories for both active and passive UAVs and improving target UAV positioning accuracy. Simulation results show that the proposed ZD-RL method can reduce the positioning errors by up to 39.4% and 64.6%, compared to VD-RL and independent deep RL methods, respectively.
Importance-Aware Image Segmentation-based Semantic Communication for Autonomous Driving
Jan 16, 2024This article studies the problem of image segmentation-based semantic communication in autonomous driving. In real traffic scenes, detecting the key objects (e.g., vehicles, pedestrians and obstacles) is more crucial than that of other objects to guarantee driving safety. Therefore, we propose a vehicular image segmentation-oriented semantic communication system, termed VIS-SemCom, where image segmentation features of important objects are transmitted to reduce transmission redundancy. First, to accurately extract image semantics, we develop a semantic codec based on Swin Transformer architecture, which expands the perceptual field thus improving the segmentation accuracy. Next, we propose a multi-scale semantic extraction scheme via assigning the number of Swin Transformer blocks for diverse resolution features, thus highlighting the important objects' accuracy. Furthermore, the importance-aware loss is invoked to emphasize the important objects, and an online hard sample mining (OHEM) strategy is proposed to handle small sample issues in the dataset. Experimental results demonstrate that the proposed VIS-SemCom can achieve a coding gain of nearly 6 dB with a 60% mean intersection over union (mIoU), reduce the transmitted data amount by up to 70% with a 60% mIoU, and improve the segmentation intersection over union (IoU) of important objects by 4%, compared to traditional transmission scheme.
Attention-based UNet enabled Lightweight Image Semantic Communication System over Internet of Things
Jan 14, 2024This paper studies the problem of the lightweight image semantic communication system that is deployed on Internet of Things (IoT) devices. In the considered system model, devices must use semantic communication techniques to support user behavior recognition in ultimate video service with high data transmission efficiency. However, it is computationally expensive for IoT devices to deploy semantic codecs due to the complex calculation processes of deep learning (DL) based codec training and inference. To make it affordable for IoT devices to deploy semantic communication systems, we propose an attention-based UNet enabled lightweight image semantic communication (LSSC) system, which achieves low computational complexity and small model size. In particular, we first let the LSSC system train the codec at the edge server to reduce the training computation load on IoT devices. Then, we introduce the convolutional block attention module (CBAM) to extract the image semantic features and decrease the number of downsampling layers thus reducing the floating-point operations (FLOPs). Finally, we experimentally adjust the structure of the codec and find out the optimal number of downsampling layers. Simulation results show that the proposed LSSC system can reduce the semantic codec FLOPs by 14%, and reduce the model size by 55%, with a sacrifice of 3% accuracy, compared to the baseline. Moreover, the proposed scheme can achieve a higher transmission accuracy than the traditional communication scheme in the low channel signal-to-noise (SNR) region.
Base Station Beamforming Design for Near-field XL-IRS Beam Training
Sep 12, 2023


Existing research on extremely large-scale intelligent reflecting surface (XL-IRS) beam training has assumed the far-field channel model for base station (BS)-IRS link. However, this approach may cause degraded beam training performance in practice due to the near-field channel model of the BS-IRS link. To address this issue, we propose two efficient schemes to optimize BS beamforming for improving the XL-IRS beam training performance. Specifically, the first scheme aims to maximize total received signal power on the XL-IRS, which generalizes the existing angle based BS beamforming design and can be resolved using the singular value decomposition (SVD) method. The second scheme aims to maximize the $\ell_1$-norm of incident signals on the XL-IRS, which is shown to achieve the maximum received power at the user. To solve the non-convex $\ell_1$-norm maximization problem, we propose an eficient algorithm by using the alternating optimization (AO) technique. Numerical results show that the proposed AO based BS beamforming design outperforms the SVD/angle based BS beamforming in terms of training accuracy and achievable received signal-to-noise ratio (SNR).
Near-Field Beam Training of Intelligent Reflecting Surface: A Novel Two-Layer Codebook
Mar 13, 2023This paper investigates the codebook based near-field beam training of Intelligent Reflecting Surface (IRS). In the considered model, near-field beam training should be performed to focus the signals at the location of user equipment (UE) to obtain the prominent IRS array gain. However, existing codebook schemes can not realize low training overhead and high receiving power, simultaneously. To tackle this issue, a novel two-layer codebook is proposed. Specifically, the layer-1 codebook is designed based on the omnidirectivity of random-phase beam pattern, which estimates the UE distance with training overhead equivalent to that of a DFT codeword. Then, based on the estimated distance of UE, the layer-2 codebook is generated to scan the candidate locations of UE, and finally obtain the optimal codeword for IRS beamforming. Numerical results show that, compared with the benchmarks, the proposed codebook scheme makes more accurate estimation of UE distances and angles, achieving higher date rate, yet with a smaller training overhead.
Cross-Layer Federated Learning Optimization in MIMO Networks
Feb 04, 2023



In this paper, the performance optimization of federated learning (FL), when deployed over a realistic wireless multiple-input multiple-output (MIMO) communication system with digital modulation and over-the-air computation (AirComp) is studied. In particular, an MIMO system is considered in which edge devices transmit their local FL models (trained using their locally collected data) to a parameter server (PS) using beamforming to maximize the number of devices scheduled for transmission. The PS, acting as a central controller, generates a global FL model using the received local FL models and broadcasts it back to all devices. Due to the limited bandwidth in a wireless network, AirComp is adopted to enable efficient wireless data aggregation. However, fading of wireless channels can produce aggregate distortions in an AirComp-based FL scheme. To tackle this challenge, we propose a modified federated averaging (FedAvg) algorithm that combines digital modulation with AirComp to mitigate wireless fading while ensuring the communication efficiency. This is achieved by a joint transmit and receive beamforming design, which is formulated as a optimization problem to dynamically adjust the beamforming matrices based on current FL model parameters so as to minimize the transmitting error and ensure the FL performance. To achieve this goal, we first analytically characterize how the beamforming matrices affect the performance of the FedAvg in different iterations. Based on this relationship, an artificial neural network (ANN) is used to estimate the local FL models of all devices and adjust the beamforming matrices at the PS for future model transmission. The algorithmic advantages and improved performance of the proposed methodologies are demonstrated through extensive numerical experiments.
Performance Optimization for Variable Bitwidth Federated Learning in Wireless Networks
Sep 21, 2022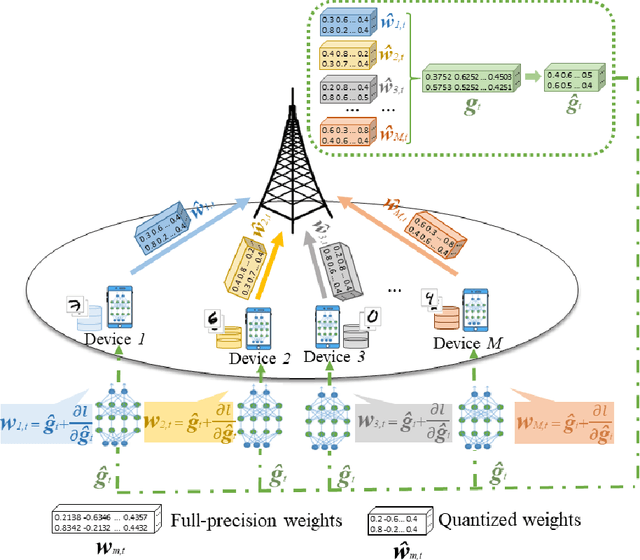
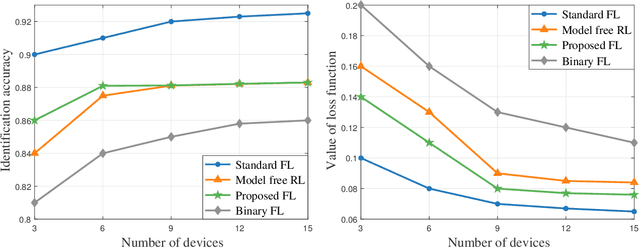
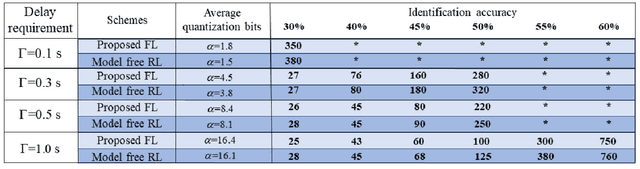
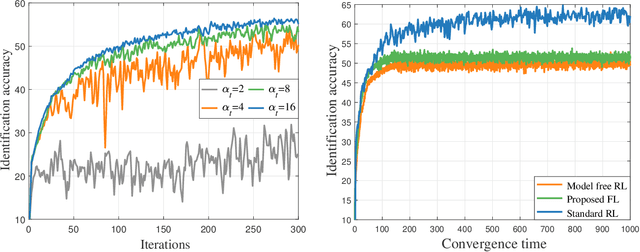
This paper considers improving wireless communication and computation efficiency in federated learning (FL) via model quantization. In the proposed bitwidth FL scheme, edge devices train and transmit quantized versions of their local FL model parameters to a coordinating server, which, in turn, aggregates them into a quantized global model and synchronizes the devices. The goal is to jointly determine the bitwidths employed for local FL model quantization and the set of devices participating in FL training at each iteration. This problem is posed as an optimization problem whose goal is to minimize the training loss of quantized FL under a per-iteration device sampling budget and delay requirement. To derive the solution, an analytical characterization is performed in order to show how the limited wireless resources and induced quantization errors affect the performance of the proposed FL method. The analytical results show that the improvement of FL training loss between two consecutive iterations depends on the device selection and quantization scheme as well as on several parameters inherent to the model being learned. Given linear regression-based estimates of these model properties, it is shown that the FL training process can be described as a Markov decision process (MDP), and, then, a model-based reinforcement learning (RL) method is proposed to optimize action selection over iterations. Compared to model-free RL, this model-based RL approach leverages the derived mathematical characterization of the FL training process to discover an effective device selection and quantization scheme without imposing additional device communication overhead. Simulation results show that the proposed FL algorithm can reduce 29% and 63% convergence time compared to a model free RL method and the standard FL method, respectively.
Multi-Factors Aware Dual-Attentional Knowledge Tracing
Aug 10, 2021With the increasing demands of personalized learning, knowledge tracing has become important which traces students' knowledge states based on their historical practices. Factor analysis methods mainly use two kinds of factors which are separately related to students and questions to model students' knowledge states. These methods use the total number of attempts of students to model students' learning progress and hardly highlight the impact of the most recent relevant practices. Besides, current factor analysis methods ignore rich information contained in questions. In this paper, we propose Multi-Factors Aware Dual-Attentional model (MF-DAKT) which enriches question representations and utilizes multiple factors to model students' learning progress based on a dual-attentional mechanism. More specifically, we propose a novel student-related factor which records the most recent attempts on relevant concepts of students to highlight the impact of recent exercises. To enrich questions representations, we use a pre-training method to incorporate two kinds of question information including questions' relation and difficulty level. We also add a regularization term about questions' difficulty level to restrict pre-trained question representations to fine-tuning during the process of predicting students' performance. Moreover, we apply a dual-attentional mechanism to differentiate contributions of factors and factor interactions to final prediction in different practice records. At last, we conduct experiments on several real-world datasets and results show that MF-DAKT can outperform existing knowledge tracing methods. We also conduct several studies to validate the effects of each component of MF-DAKT.
* 10 pages, 10 figures, 6 tables