 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural network-based virtual microphone estimation with virtual microphone and beamformer-level multi-task loss
Nov 20, 2023


Array processing performance depends on the number of microphones available. Virtual microphone estimation (VME) has been proposed to increase the number of microphone signals artificially. Neural network-based VME (NN-VME) trains an NN with a VM-level loss to predict a signal at a microphone location that is available during training but not at inference. However, this training objective may not be optimal for a specific array processing back-end, such as beamforming. An alternative approach is to use a training objective considering the array-processing back-end, such as a loss on the beamformer output. This approach may generate signals optimal for beamforming but not physically grounded. To combine the advantages of both approaches, this paper proposes a multi-task loss for NN-VME that combines both VM-level and beamformer-level losses. We evaluate the proposed multi-task NN-VME on multi-talker underdetermined conditions and show that it achieves a 33.1 % relative WER improvement compared to using only real microphones and 10.8 % compared to using a prior NN-VME approach.
Target Speech Extraction with Conditional Diffusion Model
Aug 17, 2023



Diffusion model-based speech enhancement has received increased attention since it can generate very natural enhanced signals and generalizes well to unseen conditions. Diffusion models have been explored for several sub-tasks of speech enhancement, such as speech denoising, dereverberation, and source separation. In this paper, we investigate their use for target speech extraction (TSE), which consists of estimating the clean speech signal of a target speaker in a mixture of multi-talkers. TSE is realized by conditioning the extraction process on a clue identifying the target speaker. We show we can realize TSE using a conditional diffusion model conditioned on the clue. Besides, we introduce ensemble inference to reduce potential extraction errors caused by the diffusion process. In experiments on Libri2mix corpus, we show that the proposed diffusion model-based TSE combined with ensemble inference outperforms a comparable TSE system trained discriminatively.
Modified Parametric Multichannel Wiener Filter \\for Low-latency Enhancement of Speech Mixtures with Unknown Number of Speakers
Jun 29, 2023



This paper introduces a novel low-latency online beamforming (BF) algorithm, named Modified Parametric Multichannel Wiener Filter (Mod-PMWF), for enhancing speech mixtures with unknown and varying number of speakers. Although conventional BFs such as linearly constrained minimum variance BF (LCMV BF) can enhance a speech mixture, they typically require such attributes of the speech mixture as the number of speakers and the acoustic transfer functions (ATFs) from the speakers to the microphones. When the mixture attributes are unavailable, estimating them by low-latency processing is challenging, hindering the application of the BFs to the problem. In this paper, we overcome this problem by modifying a conventional Parametric Multichannel Wiener Filter (PMWF). The proposed Mod-PMWF can adaptively form a directivity pattern that enhances all the speakers in the mixture without explicitly estimating these attributes. Our experiments will show the proposed BF's effectiveness in interference reduction ratios and subjective listening tests.
NoisyILRMA: Diffuse-Noise-Aware Independent Low-Rank Matrix Analysis for Fast Blind Source Extraction
Jun 22, 2023


In this paper, we address the multichannel blind source extraction (BSE) of a single source in diffuse noise environments. To solve this problem even faster than by fast multichannel nonnegative matrix factorization (FastMNMF) and its variant, we propose a BSE method called NoisyILRMA, which is a modification of independent low-rank matrix analysis (ILRMA) to account for diffuse noise. NoisyILRMA can achieve considerably fast BSE by incorporating an algorithm developed for independent vector extraction. In addition, to improve the BSE performance of NoisyILRMA, we propose a mechanism to switch the source model with ILRMA-like nonnegative matrix factorization to a more expressive source model during optimization. In the experiment, we show that NoisyILRMA runs faster than a FastMNMF algorithm while maintaining the BSE performance. We also confirm that the switching mechanism improves the BSE performance of NoisyILRMA.
Multi-Stream Extension of Variational Bayesian HMM Clustering (MS-VBx) for Combined End-to-End and Vector Clustering-based Diarization
May 23, 2023


Combining end-to-end neural speaker diarization (EEND) with vector clustering (VC), known as EEND-VC, has gained interest for leveraging the strengths of both methods. EEND-VC estimates activities and speaker embeddings for all speakers within an audio chunk and uses VC to associate these activities with speaker identities across different chunks. EEND-VC generates thus multiple streams of embeddings, one for each speaker in a chunk. We can cluster these embeddings using constrained agglomerative hierarchical clustering (cAHC), ensuring embeddings from the same chunk belong to different clusters. This paper introduces an alternative clustering approach, a multi-stream extension of the successful Bayesian HMM clustering of x-vectors (VBx), called MS-VBx. Experiments on three datasets demonstrate that MS-VBx outperforms cAHC in diarization and speaker counting performance.
Mask-based Neural Beamforming for Moving Speakers with Self-Attention-based Tracking
May 07, 2022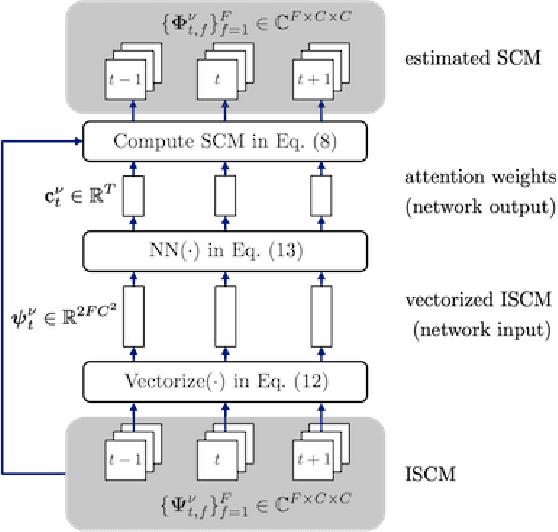
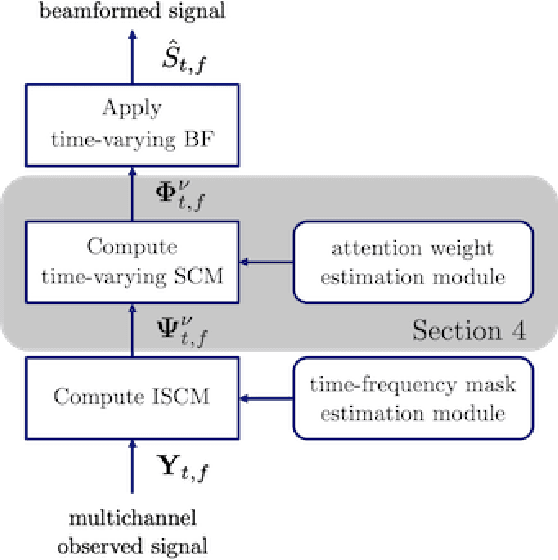
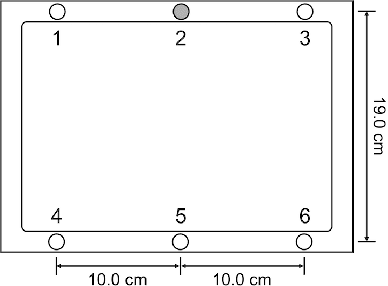
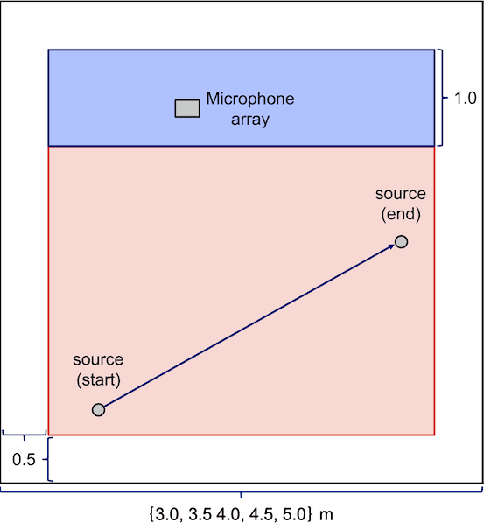
Beamforming is a powerful tool designed to enhance speech signals from the direction of a target source. Computing the beamforming filter requires estimating spatial covariance matrices (SCMs) of the source and noise signals. Time-frequency masks are often used to compute these SCMs. Most studies of mask-based beamforming have assumed that the sources do not move. However, sources often move in practice, which causes performance degradation. In this paper, we address the problem of mask-based beamforming for moving sources. We first review classical approaches to tracking a moving source, which perform online or blockwise computation of the SCMs. We show that these approaches can be interpreted as computing a sum of instantaneous SCMs weighted by attention weights. These weights indicate which time frames of the signal to consider in the SCM computation. Online or blockwise computation assumes a heuristic and deterministic way of computing these attention weights that, although simple, may not result in optimal performance. We thus introduce a learning-based framework that computes optimal attention weights for beamforming. We achieve this using a neural network implemented with self-attention layers. We show experimentally that our proposed framework can greatly improve beamforming performance in moving source situations while maintaining high performance in non-moving situations, thus enabling the development of mask-based beamformers robust to source movements.
Listen only to me! How well can target speech extraction handle false alarms?
Apr 11, 2022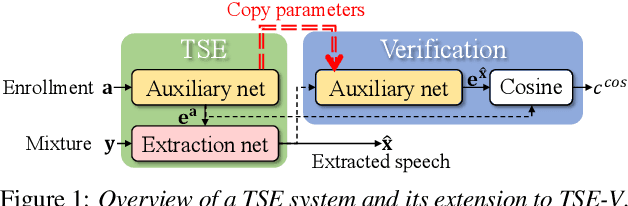
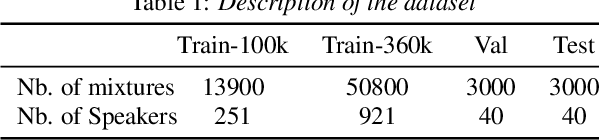
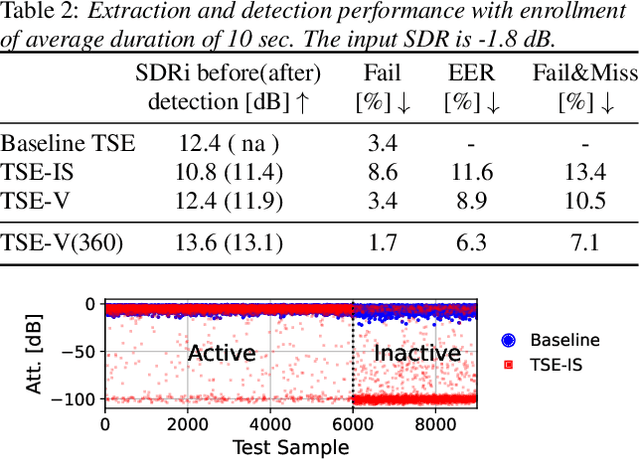
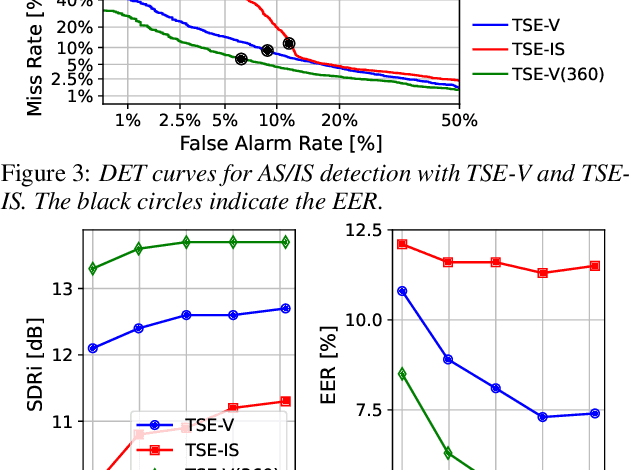
Target speech extraction (TSE) extracts the speech of a target speaker in a mixture given auxiliary clues characterizing the speaker, such as an enrollment utterance. TSE addresses thus the challenging problem of simultaneously performing separation and speaker identification. There has been much progress in extraction performance following the recent development of neural networks for speech enhancement and separation. Most studies have focused on processing mixtures where the target speaker is actively speaking. However, the target speaker is sometimes silent in practice, i.e., inactive speaker (IS). A typical TSE system will tend to output a signal in IS cases, causing false alarms. This is a severe problem for the practical deployment of TSE systems. This paper aims at understanding better how well TSE systems can handle IS cases. We consider two approaches to deal with IS, (1) training a system to directly output zero signals or (2) detecting IS with an extra speaker verification module. We perform an extensive experimental comparison of these schemes in terms of extraction performance and IS detection using the LibriMix dataset and reveal their pros and cons.
Subjective intelligibility of speech sounds enhanced by ideal ratio mask via crowdsourced remote experiments with effective data screening
Mar 31, 2022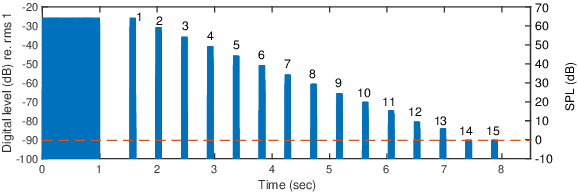
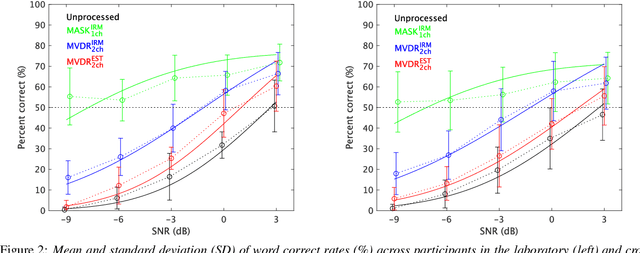
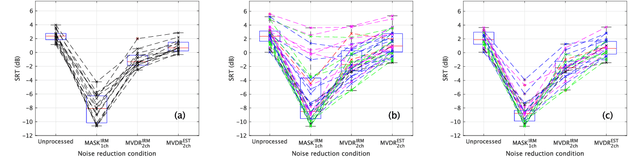
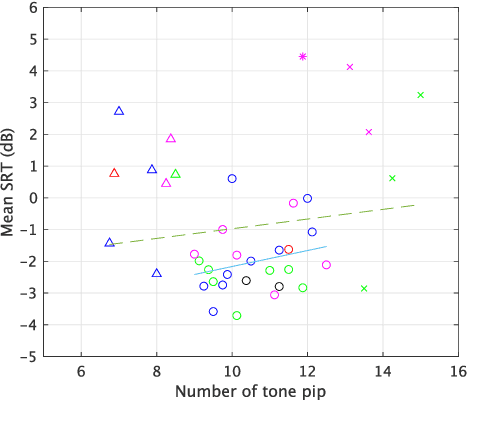
It is essential to perform speech intelligibility (SI) experiments with human listeners to evaluate the effectiveness of objective intelligibility measures. Recently crowdsourced remote testing has become popular to collect a massive amount and variety of data with relatively small cost and in short time. However, careful data screening is essential for attaining reliable SI data. We compared the results of laboratory and crowdsourced remote experiments to establish an effective data screening technique. We evaluated the SI of noisy speech sounds enhanced by a single-channel ideal ratio mask (IRM) and multi-channel mask-based beamformers. The results demonstrated that the SI scores were improved by these enhancement methods. In particular, the IRM-enhanced sounds were much better than the unprocessed and other enhanced sounds, indicating IRM enhancement may give the upper limit of speech enhancement performance. Moreover, tone pip tests, for which participants were asked to report the number of audible tone pips, reduced the variability of crowdsourced remote results so that the laboratory results became similar. Tone pip tests could be useful for future crowdsourced experiments because of their simplicity and effectiveness for data screening.
$\text{ISS}_2$: An Extension of Iterative Source Steering Algorithm for Majorization-Minimization-Based Independent Vector Analysis
Feb 02, 2022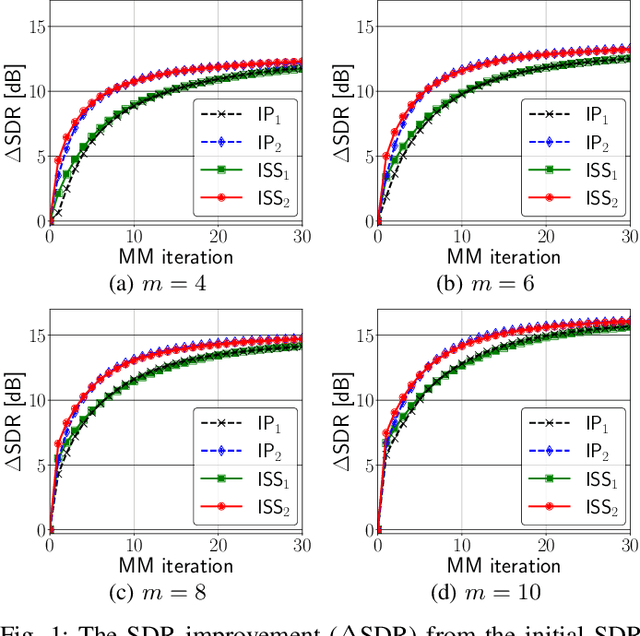
A majorization-minimization (MM) algorithm for independent vector analysis optimizes a separation matrix $W = [w_1, \ldots, w_m]^h \in \mathbb{C}^{m \times m}$ by minimizing a surrogate function of the form $\mathcal{L}(W) = \sum_{i = 1}^m w_i^h V_i w_i - \log | \det W |^2$, where $m \in \mathbb{N}$ is the number of sensors and positive definite matrices $V_1,\ldots,V_m \in \mathbb{C}^{m \times m}$ are constructed in each MM iteration. For $m \geq 3$, no algorithm has been found to obtain a global minimum of $\mathcal{L}(W)$. Instead, block coordinate descent (BCD) methods with closed-form update formulas have been developed for minimizing $\mathcal{L}(W)$ and shown to be effective. One such BCD is called iterative projection (IP) that updates one or two rows of $W$ in each iteration. Another BCD is called iterative source steering (ISS) that updates one column of the mixing matrix $A = W^{-1}$ in each iteration. Although the time complexity per iteration of ISS is $m$ times smaller than that of IP, the conventional ISS converges slower than the current fastest IP (called $\text{IP}_2$) that updates two rows of $W$ in each iteration. We here extend this ISS to $\text{ISS}_2$ that can update two columns of $A$ in each iteration while maintaining its small time complexity. To this end, we provide a unified way for developing new ISS type methods from which $\text{ISS}_2$ as well as the conventional ISS can be immediately obtained in a systematic manner. Numerical experiments to separate reverberant speech mixtures show that our $\text{ISS}_2$ converges in fewer MM iterations than the conventional ISS, and is comparable to $\text{IP}_2$.
Switching Independent Vector Analysis and Its Extension to Blind and Spatially Guided Convolutional Beamforming Algorithm
Nov 20, 2021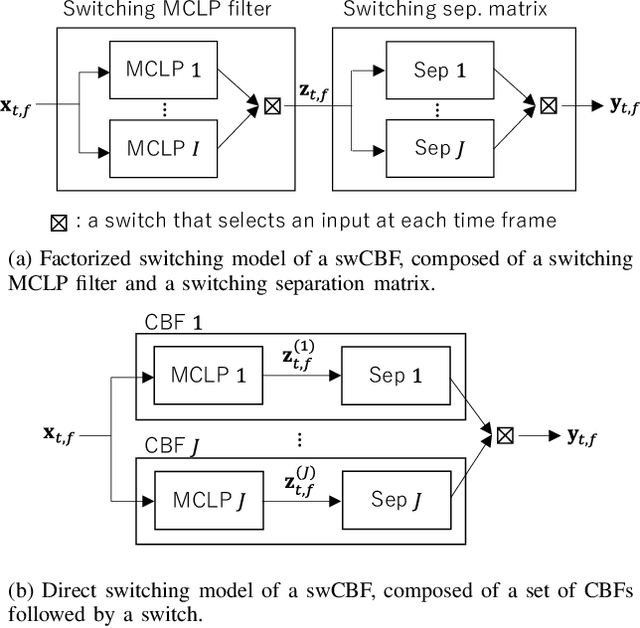
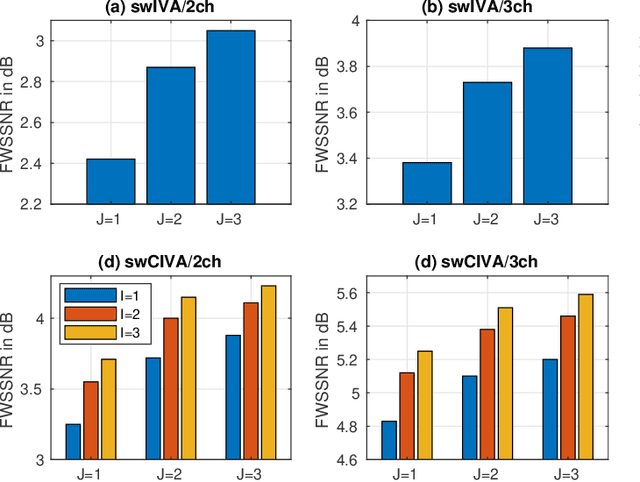
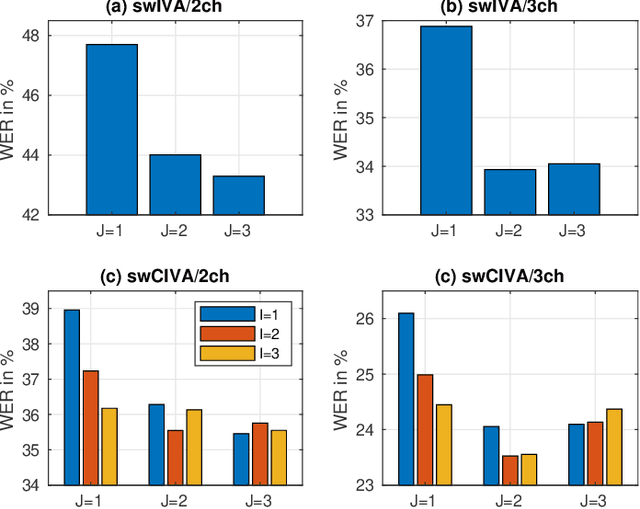
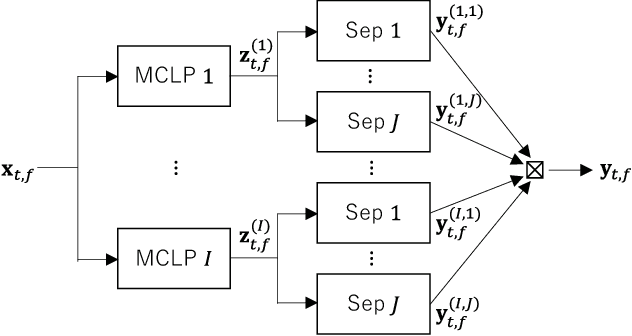
This paper develops a framework that can perform denoising, dereverberation, and source separation accurately by using a relatively small number of microphones. It has been empirically confirmed that Independent Vector Analysis (IVA) can blindly separate $N$ sources from their sound mixture even with diffuse noise when a sufficiently large number ($=M$) of microphones are available (i.e., $M\gg N)$. However, the estimation accuracy seriously degrades as the number of microphones, or more specifically $M-N$ $(\ge 0)$, decreases. To overcome this limitation of IVA, we propose switching IVA (swIVA) in this paper. With swIVA, time frames of an observed signal with time-varying characteristics are clustered into several groups, each of which can be well handled by IVA using a small number of microphones, and thus accurate estimation can be achieved by applying {\IVA} individually to each of the groups. Conventionally, a switching mechanism was introduced into a beamformer; however, no blind source separation algorithms with a switching mechanism have been successfully developed until this paper. In order to incorporate dereverberation capability, this paper further extends swIVA to blind Convolutional beamforming algorithm (swCIVA). It integrates swIVA and switching Weighted Prediction Error-based dereverberation (swWPE) in a jointly optimal way. We show that both swIVA and swIVAconv can be optimized effectively based on blind signal processing, and that their performance can be further improved using a spatial guide for the initialization. Experiments show that the both proposed methods largely outperform conventional IVA and its Convolutional beamforming extension (CIVA) in terms of objective signal quality and automatic speech recognition scores when using a relatively small number of microphones.