 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOIN: Control-Inpainting Diffusion Prior for Human and Camera Motion Estimation
Aug 29, 2024



Estimating global human motion from moving cameras is challenging due to the entanglement of human and camera motions. To mitigate the ambiguity, existing methods leverage learned human motion priors, which however often result in oversmoothed motions with misaligned 2D projections. To tackle this problem, we propose COIN, a control-inpainting motion diffusion prior that enables fine-grained control to disentangle human and camera motions. Although pre-trained motion diffusion models encode rich motion priors, we find it non-trivial to leverage such knowledge to guide global motion estimation from RGB videos. COIN introduces a novel control-inpainting score distillation sampling method to ensure well-aligned, consistent, and high-quality motion from the diffusion prior within a joint optimization framework. Furthermore, we introduce a new human-scene relation loss to alleviate the scale ambiguity by enforcing consistency among the humans, camera, and scene. Experiments on three challenging benchmarks demonstrate the effectiveness of COIN, which outperforms the state-of-the-art methods in terms of global human motion estimation and camera motion estimation. As an illustrative example, COIN outperforms the state-of-the-art method by 33% in world joint position error (W-MPJPE) on the RICH dataset.
Data Exposure from LLM Apps: An In-depth Investigation of OpenAI's GPTs
Aug 23, 2024LLM app ecosystems are quickly maturing and supporting a wide range of use cases, which requires them to collect excessive user data. Given that the LLM apps are developed by third-parties and that anecdotal evidence suggests LLM platforms currently do not strictly enforce their policies, user data shared with arbitrary third-parties poses a significant privacy risk. In this paper we aim to bring transparency in data practices of LLM apps. As a case study, we study OpenAI's GPT app ecosystem. We develop an LLM-based framework to conduct the static analysis of natural language-based source code of GPTs and their Actions (external services) to characterize their data collection practices. Our findings indicate that Actions collect expansive data about users, including sensitive information prohibited by OpenAI, such as passwords. We find that some Actions, including related to advertising and analytics, are embedded in multiple GPTs, which allow them to track user activities across GPTs. Additionally, co-occurrence of Actions exposes as much as 9.5x more data to them, than it is exposed to individual Actions. Lastly, we develop an LLM-based privacy policy analysis framework to automatically check the consistency of data collection by Actions with disclosures in their privacy policies. Our measurements indicate that the disclosures for most of the collected data types are omitted in privacy policies, with only 5.8% of Actions clearly disclosing their data collection practices.
SecGPT: An Execution Isolation Architecture for LLM-Based Systems
Mar 08, 2024



Large language models (LLMs) extended as systems, such as ChatGPT, have begun supporting third-party applications. These LLM apps leverage the de facto natural language-based automated execution paradigm of LLMs: that is, apps and their interactions are defined in natural language, provided access to user data, and allowed to freely interact with each other and the system. These LLM app ecosystems resemble the settings of earlier computing platforms, where there was insufficient isolation between apps and the system. Because third-party apps may not be trustworthy, and exacerbated by the imprecision of the natural language interfaces, the current designs pose security and privacy risks for users. In this paper, we propose SecGPT, an architecture for LLM-based systems that aims to mitigate the security and privacy issues that arise with the execution of third-party apps. SecGPT's key idea is to isolate the execution of apps and more precisely mediate their interactions outside of their isolated environments. We evaluate SecGPT against a number of case study attacks and demonstrate that it protects against many security, privacy, and safety issues that exist in non-isolated LLM-based systems. The performance overhead incurred by SecGPT to improve security is under 0.3x for three-quarters of the tested queries. To foster follow-up research, we release SecGPT's source code at https://github.com/llm-platform-security/SecGPT.
Multi-Track Timeline Control for Text-Driven 3D Human Motion Generation
Jan 16, 2024



Recent advances in generative modeling have led to promising progress on synthesizing 3D human motion from text, with methods that can generate character animations from short prompts and specified durations. However, using a single text prompt as input lacks the fine-grained control needed by animators, such as composing multiple actions and defining precise durations for parts of the motion. To address this, we introduce the new problem of timeline control for text-driven motion synthesis, which provides an intuitive, yet fine-grained, input interface for users. Instead of a single prompt, users can specify a multi-track timeline of multiple prompts organized in temporal intervals that may overlap. This enables specifying the exact timings of each action and composing multiple actions in sequence or at overlapping intervals. To generate composite animations from a multi-track timeline, we propose a new test-time denoising method. This method can be integrated with any pre-trained motion diffusion model to synthesize realistic motions that accurately reflect the timeline. At every step of denoising, our method processes each timeline interval (text prompt) individually, subsequently aggregating the predictions with consideration for the specific body parts engaged in each action. Experimental comparisons and ablations validate that our method produces realistic motions that respect the semantics and timing of given text prompts. Our code and models are publicly available at https://mathis.petrovich.fr/stmc.
What You See is What You GAN: Rendering Every Pixel for High-Fidelity Geometry in 3D GANs
Jan 04, 2024



3D-aware Generative Adversarial Networks (GANs) have shown remarkable progress in learning to generate multi-view-consistent images and 3D geometries of scenes from collections of 2D images via neural volume rendering. Yet, the significant memory and computational costs of dense sampling in volume rendering have forced 3D GANs to adopt patch-based training or employ low-resolution rendering with post-processing 2D super resolution, which sacrifices multiview consistency and the quality of resolved geometry. Consequently, 3D GANs have not yet been able to fully resolve the rich 3D geometry present in 2D images. In this work, we propose techniques to scale neural volume rendering to the much higher resolution of native 2D images, thereby resolving fine-grained 3D geometry with unprecedented detail. Our approach employs learning-based samplers for accelerating neural rendering for 3D GAN training using up to 5 times fewer depth samples. This enables us to explicitly "render every pixel" of the full-resolution image during training and inference without post-processing superresolution in 2D. Together with our strategy to learn high-quality surface geometry, our method synthesizes high-resolution 3D geometry and strictly view-consistent images while maintaining image quality on par with baselines relying on post-processing super resolution. We demonstrate state-of-the-art 3D gemetric quality on FFHQ and AFHQ, setting a new standard for unsupervised learning of 3D shapes in 3D GANs.
GAvatar: Animatable 3D Gaussian Avatars with Implicit Mesh Learning
Dec 18, 2023



Gaussian splatting has emerged as a powerful 3D representation that harnesses the advantages of both explicit (mesh) and implicit (NeRF) 3D representations. In this paper, we seek to leverage Gaussian splatting to generate realistic animatable avatars from textual descriptions, addressing the limitations (e.g., flexibility and efficiency) imposed by mesh or NeRF-based representations. However, a naive application of Gaussian splatting cannot generate high-quality animatable avatars and suffers from learning instability; it also cannot capture fine avatar geometries and often leads to degenerate body parts. To tackle these problems, we first propose a primitive-based 3D Gaussian representation where Gaussians are defined inside pose-driven primitives to facilitate animation. Second, to stabilize and amortize the learning of millions of Gaussians, we propose to use neural implicit fields to predict the Gaussian attributes (e.g., colors). Finally, to capture fine avatar geometries and extract detailed meshes, we propose a novel SDF-based implicit mesh learning approach for 3D Gaussians that regularizes the underlying geometries and extracts highly detailed textured meshes. Our proposed method, GAvatar, enables the large-scale generation of diverse animatable avatars using only text prompts. GAvatar significantly surpasses existing methods in terms of both appearance and geometry quality, and achieves extremely fast rendering (100 fps) at 1K resolution.
PACE: Human and Camera Motion Estimation from in-the-wild Videos
Oct 20, 2023
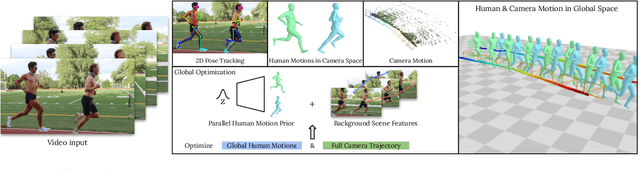
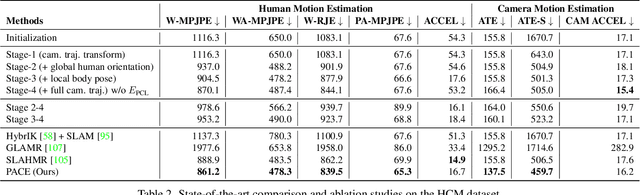

We present a method to estimate human motion in a global scene from moving cameras. This is a highly challenging task due to the coupling of human and camera motions in the video. To address this problem, we propose a joint optimization framework that disentangles human and camera motions using both foreground human motion priors and background scene features. Unlike existing methods that use SLAM as initialization, we propose to tightly integrate SLAM and human motion priors in an optimization that is inspired by bundle adjustment. Specifically, we optimize human and camera motions to match both the observed human pose and scene features. This design combines the strengths of SLAM and motion priors, which leads to significant improvements in human and camera motion estimation. We additionally introduce a motion prior that is suitable for batch optimization, making our approach significantly more efficient than existing approaches. Finally, we propose a novel synthetic dataset that enables evaluating camera motion in addition to human motion from dynamic videos. Experiments on the synthetic and real-world RICH datasets demonstrate that our approach substantially outperforms prior art in recovering both human and camera motions.
LLM Platform Security: Applying a Systematic Evaluation Framework to OpenAI's ChatGPT Plugins
Sep 19, 2023



Large language model (LLM) platforms, such as ChatGPT, have recently begun offering a plugin ecosystem to interface with third-party services on the internet. While these plugins extend the capabilities of LLM platforms, they are developed by arbitrary third parties and thus cannot be implicitly trusted. Plugins also interface with LLM platforms and users using natural language, which can have imprecise interpretations. In this paper, we propose a framework that lays a foundation for LLM platform designers to analyze and improve the security, privacy, and safety of current and future plugin-integrated LLM platforms. Our framework is a formulation of an attack taxonomy that is developed by iteratively exploring how LLM platform stakeholders could leverage their capabilities and responsibilities to mount attacks against each other. As part of our iterative process, we apply our framework in the context of OpenAI's plugin ecosystem. We uncover plugins that concretely demonstrate the potential for the types of issues that we outline in our attack taxonomy. We conclude by discussing novel challenges and by providing recommendations to improve the security, privacy, and safety of present and future LLM-based computing platforms.
PURL: Safe and Effective Sanitization of Link Decoration
Aug 07, 2023



While privacy-focused browsers have taken steps to block third-party cookies and browser fingerprinting, novel tracking methods that bypass existing defenses continue to emerge. Since trackers need to exfiltrate information from the client- to server-side through link decoration regardless of the tracking technique they employ, a promising orthogonal approach is to detect and sanitize tracking information in decorated links. We present PURL, a machine-learning approach that leverages a cross-layer graph representation of webpage execution to safely and effectively sanitize link decoration. Our evaluation shows that PURL significantly outperforms existing countermeasures in terms of accuracy and reducing website breakage while being robust to common evasion techniques. We use PURL to perform a measurement study on top-million websites. We find that link decorations are widely abused by well-known advertisers and trackers to exfiltrate user information collected from browser storage, email addresses, and scripts involved in fingerprinting.
Generalizable One-shot Neural Head Avatar
Jun 14, 2023



We present a method that reconstructs and animates a 3D head avatar from a single-view portrait image. Existing methods either involve time-consuming optimization for a specific person with multiple images, or they struggle to synthesize intricate appearance details beyond the facial region. To address these limitations, we propose a framework that not only generalizes to unseen identities based on a single-view image without requiring person-specific optimization, but also captures characteristic details within and beyond the face area (e.g. hairstyle, accessories, etc.). At the core of our method are three branches that produce three tri-planes representing the coarse 3D geometry, detailed appearance of a source image, as well as the expression of a target image. By applying volumetric rendering to the combination of the three tri-planes followed by a super-resolution module, our method yields a high fidelity image of the desired identity, expression and pose. Once trained, our model enables efficient 3D head avatar reconstruction and animation via a single forward pass through a network. Experiments show that the proposed approach generalizes well to unseen validation datasets, surpassing SOTA baseline methods by a large margin on head avatar reconstruction and animation.