 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProper Reuse of Image Classification Features Improves Object Detection
Apr 01, 2022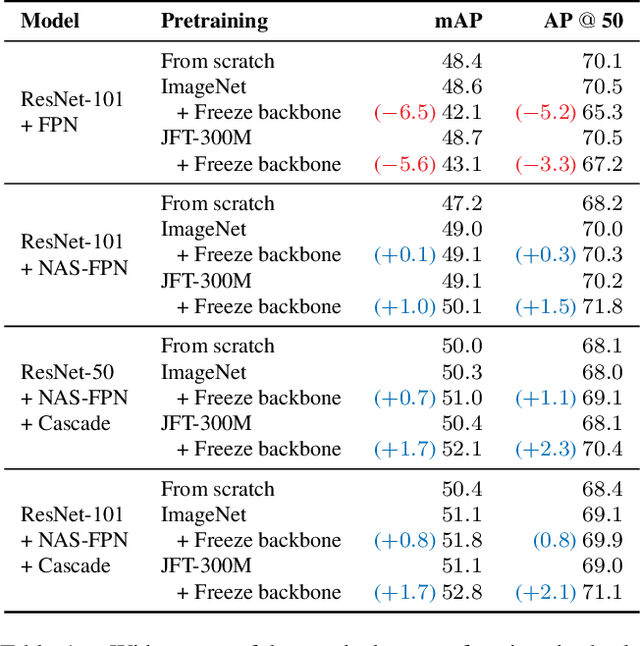
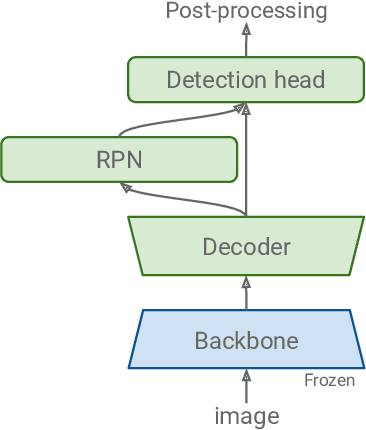
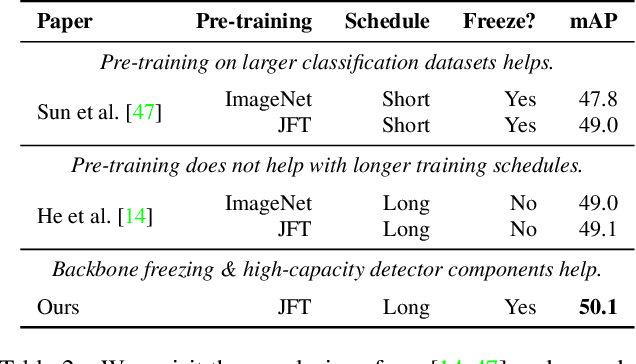

A common practice in transfer learning is to initialize the downstream model weights by pre-training on a data-abundant upstream task. In object detection specifically, the feature backbone is typically initialized with Imagenet classifier weights and fine-tuned on the object detection task. Recent works show this is not strictly necessary under longer training regimes and provide recipes for training the backbone from scratch. We investigate the opposite direction of this end-to-end training trend: we show that an extreme form of knowledge preservation -- freezing the classifier-initialized backbone -- consistently improves many different detection models, and leads to considerable resource savings. We hypothesize and corroborate experimentally that the remaining detector components capacity and structure is a crucial factor in leveraging the frozen backbone. Immediate applications of our findings include performance improvements on hard cases like detection of long-tail object classes and computational and memory resource savings that contribute to making the field more accessible to researchers with access to fewer computational resources.
Head2Toe: Utilizing Intermediate Representations for Better Transfer Learning
Jan 10, 2022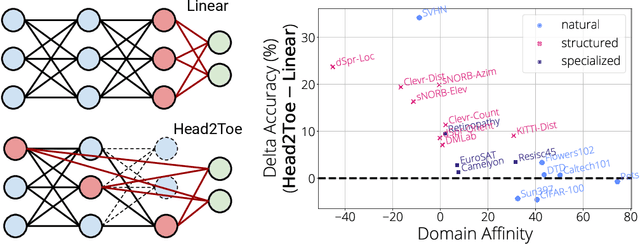
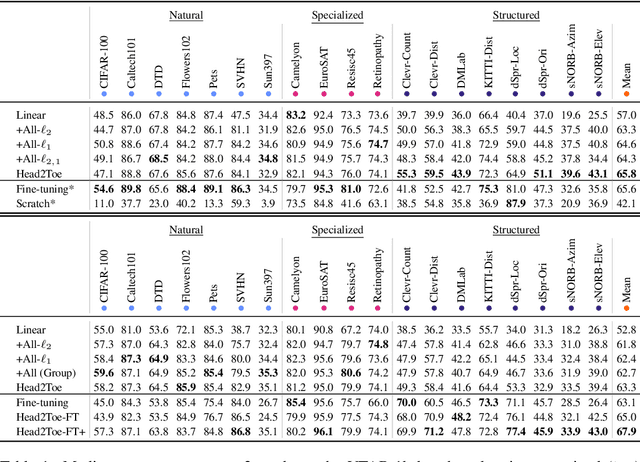
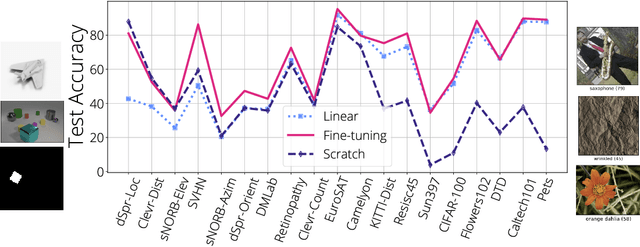
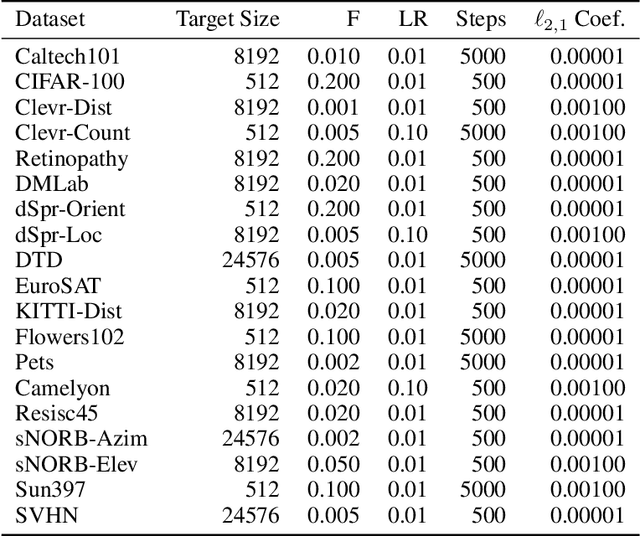
Transfer-learning methods aim to improve performance in a data-scarce target domain using a model pretrained on a data-rich source domain. A cost-efficient strategy, linear probing, involves freezing the source model and training a new classification head for the target domain. This strategy is outperformed by a more costly but state-of-the-art method -- fine-tuning all parameters of the source model to the target domain -- possibly because fine-tuning allows the model to leverage useful information from intermediate layers which is otherwise discarded by the later pretrained layers. We explore the hypothesis that these intermediate layers might be directly exploited. We propose a method, Head-to-Toe probing (Head2Toe), that selects features from all layers of the source model to train a classification head for the target-domain. In evaluations on the VTAB-1k, Head2Toe matches performance obtained with fine-tuning on average while reducing training and storage cost hundred folds or more, but critically, for out-of-distribution transfer, Head2Toe outperforms fine-tuning.
Impact of Aliasing on Generalization in Deep Convolutional Networks
Aug 07, 2021

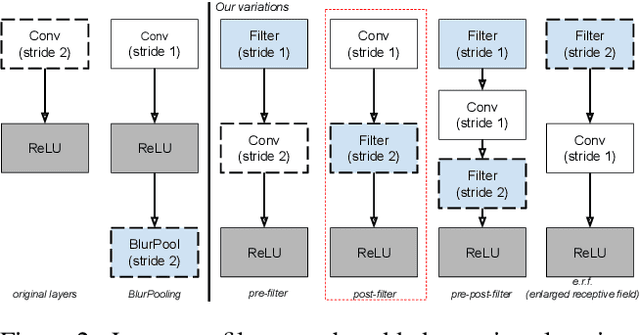
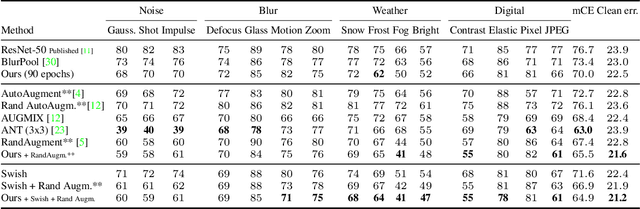
We investigate the impact of aliasing on generalization in Deep Convolutional Networks and show that data augmentation schemes alone are unable to prevent it due to structural limitations in widely used architectures. Drawing insights from frequency analysis theory, we take a closer look at ResNet and EfficientNet architectures and review the trade-off between aliasing and information loss in each of their major components. We show how to mitigate aliasing by inserting non-trainable low-pass filters at key locations, particularly where networks lack the capacity to learn them. These simple architectural changes lead to substantial improvements in generalization on i.i.d. and even more on out-of-distribution conditions, such as image classification under natural corruptions on ImageNet-C [11] and few-shot learning on Meta-Dataset [26]. State-of-the art results are achieved on both datasets without introducing additional trainable parameters and using the default hyper-parameters of open source codebases.
Domain Conditional Predictors for Domain Adaptation
Jun 25, 2021

Learning guarantees often rely on assumptions of i.i.d. data, which will likely be violated in practice once predictors are deployed to perform real-world tasks. Domain adaptation approaches thus appeared as a useful framework yielding extra flexibility in that distinct train and test data distributions are supported, provided that other assumptions are satisfied such as covariate shift, which expects the conditional distributions over labels to be independent of the underlying data distribution. Several approaches were introduced in order to induce generalization across varying train and test data sources, and those often rely on the general idea of domain-invariance, in such a way that the data-generating distributions are to be disregarded by the prediction model. In this contribution, we tackle the problem of generalizing across data sources by approaching it from the opposite direction: we consider a conditional modeling approach in which predictions, in addition to being dependent on the input data, use information relative to the underlying data-generating distribution. For instance, the model has an explicit mechanism to adapt to changing environments and/or new data sources. We argue that such an approach is more generally applicable than current domain adaptation methods since it does not require extra assumptions such as covariate shift and further yields simpler training algorithms that avoid a common source of training instabilities caused by minimax formulations, often employed in domain-invariant methods.
Learning a Universal Template for Few-shot Dataset Generalization
May 14, 2021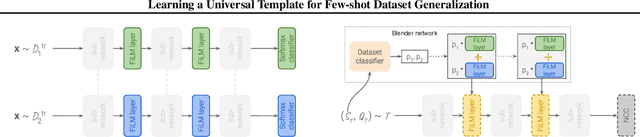
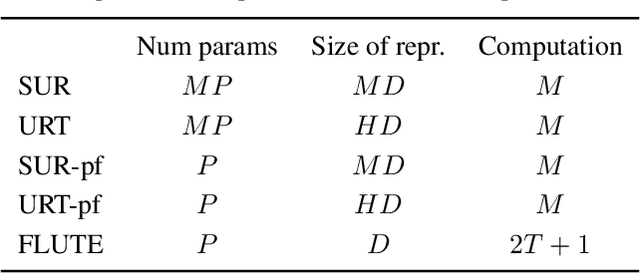
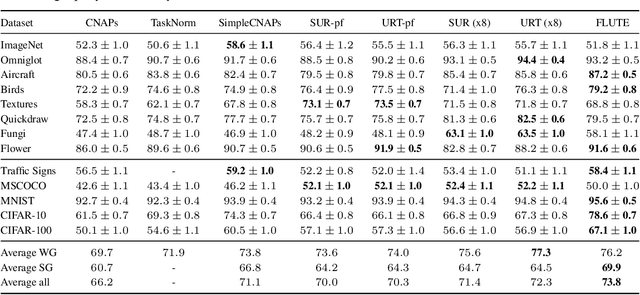

Few-shot dataset generalization is a challenging variant of the well-studied few-shot classification problem where a diverse training set of several datasets is given, for the purpose of training an adaptable model that can then learn classes from new datasets using only a few examples. To this end, we propose to utilize the diverse training set to construct a universal template: a partial model that can define a wide array of dataset-specialized models, by plugging in appropriate components. For each new few-shot classification problem, our approach therefore only requires inferring a small number of parameters to insert into the universal template. We design a separate network that produces an initialization of those parameters for each given task, and we then fine-tune its proposed initialization via a few steps of gradient descent. Our approach is more parameter-efficient, scalable and adaptable compared to previous methods, and achieves the state-of-the-art on the challenging Meta-Dataset benchmark.
Comparing Transfer and Meta Learning Approaches on a Unified Few-Shot Classification Benchmark
Apr 06, 2021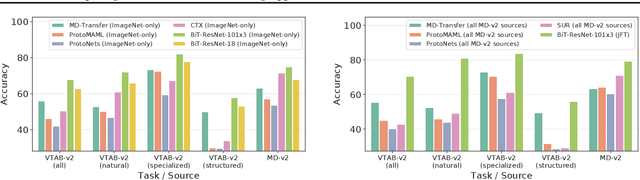
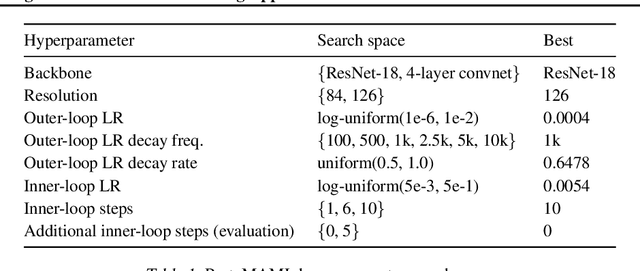
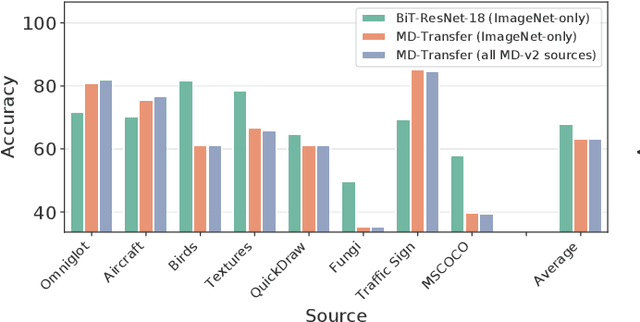

Meta and transfer learning are two successful families of approaches to few-shot learning. Despite highly related goals, state-of-the-art advances in each family are measured largely in isolation of each other. As a result of diverging evaluation norms, a direct or thorough comparison of different approaches is challenging. To bridge this gap, we perform a cross-family study of the best transfer and meta learners on both a large-scale meta-learning benchmark (Meta-Dataset, MD), and a transfer learning benchmark (Visual Task Adaptation Benchmark, VTAB). We find that, on average, large-scale transfer methods (Big Transfer, BiT) outperform competing approaches on MD, even when trained only on ImageNet. In contrast, meta-learning approaches struggle to compete on VTAB when trained and validated on MD. However, BiT is not without limitations, and pushing for scale does not improve performance on highly out-of-distribution MD tasks. In performing this study, we reveal a number of discrepancies in evaluation norms and study some of these in light of the performance gap. We hope that this work facilitates sharing of insights from each community, and accelerates progress on few-shot learning.
An Effective Anti-Aliasing Approach for Residual Networks
Nov 20, 2020

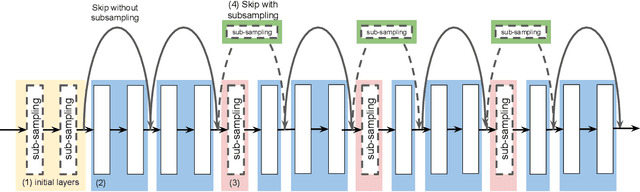

Image pre-processing in the frequency domain has traditionally played a vital role in computer vision and was even part of the standard pipeline in the early days of deep learning. However, with the advent of large datasets, many practitioners concluded that this was unnecessary due to the belief that these priors can be learned from the data itself. Frequency aliasing is a phenomenon that may occur when sub-sampling any signal, such as an image or feature map, causing distortion in the sub-sampled output. We show that we can mitigate this effect by placing non-trainable blur filters and using smooth activation functions at key locations, particularly where networks lack the capacity to learn them. These simple architectural changes lead to substantial improvements in out-of-distribution generalization on both image classification under natural corruptions on ImageNet-C [10] and few-shot learning on Meta-Dataset [17], without introducing additional trainable parameters and using the default hyper-parameters of open source codebases.
Meta-Dataset: A Dataset of Datasets for Learning to Learn from Few Examples
Mar 07, 2019
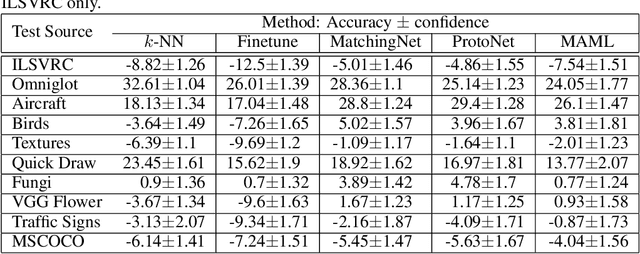

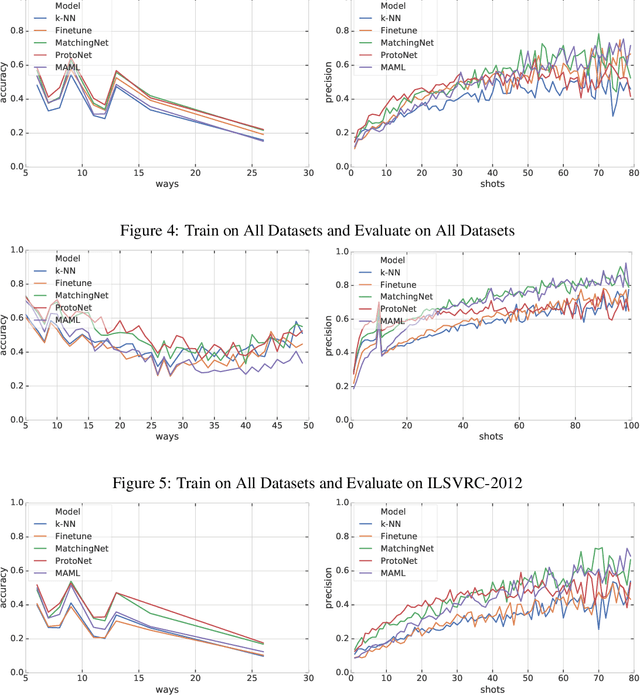
Few-shot classification refers to learning a classifier for new classes given only a few examples. While a plethora of models have emerged to tackle this recently, we find the current procedure and datasets that are used to systematically assess progress in this setting lacking. To address this, we propose Meta-Dataset: a new benchmark for training and evaluating few-shot classifiers that is large-scale, consists of multiple datasets, and presents more natural and realistic tasks. The aim is to measure the ability of state-of-the-art models to leverage diverse sources of data to achieve higher generalization, and to evaluate that generalization ability in a more challenging setting. We additionally measure robustness of current methods to variations in the number of available examples and the number of classes. Finally our extensive empirical evaluation leads us to identify weaknesses in Prototypical Networks and MAML, two popular few-shot classification methods, and to propose a new method, Proto-MAML, which achieves improved performance on our benchmark.
The Hanabi Challenge: A New Frontier for AI Research
Feb 01, 2019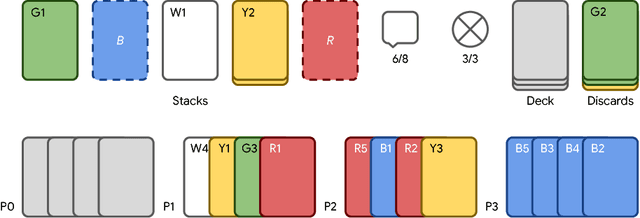
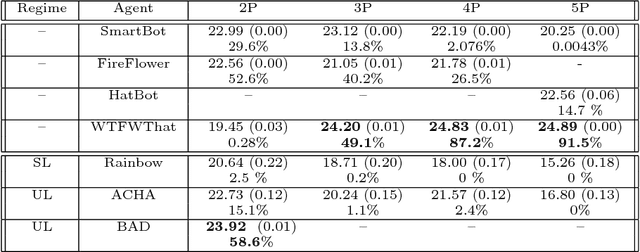
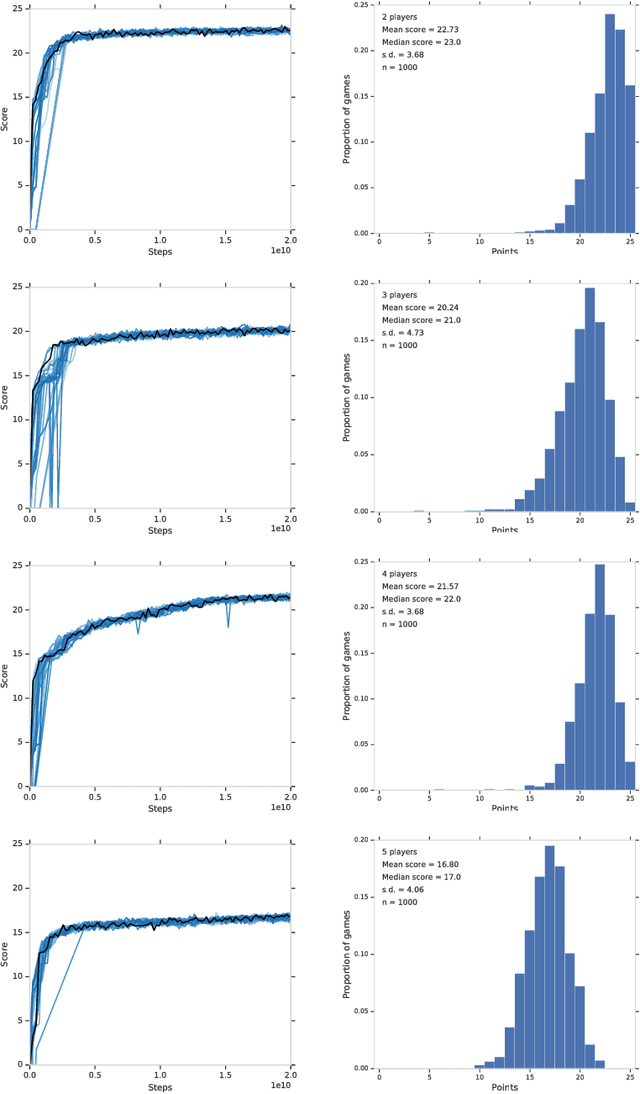
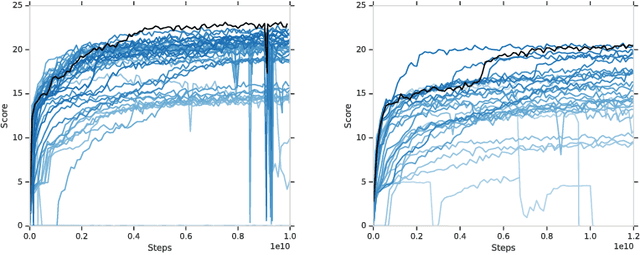
From the early days of computing, games have been important testbeds for studying how well machines can do sophisticated decision making. In recent years, machine learning has made dramatic advances with artificial agents reaching superhuman performance in challenge domains like Go, Atari, and some variants of poker. As with their predecessors of chess, checkers, and backgammon, these game domains have driven research by providing sophisticated yet well-defined challenges for artificial intelligence practitioners. We continue this tradition by proposing the game of Hanabi as a new challenge domain with novel problems that arise from its combination of purely cooperative gameplay and imperfect information in a two to five player setting. In particular, we argue that Hanabi elevates reasoning about the beliefs and intentions of other agents to the foreground. We believe developing novel techniques capable of imbuing artificial agents with such theory of mind will not only be crucial for their success in Hanabi, but also in broader collaborative efforts, and especially those with human partners. To facilitate future research, we introduce the open-source Hanabi Learning Environment, propose an experimental framework for the research community to evaluate algorithmic advances, and assess the performance of current state-of-the-art techniques.
Cross-Modulation Networks for Few-Shot Learning
Dec 01, 2018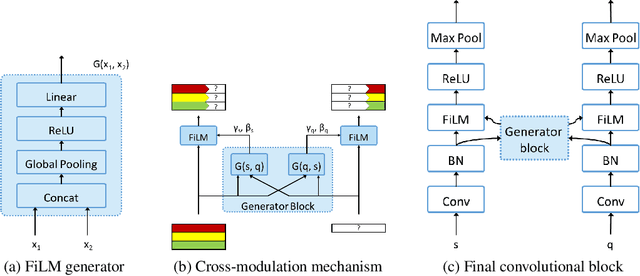
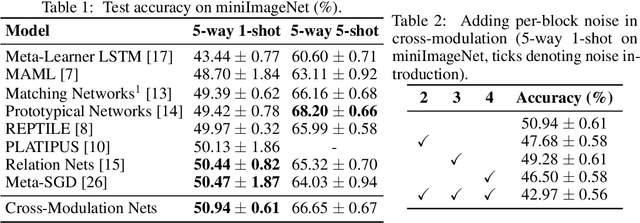
A family of recent successful approaches to few-shot learning relies on learning an embedding space in which predictions are made by computing similarities between examples. This corresponds to combining information between support and query examples at a very late stage of the prediction pipeline. Inspired by this observation, we hypothesize that there may be benefits to combining the information at various levels of abstraction along the pipeline. We present an architecture called Cross-Modulation Networks which allows support and query examples to interact throughout the feature extraction process via a feature-wise modulation mechanism. We adapt the Matching Networks architecture to take advantage of these interactions and show encouraging initial results on miniImageNet in the 5-way, 1-shot setting, where we close the gap with state-of-the-art.