 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLossy Compression with Gaussian Diffusion
Jun 17, 2022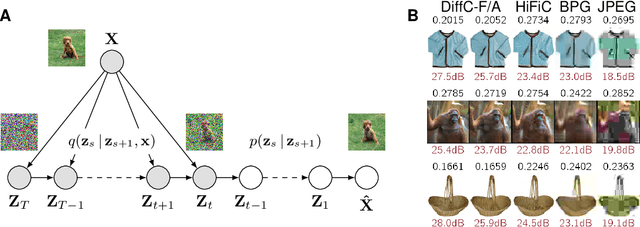
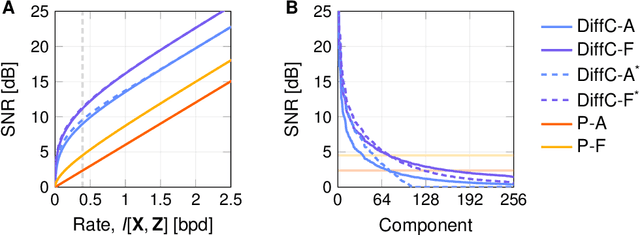
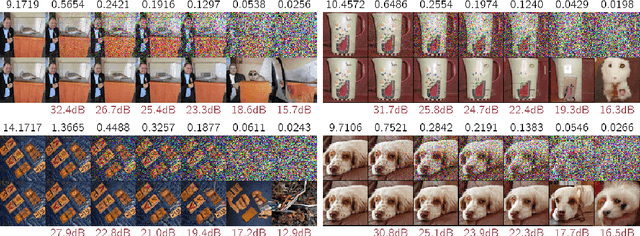
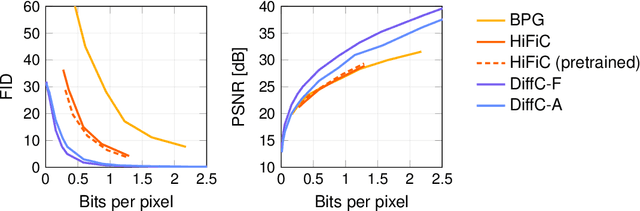
We describe a novel lossy compression approach called DiffC which is based on unconditional diffusion generative models. Unlike modern compression schemes which rely on transform coding and quantization to restrict the transmitted information, DiffC relies on the efficient communication of pixels corrupted by Gaussian noise. We implement a proof of concept and find that it works surprisingly well despite the lack of an encoder transform, outperforming the state-of-the-art generative compression method HiFiC on ImageNet 64x64. DiffC only uses a single model to encode and denoise corrupted pixels at arbitrary bitrates. The approach further provides support for progressive coding, that is, decoding from partial bit streams. We perform a rate-distortion analysis to gain a deeper understanding of its performance, providing analytical results for multivariate Gaussian data as well as initial results for general distributions. Furthermore, we show that a flow-based reconstruction achieves a 3 dB gain over ancestral sampling at high bitrates.
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
May 23, 2022

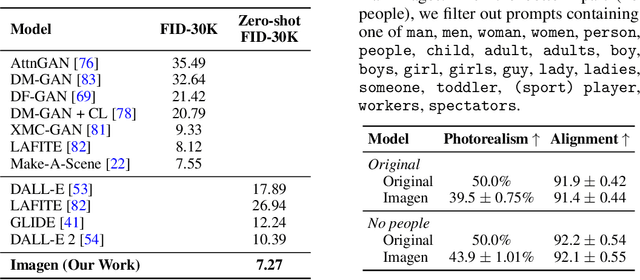
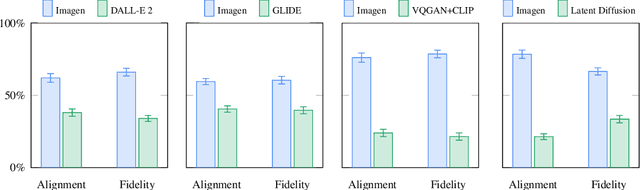
We present Imagen, a text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding. Imagen builds on the power of large transformer language models in understanding text and hinges on the strength of diffusion models in high-fidelity image generation. Our key discovery is that generic large language models (e.g. T5), pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis: increasing the size of the language model in Imagen boosts both sample fidelity and image-text alignment much more than increasing the size of the image diffusion model. Imagen achieves a new state-of-the-art FID score of 7.27 on the COCO dataset, without ever training on COCO, and human raters find Imagen samples to be on par with the COCO data itself in image-text alignment. To assess text-to-image models in greater depth, we introduce DrawBench, a comprehensive and challenging benchmark for text-to-image models. With DrawBench, we compare Imagen with recent methods including VQ-GAN+CLIP, Latent Diffusion Models, and DALL-E 2, and find that human raters prefer Imagen over other models in side-by-side comparisons, both in terms of sample quality and image-text alignment. See https://imagen.research.google/ for an overview of the results.
Video Diffusion Models
Apr 07, 2022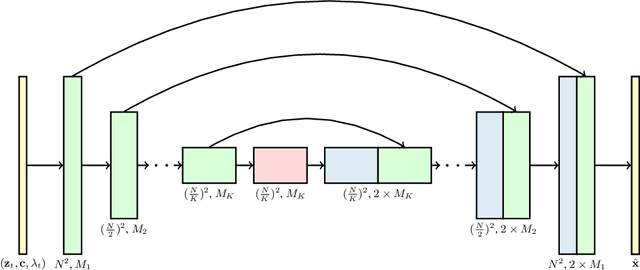
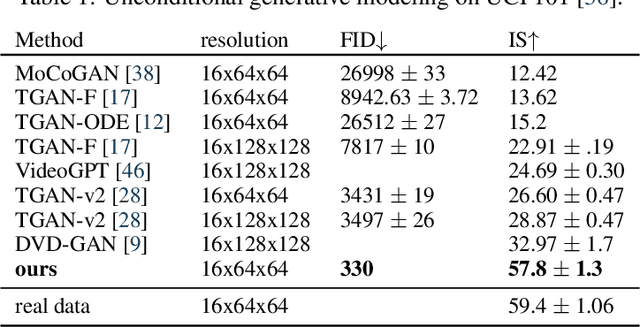


Generating temporally coherent high fidelity video is an important milestone in generative modeling research. We make progress towards this milestone by proposing a diffusion model for video generation that shows very promising initial results. Our model is a natural extension of the standard image diffusion architecture, and it enables jointly training from image and video data, which we find to reduce the variance of minibatch gradients and speed up optimization. To generate long and higher resolution videos we introduce a new conditional sampling technique for spatial and temporal video extension that performs better than previously proposed methods. We present the first results on a large text-conditioned video generation task, as well as state-of-the-art results on an established unconditional video generation benchmark. Supplementary material is available at https://video-diffusion.github.io/
Progressive Distillation for Fast Sampling of Diffusion Models
Feb 01, 2022

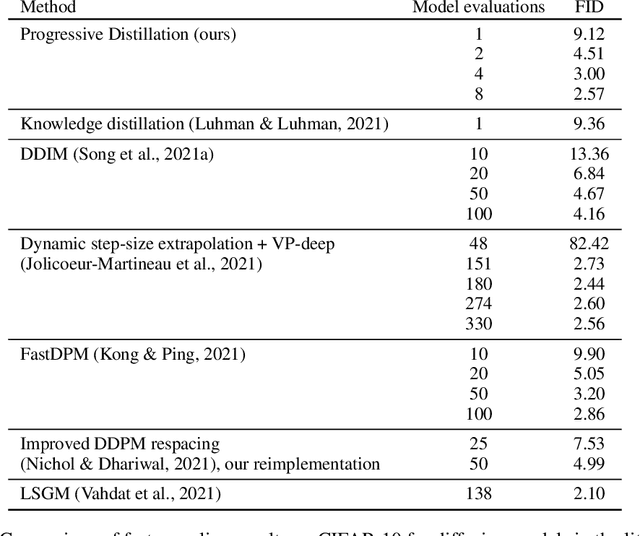
Diffusion models have recently shown great promise for generative modeling, outperforming GANs on perceptual quality and autoregressive models at density estimation. A remaining downside is their slow sampling time: generating high quality samples takes many hundreds or thousands of model evaluations. Here we make two contributions to help eliminate this downside: First, we present new parameterizations of diffusion models that provide increased stability when using few sampling steps. Second, we present a method to distill a trained deterministic diffusion sampler, using many steps, into a new diffusion model that takes half as many sampling steps. We then keep progressively applying this distillation procedure to our model, halving the number of required sampling steps each time. On standard image generation benchmarks like CIFAR-10, ImageNet, and LSUN, we start out with state-of-the-art samplers taking as many as 8192 steps, and are able to distill down to models taking as few as 4 steps without losing much perceptual quality; achieving, for example, a FID of 3.0 on CIFAR-10 in 4 steps. Finally, we show that the full progressive distillation procedure does not take more time than it takes to train the original model, thus representing an efficient solution for generative modeling using diffusion at both train and test time.
Palette: Image-to-Image Diffusion Models
Nov 10, 2021
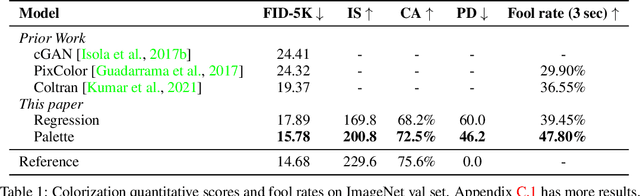

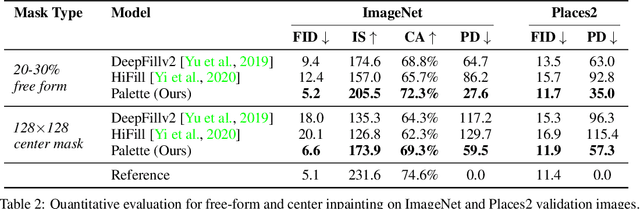
We introduce Palette, a simple and general framework for image-to-image translation using conditional diffusion models. On four challenging image-to-image translation tasks (colorization, inpainting, uncropping, and JPEG decompression), Palette outperforms strong GAN and regression baselines, and establishes a new state of the art. This is accomplished without task-specific hyper-parameter tuning, architecture customization, or any auxiliary loss, demonstrating a desirable degree of generality and flexibility. We uncover the impact of using $L_2$ vs. $L_1$ loss in the denoising diffusion objective on sample diversity, and demonstrate the importance of self-attention through empirical architecture studies. Importantly, we advocate a unified evaluation protocol based on ImageNet, and report several sample quality scores including FID, Inception Score, Classification Accuracy of a pre-trained ResNet-50, and Perceptual Distance against reference images for various baselines. We expect this standardized evaluation protocol to play a critical role in advancing image-to-image translation research. Finally, we show that a single generalist Palette model trained on 3 tasks (colorization, inpainting, JPEG decompression) performs as well or better than task-specific specialist counterparts.
Autoregressive Diffusion Models
Oct 05, 2021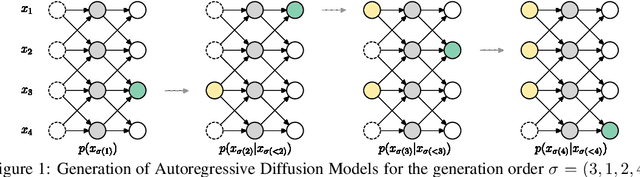

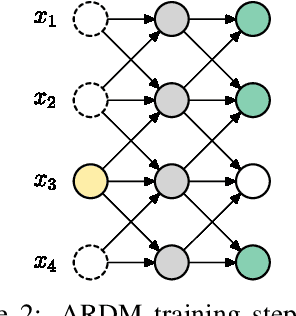

We introduce Autoregressive Diffusion Models (ARDMs), a model class encompassing and generalizing order-agnostic autoregressive models (Uria et al., 2014) and absorbing discrete diffusion (Austin et al., 2021), which we show are special cases of ARDMs under mild assumptions. ARDMs are simple to implement and easy to train. Unlike standard ARMs, they do not require causal masking of model representations, and can be trained using an efficient objective similar to modern probabilistic diffusion models that scales favourably to highly-dimensional data. At test time, ARDMs support parallel generation which can be adapted to fit any given generation budget. We find that ARDMs require significantly fewer steps than discrete diffusion models to attain the same performance. Finally, we apply ARDMs to lossless compression, and show that they are uniquely suited to this task. Contrary to existing approaches based on bits-back coding, ARDMs obtain compelling results not only on complete datasets, but also on compressing single data points. Moreover, this can be done using a modest number of network calls for (de)compression due to the model's adaptable parallel generation.
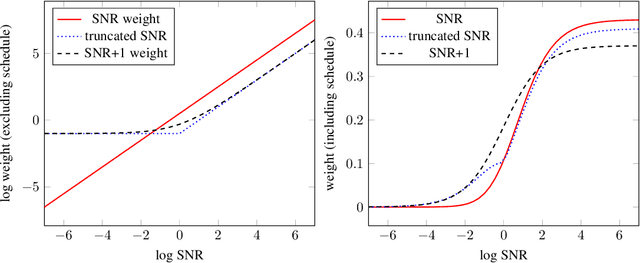
Variational Diffusion Models
Jul 12, 2021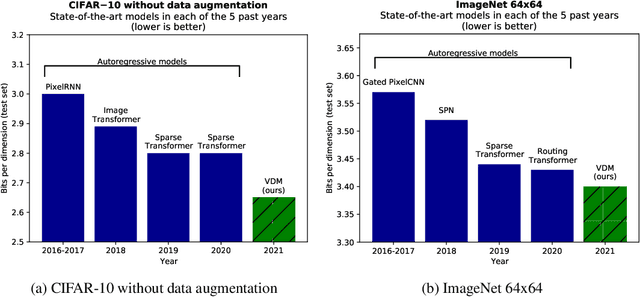
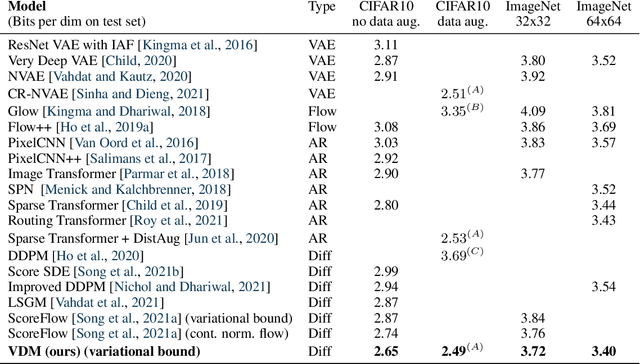

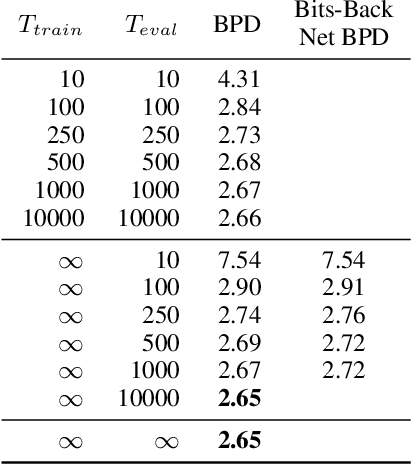
Diffusion-based generative models have demonstrated a capacity for perceptually impressive synthesis, but can they also be great likelihood-based models? We answer this in the affirmative, and introduce a family of diffusion-based generative models that obtain state-of-the-art likelihoods on standard image density estimation benchmarks. Unlike other diffusion-based models, our method allows for efficient optimization of the noise schedule jointly with the rest of the model. We show that the variational lower bound (VLB) simplifies to a remarkably short expression in terms of the signal-to-noise ratio of the diffused data, thereby improving our theoretical understanding of this model class. Using this insight, we prove an equivalence between several models proposed in the literature. In addition, we show that the continuous-time VLB is invariant to the noise schedule, except for the signal-to-noise ratio at its endpoints. This enables us to learn a noise schedule that minimizes the variance of the resulting VLB estimator, leading to faster optimization. Combining these advances with architectural improvements, we obtain state-of-the-art likelihoods on image density estimation benchmarks, outperforming autoregressive models that have dominated these benchmarks for many years, with often significantly faster optimization. In addition, we show how to turn the model into a bits-back compression scheme, and demonstrate lossless compression rates close to the theoretical optimum.
Agent-Centric Representations for Multi-Agent Reinforcement Learning
Apr 19, 2021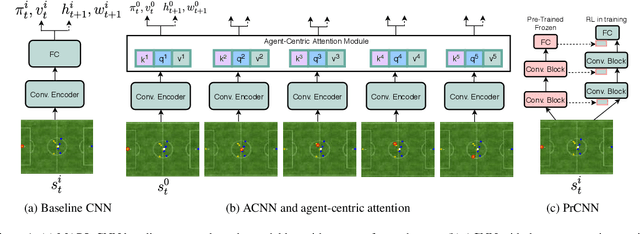

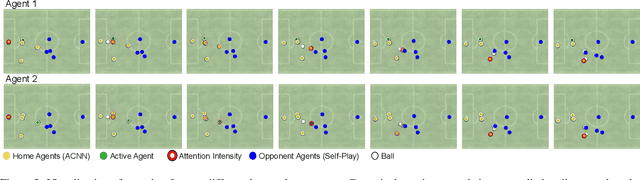

Object-centric representations have recently enabled significant progress in tackling relational reasoning tasks. By building a strong object-centric inductive bias into neural architectures, recent efforts have improved generalization and data efficiency of machine learning algorithms for these problems. One problem class involving relational reasoning that still remains under-explored is multi-agent reinforcement learning (MARL). Here we investigate whether object-centric representations are also beneficial in the fully cooperative MARL setting. Specifically, we study two ways of incorporating an agent-centric inductive bias into our RL algorithm: 1. Introducing an agent-centric attention module with explicit connections across agents 2. Adding an agent-centric unsupervised predictive objective (i.e. not using action labels), to be used as an auxiliary loss for MARL, or as the basis of a pre-training step. We evaluate these approaches on the Google Research Football environment as well as DeepMind Lab 2D. Empirically, agent-centric representation learning leads to the emergence of more complex cooperation strategies between agents as well as enhanced sample efficiency and generalization.
Image Super-Resolution via Iterative Refinement
Apr 15, 2021
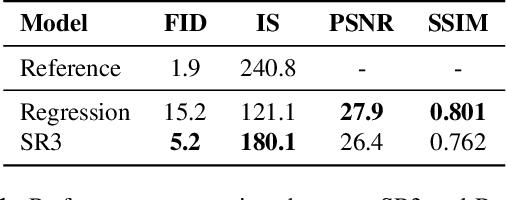
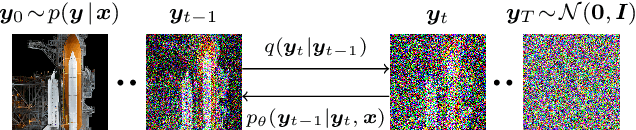

We present SR3, an approach to image Super-Resolution via Repeated Refinement. SR3 adapts denoising diffusion probabilistic models to conditional image generation and performs super-resolution through a stochastic denoising process. Inference starts with pure Gaussian noise and iteratively refines the noisy output using a U-Net model trained on denoising at various noise levels. SR3 exhibits strong performance on super-resolution tasks at different magnification factors, on faces and natural images. We conduct human evaluation on a standard 8X face super-resolution task on CelebA-HQ, comparing with SOTA GAN methods. SR3 achieves a fool rate close to 50%, suggesting photo-realistic outputs, while GANs do not exceed a fool rate of 34%. We further show the effectiveness of SR3 in cascaded image generation, where generative models are chained with super-resolution models, yielding a competitive FID score of 11.3 on ImageNet.
A Spectral Energy Distance for Parallel Speech Synthesis
Aug 03, 2020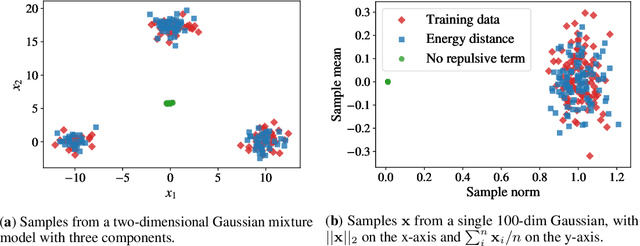
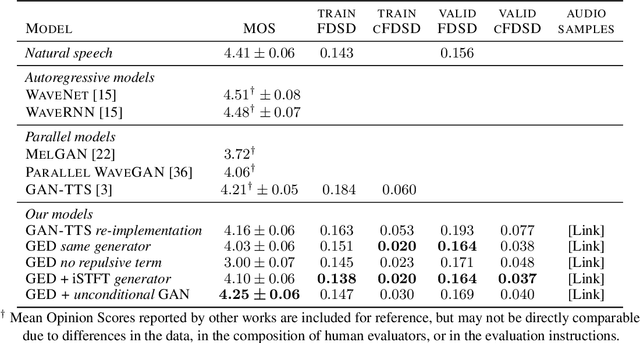
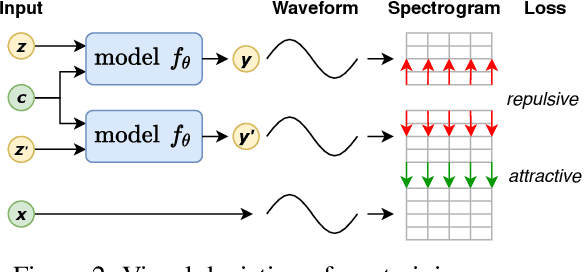
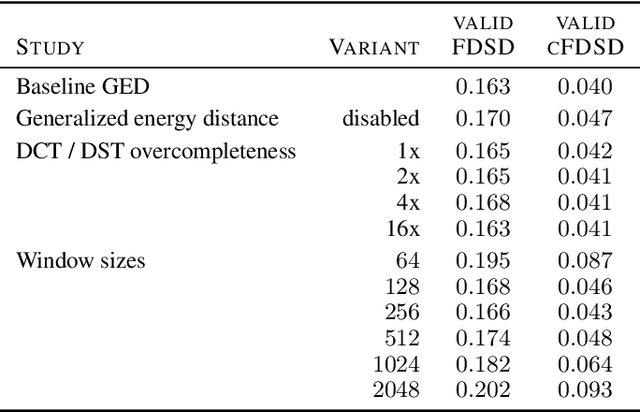
Speech synthesis is an important practical generative modeling problem that has seen great progress over the last few years, with likelihood-based autoregressive neural models now outperforming traditional concatenative systems. A downside of such autoregressive models is that they require executing tens of thousands of sequential operations per second of generated audio, making them ill-suited for deployment on specialized deep learning hardware. Here, we propose a new learning method that allows us to train highly parallel models of speech, without requiring access to an analytical likelihood function. Our approach is based on a generalized energy distance between the distributions of the generated and real audio. This spectral energy distance is a proper scoring rule with respect to the distribution over magnitude-spectrograms of the generated waveform audio and offers statistical consistency guarantees. The distance can be calculated from minibatches without bias, and does not involve adversarial learning, yielding a stable and consistent method for training implicit generative models. Empirically, we achieve state-of-the-art generation quality among implicit generative models, as judged by the recently-proposed cFDSD metric. When combining our method with adversarial techniques, we also improve upon the recently-proposed GAN-TTS model in terms of Mean Opinion Score as judged by trained human evaluators.