 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVox-Profile: A Speech Foundation Model Benchmark for Characterizing Diverse Speaker and Speech Traits
May 20, 2025We introduce Vox-Profile, a comprehensive benchmark to characterize rich speaker and speech traits using speech foundation models. Unlike existing works that focus on a single dimension of speaker traits, Vox-Profile provides holistic and multi-dimensional profiles that reflect both static speaker traits (e.g., age, sex, accent) and dynamic speech properties (e.g., emotion, speech flow). This benchmark is grounded in speech science and linguistics, developed with domain experts to accurately index speaker and speech characteristics. We report benchmark experiments using over 15 publicly available speech datasets and several widely used speech foundation models that target various static and dynamic speaker and speech properties. In addition to benchmark experiments, we showcase several downstream applications supported by Vox-Profile. First, we show that Vox-Profile can augment existing speech recognition datasets to analyze ASR performance variability. Vox-Profile is also used as a tool to evaluate the performance of speech generation systems. Finally, we assess the quality of our automated profiles through comparison with human evaluation and show convergent validity. Vox-Profile is publicly available at: https://github.com/tiantiaf0627/vox-profile-release.
Who Said What WSW 2.0? Enhanced Automated Analysis of Preschool Classroom Speech
May 15, 2025



This paper introduces an automated framework WSW2.0 for analyzing vocal interactions in preschool classrooms, enhancing both accuracy and scalability through the integration of wav2vec2-based speaker classification and Whisper (large-v2 and large-v3) speech transcription. A total of 235 minutes of audio recordings (160 minutes from 12 children and 75 minutes from 5 teachers), were used to compare system outputs to expert human annotations. WSW2.0 achieves a weighted F1 score of .845, accuracy of .846, and an error-corrected kappa of .672 for speaker classification (child vs. teacher). Transcription quality is moderate to high with word error rates of .119 for teachers and .238 for children. WSW2.0 exhibits relatively high absolute agreement intraclass correlations (ICC) with expert transcriptions for a range of classroom language features. These include teacher and child mean utterance length, lexical diversity, question asking, and responses to questions and other utterances, which show absolute agreement intraclass correlations between .64 and .98. To establish scalability, we apply the framework to an extensive dataset spanning two years and over 1,592 hours of classroom audio recordings, demonstrating the framework's robustness for broad real-world applications. These findings highlight the potential of deep learning and natural language processing techniques to revolutionize educational research by providing accurate measures of key features of preschool classroom speech, ultimately guiding more effective intervention strategies and supporting early childhood language development.
Ranking-aware Continual Learning for LiDAR Place Recognition
May 12, 2025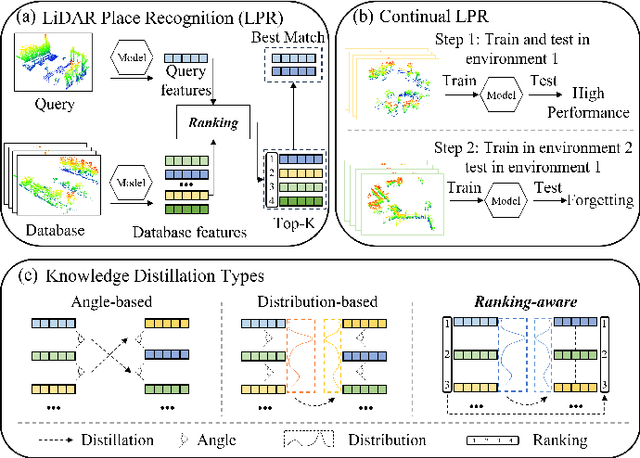
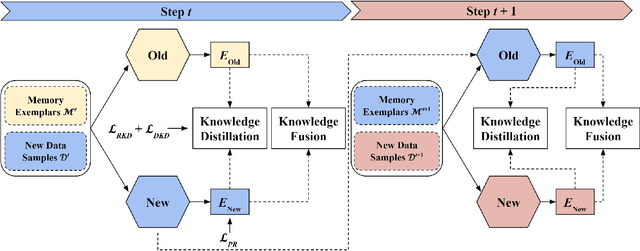
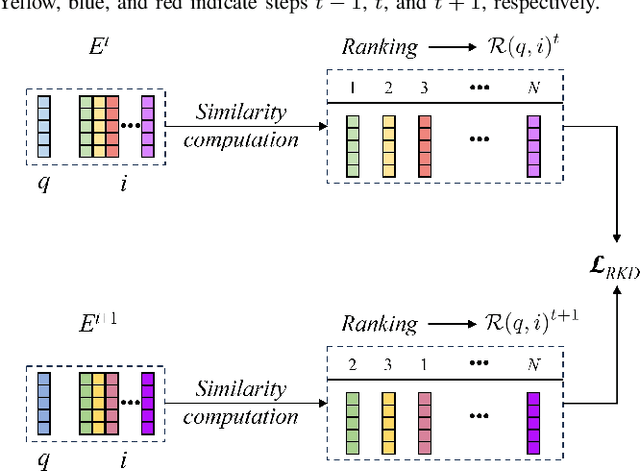
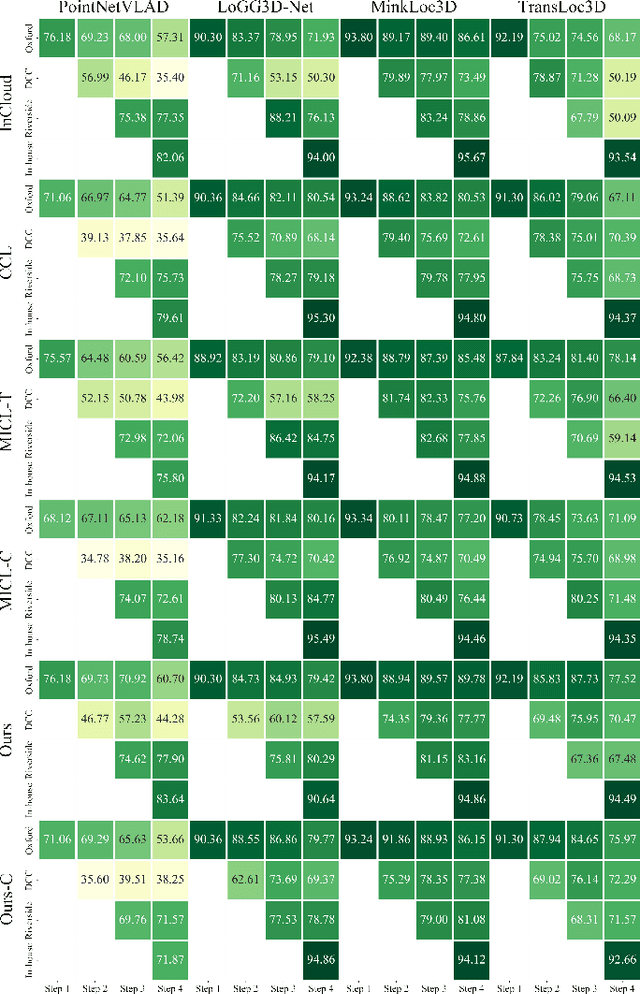
Place recognition plays a significant role in SLAM, robot navigation, and autonomous driving applications. Benefiting from deep learning, the performance of LiDAR place recognition (LPR) has been greatly improved. However, many existing learning-based LPR methods suffer from catastrophic forgetting, which severely harms the performance of LPR on previously trained places after training on a new environment. In this paper, we introduce a continual learning framework for LPR via Knowledge Distillation and Fusion (KDF) to alleviate forgetting. Inspired by the ranking process of place recognition retrieval, we present a ranking-aware knowledge distillation loss that encourages the network to preserve the high-level place recognition knowledge. We also introduce a knowledge fusion module to integrate the knowledge of old and new models for LiDAR place recognition. Our extensive experiments demonstrate that KDF can be applied to different networks to overcome catastrophic forgetting, surpassing the state-of-the-art methods in terms of mean Recall@1 and forgetting score.
Convex Hull-based Algebraic Constraint for Visual Quadric SLAM
Mar 03, 2025



Using Quadrics as the object representation has the benefits of both generality and closed-form projection derivation between image and world spaces. Although numerous constraints have been proposed for dual quadric reconstruction, we found that many of them are imprecise and provide minimal improvements to localization.After scrutinizing the existing constraints, we introduce a concise yet more precise convex hull-based algebraic constraint for object landmarks, which is applied to object reconstruction, frontend pose estimation, and backend bundle adjustment.This constraint is designed to fully leverage precise semantic segmentation, effectively mitigating mismatches between complex-shaped object contours and dual quadrics.Experiments on public datasets demonstrate that our approach is applicable to both monocular and RGB-D SLAM and achieves improved object mapping and localization than existing quadric SLAM methods. The implementation of our method is available at https://github.com/tiev-tongji/convexhull-based-algebraic-constraint.
Enhancing Listened Speech Decoding from EEG via Parallel Phoneme Sequence Prediction
Jan 08, 2025



Brain-computer interfaces (BCI) offer numerous human-centered application possibilities, particularly affecting people with neurological disorders. Text or speech decoding from brain activities is a relevant domain that could augment the quality of life for people with impaired speech perception. We propose a novel approach to enhance listened speech decoding from electroencephalography (EEG) signals by utilizing an auxiliary phoneme predictor that simultaneously decodes textual phoneme sequences. The proposed model architecture consists of three main parts: EEG module, speech module, and phoneme predictor. The EEG module learns to properly represent EEG signals into EEG embeddings. The speech module generates speech waveforms from the EEG embeddings. The phoneme predictor outputs the decoded phoneme sequences in text modality. Our proposed approach allows users to obtain decoded listened speech from EEG signals in both modalities (speech waveforms and textual phoneme sequences) simultaneously, eliminating the need for a concatenated sequential pipeline for each modality. The proposed approach also outperforms previous methods in both modalities. The source code and speech samples are publicly available.
MVC-VPR: Mutual Learning of Viewpoint Classification and Visual Place Recognition
Dec 13, 2024



Visual Place Recognition (VPR) aims to robustly identify locations by leveraging image retrieval based on descriptors encoded from environmental images. However, drastic appearance changes of images captured from different viewpoints at the same location pose incoherent supervision signals for descriptor learning, which severely hinder the performance of VPR. Previous work proposes classifying images based on manually defined rules or ground truth labels for viewpoints, followed by descriptor training based on the classification results. However, not all datasets have ground truth labels of viewpoints and manually defined rules may be suboptimal, leading to degraded descriptor performance.To address these challenges, we introduce the mutual learning of viewpoint self-classification and VPR. Starting from coarse classification based on geographical coordinates, we progress to finer classification of viewpoints using simple clustering techniques. The dataset is partitioned in an unsupervised manner while simultaneously training a descriptor extractor for place recognition. Experimental results show that this approach almost perfectly partitions the dataset based on viewpoints, thus achieving mutually reinforcing effects. Our method even excels state-of-the-art (SOTA) methods that partition datasets using ground truth labels.
Can Generic LLMs Help Analyze Child-adult Interactions Involving Children with Autism in Clinical Observation?
Nov 16, 2024Large Language Models (LLMs) have shown significant potential in understanding human communication and interaction. However, their performance in the domain of child-inclusive interactions, including in clinical settings, remains less explored. In this work, we evaluate generic LLMs' ability to analyze child-adult dyadic interactions in a clinically relevant context involving children with ASD. Specifically, we explore LLMs in performing four tasks: classifying child-adult utterances, predicting engaged activities, recognizing language skills and understanding traits that are clinically relevant. Our evaluation shows that generic LLMs are highly capable of analyzing long and complex conversations in clinical observation sessions, often surpassing the performance of non-expert human evaluators. The results show their potential to segment interactions of interest, assist in language skills evaluation, identify engaged activities, and offer clinical-relevant context for assessments.
Egocentric Speaker Classification in Child-Adult Dyadic Interactions: From Sensing to Computational Modeling
Sep 14, 2024



Autism spectrum disorder (ASD) is a neurodevelopmental condition characterized by challenges in social communication, repetitive behavior, and sensory processing. One important research area in ASD is evaluating children's behavioral changes over time during treatment. The standard protocol with this objective is BOSCC, which involves dyadic interactions between a child and clinicians performing a pre-defined set of activities. A fundamental aspect of understanding children's behavior in these interactions is automatic speech understanding, particularly identifying who speaks and when. Conventional approaches in this area heavily rely on speech samples recorded from a spectator perspective, and there is limited research on egocentric speech modeling. In this study, we design an experiment to perform speech sampling in BOSCC interviews from an egocentric perspective using wearable sensors and explore pre-training Ego4D speech samples to enhance child-adult speaker classification in dyadic interactions. Our findings highlight the potential of egocentric speech collection and pre-training to improve speaker classification accuracy.
Data Efficient Child-Adult Speaker Diarization with Simulated Conversations
Sep 13, 2024



Automating child speech analysis is crucial for applications such as neurocognitive assessments. Speaker diarization, which identifies ``who spoke when'', is an essential component of the automated analysis. However, publicly available child-adult speaker diarization solutions are scarce due to privacy concerns and a lack of annotated datasets, while manually annotating data for each scenario is both time-consuming and costly. To overcome these challenges, we propose a data-efficient solution by creating simulated child-adult conversations using AudioSet. We then train a Whisper Encoder-based model, achieving strong zero-shot performance on child-adult speaker diarization using real datasets. The model performance improves substantially when fine-tuned with only 30 minutes of real train data, with LoRA further improving the transfer learning performance. The source code and the child-adult speaker diarization model trained on simulated conversations are publicly available.
ModalityMirror: Improving Audio Classification in Modality Heterogeneity Federated Learning with Multimodal Distillation
Aug 28, 2024Multimodal Federated Learning frequently encounters challenges of client modality heterogeneity, leading to undesired performances for secondary modality in multimodal learning. It is particularly prevalent in audiovisual learning, with audio is often assumed to be the weaker modality in recognition tasks. To address this challenge, we introduce ModalityMirror to improve audio model performance by leveraging knowledge distillation from an audiovisual federated learning model. ModalityMirror involves two phases: a modality-wise FL stage to aggregate uni-modal encoders; and a federated knowledge distillation stage on multi-modality clients to train an unimodal student model. Our results demonstrate that ModalityMirror significantly improves the audio classification compared to the state-of-the-art FL methods such as Harmony, particularly in audiovisual FL facing video missing. Our approach unlocks the potential for exploiting the diverse modality spectrum inherent in multi-modal FL.