 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Dereverberation, Beamforming, and Speech Recognition with Improved Numerical Stability and Advanced Frontend
Paper and Code
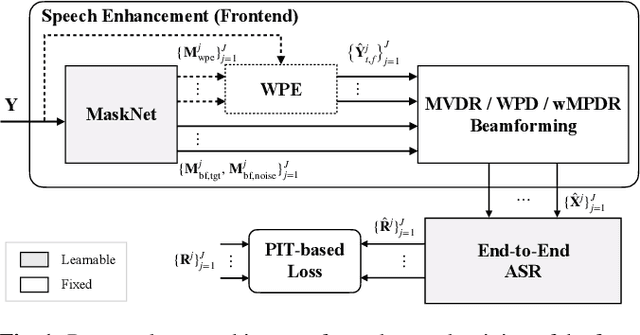
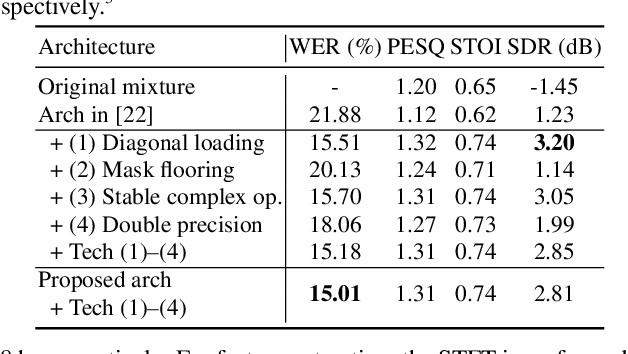
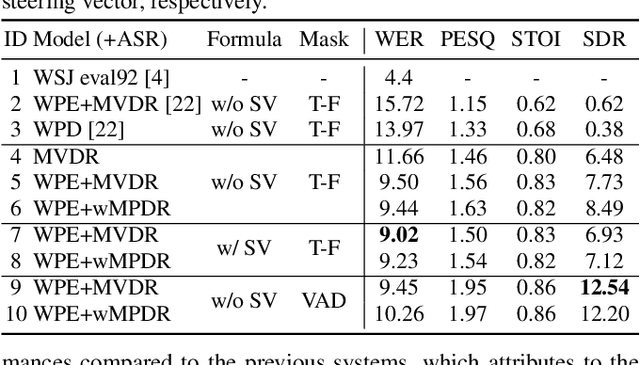
Recently, the end-to-end approach has been successfully applied to multi-speaker speech separation and recognition in both single-channel and multichannel conditions. However, severe performance degradation is still observed in the reverberant and noisy scenarios, and there is still a large performance gap between anechoic and reverberant conditions. In this work, we focus on the multichannel multi-speaker reverberant condition, and propose to extend our previous framework for end-to-end dereverberation, beamforming, and speech recognition with improved numerical stability and advanced frontend subnetworks including voice activity detection like masks. The techniques significantly stabilize the end-to-end training process. The experiments on the spatialized wsj1-2mix corpus show that the proposed system achieves about 35% WER relative reduction compared to our conventional multi-channel E2E ASR system, and also obtains decent speech dereverberation and separation performance (SDR=12.5 dB) in the reverberant multi-speaker condition while trained only with the ASR criterion.