 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolistically-Attracted Wireframe Parsing: From Supervised to Self-Supervised Learning
Oct 24, 2022This paper presents Holistically-Attracted Wireframe Parsing (HAWP) for 2D images using both fully supervised and self-supervised learning paradigms. At the core is a parsimonious representation that encodes a line segment using a closed-form 4D geometric vector, which enables lifting line segments in wireframe to an end-to-end trainable holistic attraction field that has built-in geometry-awareness, context-awareness and robustness. The proposed HAWP consists of three components: generating line segment and end-point proposal, binding line segment and end-point, and end-point-decoupled lines-of-interest verification. For self-supervised learning, a simulation-to-reality pipeline is exploited in which a HAWP is first trained using synthetic data and then used to ``annotate" wireframes in real images with Homographic Adaptation. With the self-supervised annotations, a HAWP model for real images is trained from scratch. In experiments, the proposed HAWP achieves state-of-the-art performance in both the Wireframe dataset and the YorkUrban dataset in fully-supervised learning. It also demonstrates a significantly better repeatability score than prior arts with much more efficient training in self-supervised learning. Furthermore, the self-supervised HAWP shows great potential for general wireframe parsing without onerous wireframe labels.
HoW-3D: Holistic 3D Wireframe Perception from a Single Image
Aug 19, 2022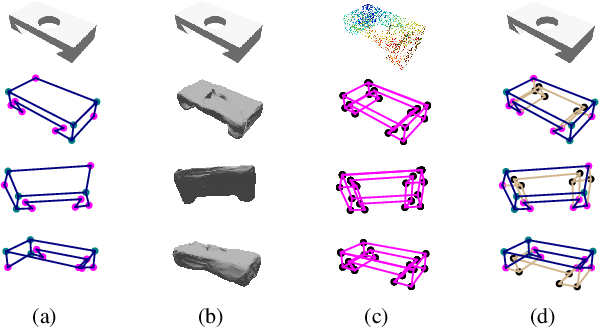

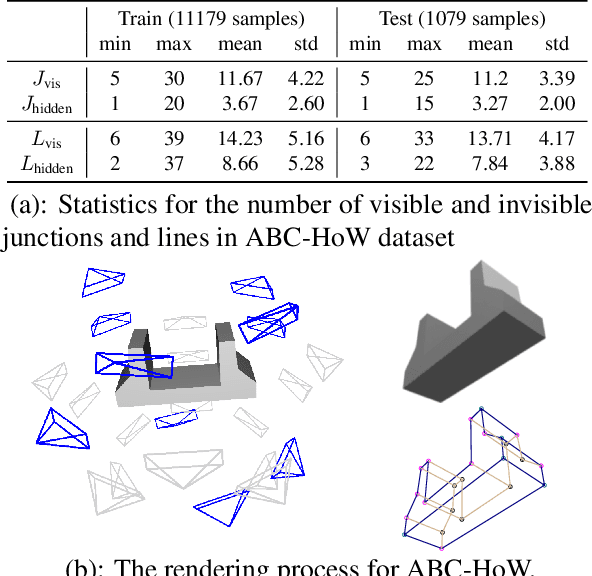
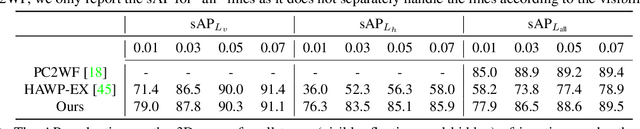
This paper studies the problem of holistic 3D wireframe perception (HoW-3D), a new task of perceiving both the visible 3D wireframes and the invisible ones from single-view 2D images. As the non-front surfaces of an object cannot be directly observed in a single view, estimating the non-line-of-sight (NLOS) geometries in HoW-3D is a fundamentally challenging problem and remains open in computer vision. We study the problem of HoW-3D by proposing an ABC-HoW benchmark, which is created on top of CAD models sourced from the ABC-dataset with 12k single-view images and the corresponding holistic 3D wireframe models. With our large-scale ABC-HoW benchmark available, we present a novel Deep Spatial Gestalt (DSG) model to learn the visible junctions and line segments as the basis and then infer the NLOS 3D structures from the visible cues by following the Gestalt principles of human vision systems. In our experiments, we demonstrate that our DSG model performs very well in inferring the holistic 3D wireframes from single-view images. Compared with the strong baseline methods, our DSG model outperforms the previous wireframe detectors in detecting the invisible line geometry in single-view images and is even very competitive with prior arts that take high-fidelity PointCloud as inputs on reconstructing 3D wireframes.
Learning Patch-to-Cluster Attention in Vision Transformer
Mar 22, 2022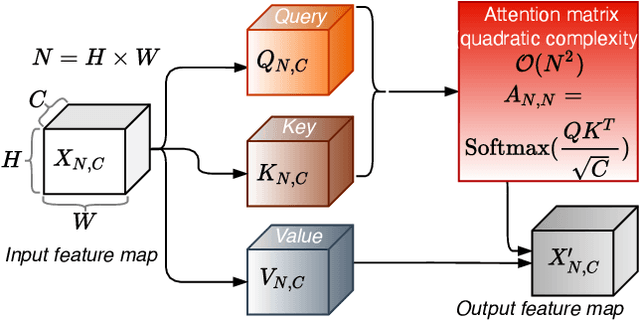
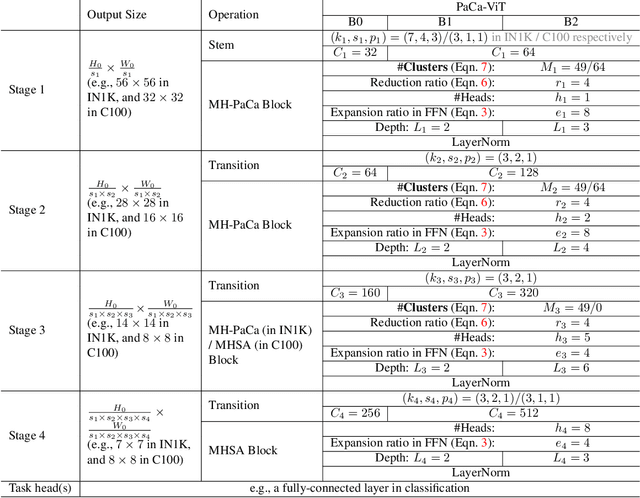
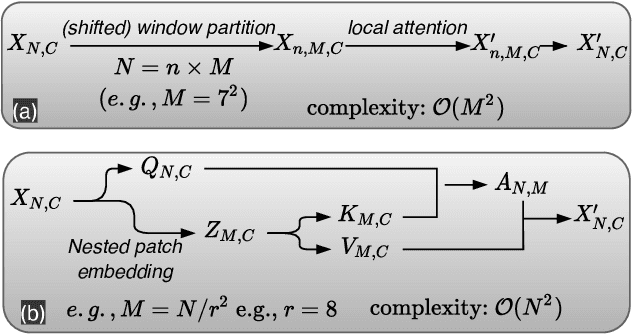
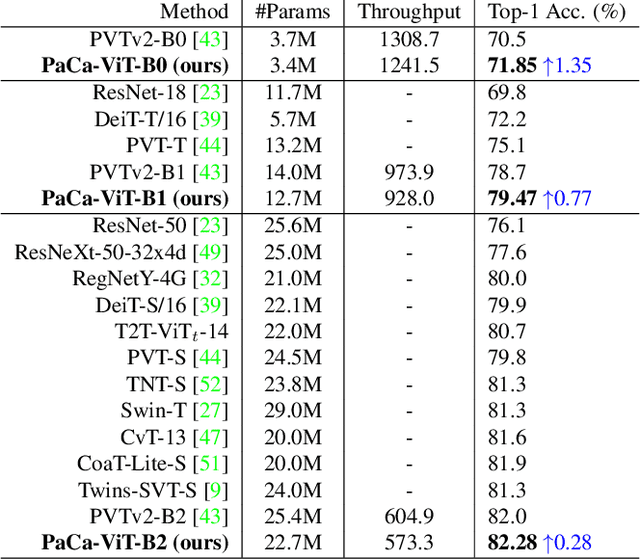
The Vision Transformer (ViT) model is built on the assumption of treating image patches as "visual tokens" and learning patch-to-patch attention. The patch embedding based tokenizer is a workaround in practice and has a semantic gap with respect to its counterpart, the textual tokenizer. The patch-to-patch attention suffers from the quadratic complexity issue, and also makes it non-trivial to explain learned ViT models. To address these issues in ViT models, this paper proposes to learn patch-to-cluster attention (PaCa) based ViT models. Queries in our PaCaViT are based on patches, while keys and values are based on clustering (with a predefined small number of clusters). The clusters are learned end-to-end, leading to better tokenizers and realizing joint clustering-for-attention and attention-for-clustering when deployed in ViT models. The quadratic complexity is relaxed to linear complexity. Also, directly visualizing the learned clusters can reveal how a trained ViT model learns to perform a task (e.g., object detection). In experiments, the proposed PaCa-ViT is tested on CIFAR-100 and ImageNet-1000 image classification, and MS-COCO object detection and instance segmentation. Compared with prior arts, it obtains better performance in classification and comparable performance in detection and segmentation. It is significantly more efficient in COCO due to the linear complexity. The learned clusters are also semantically meaningful and shed light on designing more discriminative yet interpretable ViT models.
Refining Self-Supervised Learning in Imaging: Beyond Linear Metric
Feb 25, 2022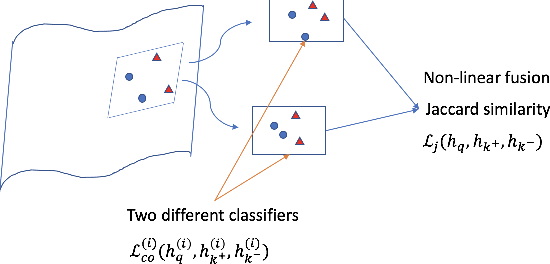
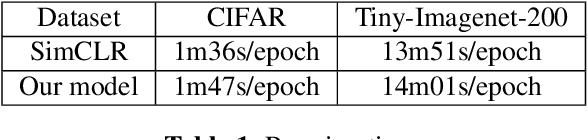
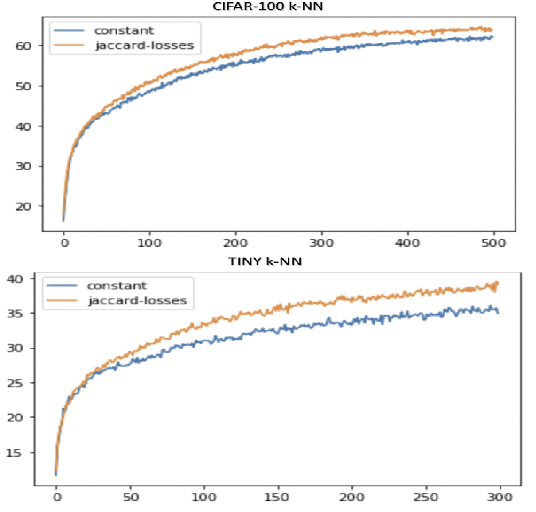
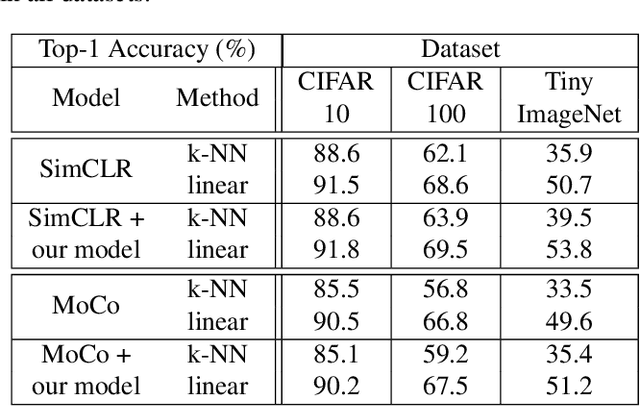
We introduce in this paper a new statistical perspective, exploiting the Jaccard similarity metric, as a measure-based metric to effectively invoke non-linear features in the loss of self-supervised contrastive learning. Specifically, our proposed metric may be interpreted as a dependence measure between two adapted projections learned from the so-called latent representations. This is in contrast to the cosine similarity measure in the conventional contrastive learning model, which accounts for correlation information. To the best of our knowledge, this effectively non-linearly fused information embedded in the Jaccard similarity, is novel to self-supervision learning with promising results. The proposed approach is compared to two state-of-the-art self-supervised contrastive learning methods on three image datasets. We not only demonstrate its amenable applicability in current ML problems, but also its improved performance and training efficiency.
Learning Inception Attention for Image Synthesis and Image Recognition
Dec 29, 2021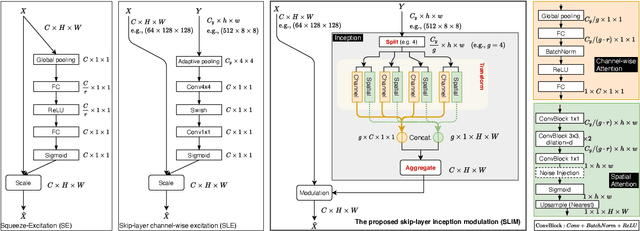

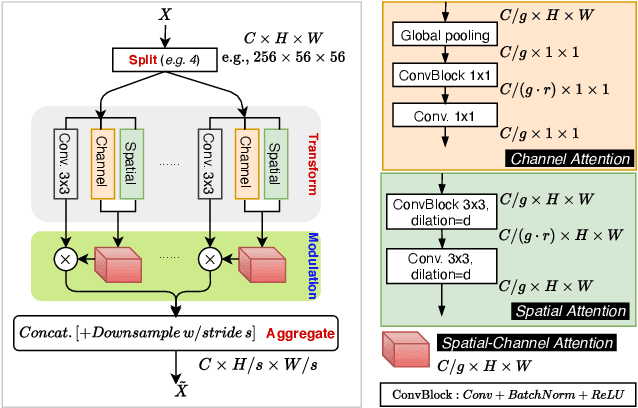

Image synthesis and image recognition have witnessed remarkable progress, but often at the expense of computationally expensive training and inference. Learning lightweight yet expressive deep model has emerged as an important and interesting direction. Inspired by the well-known split-transform-aggregate design heuristic in the Inception building block, this paper proposes a Skip-Layer Inception Module (SLIM) that facilitates efficient learning of image synthesis models, and a same-layer variant (dubbed as SLIM too) as a stronger alternative to the well-known ResNeXts for image recognition. In SLIM, the input feature map is first split into a number of groups (e.g., 4).Each group is then transformed to a latent style vector(via channel-wise attention) and a latent spatial mask (via spatial attention). The learned latent masks and latent style vectors are aggregated to modulate the target feature map. For generative learning, SLIM is built on a recently proposed lightweight Generative Adversarial Networks (i.e., FastGANs) which present a skip-layer excitation(SLE) module. For few-shot image synthesis tasks, the proposed SLIM achieves better performance than the SLE work and other related methods. For one-shot image synthesis tasks, it shows stronger capability of preserving images structures than prior arts such as the SinGANs. For image classification tasks, the proposed SLIM is used as a drop-in replacement for convolution layers in ResNets (resulting in ResNeXt-like models) and achieves better accuracy in theImageNet-1000 dataset, with significantly smaller model complexity
Learning Auxiliary Monocular Contexts Helps Monocular 3D Object Detection
Dec 09, 2021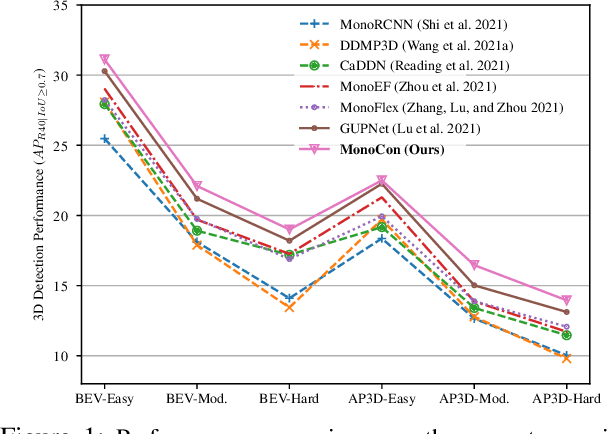
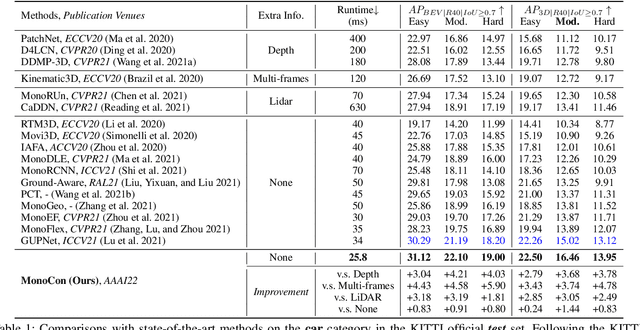
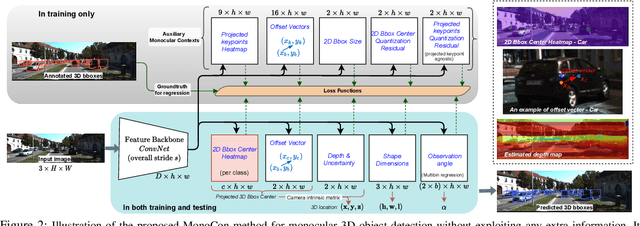
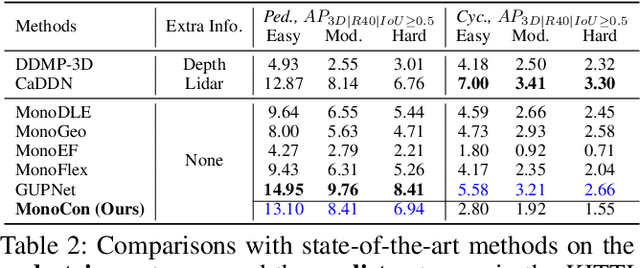
Monocular 3D object detection aims to localize 3D bounding boxes in an input single 2D image. It is a highly challenging problem and remains open, especially when no extra information (e.g., depth, lidar and/or multi-frames) can be leveraged in training and/or inference. This paper proposes a simple yet effective formulation for monocular 3D object detection without exploiting any extra information. It presents the MonoCon method which learns Monocular Contexts, as auxiliary tasks in training, to help monocular 3D object detection. The key idea is that with the annotated 3D bounding boxes of objects in an image, there is a rich set of well-posed projected 2D supervision signals available in training, such as the projected corner keypoints and their associated offset vectors with respect to the center of 2D bounding box, which should be exploited as auxiliary tasks in training. The proposed MonoCon is motivated by the Cramer-Wold theorem in measure theory at a high level. In implementation, it utilizes a very simple end-to-end design to justify the effectiveness of learning auxiliary monocular contexts, which consists of three components: a Deep Neural Network (DNN) based feature backbone, a number of regression head branches for learning the essential parameters used in the 3D bounding box prediction, and a number of regression head branches for learning auxiliary contexts. After training, the auxiliary context regression branches are discarded for better inference efficiency. In experiments, the proposed MonoCon is tested in the KITTI benchmark (car, pedestrain and cyclist). It outperforms all prior arts in the leaderboard on car category and obtains comparable performance on pedestrian and cyclist in terms of accuracy. Thanks to the simple design, the proposed MonoCon method obtains the fastest inference speed with 38.7 fps in comparisons
Learning Local-Global Contextual Adaptation for Fully End-to-End Bottom-Up Human Pose Estimation
Sep 08, 2021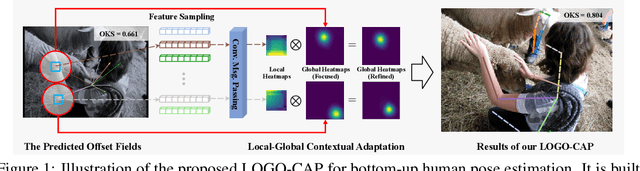
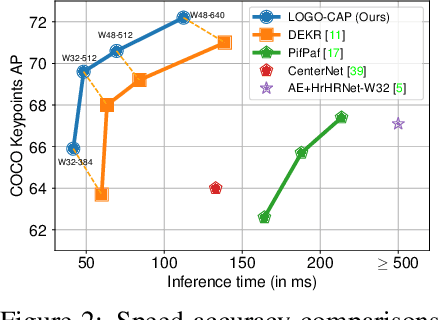
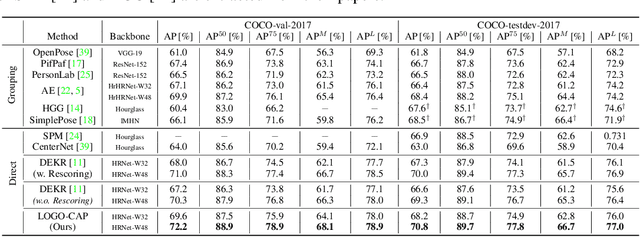
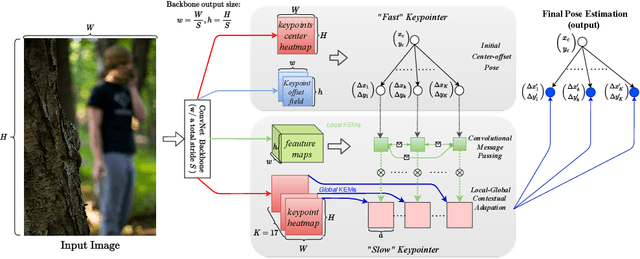
This paper presents a method of learning Local-GlObal Contextual Adaptation for fully end-to-end and fast bottom-up human Pose estimation, dubbed as LOGO-CAP. It is built on the conceptually simple center-offset formulation that lacks inaccuracy for pose estimation. When revisiting the bottom-up human pose estimation with the thought of "thinking, fast and slow" by D. Kahneman, we introduce a "slow keypointer" to remedy the lack of sufficient accuracy of the "fast keypointer". In learning the "slow keypointer", the proposed LOGO-CAP lifts the initial "fast" keypoints by offset predictions to keypoint expansion maps (KEMs) to counter their uncertainty in two modules. Firstly, the local KEMs (e.g., 11x11) are extracted from a low-dimensional feature map. A proposed convolutional message passing module learns to "re-focus" the local KEMs to the keypoint attraction maps (KAMs) by accounting for the structured output prediction nature of human pose estimation, which is directly supervised by the object keypoint similarity (OKS) loss in training. Secondly, the global KEMs are extracted, with a sufficiently large region-of-interest (e.g., 97x97), from the keypoint heatmaps that are computed by a direct map-to-map regression. Then, a local-global contextual adaptation module is proposed to convolve the global KEMs using the learned KAMs as the kernels. This convolution can be understood as the learnable offsets guided deformable and dynamic convolution in a pose-sensitive way. The proposed method is end-to-end trainable with near real-time inference speed, obtaining state-of-the-art performance on the COCO keypoint benchmark for bottom-up human pose estimation. With the COCO trained model, our LOGO-CAP also outperforms prior arts by a large margin on the challenging OCHuman dataset.
Towards Adversarially Robust and Domain Generalizable Stereo Matching by Rethinking DNN Feature Backbones
Jul 31, 2021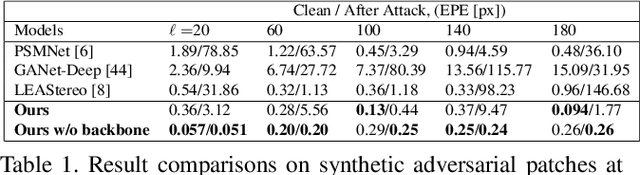
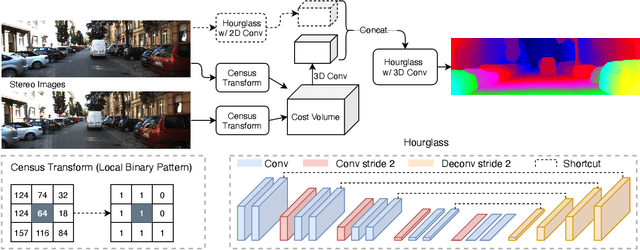
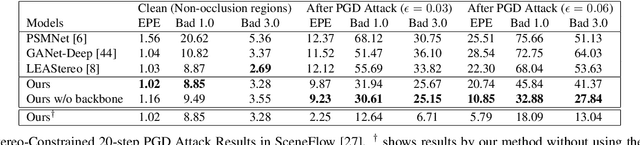
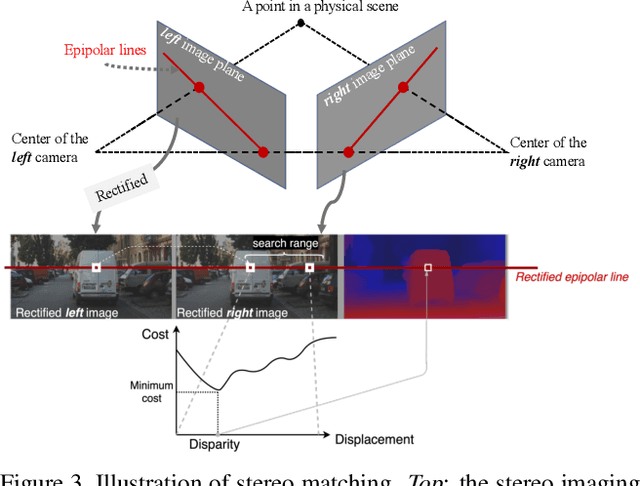
Stereo matching has recently witnessed remarkable progress using Deep Neural Networks (DNNs). But, how robust are they? Although it has been well-known that DNNs often suffer from adversarial vulnerability with a catastrophic drop in performance, the situation is even worse in stereo matching. This paper first shows that a type of weak white-box attacks can fail state-of-the-art methods. The attack is learned by a proposed stereo-constrained projected gradient descent (PGD) method in stereo matching. This observation raises serious concerns for the deployment of DNN-based stereo matching. Parallel to the adversarial vulnerability, DNN-based stereo matching is typically trained under the so-called simulation to reality pipeline, and thus domain generalizability is an important problem. This paper proposes to rethink the learnable DNN-based feature backbone towards adversarially-robust and domain generalizable stereo matching, either by completely removing it or by applying it only to the left reference image. It computes the matching cost volume using the classic multi-scale census transform (i.e., local binary pattern) of the raw input stereo images, followed by a stacked Hourglass head sub-network solving the matching problem. In experiments, the proposed method is tested in the SceneFlow dataset and the KITTI2015 benchmark. It significantly improves the adversarial robustness, while retaining accuracy performance comparable to state-of-the-art methods. It also shows better generalizability from simulation (SceneFlow) to real (KITTI) datasets when no fine-tuning is used.
PlaneTR: Structure-Guided Transformers for 3D Plane Recovery
Jul 27, 2021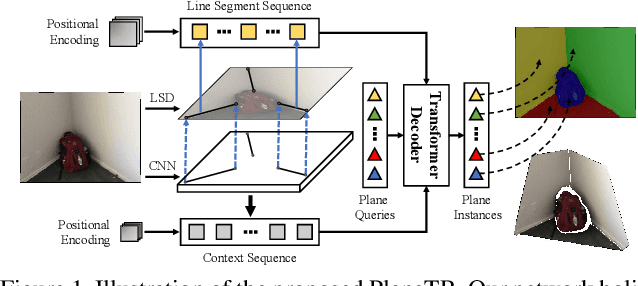
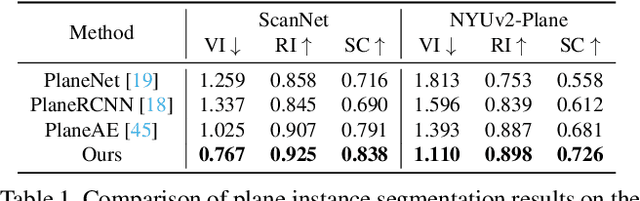
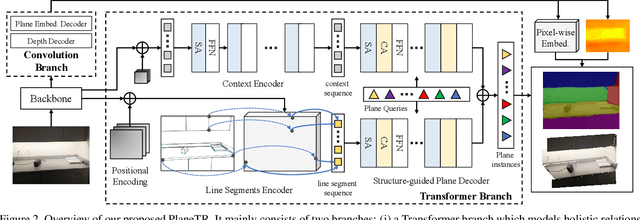
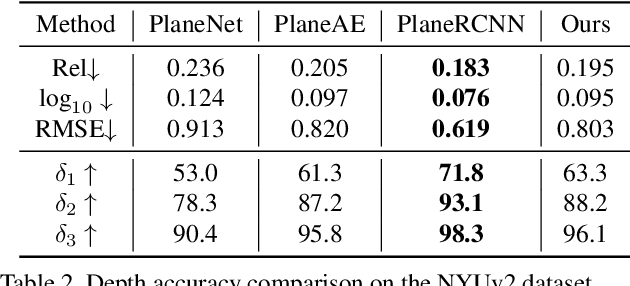
This paper presents a neural network built upon Transformers, namely PlaneTR, to simultaneously detect and reconstruct planes from a single image. Different from previous methods, PlaneTR jointly leverages the context information and the geometric structures in a sequence-to-sequence way to holistically detect plane instances in one forward pass. Specifically, we represent the geometric structures as line segments and conduct the network with three main components: (i) context and line segments encoders, (ii) a structure-guided plane decoder, (iii) a pixel-wise plane embedding decoder. Given an image and its detected line segments, PlaneTR generates the context and line segment sequences via two specially designed encoders and then feeds them into a Transformers-based decoder to directly predict a sequence of plane instances by simultaneously considering the context and global structure cues. Finally, the pixel-wise embeddings are computed to assign each pixel to one predicted plane instance which is nearest to it in embedding space. Comprehensive experiments demonstrate that PlaneTR achieves a state-of-the-art performance on the ScanNet and NYUv2 datasets.
Deep Consensus Learning
Mar 15, 2021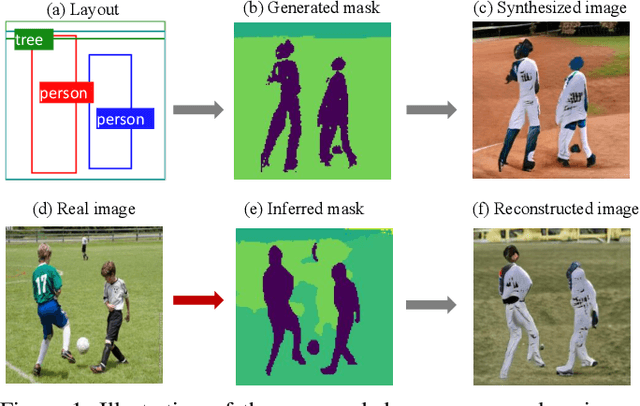
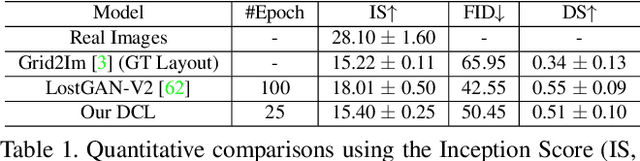
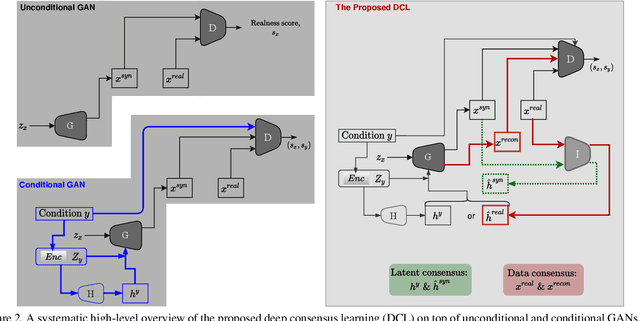
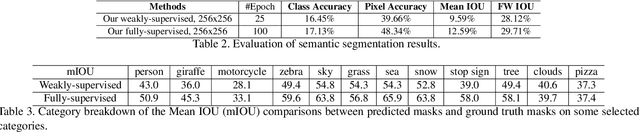
Both generative learning and discriminative learning have recently witnessed remarkable progress using Deep Neural Networks (DNNs). For structured input synthesis and structured output prediction problems (e.g., layout-to-image synthesis and image semantic segmentation respectively), they often are studied separately. This paper proposes deep consensus learning (DCL) for joint layout-to-image synthesis and weakly-supervised image semantic segmentation. The former is realized by a recently proposed LostGAN approach, and the latter by introducing an inference network as the third player joining the two-player game of LostGAN. Two deep consensus mappings are exploited to facilitate training the three networks end-to-end: Given an input layout (a list of object bounding boxes), the generator generates a mask (label map) and then use it to help synthesize an image. The inference network infers the mask for the synthesized image. Then, the latent consensus is measured between the mask generated by the generator and the one inferred by the inference network. For the real image corresponding to the input layout, its mask also is computed by the inference network, and then used by the generator to reconstruct the real image. Then, the data consensus is measured between the real image and its reconstructed image. The discriminator still plays the role of an adversary by computing the realness scores for a real image, its reconstructed image and a synthesized image. In experiments, our DCL is tested in the COCO-Stuff dataset. It obtains compelling layout-to-image synthesis results and weakly-supervised image semantic segmentation results.