 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Reinforcement Learning Chatbot
Nov 05, 2017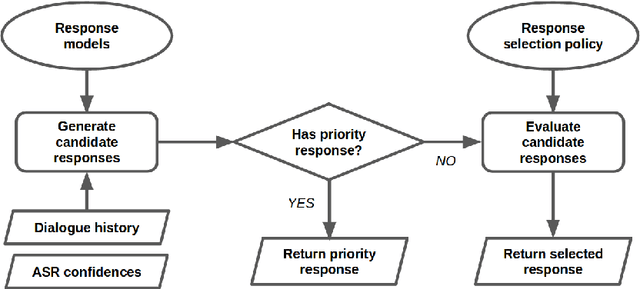
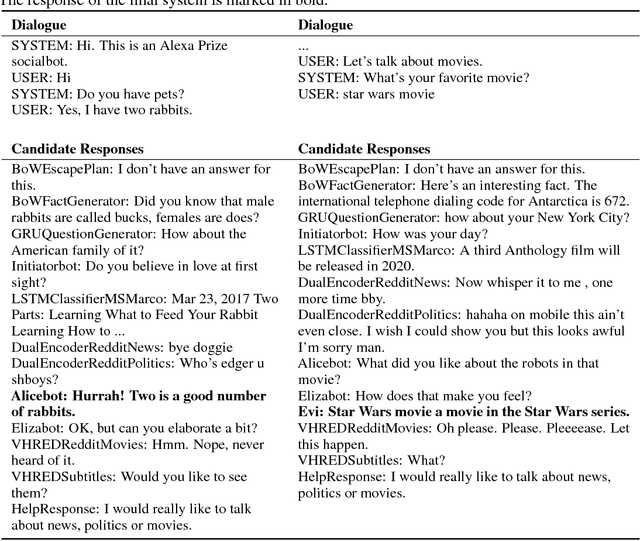
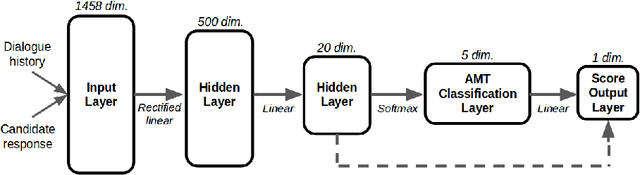

We present MILABOT: a deep reinforcement learning chatbot developed by the Montreal Institute for Learning Algorithms (MILA) for the Amazon Alexa Prize competition. MILABOT is capable of conversing with humans on popular small talk topics through both speech and text. The system consists of an ensemble of natural language generation and retrieval models, including template-based models, bag-of-words models, sequence-to-sequence neural network and latent variable neural network models. By applying reinforcement learning to crowdsourced data and real-world user interactions, the system has been trained to select an appropriate response from the models in its ensemble. The system has been evaluated through A/B testing with real-world users, where it performed significantly better than many competing systems. Due to its machine learning architecture, the system is likely to improve with additional data.
The "something something" video database for learning and evaluating visual common sense
Jun 15, 2017
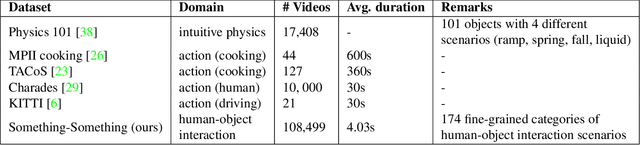

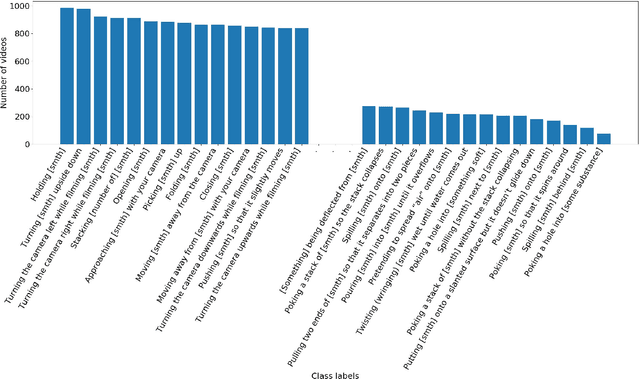
Neural networks trained on datasets such as ImageNet have led to major advances in visual object classification. One obstacle that prevents networks from reasoning more deeply about complex scenes and situations, and from integrating visual knowledge with natural language, like humans do, is their lack of common sense knowledge about the physical world. Videos, unlike still images, contain a wealth of detailed information about the physical world. However, most labelled video datasets represent high-level concepts rather than detailed physical aspects about actions and scenes. In this work, we describe our ongoing collection of the "something-something" database of video prediction tasks whose solutions require a common sense understanding of the depicted situation. The database currently contains more than 100,000 videos across 174 classes, which are defined as caption-templates. We also describe the challenges in crowd-sourcing this data at scale.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
RATM: Recurrent Attentive Tracking Model
Apr 28, 2016
We present an attention-based modular neural framework for computer vision. The framework uses a soft attention mechanism allowing models to be trained with gradient descent. It consists of three modules: a recurrent attention module controlling where to look in an image or video frame, a feature-extraction module providing a representation of what is seen, and an objective module formalizing why the model learns its attentive behavior. The attention module allows the model to focus computation on task-related information in the input. We apply the framework to several object tracking tasks and explore various design choices. We experiment with three data sets, bouncing ball, moving digits and the real-world KTH data set. The proposed Recurrent Attentive Tracking Model performs well on all three tasks and can generalize to related but previously unseen sequences from a challenging tracking data set.
EmoNets: Multimodal deep learning approaches for emotion recognition in video
Mar 30, 2015

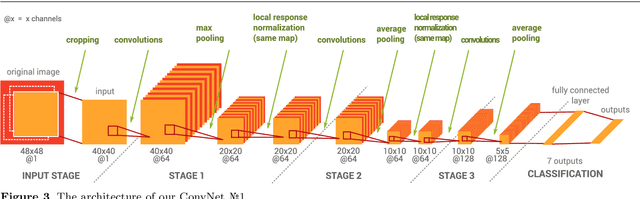
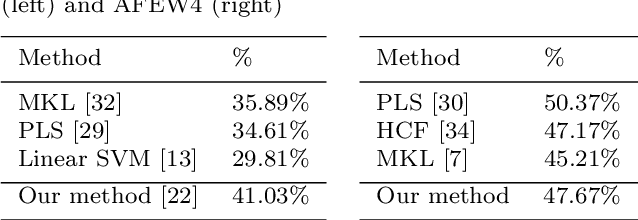
The task of the emotion recognition in the wild (EmotiW) Challenge is to assign one of seven emotions to short video clips extracted from Hollywood style movies. The videos depict acted-out emotions under realistic conditions with a large degree of variation in attributes such as pose and illumination, making it worthwhile to explore approaches which consider combinations of features from multiple modalities for label assignment. In this paper we present our approach to learning several specialist models using deep learning techniques, each focusing on one modality. Among these are a convolutional neural network, focusing on capturing visual information in detected faces, a deep belief net focusing on the representation of the audio stream, a K-Means based "bag-of-mouths" model, which extracts visual features around the mouth region and a relational autoencoder, which addresses spatio-temporal aspects of videos. We explore multiple methods for the combination of cues from these modalities into one common classifier. This achieves a considerably greater accuracy than predictions from our strongest single-modality classifier. Our method was the winning submission in the 2013 EmotiW challenge and achieved a test set accuracy of 47.67% on the 2014 dataset.
Modeling sequential data using higher-order relational features and predictive training
Feb 10, 2014

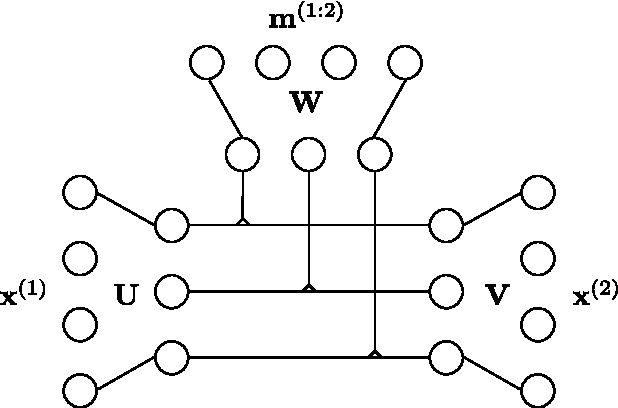
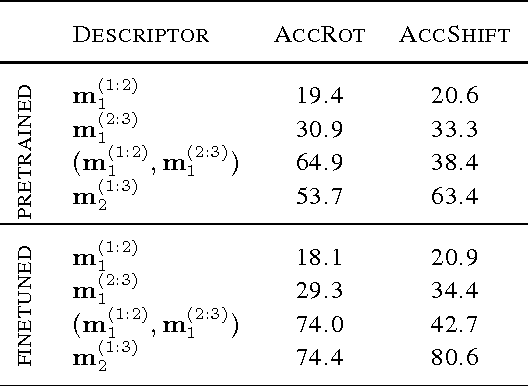
Bi-linear feature learning models, like the gated autoencoder, were proposed as a way to model relationships between frames in a video. By minimizing reconstruction error of one frame, given the previous frame, these models learn "mapping units" that encode the transformations inherent in a sequence, and thereby learn to encode motion. In this work we extend bi-linear models by introducing "higher-order mapping units" that allow us to encode transformations between frames and transformations between transformations. We show that this makes it possible to encode temporal structure that is more complex and longer-range than the structure captured within standard bi-linear models. We also show that a natural way to train the model is by replacing the commonly used reconstruction objective with a prediction objective which forces the model to correctly predict the evolution of the input multiple steps into the future. Learning can be achieved by back-propagating the multi-step prediction through time. We test the model on various temporal prediction tasks, and show that higher-order mappings and predictive training both yield a significant improvement over bi-linear models in terms of prediction accuracy.
Learning to encode motion using spatio-temporal synchrony
Feb 10, 2014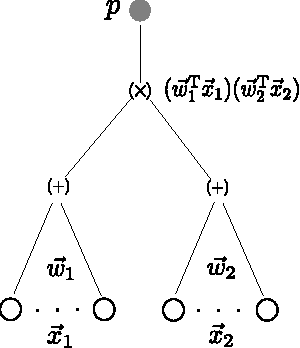

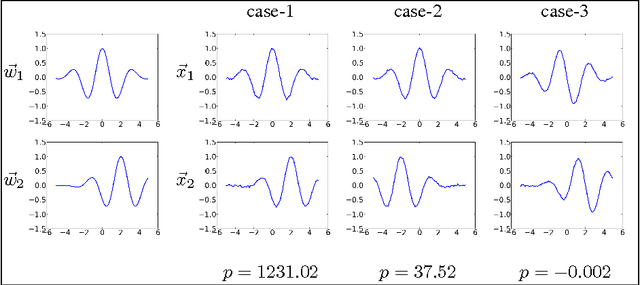

We consider the task of learning to extract motion from videos. To this end, we show that the detection of spatial transformations can be viewed as the detection of synchrony between the image sequence and a sequence of features undergoing the motion we wish to detect. We show that learning about synchrony is possible using very fast, local learning rules, by introducing multiplicative "gating" interactions between hidden units across frames. This makes it possible to achieve competitive performance in a wide variety of motion estimation tasks, using a small fraction of the time required to learn features, and to outperform hand-crafted spatio-temporal features by a large margin. We also show how learning about synchrony can be viewed as performing greedy parameter estimation in the well-known motion energy model.