 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Humanless Environment Walkthroughs from Egocentric Walking Tour Videos
Mar 30, 2026Egocentric "walking tour" videos provide a rich source of image data to develop rich and diverse visual models of environments around the world. However, the significant presence of humans in frames of these videos due to crowds and eye-level camera perspectives mitigates their usefulness in environment modeling applications. We focus on addressing this challenge by developing a generative algorithm that can realistically remove (i.e., inpaint) humans and their associated shadow effects from walking tour videos. Key to our approach is the construction of a rich semi-synthetic dataset of video clip pairs to train this generative model. Each pair in the dataset consists of an environment-only background clip, and a composite clip of walking humans with simulated shadows overlaid on the background. We randomly sourced both foreground and background components from real egocentric walking tour videos around the world to maintain visual diversity. We then used this dataset to fine-tune the state-of-the-art Casper video diffusion model for object and effects inpainting, and demonstrate that the resulting model performs far better than Casper both qualitatively and quantitatively at removing humans from walking tour clips with significant human presence and complex backgrounds. Finally, we show that the resulting generated clips can be used to build successful 3D/4D models of urban locations.
Compressive Sensing Photoacoustic Imaging Receiver with Matrix-Vector-Multiplication SAR ADC
Nov 09, 2025Wearable photoacoustic imaging devices hold great promise for continuous health monitoring and point-of-care diagnostics. However, the large data volume generated by high-density transducer arrays presents a major challenge for realizing compact and power-efficient wearable systems. This paper presents a photoacoustic imaging receiver (RX) that embeds compressive sensing directly into the hardware to address this bottleneck. The RX integrates 16 AFEs and four matrix-vector-multiplication (MVM) SAR ADCs that perform energy- and area-efficient analog-domain compression. The architecture achieves a 4-8x reduction in output data rate while preserving low-loss full-array information. The MVM SAR ADC executes passive and accurate MVM using user-defined programmable ternary weights. Two signal reconstruction methods are implemented: (1) an optimization approach using the fast iterative shrinkage-thresholding algorithm, and (2) a learning-based approach employing implicit neural representation. Fabricated in 65 nm CMOS, the chip achieves an ADC's SNDR of 57.5 dB at 20.41 MS/s, with an AFE input-referred noise of 3.5 nV/sqrt(Hz). MVM linearity measurements show R^2 > 0.999 across a wide range of weights and input amplitudes. The system is validated through phantom imaging experiments, demonstrating high-fidelity image reconstruction under up to 8x compression. The RX consumes 5.83 mW/channel and supports a general ternary-weighted measurement matrix, offering a compelling solution for next-generation miniaturized, wearable PA imaging systems.
High-Speed Dynamic 3D Imaging with Sensor Fusion Splatting
Feb 07, 2025



Capturing and reconstructing high-speed dynamic 3D scenes has numerous applications in computer graphics, vision, and interdisciplinary fields such as robotics, aerodynamics, and evolutionary biology. However, achieving this using a single imaging modality remains challenging. For instance, traditional RGB cameras suffer from low frame rates, limited exposure times, and narrow baselines. To address this, we propose a novel sensor fusion approach using Gaussian splatting, which combines RGB, depth, and event cameras to capture and reconstruct deforming scenes at high speeds. The key insight of our method lies in leveraging the complementary strengths of these imaging modalities: RGB cameras capture detailed color information, event cameras record rapid scene changes with microsecond resolution, and depth cameras provide 3D scene geometry. To unify the underlying scene representation across these modalities, we represent the scene using deformable 3D Gaussians. To handle rapid scene movements, we jointly optimize the 3D Gaussian parameters and their temporal deformation fields by integrating data from all three sensor modalities. This fusion enables efficient, high-quality imaging of fast and complex scenes, even under challenging conditions such as low light, narrow baselines, or rapid motion. Experiments on synthetic and real datasets captured with our prototype sensor fusion setup demonstrate that our method significantly outperforms state-of-the-art techniques, achieving noticeable improvements in both rendering fidelity and structural accuracy.
Event fields: Capturing light fields at high speed, resolution, and dynamic range
Dec 09, 2024



Event cameras, which feature pixels that independently respond to changes in brightness, are becoming increasingly popular in high-speed applications due to their lower latency, reduced bandwidth requirements, and enhanced dynamic range compared to traditional frame-based cameras. Numerous imaging and vision techniques have leveraged event cameras for high-speed scene understanding by capturing high-framerate, high-dynamic range videos, primarily utilizing the temporal advantages inherent to event cameras. Additionally, imaging and vision techniques have utilized the light field-a complementary dimension to temporal information-for enhanced scene understanding. In this work, we propose "Event Fields", a new approach that utilizes innovative optical designs for event cameras to capture light fields at high speed. We develop the underlying mathematical framework for Event Fields and introduce two foundational frameworks to capture them practically: spatial multiplexing to capture temporal derivatives and temporal multiplexing to capture angular derivatives. To realize these, we design two complementary optical setups one using a kaleidoscope for spatial multiplexing and another using a galvanometer for temporal multiplexing. We evaluate the performance of both designs using a custom-built simulator and real hardware prototypes, showcasing their distinct benefits. Our event fields unlock the full advantages of typical light fields-like post-capture refocusing and depth estimation-now supercharged for high-speed and high-dynamic range scenes. This novel light-sensing paradigm opens doors to new applications in photography, robotics, and AR/VR, and presents fresh challenges in rendering and machine learning.
Streaming quanta sensors for online, high-performance imaging and vision
Jun 02, 2024



Recently quanta image sensors (QIS) -- ultra-fast, zero-read-noise binary image sensors -- have demonstrated remarkable imaging capabilities in many challenging scenarios. Despite their potential, the adoption of these sensors is severely hampered by (a) high data rates and (b) the need for new computational pipelines to handle the unconventional raw data. We introduce a simple, low-bandwidth computational pipeline to address these challenges. Our approach is based on a novel streaming representation with a small memory footprint, efficiently capturing intensity information at multiple temporal scales. Updating the representation requires only 16 floating-point operations/pixel, which can be efficiently computed online at the native frame rate of the binary frames. We use a neural network operating on this representation to reconstruct videos in real-time (10-30 fps). We illustrate why such representation is well-suited for these emerging sensors, and how it offers low latency and high frame rate while retaining flexibility for downstream computer vision. Our approach results in significant data bandwidth reductions ~100X and real-time image reconstruction and computer vision -- $10^4$-$10^5$ reduction in computation than existing state-of-the-art approach while maintaining comparable quality. To the best of our knowledge, our approach is the first to achieve online, real-time image reconstruction on QIS.
Passive Snapshot Coded Aperture Dual-Pixel RGB-D Imaging
Feb 28, 2024



Passive, compact, single-shot 3D sensing is useful in many application areas such as microscopy, medical imaging, surgical navigation, and autonomous driving where form factor, time, and power constraints can exist. Obtaining RGB-D scene information over a short imaging distance, in an ultra-compact form factor, and in a passive, snapshot manner is challenging. Dual-pixel (DP) sensors are a potential solution to achieve the same. DP sensors collect light rays from two different halves of the lens in two interleaved pixel arrays, thus capturing two slightly different views of the scene, like a stereo camera system. However, imaging with a DP sensor implies that the defocus blur size is directly proportional to the disparity seen between the views. This creates a trade-off between disparity estimation vs. deblurring accuracy. To improve this trade-off effect, we propose CADS (Coded Aperture Dual-Pixel Sensing), in which we use a coded aperture in the imaging lens along with a DP sensor. In our approach, we jointly learn an optimal coded pattern and the reconstruction algorithm in an end-to-end optimization setting. Our resulting CADS imaging system demonstrates improvement of $>$1.5dB PSNR in all-in-focus (AIF) estimates and 5-6% in depth estimation quality over naive DP sensing for a wide range of aperture settings. Furthermore, we build the proposed CADS prototypes for DSLR photography settings and in an endoscope and a dermoscope form factor. Our novel coded dual-pixel sensing approach demonstrates accurate RGB-D reconstruction results in simulations and real-world experiments in a passive, snapshot, and compact manner.
NeRT: Implicit Neural Representations for General Unsupervised Turbulence Mitigation
Aug 01, 2023The atmospheric and water turbulence mitigation problems have emerged as challenging inverse problems in computer vision and optics communities over the years. However, current methods either rely heavily on the quality of the training dataset or fail to generalize over various scenarios, such as static scenes, dynamic scenes, and text reconstructions. We propose a general implicit neural representation for unsupervised atmospheric and water turbulence mitigation (NeRT). NeRT leverages the implicit neural representations and the physically correct tilt-then-blur turbulence model to reconstruct the clean, undistorted image, given only dozens of distorted input images. Moreover, we show that NeRT outperforms the state-of-the-art through various qualitative and quantitative evaluations of atmospheric and water turbulence datasets. Furthermore, we demonstrate the ability of NeRT to eliminate uncontrolled turbulence from real-world environments. Lastly, we incorporate NeRT into continuously captured video sequences and demonstrate $48 \times$ speedup.
Foveated Thermal Computational Imaging in the Wild Using All-Silicon Meta-Optics
Dec 13, 2022Foveated imaging provides a better tradeoff between situational awareness (field of view) and resolution and is critical in long-wavelength infrared regimes because of the size, weight, power, and cost of thermal sensors. We demonstrate computational foveated imaging by exploiting the ability of a meta-optical frontend to discriminate between different polarization states and a computational backend to reconstruct the captured image/video. The frontend is a three-element optic: the first element which we call the "foveal" element is a metalens that focuses s-polarized light at a distance of $f_1$ without affecting the p-polarized light; the second element which we call the "perifoveal" element is another metalens that focuses p-polarized light at a distance of $f_2$ without affecting the s-polarized light. The third element is a freely rotating polarizer that dynamically changes the mixing ratios between the two polarization states. Both the foveal element (focal length = 150mm; diameter = 75mm), and the perifoveal element (focal length = 25mm; diameter = 25mm) were fabricated as polarization-sensitive, all-silicon, meta surfaces resulting in a large-aperture, 1:6 foveal expansion, thermal imaging capability. A computational backend then utilizes a deep image prior to separate the resultant multiplexed image or video into a foveated image consisting of a high-resolution center and a lower-resolution large field of view context. We build a first-of-its-kind prototype system and demonstrate 12 frames per second real-time, thermal, foveated image, and video capture in the wild.
FlatNet: Towards Photorealistic Scene Reconstruction from Lensless Measurements
Oct 29, 2020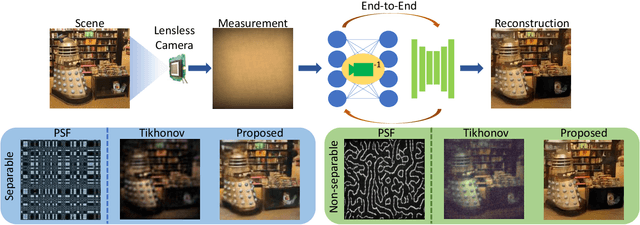

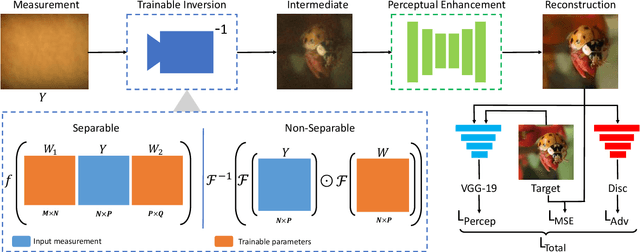
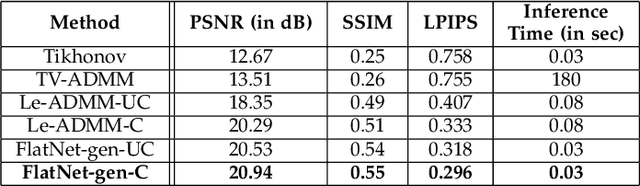
Lensless imaging has emerged as a potential solution towards realizing ultra-miniature cameras by eschewing the bulky lens in a traditional camera. Without a focusing lens, the lensless cameras rely on computational algorithms to recover the scenes from multiplexed measurements. However, the current iterative-optimization-based reconstruction algorithms produce noisier and perceptually poorer images. In this work, we propose a non-iterative deep learning based reconstruction approach that results in orders of magnitude improvement in image quality for lensless reconstructions. Our approach, called $\textit{FlatNet}$, lays down a framework for reconstructing high-quality photorealistic images from mask-based lensless cameras, where the camera's forward model formulation is known. FlatNet consists of two stages: (1) an inversion stage that maps the measurement into a space of intermediate reconstruction by learning parameters within the forward model formulation, and (2) a perceptual enhancement stage that improves the perceptual quality of this intermediate reconstruction. These stages are trained together in an end-to-end manner. We show high-quality reconstructions by performing extensive experiments on real and challenging scenes using two different types of lensless prototypes: one which uses a separable forward model and another, which uses a more general non-separable cropped-convolution model. Our end-to-end approach is fast, produces photorealistic reconstructions, and is easy to adopt for other mask-based lensless cameras.