 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Best Arm Identification with Heterogeneous Clients
Oct 17, 2022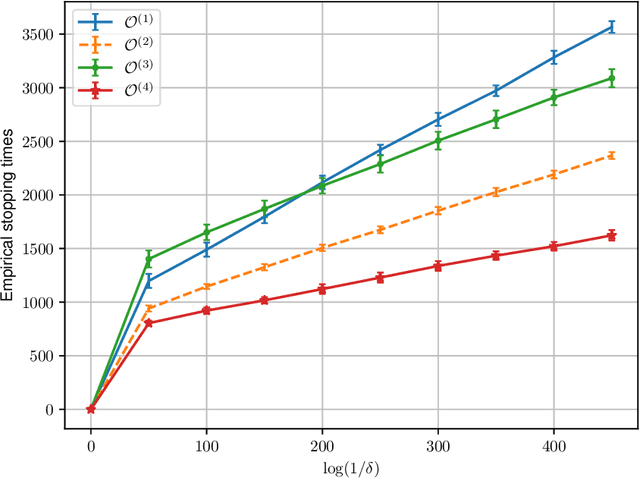
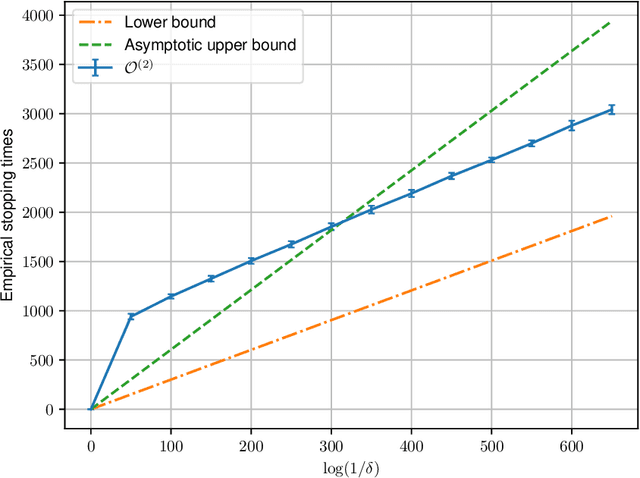
We study best arm identification in a federated multi-armed bandit setting with a central server and multiple clients, when each client has access to a {\em subset} of arms and each arm yields independent Gaussian observations. The {\em reward} from an arm at any given time is defined as the average of the observations generated at this time across all the clients that have access to the arm. The end goal is to identify the best arm (the arm with the largest mean reward) of each client with the least expected stopping time, subject to an upper bound on the error probability (i.e., the {\em fixed-confidence regime}). We provide a lower bound on the growth rate of the expected time to find the best arm of each client. Furthermore, we show that for any algorithm whose upper bound on the expected time to find the best arms matches with the lower bound up to a multiplicative constant, the ratio of any two consecutive communication time instants must be bounded, a result that is of independent interest. We then provide the first-known lower bound on the expected number of {\em communication rounds} required to find the best arms. We propose a novel algorithm based on the well-known {\em Track-and-Stop} strategy that communicates only at exponential time instants, and derive asymptotic upper bounds on its expected time to find the best arms and the expected number of communication rounds, where the asymptotics is one of vanishing error probabilities.
How Does Pseudo-Labeling Affect the Generalization Error of the Semi-Supervised Gibbs Algorithm?
Oct 15, 2022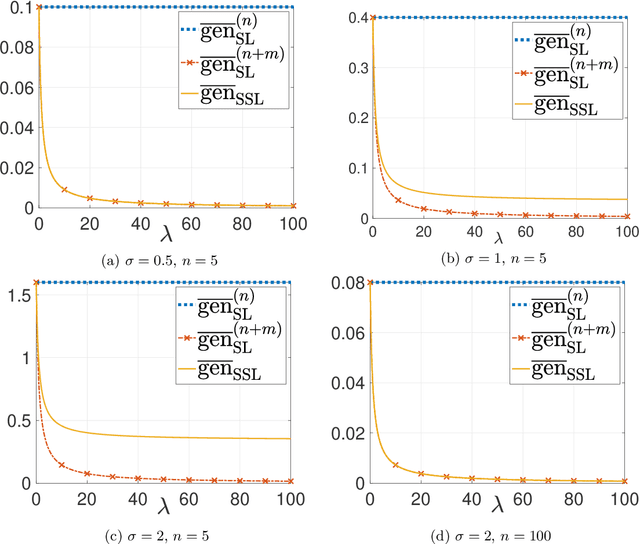
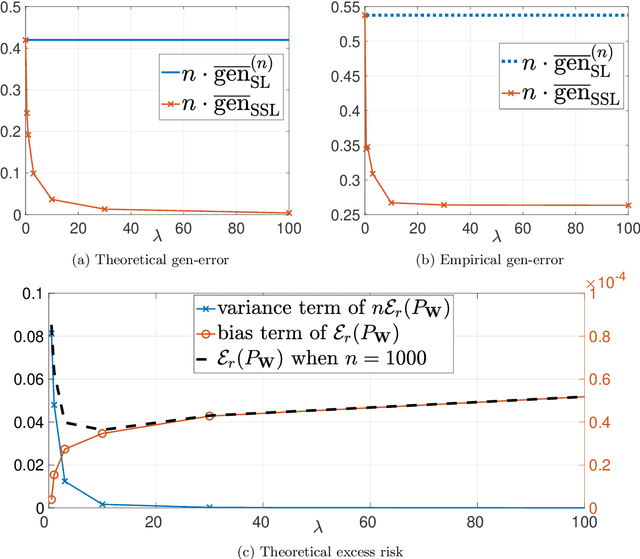
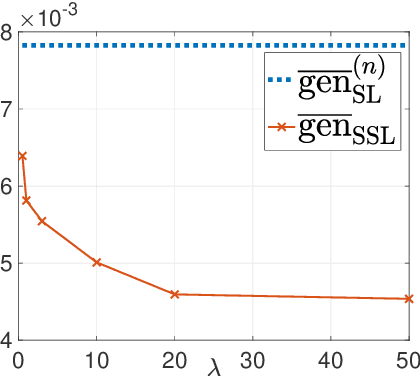
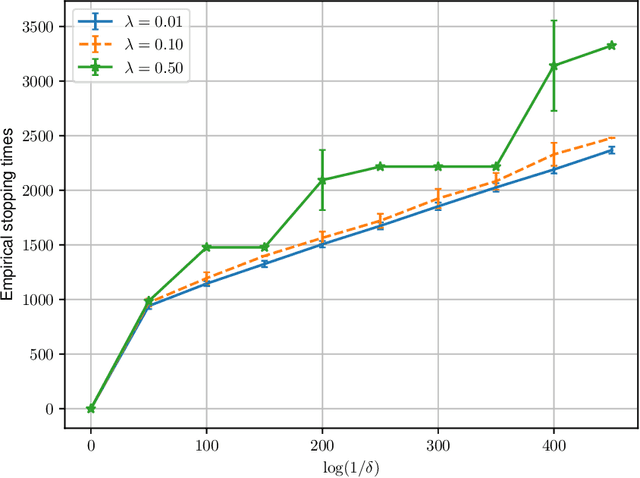
This paper provides an exact characterization of the expected generalization error (gen-error) for semi-supervised learning (SSL) with pseudo-labeling via the Gibbs algorithm. This characterization is expressed in terms of the symmetrized KL information between the output hypothesis, the pseudo-labeled dataset, and the labeled dataset. It can be applied to obtain distribution-free upper and lower bounds on the gen-error. Our findings offer new insights that the generalization performance of SSL with pseudo-labeling is affected not only by the information between the output hypothesis and input training data but also by the information {\em shared} between the {\em labeled} and {\em pseudo-labeled} data samples. To deepen our understanding, we further explore two examples -- mean estimation and logistic regression. In particular, we analyze how the ratio of the number of unlabeled to labeled data $\lambda$ affects the gen-error under both scenarios. As $\lambda$ increases, the gen-error for mean estimation decreases and then saturates at a value larger than when all the samples are labeled, and the gap can be quantified {\em exactly} with our analysis, and is dependent on the \emph{cross-covariance} between the labeled and pseudo-labeled data sample. In logistic regression, the gen-error and the variance component of the excess risk also decrease as $\lambda$ increases.
Towards Understanding and Mitigating Dimensional Collapse in Heterogeneous Federated Learning
Oct 01, 2022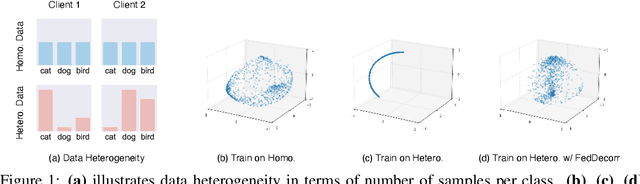
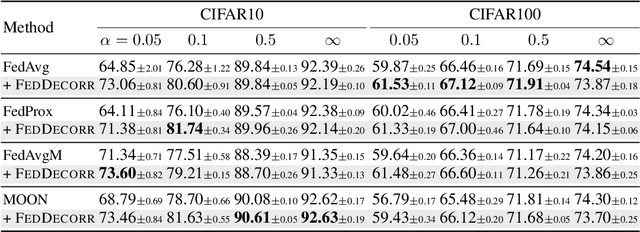
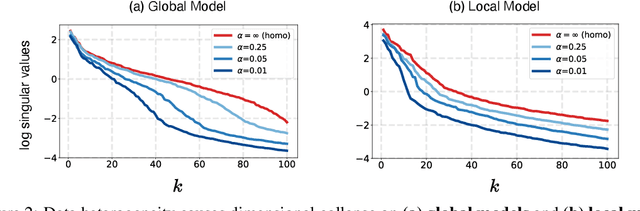
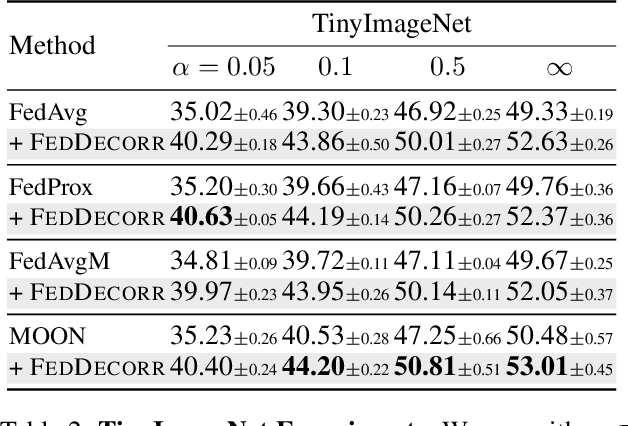
Federated learning aims to train models collaboratively across different clients without the sharing of data for privacy considerations. However, one major challenge for this learning paradigm is the {\em data heterogeneity} problem, which refers to the discrepancies between the local data distributions among various clients. To tackle this problem, we first study how data heterogeneity affects the representations of the globally aggregated models. Interestingly, we find that heterogeneous data results in the global model suffering from severe {\em dimensional collapse}, in which representations tend to reside in a lower-dimensional space instead of the ambient space. Moreover, we observe a similar phenomenon on models locally trained on each client and deduce that the dimensional collapse on the global model is inherited from local models. In addition, we theoretically analyze the gradient flow dynamics to shed light on how data heterogeneity result in dimensional collapse for local models. To remedy this problem caused by the data heterogeneity, we propose {\sc FedDecorr}, a novel method that can effectively mitigate dimensional collapse in federated learning. Specifically, {\sc FedDecorr} applies a regularization term during local training that encourages different dimensions of representations to be uncorrelated. {\sc FedDecorr}, which is implementation-friendly and computationally-efficient, yields consistent improvements over baselines on standard benchmark datasets. Code will be released.
Relational Reasoning via Set Transformers: Provable Efficiency and Applications to MARL
Sep 26, 2022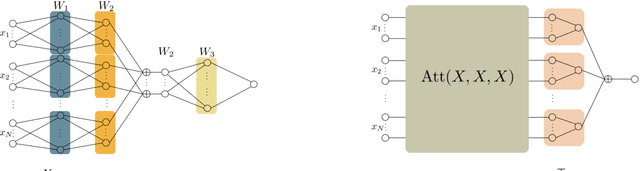
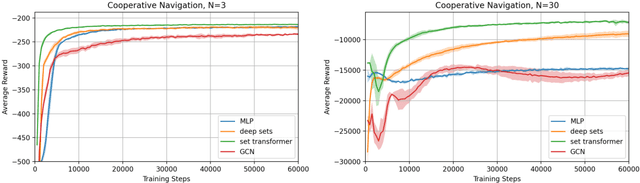
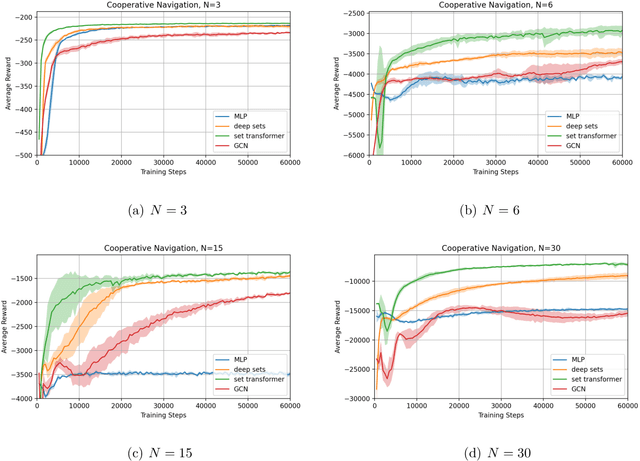
The cooperative Multi-A gent R einforcement Learning (MARL) with permutation invariant agents framework has achieved tremendous empirical successes in real-world applications. Unfortunately, the theoretical understanding of this MARL problem is lacking due to the curse of many agents and the limited exploration of the relational reasoning in existing works. In this paper, we verify that the transformer implements complex relational reasoning, and we propose and analyze model-free and model-based offline MARL algorithms with the transformer approximators. We prove that the suboptimality gaps of the model-free and model-based algorithms are independent of and logarithmic in the number of agents respectively, which mitigates the curse of many agents. These results are consequences of a novel generalization error bound of the transformer and a novel analysis of the Maximum Likelihood Estimate (MLE) of the system dynamics with the transformer. Our model-based algorithm is the first provably efficient MARL algorithm that explicitly exploits the permutation invariance of the agents.
Almost Cost-Free Communication in Federated Best Arm Identification
Aug 19, 2022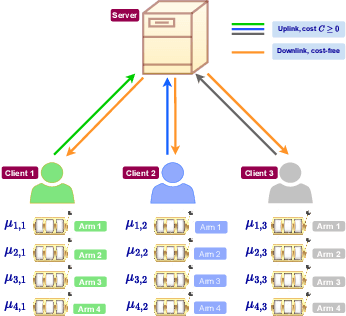

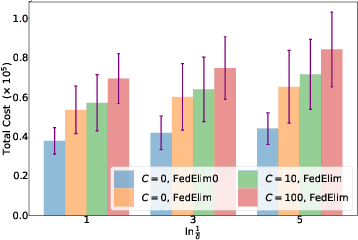
We study the problem of best arm identification in a federated learning multi-armed bandit setup with a central server and multiple clients. Each client is associated with a multi-armed bandit in which each arm yields {\em i.i.d.}\ rewards following a Gaussian distribution with an unknown mean and known variance. The set of arms is assumed to be the same at all the clients. We define two notions of best arm -- local and global. The local best arm at a client is the arm with the largest mean among the arms local to the client, whereas the global best arm is the arm with the largest average mean across all the clients. We assume that each client can only observe the rewards from its local arms and thereby estimate its local best arm. The clients communicate with a central server on uplinks that entail a cost of $C\ge0$ units per usage per uplink. The global best arm is estimated at the server. The goal is to identify the local best arms and the global best arm with minimal total cost, defined as the sum of the total number of arm selections at all the clients and the total communication cost, subject to an upper bound on the error probability. We propose a novel algorithm {\sc FedElim} that is based on successive elimination and communicates only in exponential time steps and obtain a high probability instance-dependent upper bound on its total cost. The key takeaway from our paper is that for any $C\geq 0$ and error probabilities sufficiently small, the total number of arm selections (resp.\ the total cost) under {\sc FedElim} is at most~$2$ (resp.~$3$) times the maximum total number of arm selections under its variant that communicates in every time step. Additionally, we show that the latter is optimal in expectation up to a constant factor, thereby demonstrating that communication is almost cost-free in {\sc FedElim}. We numerically validate the efficacy of {\sc FedElim}.
Asymptotic Nash Equilibrium for the $M$-ary Sequential Adversarial Hypothesis Testing Game
Jun 20, 2022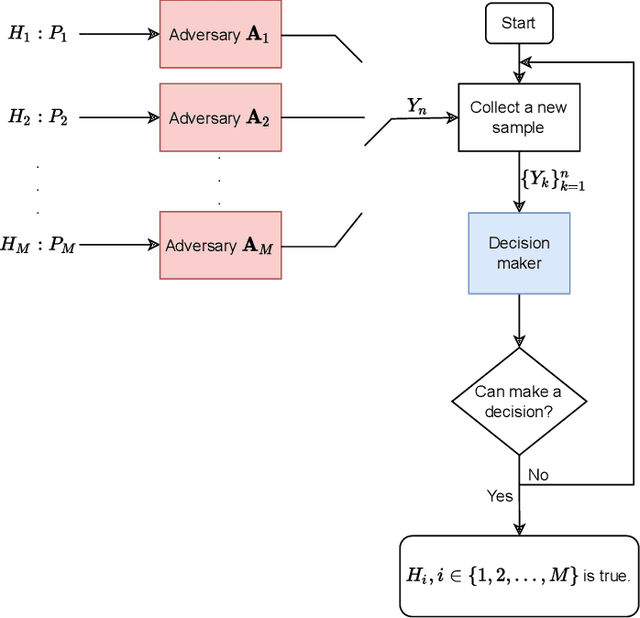
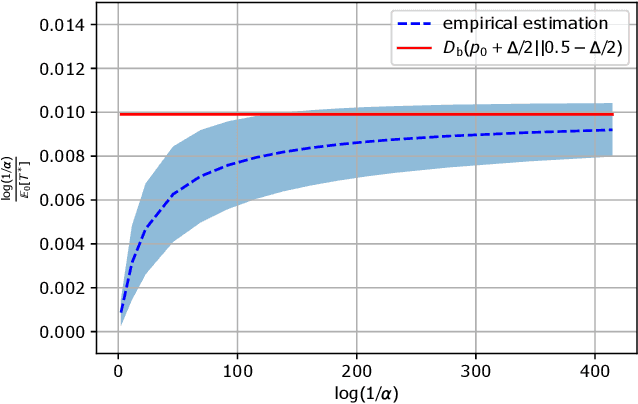
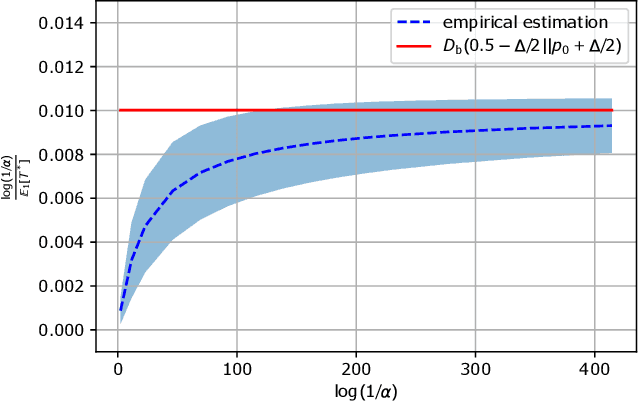
In this paper, we consider a novel $M$-ary sequential hypothesis testing problem in which an adversary is present and perturbs the distributions of the samples before the decision maker observes them. This problem is formulated as a sequential adversarial hypothesis testing game played between the decision maker and the adversary. This game is a zero-sum and strategic one. We assume the adversary is active under \emph{all} hypotheses and knows the underlying distribution of observed samples. We adopt this framework as it is the worst-case scenario from the perspective of the decision maker. The goal of the decision maker is to minimize the expectation of the stopping time to ensure that the test is as efficient as possible; the adversary's goal is, instead, to maximize the stopping time. We derive a pair of strategies under which the asymptotic Nash equilibrium of the game is attained. We also consider the case in which the adversary is not aware of the underlying hypothesis and hence is constrained to apply the same strategy regardless of which hypothesis is in effect. Numerical results corroborate our theoretical findings.
Sharpness-Aware Training for Free
May 30, 2022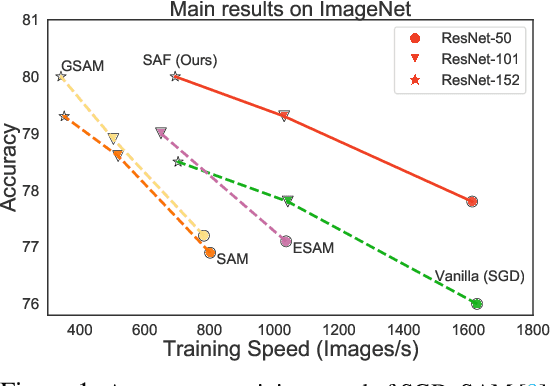
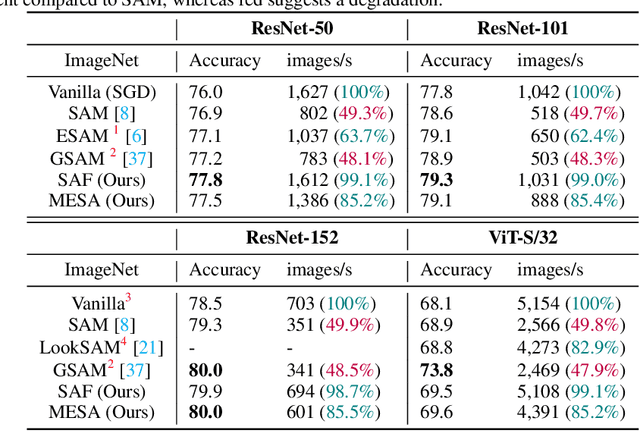

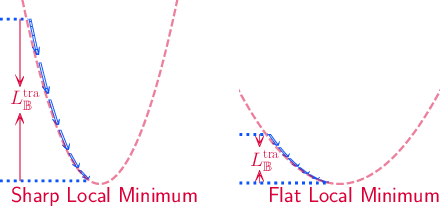
Modern deep neural networks (DNNs) have achieved state-of-the-art performances but are typically over-parameterized. The over-parameterization may result in undesirably large generalization error in the absence of other customized training strategies. Recently, a line of research under the name of Sharpness-Aware Minimization (SAM) has shown that minimizing a sharpness measure, which reflects the geometry of the loss landscape, can significantly reduce the generalization error. However, SAM-like methods incur a two-fold computational overhead of the given base optimizer (e.g. SGD) for approximating the sharpness measure. In this paper, we propose Sharpness-Aware Training for Free, or SAF, which mitigates the sharp landscape at almost zero additional computational cost over the base optimizer. Intuitively, SAF achieves this by avoiding sudden drops in the loss in the sharp local minima throughout the trajectory of the updates of the weights. Specifically, we suggest a novel trajectory loss, based on the KL-divergence between the outputs of DNNs with the current weights and past weights, as a replacement of the SAM's sharpness measure. This loss captures the rate of change of the training loss along the model's update trajectory. By minimizing it, SAF ensures the convergence to a flat minimum with improved generalization capabilities. Extensive empirical results show that SAF minimizes the sharpness in the same way that SAM does, yielding better results on the ImageNet dataset with essentially the same computational cost as the base optimizer.
A Survey of Risk-Aware Multi-Armed Bandits
May 12, 2022In several applications such as clinical trials and financial portfolio optimization, the expected value (or the average reward) does not satisfactorily capture the merits of a drug or a portfolio. In such applications, risk plays a crucial role, and a risk-aware performance measure is preferable, so as to capture losses in the case of adverse events. This survey aims to consolidate and summarise the existing research on risk measures, specifically in the context of multi-armed bandits. We review various risk measures of interest, and comment on their properties. Next, we review existing concentration inequalities for various risk measures. Then, we proceed to defining risk-aware bandit problems, We consider algorithms for the regret minimization setting, where the exploration-exploitation trade-off manifests, as well as the best-arm identification setting, which is a pure exploration problem -- both in the context of risk-sensitive measures. We conclude by commenting on persisting challenges and fertile areas for future research.
Best Arm Identification in Restless Markov Multi-Armed Bandits
Mar 29, 2022We study the problem of identifying the best arm in a multi-armed bandit environment when each arm is a time-homogeneous and ergodic discrete-time Markov process on a common, finite state space. The state evolution on each arm is governed by the arm's transition probability matrix (TPM). A decision entity that knows the set of arm TPMs but not the exact mapping of the TPMs to the arms, wishes to find the index of the best arm as quickly as possible, subject to an upper bound on the error probability. The decision entity selects one arm at a time sequentially, and all the unselected arms continue to undergo state evolution ({\em restless} arms). For this problem, we derive the first-known problem instance-dependent asymptotic lower bound on the growth rate of the expected time required to find the index of the best arm, where the asymptotics is as the error probability vanishes. Further, we propose a sequential policy that, for an input parameter $R$, forcibly selects an arm that has not been selected for $R$ consecutive time instants. We show that this policy achieves an upper bound that depends on $R$ and is monotonically non-increasing as $R\to\infty$. The question of whether, in general, the limiting value of the upper bound as $R\to\infty$ matches with the lower bound, remains open. We identify a special case in which the upper and the lower bounds match. Prior works on best arm identification have dealt with (a) independent and identically distributed observations from the arms, and (b) rested Markov arms, whereas our work deals with the more difficult setting of restless Markov arms.
Optimal Clustering with Bandit Feedback
Feb 09, 2022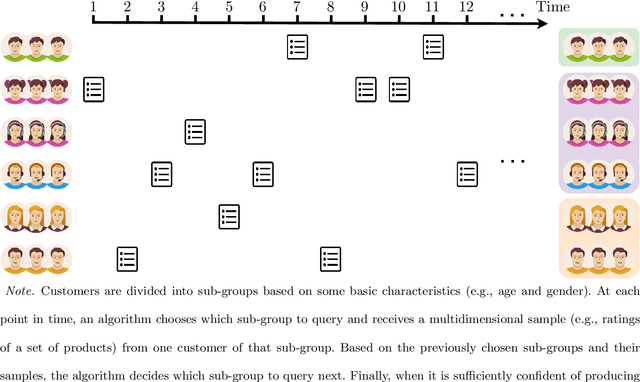
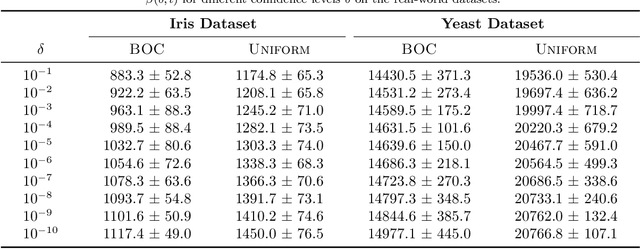
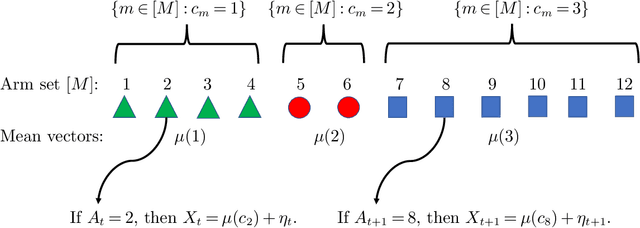
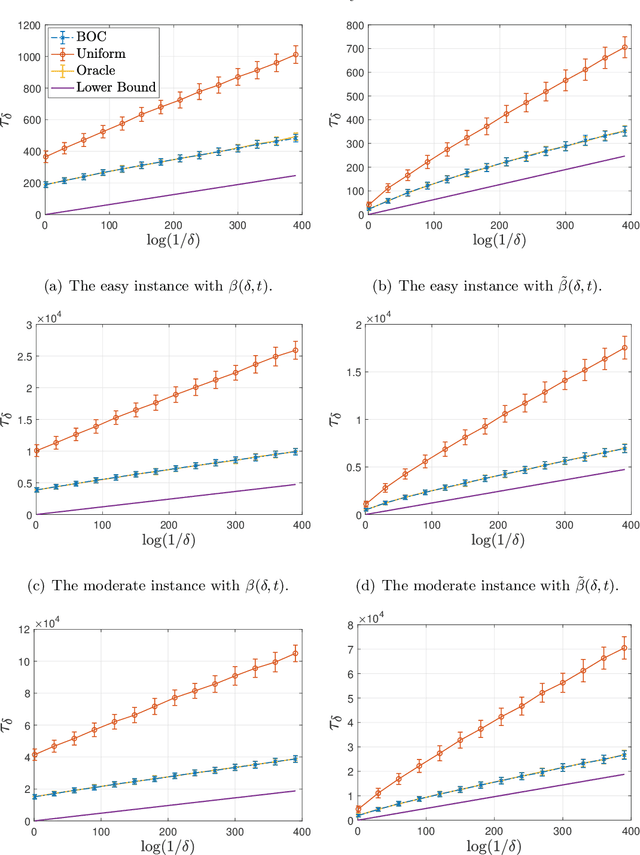
This paper considers the problem of online clustering with bandit feedback. A set of arms (or items) can be partitioned into various groups that are unknown. Within each group, the observations associated to each of the arms follow the same distribution with the same mean vector. At each time step, the agent queries or pulls an arm and obtains an independent observation from the distribution it is associated to. Subsequent pulls depend on previous ones as well as the previously obtained samples. The agent's task is to uncover the underlying partition of the arms with the least number of arm pulls and with a probability of error not exceeding a prescribed constant $\delta$. The problem proposed finds numerous applications from clustering of variants of viruses to online market segmentation. We present an instance-dependent information-theoretic lower bound on the expected sample complexity for this task, and design a computationally efficient and asymptotically optimal algorithm, namely Bandit Online Clustering (BOC). The algorithm includes a novel stopping rule for adaptive sequential testing that circumvents the need to exactly solve any NP-hard weighted clustering problem as its subroutines. We show through extensive simulations on synthetic and real-world datasets that BOC's performance matches the lower bound asymptotically, and significantly outperforms a non-adaptive baseline algorithm.