 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndependent Deeply Learned Tensor Analysis for Determined Audio Source Separation
Paper and Code
Jun 10, 2021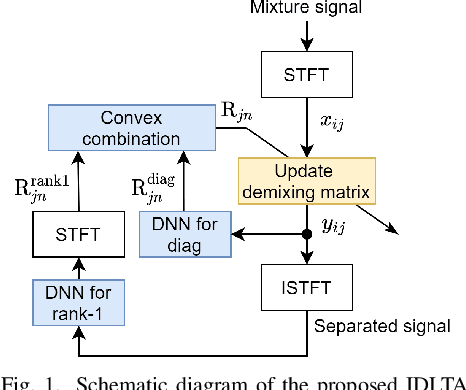

We address the determined audio source separation problem in the time-frequency domain. In independent deeply learned matrix analysis (IDLMA), it is assumed that the inter-frequency correlation of each source spectrum is zero, which is inappropriate for modeling nonstationary signals such as music signals. To account for the correlation between frequencies, independent positive semidefinite tensor analysis has been proposed. This unsupervised (blind) method, however, severely restrict the structure of frequency covariance matrices (FCMs) to reduce the number of model parameters. As an extension of these conventional approaches, we here propose a supervised method that models FCMs using deep neural networks (DNNs). It is difficult to directly infer FCMs using DNNs. Therefore, we also propose a new FCM model represented as a convex combination of a diagonal FCM and a rank-1 FCM. Our FCM model is flexible enough to not only consider inter-frequency correlation, but also capture the dynamics of time-varying FCMs of nonstationary signals. We infer the proposed FCMs using two DNNs: DNN for power spectrum estimation and DNN for time-domain signal estimation. An experimental result of separating music signals shows that the proposed method provides higher separation performance than IDLMA.