 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeamlessM4T-Massively Multilingual & Multimodal Machine Translation
Aug 23, 2023



What does it take to create the Babel Fish, a tool that can help individuals translate speech between any two languages? While recent breakthroughs in text-based models have pushed machine translation coverage beyond 200 languages, unified speech-to-speech translation models have yet to achieve similar strides. More specifically, conventional speech-to-speech translation systems rely on cascaded systems that perform translation progressively, putting high-performing unified systems out of reach. To address these gaps, we introduce SeamlessM4T, a single model that supports speech-to-speech translation, speech-to-text translation, text-to-speech translation, text-to-text translation, and automatic speech recognition for up to 100 languages. To build this, we used 1 million hours of open speech audio data to learn self-supervised speech representations with w2v-BERT 2.0. Subsequently, we created a multimodal corpus of automatically aligned speech translations. Filtered and combined with human-labeled and pseudo-labeled data, we developed the first multilingual system capable of translating from and into English for both speech and text. On FLEURS, SeamlessM4T sets a new standard for translations into multiple target languages, achieving an improvement of 20% BLEU over the previous SOTA in direct speech-to-text translation. Compared to strong cascaded models, SeamlessM4T improves the quality of into-English translation by 1.3 BLEU points in speech-to-text and by 2.6 ASR-BLEU points in speech-to-speech. Tested for robustness, our system performs better against background noises and speaker variations in speech-to-text tasks compared to the current SOTA model. Critically, we evaluated SeamlessM4T on gender bias and added toxicity to assess translation safety. Finally, all contributions in this work are open-sourced and accessible at https://github.com/facebookresearch/seamless_communication
IPCC-TP: Utilizing Incremental Pearson Correlation Coefficient for Joint Multi-Agent Trajectory Prediction
Mar 16, 2023Reliable multi-agent trajectory prediction is crucial for the safe planning and control of autonomous systems. Compared with single-agent cases, the major challenge in simultaneously processing multiple agents lies in modeling complex social interactions caused by various driving intentions and road conditions. Previous methods typically leverage graph-based message propagation or attention mechanism to encapsulate such interactions in the format of marginal probabilistic distributions. However, it is inherently sub-optimal. In this paper, we propose IPCC-TP, a novel relevance-aware module based on Incremental Pearson Correlation Coefficient to improve multi-agent interaction modeling. IPCC-TP learns pairwise joint Gaussian Distributions through the tightly-coupled estimation of the means and covariances according to interactive incremental movements. Our module can be conveniently embedded into existing multi-agent prediction methods to extend original motion distribution decoders. Extensive experiments on nuScenes and Argoverse 2 datasets demonstrate that IPCC-TP improves the performance of baselines by a large margin.
On some studies of Fraud Detection Pipeline and related issues from the scope of Ensemble Learning and Graph-based Learning
May 10, 2022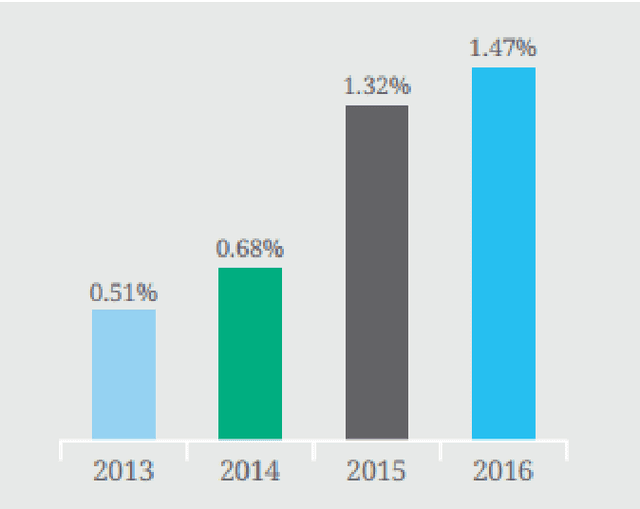
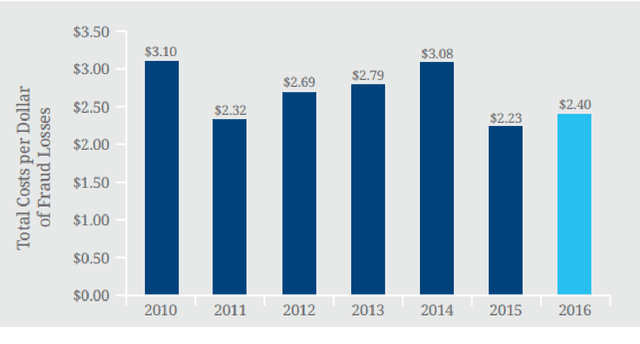
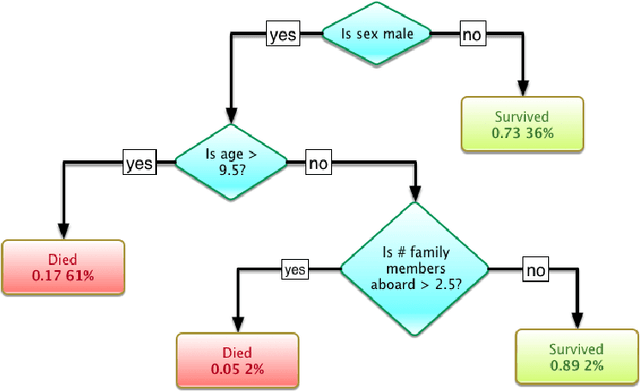
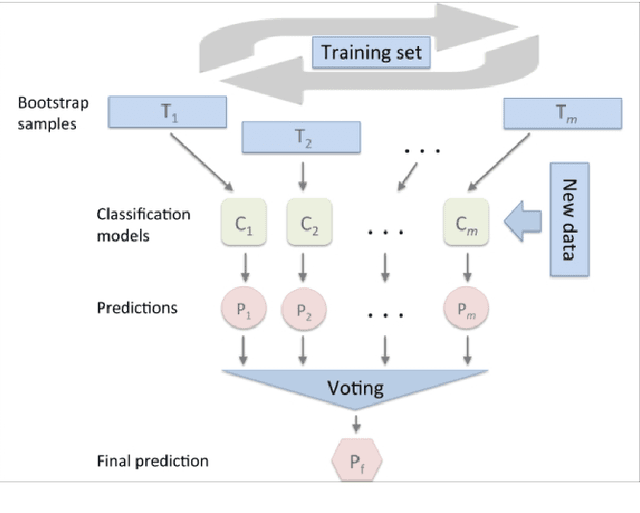
The UK anti-fraud charity Fraud Advisory Panel (FAP) in their review of 2016 estimates business costs of fraud at 144 billion, and its individual counterpart at 9.7 billion. Banking, insurance, manufacturing, and government are the most common industries affected by fraud activities. Designing an efficient fraud detection system could avoid losing the money; however, building this system is challenging due to many difficult problems, e.g.imbalanced data, computing costs, etc. Over the last three decades, there are various research relates to fraud detection but no agreement on what is the best approach to build the fraud detection system. In this thesis, we aim to answer some questions such as i) how to build a simplified and effective Fraud Detection System that not only easy to implement but also providing reliable results and our proposed Fraud Detection Pipeline is a potential backbone of the system and is easy to be extended or upgraded, ii) when to update models in our system (and keep the accuracy stable) in order to reduce the cost of updating process, iii) how to deal with an extreme imbalance in big data classification problem, e.g. fraud detection, since this is the gap between two difficult problems, iv) further, how to apply graph-based semi-supervised learning to detect fraudulent transactions.
Understanding Public Opinion on Using Hydroxychloroquine for COVID-19 Treatment via Social Media
Jan 01, 2022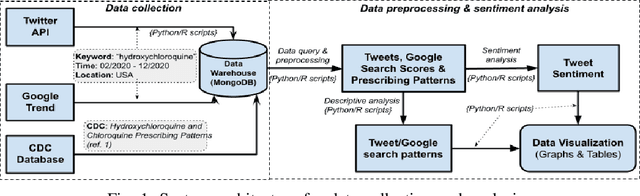

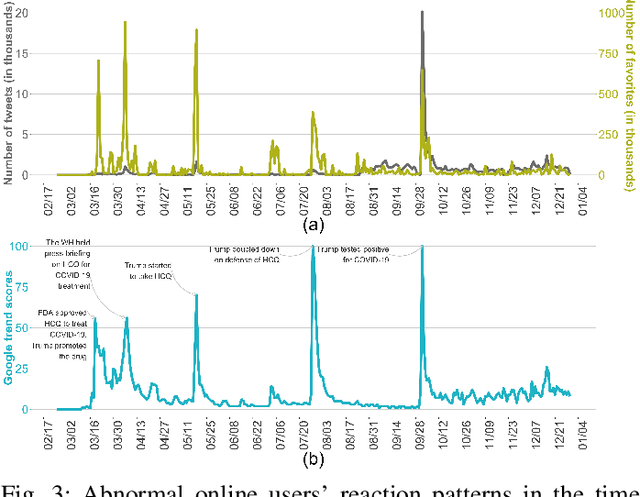

Hydroxychloroquine (HCQ) is used to prevent or treat malaria caused by mosquito bites. Recently, the drug has been suggested to treat COVID-19, but that has not been supported by scientific evidence. The information regarding the drug efficacy has flooded social networks, posting potential threats to the community by perverting their perceptions of the drug efficacy. This paper studies the reactions of social network users on the recommendation of using HCQ for COVID-19 treatment by analyzing the reaction patterns and sentiment of the tweets. We collected 164,016 tweets from February to December 2020 and used a text mining approach to identify social reaction patterns and opinion change over time. Our descriptive analysis identified an irregularity of the users' reaction patterns associated tightly with the social and news feeds on the development of HCQ and COVID-19 treatment. The study linked the tweets and Google search frequencies to reveal the viewpoints of local communities on the use of HCQ for COVID-19 treatment across different states. Further, our tweet sentiment analysis reveals that public opinion changed significantly over time regarding the recommendation of using HCQ for COVID-19 treatment. The data showed that high support in the early dates but it significantly declined in October. Finally, using the manual classification of 4,850 tweets by humans as our benchmark, our sentiment analysis showed that the Google Cloud Natural Language algorithm outperformed the Valence Aware Dictionary and sEntiment Reasoner in classifying tweets, especially in the sarcastic tweet group.
Improved sparse PCA method for face and image recognition
Dec 01, 2021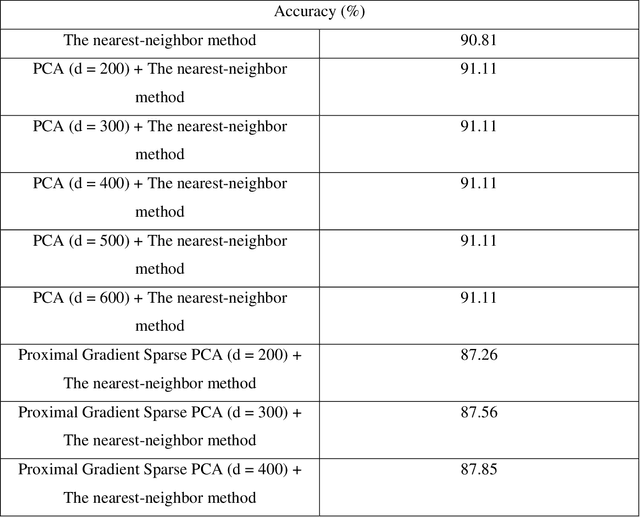
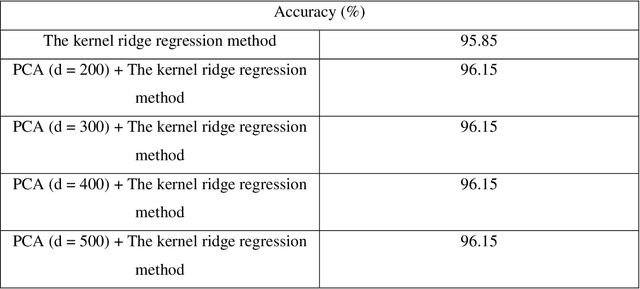

Face recognition is the very significant field in pattern recognition area. It has multiple applications in military and finance, to name a few. In this paper, the combination of the sparse PCA with the nearest-neighbor method (and with the kernel ridge regression method) will be proposed and will be applied to solve the face recognition problem. Experimental results illustrate that the accuracy of the combination of the sparse PCA method (using the proximal gradient method and the FISTA method) and one specific classification system may be lower than the accuracy of the combination of the PCA method and one specific classification system but sometimes the combination of the sparse PCA method (using the proximal gradient method or the FISTA method) and one specific classification system leads to better accuracy. Moreover, we recognize that the process computing the sparse PCA algorithm using the FISTA method is always faster than the process computing the sparse PCA algorithm using the proximal gradient method.
Text classification problems via BERT embedding method and graph convolutional neural network
Nov 30, 2021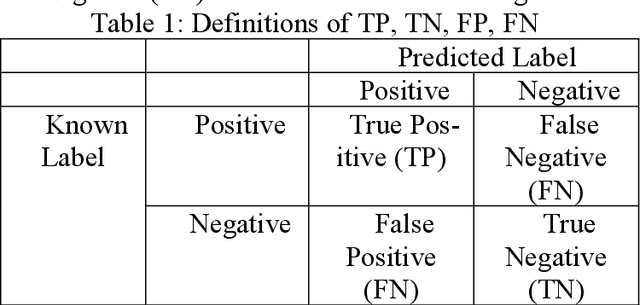
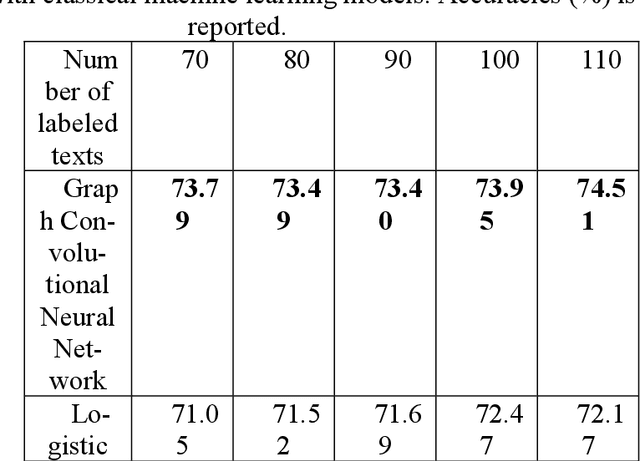
This paper presents the novel way combining the BERT embedding method and the graph convolutional neural network. This combination is employed to solve the text classification problem. Initially, we apply the BERT embedding method to the texts (in the BBC news dataset and the IMDB movie reviews dataset) in order to transform all the texts to numerical vector. Then, the graph convolutional neural network will be applied to these numerical vectors to classify these texts into their ap-propriate classes/labels. Experiments show that the performance of the graph convolutional neural network model is better than the perfor-mances of the combination of the BERT embedding method with clas-sical machine learning models.
Predictive Probability Path Planning Model For Dynamic Environments
Jul 29, 2020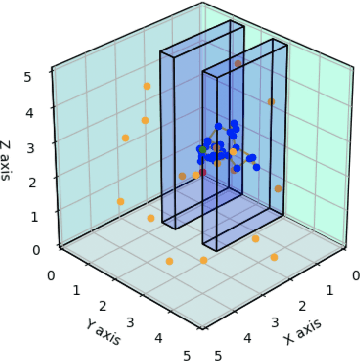
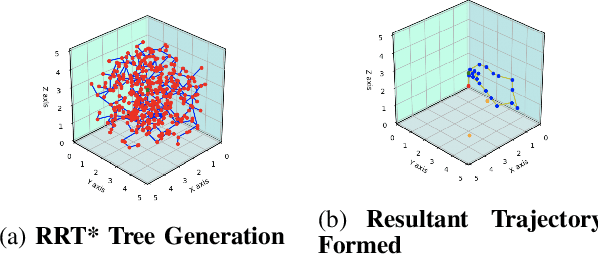
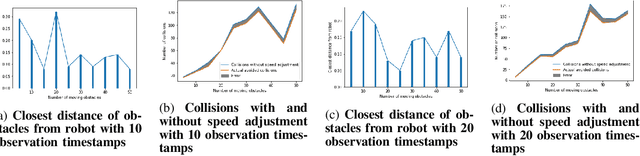
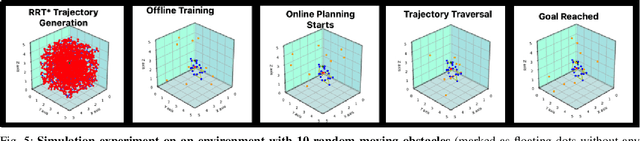
Path planning in dynamic environments is essential to high-risk applications such as unmanned aerial vehicles, self-driving cars, and autonomous underwater vehicles. In this paper, we generate collision-free trajectories for a robot within any given environment with temporal and spatial uncertainties caused due to randomly moving obstacles. We use two Poisson distributions to model the movements of obstacles across the generated trajectory of a robot in both space and time to determine the probability of collision with an obstacle. Measures are taken to avoid an obstacle by intelligently manipulating the speed of the robot at space-time intervals where a larger number of obstacles intersect the trajectory of the robot. Our method potentially reduces the use of computationally expensive collision detection libraries. Based on our experiments, there has been a significant improvement over existing methods in terms of safety, accuracy, execution time and computational cost. Our results show a high level of accuracy between the predicted and actual number of collisions with moving obstacles.
Predicting Sample Collision with Neural Networks
Jun 30, 2020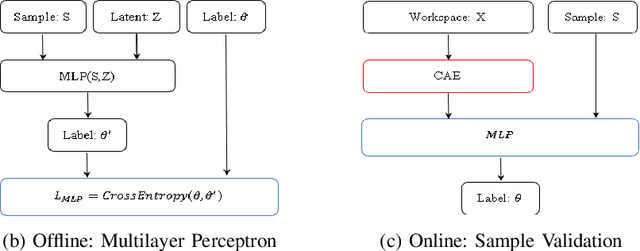
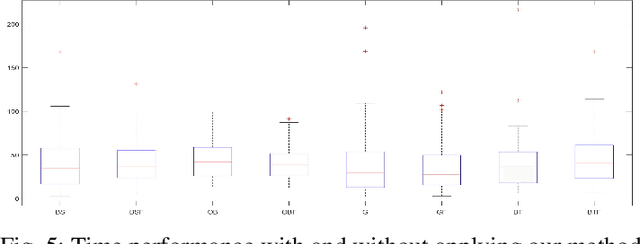
Many state-of-art robotics applications require fast and efficient motion planning algorithms. Existing motion planning methods become less effective as the dimensionality of the robot and its workspace increases, especially the computational cost of collision detection routines. In this work, we present a framework to address the cost of expensive primitive operations in sampling-based motion planning. This framework determines the validity of a sample robot configuration through a novel combination of a Contractive AutoEncoder (CAE), which captures a occupancy grids representation of the robot's workspace, and a Multilayer Perceptron, which efficiently predicts the collision state of the robot from the CAE and the robot's configuration. We evaluate our framework on multiple planning problems with a variety of robots in 2D and 3D workspaces. The results show that (1) the framework is computationally efficient in all investigated problems, and (2) the framework generalizes well to new workspaces.
Solve fraud detection problem by using graph based learning methods
Aug 29, 2019The credit cards' fraud transactions detection is the important problem in machine learning field. To detect the credit cards's fraud transactions help reduce the significant loss of the credit cards' holders and the banks. To detect the credit cards' fraud transactions, data scientists normally employ the unsupervised learning techniques and supervised learning techniques. In this paper, we employ the graph p-Laplacian based semi-supervised learning methods combined with the undersampling techniques such as Cluster Centroids to solve the credit cards' fraud transactions detection problem. Experimental results show that the graph p-Laplacian semi-supervised learning methods outperform the current state of the art graph Laplacian based semi-supervised learning method (p=2).
Point cloud denoising based on tensor Tucker decomposition
Feb 20, 2019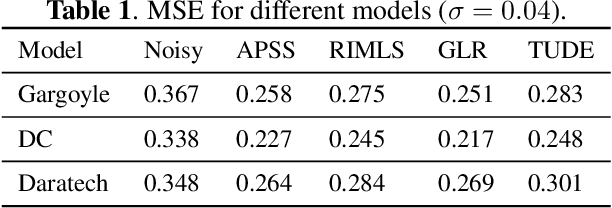

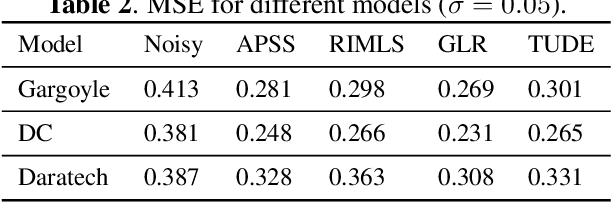
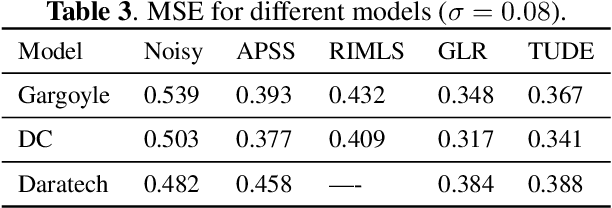
In this paper, we propose an algorithm for point cloud denoising based on the tensor Tucker decomposition. We first represent the local surface patches of a noisy point cloud to be matrices by their distances to a reference point, and stack the similar patch matrices to be a 3rd order tensor. Then we use the Tucker decomposition to compress this patch tensor to be a core tensor of smaller size. We consider this core tensor as the frequency domain and remove the noise by manipulating the hard thresholding. Finally, all the fibers of the denoised patch tensor are placed back, and the average is taken if there are more than one estimators overlapped. The experimental evaluation shows that the proposed algorithm outperforms the state-of-the-art graph Laplacian regularized (GLR) algorithm when the Gaussian noise is high ($\sigma=0.1$), and the GLR algorithm is better in lower noise cases ($\sigma=0.04, 0.05, 0.08$).