 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDEMapper: Enhancing NIH Common Data Element Normalization using Large Language Models
Nov 30, 2024Common Data Elements (CDEs) standardize data collection and sharing across studies, enhancing data interoperability and improving research reproducibility. However, implementing CDEs presents challenges due to the broad range and variety of data elements. This study aims to develop an effective and efficient mapping tool to bridge the gap between local data elements and National Institutes of Health (NIH) CDEs. We propose CDEMapper, a large language model (LLM) powered mapping tool designed to assist in mapping local data elements to NIH CDEs. CDEMapper has three core modules: (1) CDE indexing and embeddings. NIH CDEs were indexed and embedded to support semantic search; (2) CDE recommendations. The tool combines Elasticsearch (BM25 similarity methods) with state of the art GPT services to recommend candidate CDEs and their permissible values; and (3) Human review. Users review and select the NIH CDEs and values that best match their data elements and value sets. We evaluate the tool recommendation accuracy against manually annotated mapping results. CDEMapper offers a publicly available, LLM-powered, and intuitive user interface that consolidates essential and advanced mapping services into a streamlined pipeline. It provides a step by step, quality assured mapping workflow designed with a user-centered approach. The evaluation results demonstrated that augmenting BM25 with GPT embeddings and a ranker consistently enhances CDEMapper mapping accuracy in three different mapping settings across four evaluation datasets. This work opens up the potential of using LLMs to assist with CDE recommendation and human curation when aligning local data elements with NIH CDEs. Additionally, this effort enhances clinical research data interoperability and helps researchers better understand the gaps between local data elements and NIH CDEs.
Generalizable Cross-Graph Embedding for GNN-based Congestion Prediction
Nov 10, 2021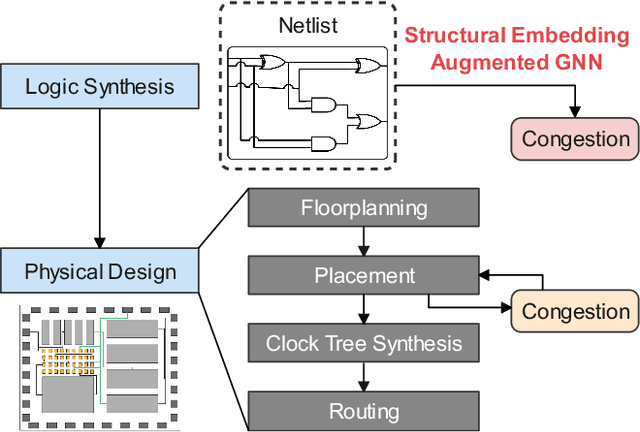
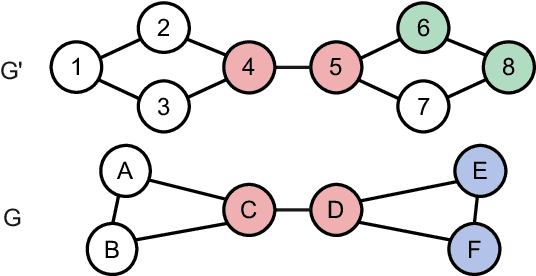
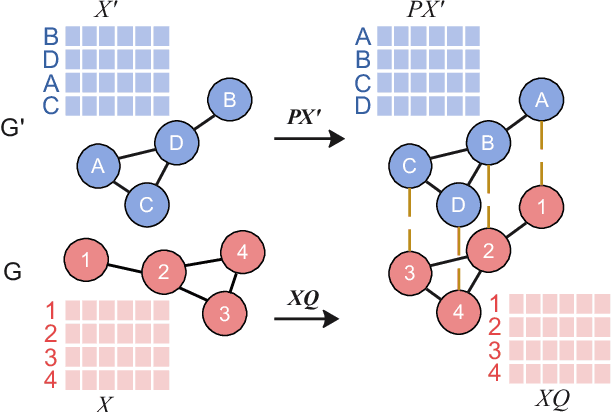
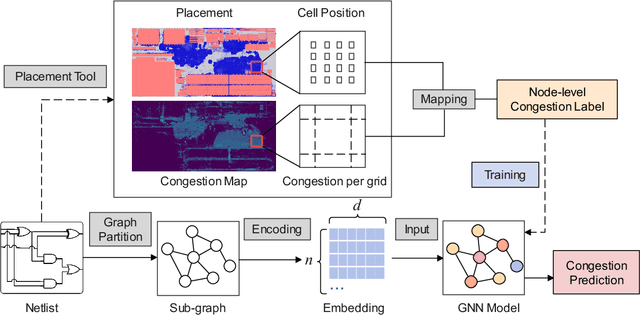
Presently with technology node scaling, an accurate prediction model at early design stages can significantly reduce the design cycle. Especially during logic synthesis, predicting cell congestion due to improper logic combination can reduce the burden of subsequent physical implementations. There have been attempts using Graph Neural Network (GNN) techniques to tackle congestion prediction during the logic synthesis stage. However, they require informative cell features to achieve reasonable performance since the core idea of GNNs is built on the message passing framework, which would be impractical at the early logic synthesis stage. To address this limitation, we propose a framework that can directly learn embeddings for the given netlist to enhance the quality of our node features. Popular random-walk based embedding methods such as Node2vec, LINE, and DeepWalk suffer from the issue of cross-graph alignment and poor generalization to unseen netlist graphs, yielding inferior performance and costing significant runtime. In our framework, we introduce a superior alternative to obtain node embeddings that can generalize across netlist graphs using matrix factorization methods. We propose an efficient mini-batch training method at the sub-graph level that can guarantee parallel training and satisfy the memory restriction for large-scale netlists. We present results utilizing open-source EDA tools such as DREAMPLACE and OPENROAD frameworks on a variety of openly available circuits. By combining the learned embedding on top of the netlist with the GNNs, our method improves prediction performance, generalizes to new circuit lines, and is efficient in training, potentially saving over $90 \%$ of runtime.
CoSQL: A Conversational Text-to-SQL Challenge Towards Cross-Domain Natural Language Interfaces to Databases
Sep 11, 2019
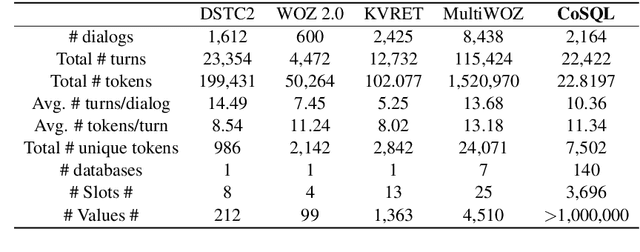
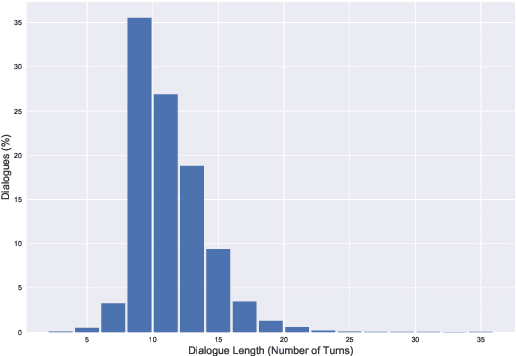
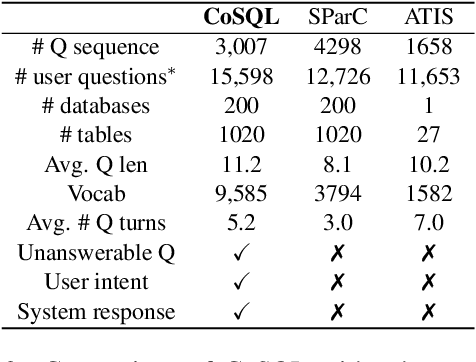
We present CoSQL, a corpus for building cross-domain, general-purpose database (DB) querying dialogue systems. It consists of 30k+ turns plus 10k+ annotated SQL queries, obtained from a Wizard-of-Oz (WOZ) collection of 3k dialogues querying 200 complex DBs spanning 138 domains. Each dialogue simulates a real-world DB query scenario with a crowd worker as a user exploring the DB and a SQL expert retrieving answers with SQL, clarifying ambiguous questions, or otherwise informing of unanswerable questions. When user questions are answerable by SQL, the expert describes the SQL and execution results to the user, hence maintaining a natural interaction flow. CoSQL introduces new challenges compared to existing task-oriented dialogue datasets:(1) the dialogue states are grounded in SQL, a domain-independent executable representation, instead of domain-specific slot-value pairs, and (2) because testing is done on unseen databases, success requires generalizing to new domains. CoSQL includes three tasks: SQL-grounded dialogue state tracking, response generation from query results, and user dialogue act prediction. We evaluate a set of strong baselines for each task and show that CoSQL presents significant challenges for future research. The dataset, baselines, and leaderboard will be released at https://yale-lily.github.io/cosql.
SParC: Cross-Domain Semantic Parsing in Context
Jun 05, 2019
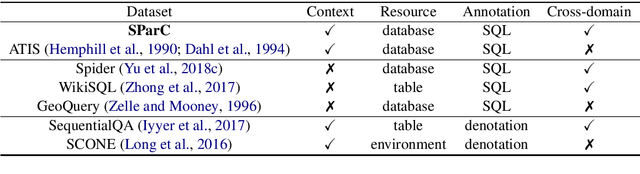

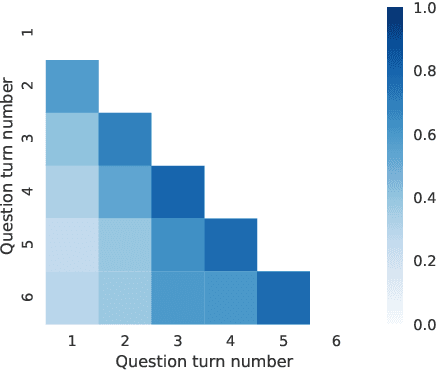
We present SParC, a dataset for cross-domainSemanticParsing inContext that consists of 4,298 coherent question sequences (12k+ individual questions annotated with SQL queries). It is obtained from controlled user interactions with 200 complex databases over 138 domains. We provide an in-depth analysis of SParC and show that it introduces new challenges compared to existing datasets. SParC demonstrates complex contextual dependencies, (2) has greater semantic diversity, and (3) requires generalization to unseen domains due to its cross-domain nature and the unseen databases at test time. We experiment with two state-of-the-art text-to-SQL models adapted to the context-dependent, cross-domain setup. The best model obtains an exact match accuracy of 20.2% over all questions and less than10% over all interaction sequences, indicating that the cross-domain setting and the con-textual phenomena of the dataset present significant challenges for future research. The dataset, baselines, and leaderboard are released at https://yale-lily.github.io/sparc.