 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandsFormer: Keypoint Transformer for Monocular 3D Pose Estimation ofHands and Object in Interaction
Paper and Code
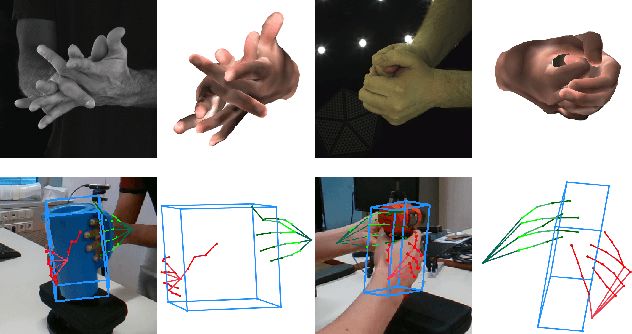
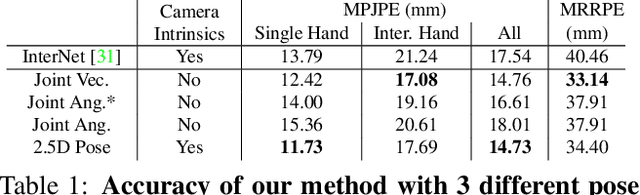
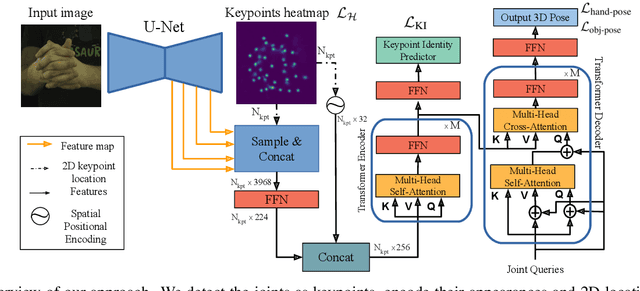

We propose a robust and accurate method for estimating the 3D poses of two hands in close interaction from a single color image. This is a very challenging problem, as large occlusions and many confusions between the joints may happen. Our method starts by extracting a set of potential 2D locations for the joints of both hands as extrema of a heatmap. We do not require that all locations correctly correspond to a joint, not that all the joints are detected. We use appearance and spatial encodings of these locations as input to a transformer, and leverage the attention mechanisms to sort out the correct configuration of the joints and output the 3D poses of both hands. Our approach thus allies the recognition power of a Transformer to the accuracy of heatmap-based methods. We also show it can be extended to estimate the 3D pose of an object manipulated by one or two hands. We evaluate our approach on the recent and challenging InterHand2.6M and HO-3D datasets. We obtain 17% improvement over the baseline. Moreover, we introduce the first dataset made of action sequences of two hands manipulating an object fully annotated in 3D and will make it publicly available.