 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Never Get a Second Chance To Make a Good First Impression: Seeding Active Learning for 3D Semantic Segmentation
Apr 23, 2023We propose SeedAL, a method to seed active learning for efficient annotation of 3D point clouds for semantic segmentation. Active Learning (AL) iteratively selects relevant data fractions to annotate within a given budget, but requires a first fraction of the dataset (a 'seed') to be already annotated to estimate the benefit of annotating other data fractions. We first show that the choice of the seed can significantly affect the performance of many AL methods. We then propose a method for automatically constructing a seed that will ensure good performance for AL. Assuming that images of the point clouds are available, which is common, our method relies on powerful unsupervised image features to measure the diversity of the point clouds. It selects the point clouds for the seed by optimizing the diversity under an annotation budget, which can be done by solving a linear optimization problem. Our experiments demonstrate the effectiveness of our approach compared to random seeding and existing methods on both the S3DIS and SemanticKitti datasets. Code is available at \url{https://github.com/nerminsamet/seedal}.
NOPE: Novel Object Pose Estimation from a Single Image
Mar 23, 2023The practicality of 3D object pose estimation remains limited for many applications due to the need for prior knowledge of a 3D model and a training period for new objects. To address this limitation, we propose an approach that takes a single image of a new object as input and predicts the relative pose of this object in new images without prior knowledge of the object's 3D model and without requiring training time for new objects and categories. We achieve this by training a model to directly predict discriminative embeddings for viewpoints surrounding the object. This prediction is done using a simple U-Net architecture with attention and conditioned on the desired pose, which yields extremely fast inference. We compare our approach to state-of-the-art methods and show it outperforms them both in terms of accuracy and robustness. Our source code is publicly available at https://github.com/nv-nguyen/nope
MACARONS: Mapping And Coverage Anticipation with RGB Online Self-Supervision
Mar 06, 2023



We introduce a method that simultaneously learns to explore new large environments and to reconstruct them in 3D from color images only. This is closely related to the Next Best View problem (NBV), where one has to identify where to move the camera next to improve the coverage of an unknown scene. However, most of the current NBV methods rely on depth sensors, need 3D supervision and/or do not scale to large scenes. Our method requires only a color camera and no 3D supervision. It simultaneously learns in a self-supervised fashion to predict a "volume occupancy field" from color images and, from this field, to predict the NBV. Thanks to this approach, our method performs well on new scenes as it is not biased towards any training 3D data. We demonstrate this on a recent dataset made of various 3D scenes and show it performs even better than recent methods requiring a depth sensor, which is not a realistic assumption for outdoor scenes captured with a flying drone.
Automatically Annotating Indoor Images with CAD Models via RGB-D Scans
Dec 22, 2022



We present an automatic method for annotating images of indoor scenes with the CAD models of the objects by relying on RGB-D scans. Through a visual evaluation by 3D experts, we show that our method retrieves annotations that are at least as accurate as manual annotations, and can thus be used as ground truth without the burden of manually annotating 3D data. We do this using an analysis-by-synthesis approach, which compares renderings of the CAD models with the captured scene. We introduce a 'cloning procedure' that identifies objects that have the same geometry, to annotate these objects with the same CAD models. This allows us to obtain complete annotations for the ScanNet dataset and the recent ARKitScenes dataset.
In-Hand 3D Object Scanning from an RGB Sequence
Nov 28, 2022
We propose a method for in-hand 3D scanning of an unknown object from a sequence of color images. We cast the problem as reconstructing the object surface from un-posed multi-view images and rely on a neural implicit surface representation that captures both the geometry and the appearance of the object. By contrast with most NeRF-based methods, we do not assume that the camera-object relative poses are known and instead simultaneously optimize both the object shape and the pose trajectory. As global optimization over all the shape and pose parameters is prone to fail without coarse-level initialization of the poses, we propose an incremental approach which starts by splitting the sequence into carefully selected overlapping segments within which the optimization is likely to succeed. We incrementally reconstruct the object shape and track the object poses independently within each segment, and later merge all the segments by aligning poses estimated at the overlapping frames. Finally, we perform a global optimization over all the aligned segments to achieve full reconstruction. We experimentally show that the proposed method is able to reconstruct the shape and color of both textured and challenging texture-less objects, outperforms classical methods that rely only on appearance features, and its performance is close to recent methods that assume known camera poses.
Multi-Finger Grasping Like Humans
Nov 14, 2022Robots with multi-fingered grippers could perform advanced manipulation tasks for us if we were able to properly specify to them what to do. In this study, we take a step in that direction by making a robot grasp an object like a grasping demonstration performed by a human. We propose a novel optimization-based approach for transferring human grasp demonstrations to any multi-fingered grippers, which produces robotic grasps that mimic the human hand orientation and the contact area with the object, while alleviating interpenetration. Extensive experiments with the Allegro and BarrettHand grippers show that our method leads to grasps more similar to the human demonstration than existing approaches, without requiring any gripper-specific tuning. We confirm these findings through a user study and validate the applicability of our approach on a real robot.
* presented at IROS 2022 conference
Long-Lived Accurate Keypoints in Event Streams
Oct 07, 2022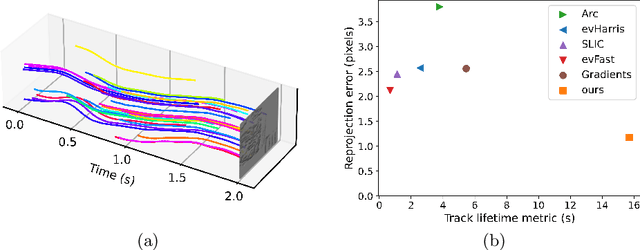
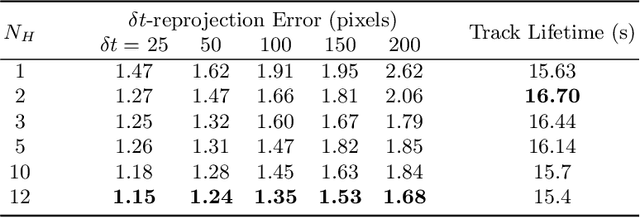
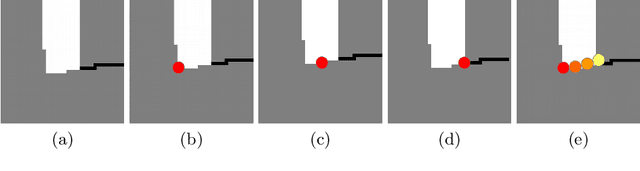
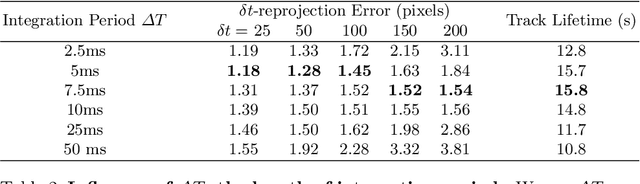
We present a novel end-to-end approach to keypoint detection and tracking in an event stream that provides better precision and much longer keypoint tracks than previous methods. This is made possible by two contributions working together. First, we propose a simple procedure to generate stable keypoint labels, which we use to train a recurrent architecture. This training data results in detections that are very consistent over time. Moreover, we observe that previous methods for keypoint detection work on a representation (such as the time surface) that integrates events over a period of time. Since this integration is required, we claim it is better to predict the keypoints' trajectories for the time period rather than single locations, as done in previous approaches. We predict these trajectories in the form of a series of heatmaps for the integration time period. This improves the keypoint localization. Our architecture can also be kept very simple, which results in very fast inference times. We demonstrate our approach on the HVGA ATIS Corner dataset as well as "The Event-Camera Dataset and Simulator" dataset, and show it results in keypoint tracks that are three times longer and nearly twice as accurate as the best previous state-of-the-art methods. We believe our approach can be generalized to other event-based camera problems, and we release our source code to encourage other authors to explore it.
A Simple and Powerful Global Optimization for Unsupervised Video Object Segmentation
Sep 19, 2022
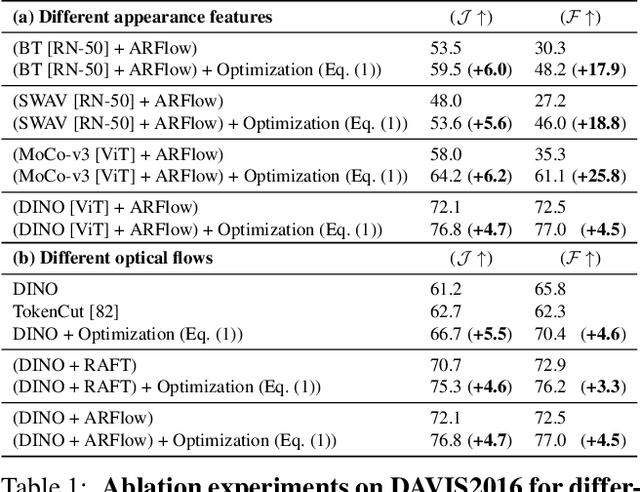

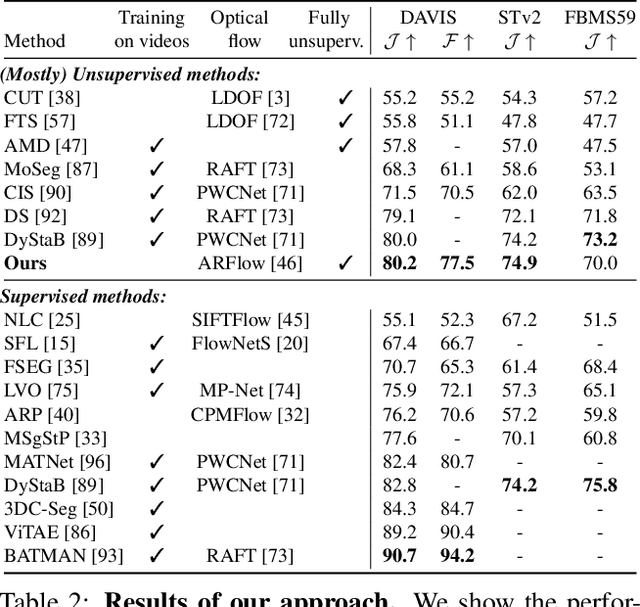
We propose a simple, yet powerful approach for unsupervised object segmentation in videos. We introduce an objective function whose minimum represents the mask of the main salient object over the input sequence. It only relies on independent image features and optical flows, which can be obtained using off-the-shelf self-supervised methods. It scales with the length of the sequence with no need for superpixels or sparsification, and it generalizes to different datasets without any specific training. This objective function can actually be derived from a form of spectral clustering applied to the entire video. Our method achieves on-par performance with the state of the art on standard benchmarks (DAVIS2016, SegTrack-v2, FBMS59), while being conceptually and practically much simpler. Code is available at https://ponimatkin.github.io/ssl-vos.
PIZZA: A Powerful Image-only Zero-Shot Zero-CAD Approach to 6 DoF Tracking
Sep 15, 2022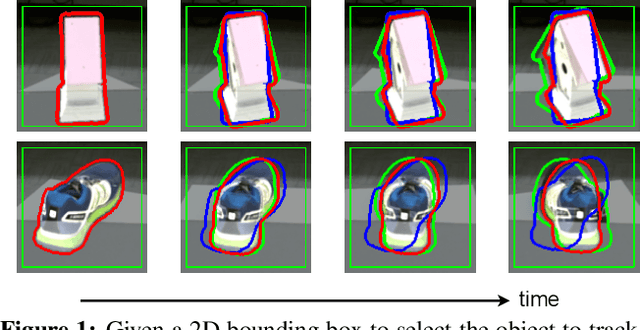
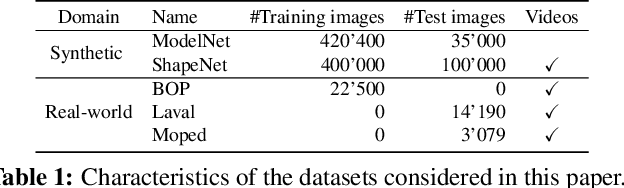
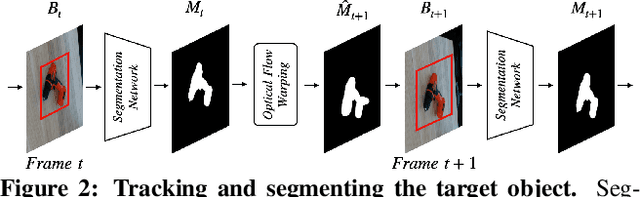
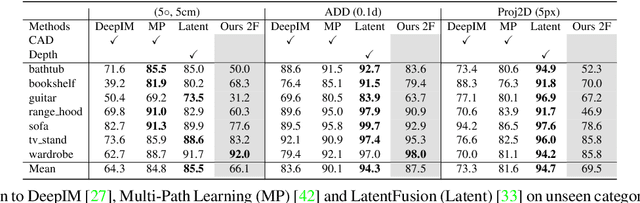
Estimating the relative pose of a new object without prior knowledge is a hard problem, while it is an ability very much needed in robotics and Augmented Reality. We present a method for tracking the 6D motion of objects in RGB video sequences when neither the training images nor the 3D geometry of the objects are available. In contrast to previous works, our method can therefore consider unknown objects in open world instantly, without requiring any prior information or a specific training phase. We consider two architectures, one based on two frames, and the other relying on a Transformer Encoder, which can exploit an arbitrary number of past frames. We train our architectures using only synthetic renderings with domain randomization. Our results on challenging datasets are on par with previous works that require much more information (training images of the target objects, 3D models, and/or depth data). Our source code is available at https://github.com/nv-nguyen/pizza
SCONE: Surface Coverage Optimization in Unknown Environments by Volumetric Integration
Aug 22, 2022
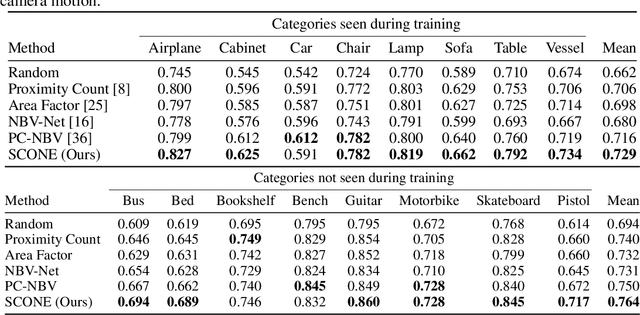
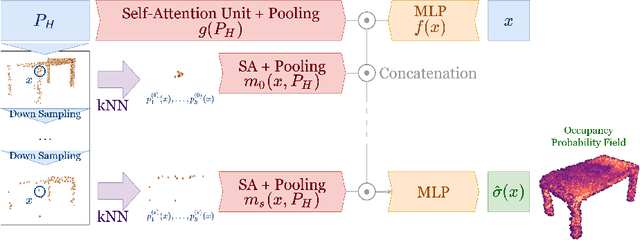
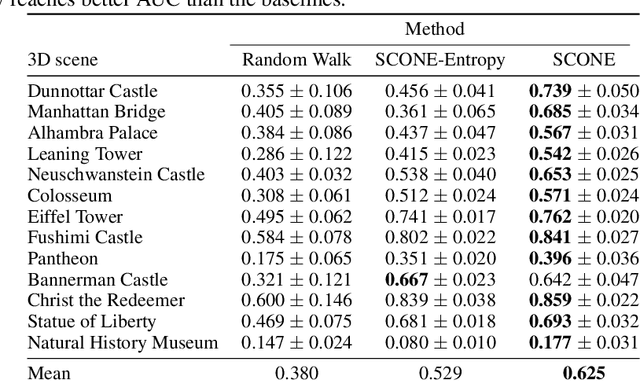
Next Best View computation (NBV) is a long-standing problem in robotics, and consists in identifying the next most informative sensor position(s) for reconstructing a 3D object or scene efficiently and accurately. Like most current methods, we consider NBV prediction from a depth sensor. Learning-based methods relying on a volumetric representation of the scene are suitable for path planning, but do not scale well with the size of the scene and have lower accuracy than methods using a surface-based representation. However, the latter constrain the camera to a small number of poses. To obtain the advantages of both representations, we show that we can maximize surface metrics by Monte Carlo integration over a volumetric representation. Our method scales to large scenes and handles free camera motion: It takes as input an arbitrarily large point cloud gathered by a depth sensor like Lidar systems as well as camera poses to predict NBV. We demonstrate our approach on a novel dataset made of large and complex 3D scenes.