 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAION: Next-Generation Tasks and Practical Harness for Time Series
May 24, 2026Time series research is moving beyond fixed forecasting benchmarks toward realistic tasks that combine prediction, contextual reasoning, tool use, and structured decision support. Most benchmarks are built around clean data and short evaluation loops; agents alone may miss temporal constraints, evidence checks, or review before finalizing outputs. We first formalize next-generation time series tasks as three-component tuples consisting of a task file, a workspace, and a validation interface. We then present AION, a time series harness built from six component groups: agents, skills, rules, memory, evaluation, and protocols. In this harness, we use three design principles: temporal grounding, temporal knowledge-grounded reasoning, and reliability mechanisms such as post-experiment analysis and layered review. A Kaggle Store Sales case study shows that the harness produces more detailed process traces, more artifacts, and more review steps than the same base agent operating in OpenCode direct build mode. Taken together, these results argue for a paradigm shift from fixed tasks to realistic ones under real-world constraints.
PhySE: A Psychological Framework for Real-Time AR-LLM Social Engineering Attacks
Apr 25, 2026The emerging threat of AR-LLM-based Social Engineering (AR-LLM-SE) attacks (e.g. SEAR) poses a significant risk to real-world social interactions. In such an attack, a malicious actor uses Augmented Reality (AR) glasses to capture a target visual and vocal data. A Large Language Model (LLM) then analyzes this data to identify the individual and generate a detailed social profile. Subsequently, LLM-powered agents employ social engineering strategies, providing real-time conversation suggestions, to gain the target trust and ultimately execute phishing or other malicious acts. Despite its potential, the practical application of AR-LLM-SE faces two major bottlenecks, (1) Cold-start personalization, Current Retrieval-Augmented Generation (RAG) methods introduce critical delays in the earliest turns, slowing initial profile formation and disrupting real-time interaction, (2) Static Attack Strategies, Existing approaches rely on fixed-stage, handcrafted social engineering tactics that lack foundation in established psychological theory. To address these limitations, we propose PhySE, a novel framework with two core innovations, (1) VLM-Based SocialContext Training, To eliminate profiling delays, we efficiently pre-train a Visual Language Model (VLM) with social-context data, enabling rapid, on-the-fly profile generation, (2) Adaptive Psychological Agent, We introduce a psychological LLM that dynamically deploys distinct classes of psychological strategies based on target response, moving beyond static, handcrafted scripts. We evaluated PhySE through an IRB-approved user study with 60 participants, collecting a novel dataset of 360 annotated conversations across diverse social scenarios.
TimeOmni-VL: Unified Models for Time Series Understanding and Generation
Feb 19, 2026Recent time series modeling faces a sharp divide between numerical generation and semantic understanding, with research showing that generation models often rely on superficial pattern matching, while understanding-oriented models struggle with high-fidelity numerical output. Although unified multimodal models (UMMs) have bridged this gap in vision, their potential for time series remains untapped. We propose TimeOmni-VL, the first vision-centric framework that unifies time series understanding and generation through two key innovations: (1) Fidelity-preserving bidirectional mapping between time series and images (Bi-TSI), which advances Time Series-to-Image (TS2I) and Image-to-Time Series (I2TS) conversions to ensure near-lossless transformations. (2) Understanding-guided generation. We introduce TSUMM-Suite, a novel dataset consists of six understanding tasks rooted in time series analytics that are coupled with two generation tasks. With a calibrated Chain-of-Thought, TimeOmni-VL is the first to leverage time series understanding as an explicit control signal for high-fidelity generation. Experiments confirm that this unified approach significantly improves both semantic understanding and numerical precision, establishing a new frontier for multimodal time series modeling.
PocketCare: Tracking the Flu with Mobile Phones using Partial Observations of Proximity and Symptoms
May 07, 2019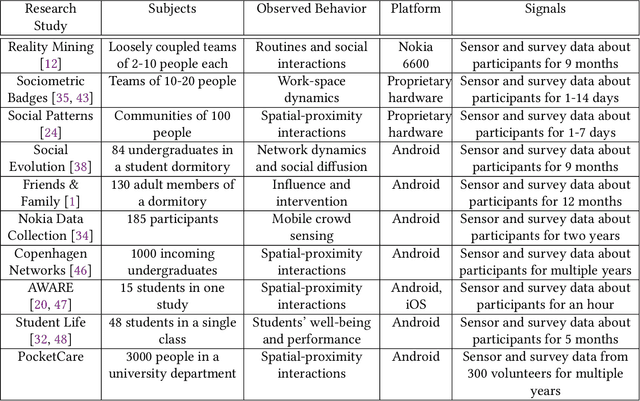
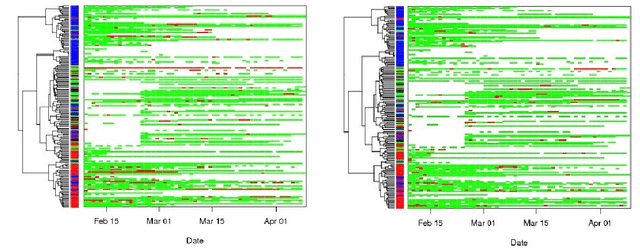
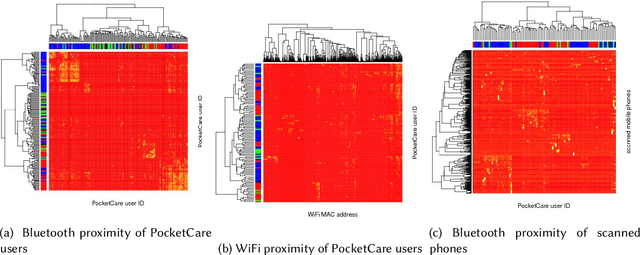
Mobile phones provide a powerful sensing platform that researchers may adopt to understand proximity interactions among people and the diffusion, through these interactions, of diseases, behaviors, and opinions. However, it remains a challenge to track the proximity-based interactions of a whole community and then model the social diffusion of diseases and behaviors starting from the observations of a small fraction of the volunteer population. In this paper, we propose a novel approach that tries to connect together these sparse observations using a model of how individuals interact with each other and how social interactions happen in terms of a sequence of proximity interactions. We apply our approach to track the spreading of flu in the spatial-proximity network of a 3000-people university campus by mobilizing 300 volunteers from this population to monitor nearby mobile phones through Bluetooth scanning and to daily report flu symptoms about and around them. Our aim is to predict the likelihood for an individual to get flu based on how often her/his daily routine intersects with those of the volunteers. Thus, we use the daily routines of the volunteers to build a model of the volunteers as well as of the non-volunteers. Our results show that we can predict flu infection two weeks ahead of time with an average precision from 0.24 to 0.35 depending on the amount of information. This precision is six to nine times higher than with a random guess model. At the population level, we can predict infectious population in a two-week window with an r-squared value of 0.95 (a random-guess model obtains an r-squared value of 0.2). These results point to an innovative approach for tracking individuals who have interacted with people showing symptoms, allowing us to warn those in danger of infection and to inform health researchers about the progression of contact-induced diseases.