 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Imitation Learning in Minecraft
Jul 06, 2020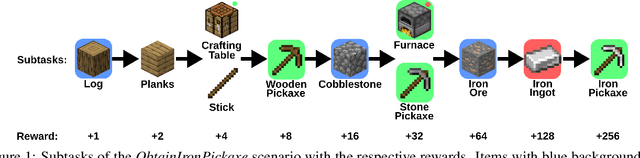

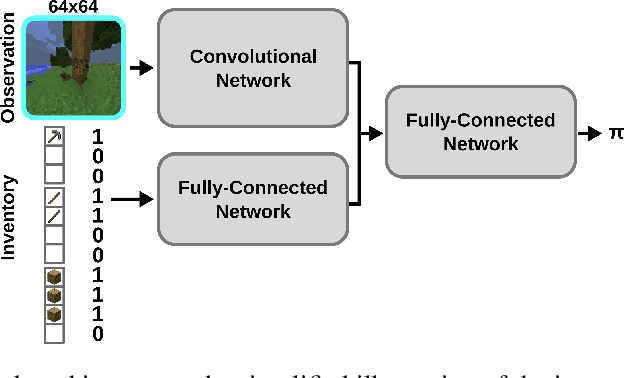
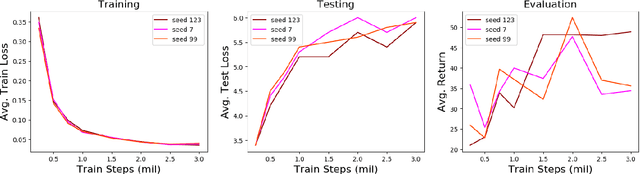
Imitation learning is a powerful family of techniques for learning sensorimotor coordination in immersive environments. We apply imitation learning to attain state-of-the-art performance on hard exploration problems in the Minecraft environment. We report experiments that highlight the influence of network architecture, loss function, and data augmentation. An early version of our approach reached second place in the MineRL competition at NeurIPS 2019. Here we report stronger results that can be used as a starting point for future competition entries and related research. Our code is available at https://github.com/amiranas/minerl_imitation_learning.
Scalable Differentiable Physics for Learning and Control
Jul 04, 2020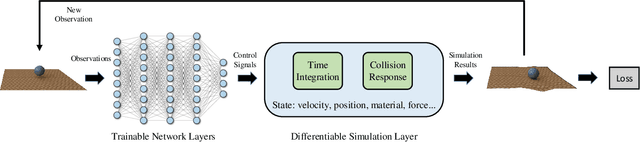



Differentiable physics is a powerful approach to learning and control problems that involve physical objects and environments. While notable progress has been made, the capabilities of differentiable physics solvers remain limited. We develop a scalable framework for differentiable physics that can support a large number of objects and their interactions. To accommodate objects with arbitrary geometry and topology, we adopt meshes as our representation and leverage the sparsity of contacts for scalable differentiable collision handling. Collisions are resolved in localized regions to minimize the number of optimization variables even when the number of simulated objects is high. We further accelerate implicit differentiation of optimization with nonlinear constraints. Experiments demonstrate that the presented framework requires up to two orders of magnitude less memory and computation in comparison to recent particle-based methods. We further validate the approach on inverse problems and control scenarios, where it outperforms derivative-free and model-free baselines by at least an order of magnitude.
Sample Factory: Egocentric 3D Control from Pixels at 100000 FPS with Asynchronous Reinforcement Learning
Jun 23, 2020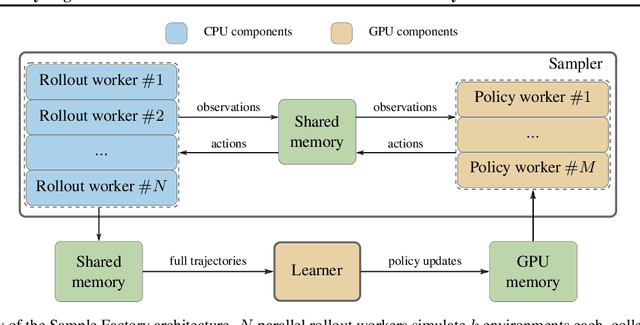
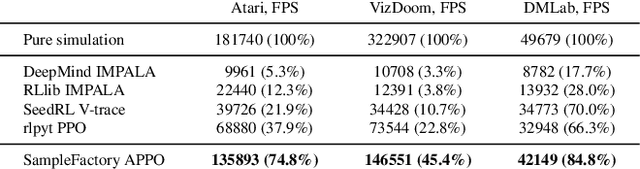
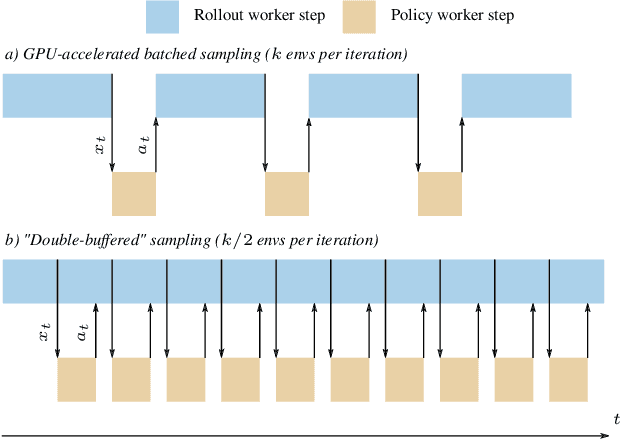
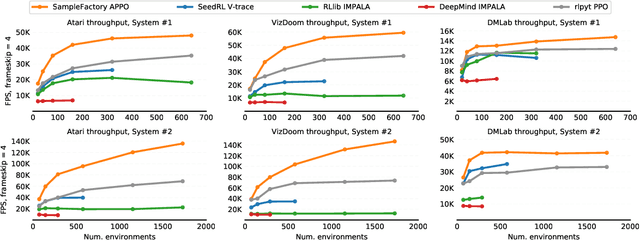
Increasing the scale of reinforcement learning experiments has allowed researchers to achieve unprecedented results in both training sophisticated agents for video games, and in sim-to-real transfer for robotics. Typically such experiments rely on large distributed systems and require expensive hardware setups, limiting wider access to this exciting area of research. In this work we aim to solve this problem by optimizing the efficiency and resource utilization of reinforcement learning algorithms instead of relying on distributed computation. We present the "Sample Factory", a high-throughput training system optimized for a single-machine setting. Our architecture combines a highly efficient, asynchronous, GPU-based sampler with off-policy correction techniques, allowing us to achieve throughput higher than $10^5$ environment frames/second on non-trivial control problems in 3D without sacrificing sample efficiency. We extend Sample Factory to support self-play and population-based training and apply these techniques to train highly capable agents for a multiplayer first-person shooter game. The source code is available at https://github.com/alex-petrenko/sample-factory
Multiscale Deep Equilibrium Models
Jun 15, 2020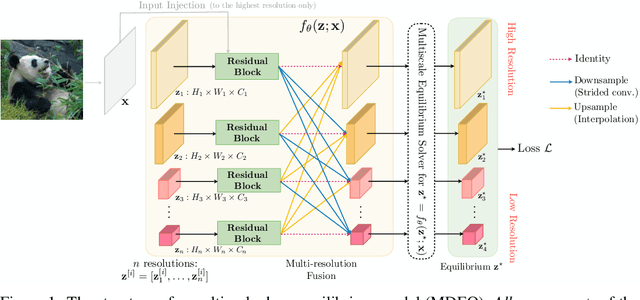
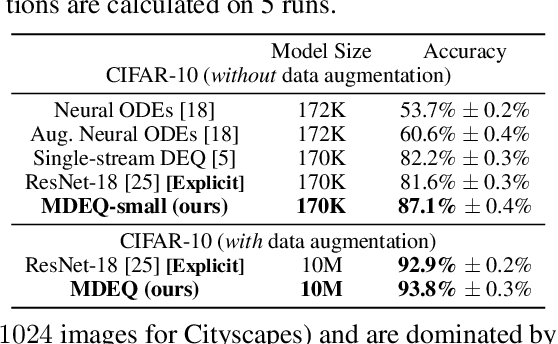
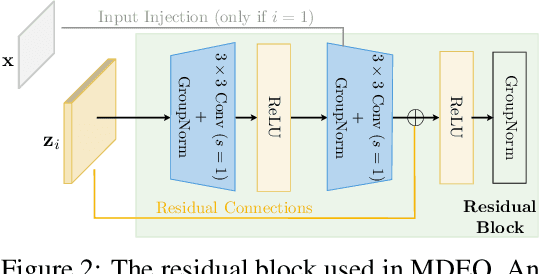
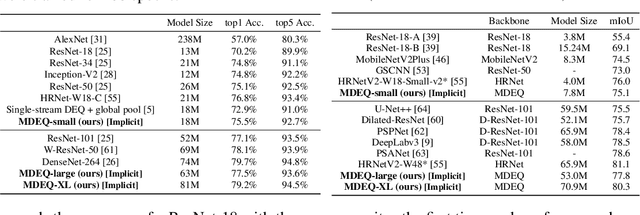
We propose a new class of implicit networks, the multiscale deep equilibrium model (MDEQ), suited to large-scale and highly hierarchical pattern recognition domains. An MDEQ directly solves for and backpropagates through the equilibrium points of multiple feature resolutions simultaneously, using implicit differentiation to avoid storing intermediate states (and thus requiring only O(1) memory consumption). These simultaneously-learned multi-resolution features allow us to train a single model on a diverse set of tasks and loss functions, such as using a single MDEQ to perform both image classification and semantic segmentation. We illustrate the effectiveness of this approach on two large-scale vision tasks: ImageNet classification and semantic segmentation on high-resolution images from the Cityscapes dataset. In both settings, MDEQs are able to match or exceed the performance of recent competitive computer vision models: the first time such performance and scale have been achieved by an implicit deep learning approach. The code and pre-trained models are at https://github.com/locuslab/mdeq .
Deep Drone Acrobatics
Jun 11, 2020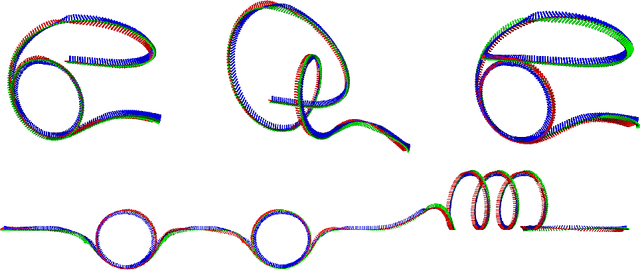
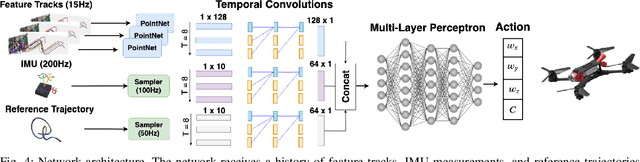

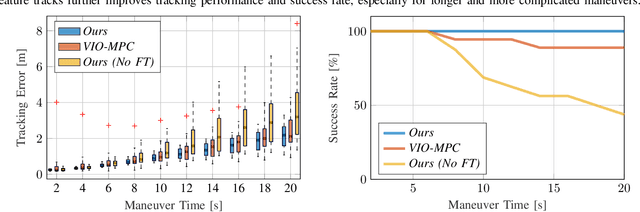
Performing acrobatic maneuvers with quadrotors is extremely challenging. Acrobatic flight requires high thrust and extreme angular accelerations that push the platform to its physical limits. Professional drone pilots often measure their level of mastery by flying such maneuvers in competitions. In this paper, we propose to learn a sensorimotor policy that enables an autonomous quadrotor to fly extreme acrobatic maneuvers with only onboard sensing and computation. We train the policy entirely in simulation by leveraging demonstrations from an optimal controller that has access to privileged information. We use appropriate abstractions of the visual input to enable transfer to a real quadrotor. We show that the resulting policy can be directly deployed in the physical world without any fine-tuning on real data. Our methodology has several favorable properties: it does not require a human expert to provide demonstrations, it cannot harm the physical system during training, and it can be used to learn maneuvers that are challenging even for the best human pilots. Our approach enables a physical quadrotor to fly maneuvers such as the Power Loop, the Barrel Roll, and the Matty Flip, during which it incurs accelerations of up to 3g.
* 8 pages + 2 pages references. Video: https://youtu.be/2N_wKXQ6MXA. Code: https://github.com/uzh-rpg/deep_drone_acrobatics
Auto-decoding Graphs
Jun 04, 2020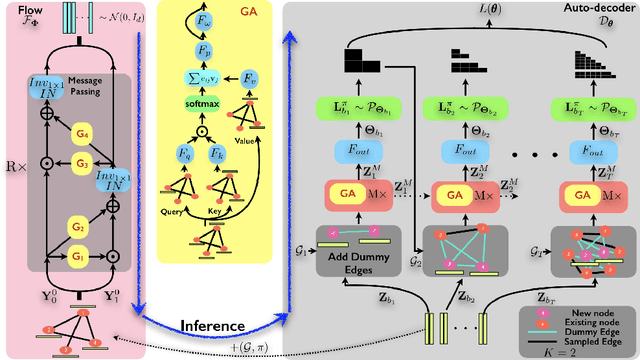
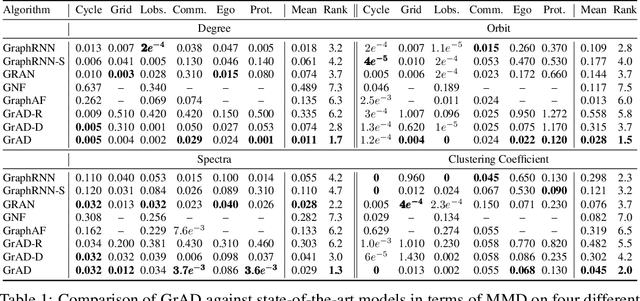
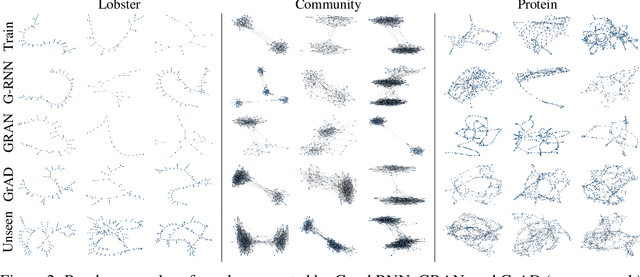
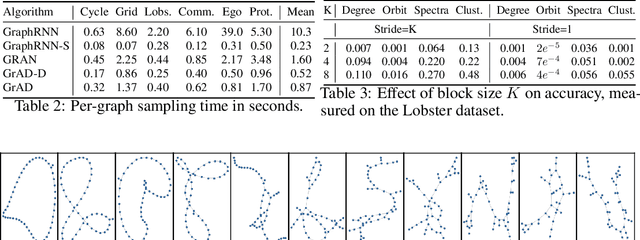
We present an approach to synthesizing new graph structures from empirically specified distributions. The generative model is an auto-decoder that learns to synthesize graphs from latent codes. The graph synthesis model is learned jointly with an empirical distribution over the latent codes. Graphs are synthesized using self-attention modules that are trained to identify likely connectivity patterns. Graph-based normalizing flows are used to sample latent codes from the distribution learned by the auto-decoder. The resulting model combines accuracy and scalability. On benchmark datasets of large graphs, the presented model outperforms the state of the art by a factor of 1.5 in mean accuracy and average rank across at least three different graph statistics, with a 2x speedup during inference.
High-dimensional Convolutional Networks for Geometric Pattern Recognition
May 17, 2020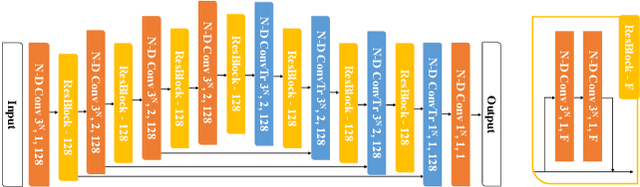

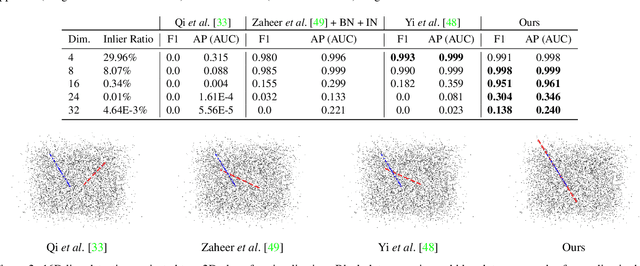
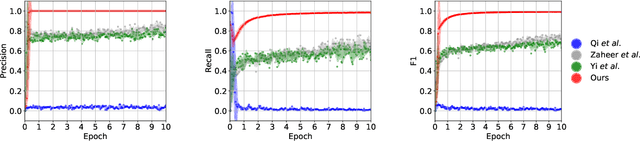
Many problems in science and engineering can be formulated in terms of geometric patterns in high-dimensional spaces. We present high-dimensional convolutional networks (ConvNets) for pattern recognition problems that arise in the context of geometric registration. We first study the effectiveness of convolutional networks in detecting linear subspaces in high-dimensional spaces with up to 32 dimensions: much higher dimensionality than prior applications of ConvNets. We then apply high-dimensional ConvNets to 3D registration under rigid motions and image correspondence estimation. Experiments indicate that our high-dimensional ConvNets outperform prior approaches that relied on deep networks based on global pooling operators.
Deep Global Registration
May 08, 2020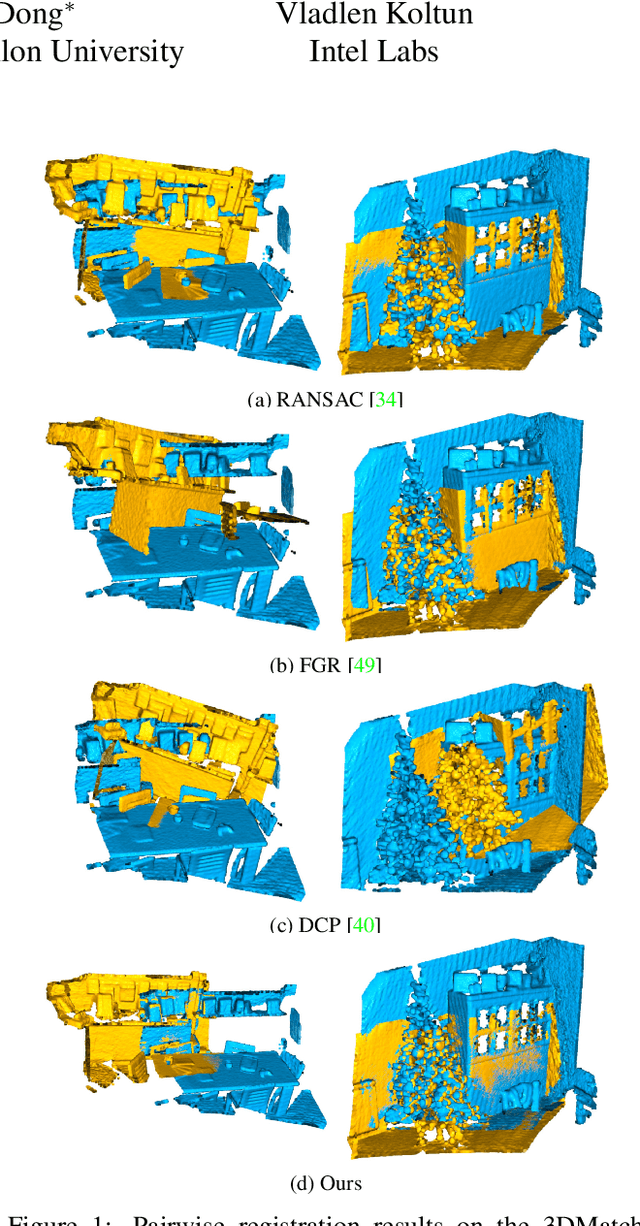
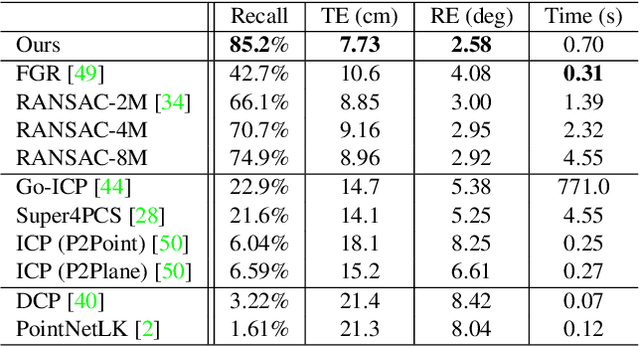
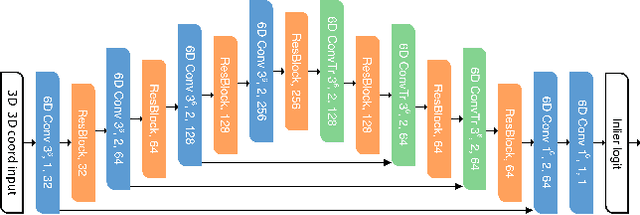

We present Deep Global Registration, a differentiable framework for pairwise registration of real-world 3D scans. Deep global registration is based on three modules: a 6-dimensional convolutional network for correspondence confidence prediction, a differentiable Weighted Procrustes algorithm for closed-form pose estimation, and a robust gradient-based SE(3) optimizer for pose refinement. Experiments demonstrate that our approach outperforms state-of-the-art methods, both learning-based and classical, on real-world data.
Exploring Self-attention for Image Recognition
Apr 28, 2020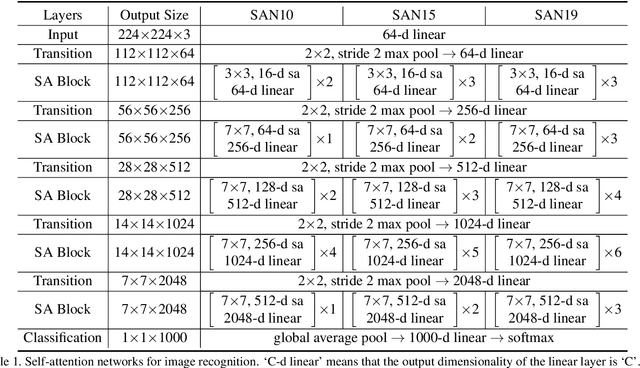
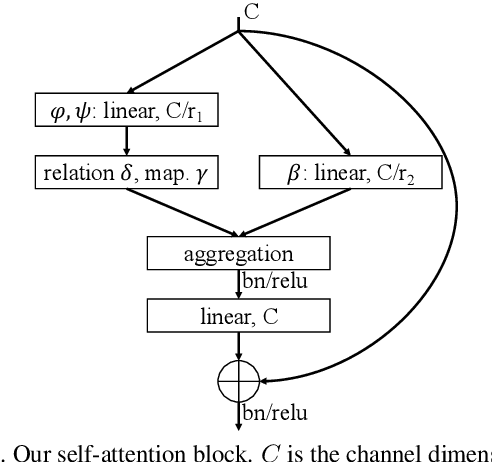


Recent work has shown that self-attention can serve as a basic building block for image recognition models. We explore variations of self-attention and assess their effectiveness for image recognition. We consider two forms of self-attention. One is pairwise self-attention, which generalizes standard dot-product attention and is fundamentally a set operator. The other is patchwise self-attention, which is strictly more powerful than convolution. Our pairwise self-attention networks match or outperform their convolutional counterparts, and the patchwise models substantially outperform the convolutional baselines. We also conduct experiments that probe the robustness of learned representations and conclude that self-attention networks may have significant benefits in terms of robustness and generalization.
Learning to Guide Random Search
Apr 25, 2020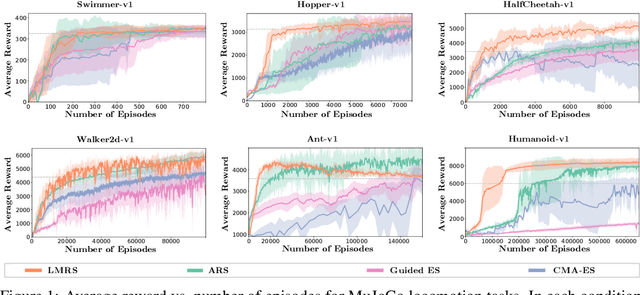
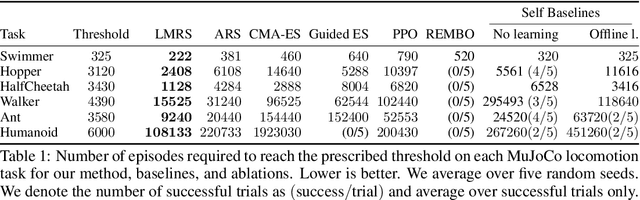
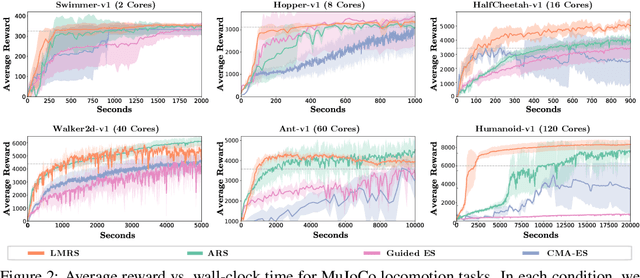

We are interested in derivative-free optimization of high-dimensional functions. The sample complexity of existing methods is high and depends on problem dimensionality, unlike the dimensionality-independent rates of first-order methods. The recent success of deep learning suggests that many datasets lie on low-dimensional manifolds that can be represented by deep nonlinear models. We therefore consider derivative-free optimization of a high-dimensional function that lies on a latent low-dimensional manifold. We develop an online learning approach that learns this manifold while performing the optimization. In other words, we jointly learn the manifold and optimize the function. Our analysis suggests that the presented method significantly reduces sample complexity. We empirically evaluate the method on continuous optimization benchmarks and high-dimensional continuous control problems. Our method achieves significantly lower sample complexity than Augmented Random Search, Bayesian optimization, covariance matrix adaptation (CMA-ES), and other derivative-free optimization algorithms.