 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Attentive Contextualization for Multi-View 3D Object Detection
May 20, 2024



We present Multi-View Attentive Contextualization (MvACon), a simple yet effective method for improving 2D-to-3D feature lifting in query-based multi-view 3D (MV3D) object detection. Despite remarkable progress witnessed in the field of query-based MV3D object detection, prior art often suffers from either the lack of exploiting high-resolution 2D features in dense attention-based lifting, due to high computational costs, or from insufficiently dense grounding of 3D queries to multi-scale 2D features in sparse attention-based lifting. Our proposed MvACon hits the two birds with one stone using a representationally dense yet computationally sparse attentive feature contextualization scheme that is agnostic to specific 2D-to-3D feature lifting approaches. In experiments, the proposed MvACon is thoroughly tested on the nuScenes benchmark, using both the BEVFormer and its recent 3D deformable attention (DFA3D) variant, as well as the PETR, showing consistent detection performance improvement, especially in enhancing performance in location, orientation, and velocity prediction. It is also tested on the Waymo-mini benchmark using BEVFormer with similar improvement. We qualitatively and quantitatively show that global cluster-based contexts effectively encode dense scene-level contexts for MV3D object detection. The promising results of our proposed MvACon reinforces the adage in computer vision -- ``(contextualized) feature matters".
Monocular 3D Object Detection with Bounding Box Denoising in 3D by Perceiver
Apr 03, 2023



The main challenge of monocular 3D object detection is the accurate localization of 3D center. Motivated by a new and strong observation that this challenge can be remedied by a 3D-space local-grid search scheme in an ideal case, we propose a stage-wise approach, which combines the information flow from 2D-to-3D (3D bounding box proposal generation with a single 2D image) and 3D-to-2D (proposal verification by denoising with 3D-to-2D contexts) in a top-down manner. Specifically, we first obtain initial proposals from off-the-shelf backbone monocular 3D detectors. Then, we generate a 3D anchor space by local-grid sampling from the initial proposals. Finally, we perform 3D bounding box denoising at the 3D-to-2D proposal verification stage. To effectively learn discriminative features for denoising highly overlapped proposals, this paper presents a method of using the Perceiver I/O model to fuse the 3D-to-2D geometric information and the 2D appearance information. With the encoded latent representation of a proposal, the verification head is implemented with a self-attention module. Our method, named as MonoXiver, is generic and can be easily adapted to any backbone monocular 3D detectors. Experimental results on the well-established KITTI dataset and the challenging large-scale Waymo dataset show that MonoXiver consistently achieves improvement with limited computation overhead.
POTTER: Pooling Attention Transformer for Efficient Human Mesh Recovery
Mar 23, 2023



Transformer architectures have achieved SOTA performance on the human mesh recovery (HMR) from monocular images. However, the performance gain has come at the cost of substantial memory and computational overhead. A lightweight and efficient model to reconstruct accurate human mesh is needed for real-world applications. In this paper, we propose a pure transformer architecture named POoling aTtention TransformER (POTTER) for the HMR task from single images. Observing that the conventional attention module is memory and computationally expensive, we propose an efficient pooling attention module, which significantly reduces the memory and computational cost without sacrificing performance. Furthermore, we design a new transformer architecture by integrating a High-Resolution (HR) stream for the HMR task. The high-resolution local and global features from the HR stream can be utilized for recovering more accurate human mesh. Our POTTER outperforms the SOTA method METRO by only requiring 7% of total parameters and 14% of the Multiply-Accumulate Operations on the Human3.6M (PA-MPJPE metric) and 3DPW (all three metrics) datasets. The project webpage is https://zczcwh.github.io/potter_page.
Learning Auxiliary Monocular Contexts Helps Monocular 3D Object Detection
Dec 09, 2021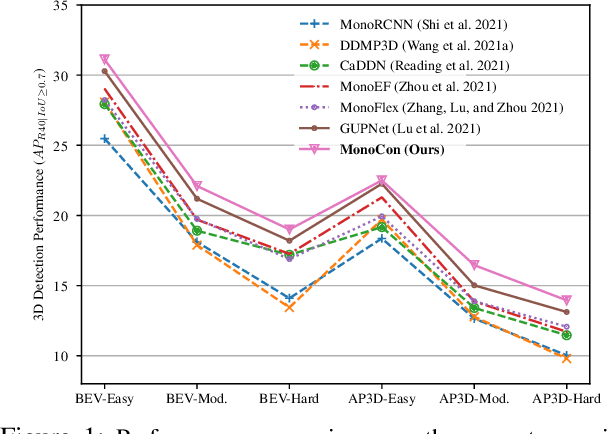
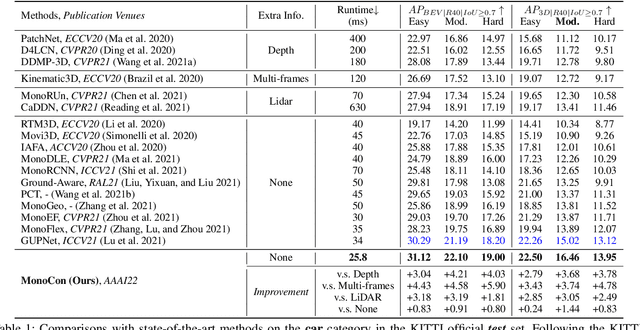
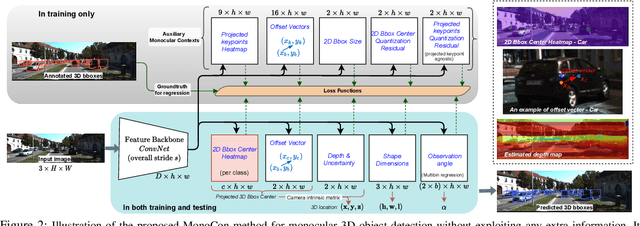
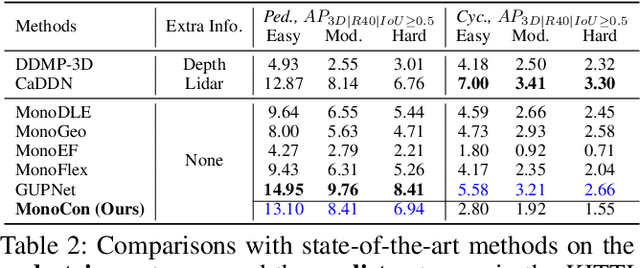
Monocular 3D object detection aims to localize 3D bounding boxes in an input single 2D image. It is a highly challenging problem and remains open, especially when no extra information (e.g., depth, lidar and/or multi-frames) can be leveraged in training and/or inference. This paper proposes a simple yet effective formulation for monocular 3D object detection without exploiting any extra information. It presents the MonoCon method which learns Monocular Contexts, as auxiliary tasks in training, to help monocular 3D object detection. The key idea is that with the annotated 3D bounding boxes of objects in an image, there is a rich set of well-posed projected 2D supervision signals available in training, such as the projected corner keypoints and their associated offset vectors with respect to the center of 2D bounding box, which should be exploited as auxiliary tasks in training. The proposed MonoCon is motivated by the Cramer-Wold theorem in measure theory at a high level. In implementation, it utilizes a very simple end-to-end design to justify the effectiveness of learning auxiliary monocular contexts, which consists of three components: a Deep Neural Network (DNN) based feature backbone, a number of regression head branches for learning the essential parameters used in the 3D bounding box prediction, and a number of regression head branches for learning auxiliary contexts. After training, the auxiliary context regression branches are discarded for better inference efficiency. In experiments, the proposed MonoCon is tested in the KITTI benchmark (car, pedestrain and cyclist). It outperforms all prior arts in the leaderboard on car category and obtains comparable performance on pedestrian and cyclist in terms of accuracy. Thanks to the simple design, the proposed MonoCon method obtains the fastest inference speed with 38.7 fps in comparisons
Toward Effective Automated Content Analysis via Crowdsourcing
Jan 12, 2021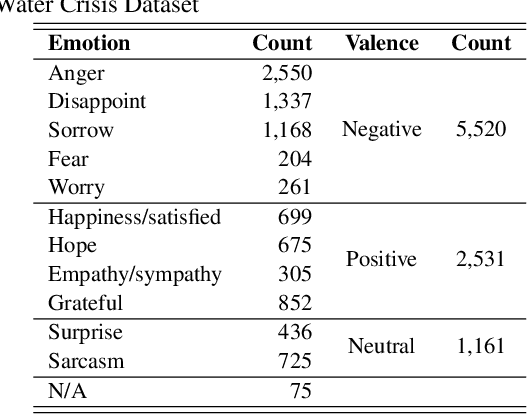
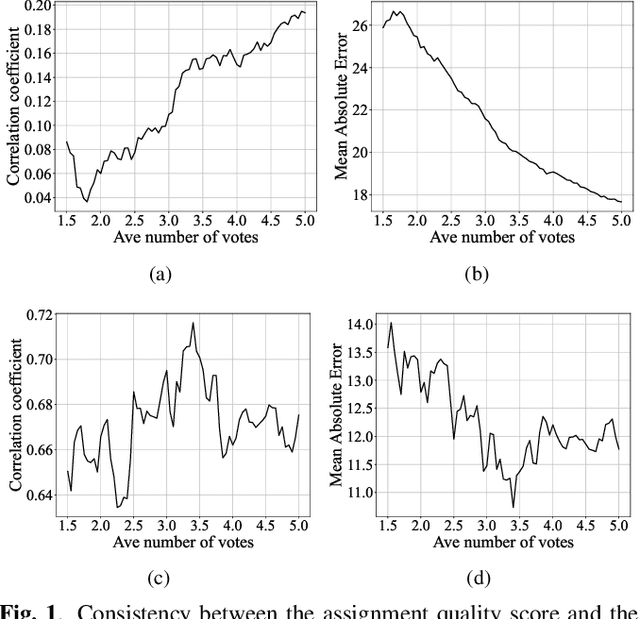
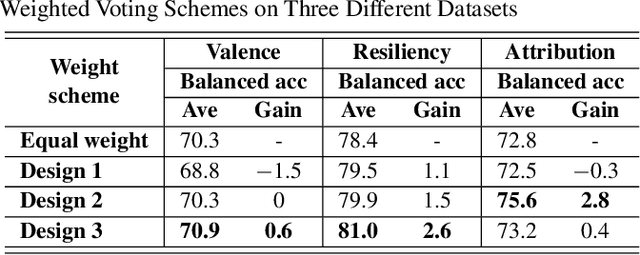
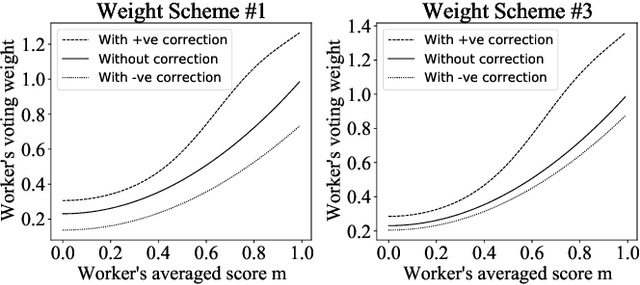
Many computer scientists use the aggregated answers of online workers to represent ground truth. Prior work has shown that aggregation methods such as majority voting are effective for measuring relatively objective features. For subjective features such as semantic connotation, online workers, known for optimizing their hourly earnings, tend to deteriorate in the quality of their responses as they work longer. In this paper, we aim to address this issue by proposing a quality-aware semantic data annotation system. We observe that with timely feedback on workers' performance quantified by quality scores, better informed online workers can maintain the quality of their labeling throughout an extended period of time. We validate the effectiveness of the proposed annotation system through i) evaluating performance based on an expert-labeled dataset, and ii) demonstrating machine learning tasks that can lead to consistent learning behavior with 70%-80% accuracy. Our results suggest that with our system, researchers can collect high-quality answers of subjective semantic features at a large scale.