 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Generative Transformer Is What You Need for Image Editing
May 11, 2026Diffusion models dominate image editing, yet their global denoising mechanism entangles edited regions with surrounding context, causing modifications to propagate into areas that should remain intact. We propose a fundamentally different approach by leveraging Masked Generative Transformers (MGTs), whose localized token-prediction paradigm naturally confines changes to intended regions. We present EditMGT, an MGT-based editing framework that is the first of its kind. Our approach employs multi-layer attention consolidation to aggregate cross-attention maps into precise edit localization signals, and region-hold sampling to explicitly prevent token flipping in non-target areas. To support training, we construct CrispEdit-2M, a 2M-sample high-resolution (>1024) editing dataset spanning seven categories. With only 960M parameters, EditMGT achieves state-of-the-art image similarity on multiple benchmarks while delivering 6x faster editing, demonstrating that MGTs offer a compelling alternative to diffusion-based editing.
EditMGT: Unleashing Potentials of Masked Generative Transformers in Image Editing
Dec 12, 2025Recent advances in diffusion models (DMs) have achieved exceptional visual quality in image editing tasks. However, the global denoising dynamics of DMs inherently conflate local editing targets with the full-image context, leading to unintended modifications in non-target regions. In this paper, we shift our attention beyond DMs and turn to Masked Generative Transformers (MGTs) as an alternative approach to tackle this challenge. By predicting multiple masked tokens rather than holistic refinement, MGTs exhibit a localized decoding paradigm that endows them with the inherent capacity to explicitly preserve non-relevant regions during the editing process. Building upon this insight, we introduce the first MGT-based image editing framework, termed EditMGT. We first demonstrate that MGT's cross-attention maps provide informative localization signals for localizing edit-relevant regions and devise a multi-layer attention consolidation scheme that refines these maps to achieve fine-grained and precise localization. On top of these adaptive localization results, we introduce region-hold sampling, which restricts token flipping within low-attention areas to suppress spurious edits, thereby confining modifications to the intended target regions and preserving the integrity of surrounding non-target areas. To train EditMGT, we construct CrispEdit-2M, a high-resolution dataset spanning seven diverse editing categories. Without introducing additional parameters, we adapt a pre-trained text-to-image MGT into an image editing model through attention injection. Extensive experiments across four standard benchmarks demonstrate that, with fewer than 1B parameters, our model achieves similarity performance while enabling 6 times faster editing. Moreover, it delivers comparable or superior editing quality, with improvements of 3.6% and 17.6% on style change and style transfer tasks, respectively.
Generative Model Watermarking Based on Human Visual System
Sep 30, 2022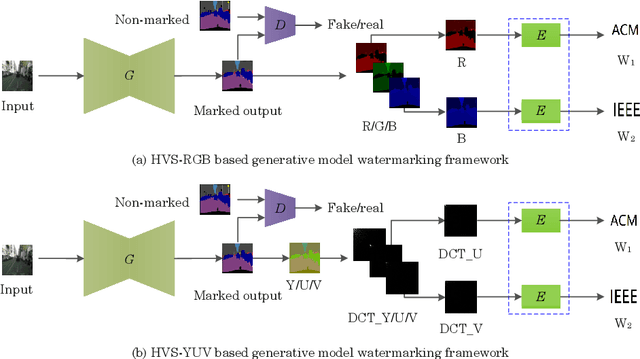
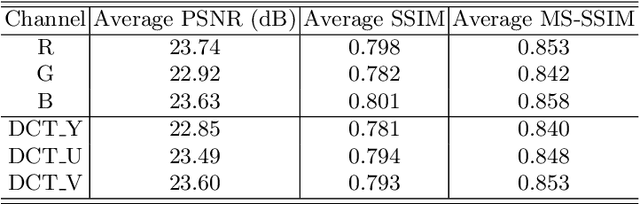


Intellectual property protection of deep neural networks is receiving attention from more and more researchers, and the latest research applies model watermarking to generative models for image processing. However, the existing watermarking methods designed for generative models do not take into account the effects of different channels of sample images on watermarking. As a result, the watermarking performance is still limited. To tackle this problem, in this paper, we first analyze the effects of embedding watermark information on different channels. Then, based on the characteristics of human visual system (HVS), we introduce two HVS-based generative model watermarking methods, which are realized in RGB color space and YUV color space respectively. In RGB color space, the watermark is embedded into the R and B channels based on the fact that HVS is more sensitive to G channel. In YUV color space, the watermark is embedded into the DCT domain of U and V channels based on the fact that HVS is more sensitive to brightness changes. Experimental results demonstrate the effectiveness of the proposed work, which improves the fidelity of the model to be protected and has good universality compared with previous methods.