 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Local is the Local Diversity? Reinforcing Sequential Determinantal Point Processes with Dynamic Ground Sets for Supervised Video Summarization
Aug 24, 2018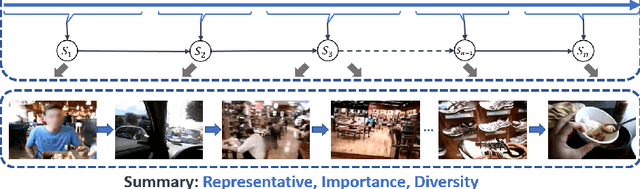
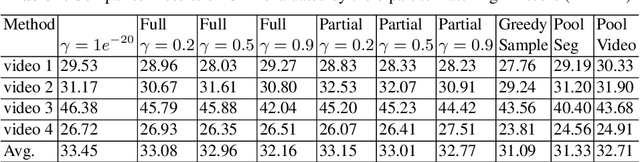
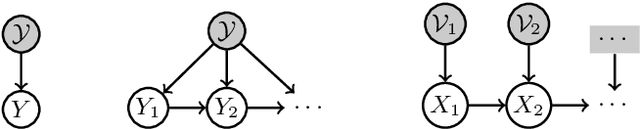
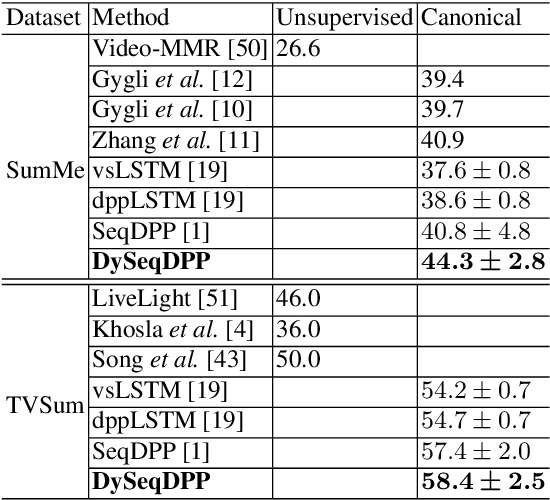
The large volume of video content and high viewing frequency demand automatic video summarization algorithms, of which a key property is the capability of modeling diversity. If videos are lengthy like hours-long egocentric videos, it is necessary to track the temporal structures of the videos and enforce local diversity. The local diversity refers to that the shots selected from a short time duration are diverse but visually similar shots are allowed to co-exist in the summary if they appear far apart in the video. In this paper, we propose a novel probabilistic model, built upon SeqDPP, to dynamically control the time span of a video segment upon which the local diversity is imposed. In particular, we enable SeqDPP to learn to automatically infer how local the local diversity is supposed to be from the input video. The resulting model is extremely involved to train by the hallmark maximum likelihood estimation (MLE), which further suffers from the exposure bias and non-differentiable evaluation metrics. To tackle these problems, we instead devise a reinforcement learning algorithm for training the proposed model. Extensive experiments verify the advantages of our model and the new learning algorithm over MLE-based methods.
EIGEN: Ecologically-Inspired GENetic Approach for Neural Network Structure Searching
Jun 05, 2018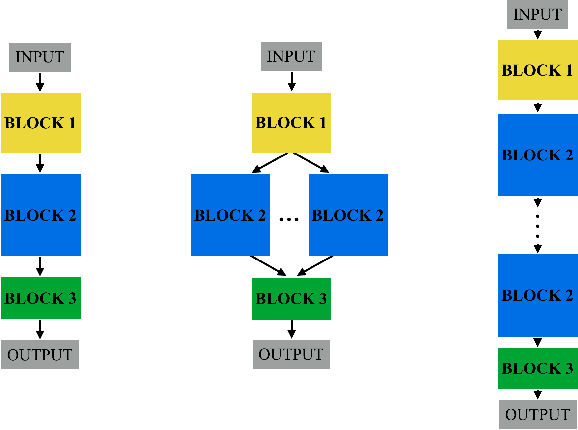
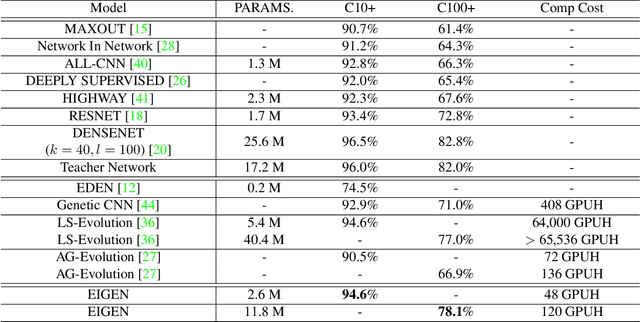
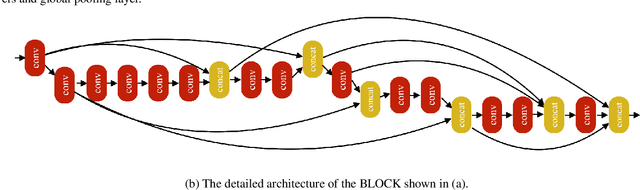

Designing the structure of neural networks is considered one of the most challenging tasks in deep learning. Recently, a few approaches have been proposed to automatically search for the optimal structure of neural networks, however, they suffer from either prohibitive computation cost (e.g., 256 Hours on 250 GPU in [1]) or unsatisfactory performance compared to those of hand-crafted neural networks. In this paper, we propose an Ecologically-Inspired GENetic approach for neural network structure search (EIGEN), that includes succession, mimicry and gene duplication. Specifically, we first use primary succession to rapidly evolve a community of poor initialized neural network structures into a more diverse community, followed by a secondary succession stage for fine-grained searching based on the networks from the primary succession. Extinction is applied in both stages to reduce computational cost. Mimicry is employed during the entire evolution process to help the inferior networks imitate the behavior of a superior network and gene duplication is utilized to duplicate the learned blocks of novel structures, both of which help to find the better network structures. Extensive experimental results show that our proposed approach can achieve the similar or better performance compared to the existing genetic approaches with dramatically reduced computation cost. For example, the network discovered by our approach on CIFAR-100 dataset achieves 78.1% test accuracy under 120 GPU hours, compared to 77.0% test accuracy in more than 65, 536 GPU hours in [1].
Dynamic Regret of Strongly Adaptive Methods
Jun 04, 2018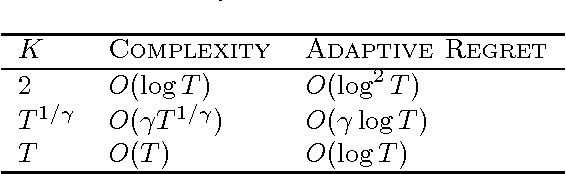
To cope with changing environments, recent developments in online learning have introduced the concepts of adaptive regret and dynamic regret independently. In this paper, we illustrate an intrinsic connection between these two concepts by showing that the dynamic regret can be expressed in terms of the adaptive regret and the functional variation. This observation implies that strongly adaptive algorithms can be directly leveraged to minimize the dynamic regret. As a result, we present a series of strongly adaptive algorithms that have small dynamic regrets for convex functions, exponentially concave functions, and strongly convex functions, respectively. To the best of our knowledge, this is the first time that exponential concavity is utilized to upper bound the dynamic regret. Moreover, all of those adaptive algorithms do not need any prior knowledge of the functional variation, which is a significant advantage over previous specialized methods for minimizing dynamic regret.
An Aggressive Genetic Programming Approach for Searching Neural Network Structure Under Computational Constraints
Jun 03, 2018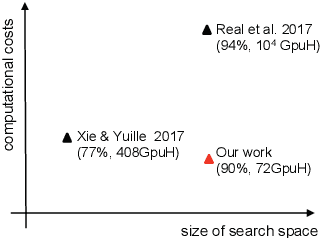
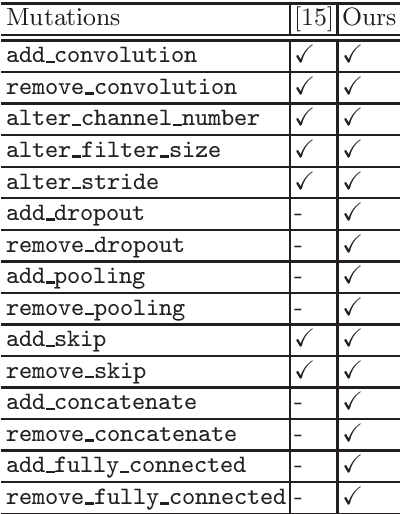
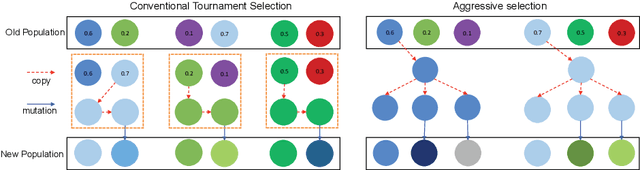
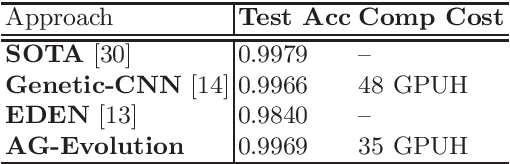
Recently, there emerged revived interests of designing automatic programs (e.g., using genetic/evolutionary algorithms) to optimize the structure of Convolutional Neural Networks (CNNs) for a specific task. The challenge in designing such programs lies in how to balance between large search space of the network structures and high computational costs. Existing works either impose strong restrictions on the search space or use enormous computing resources. In this paper, we study how to design a genetic programming approach for optimizing the structure of a CNN for a given task under limited computational resources yet without imposing strong restrictions on the search space. To reduce the computational costs, we propose two general strategies that are observed to be helpful: (i) aggressively selecting strongest individuals for survival and reproduction, and killing weaker individuals at a very early age; (ii) increasing mutation frequency to encourage diversity and faster evolution. The combined strategy with additional optimization techniques allows us to explore a large search space but with affordable computational costs. Our results on standard benchmark datasets (MNIST, SVHN, CIFAR-10, CIFAR-100) are competitive to similar approaches with significantly reduced computational costs.
Learning with Non-Convex Truncated Losses by SGD
May 21, 2018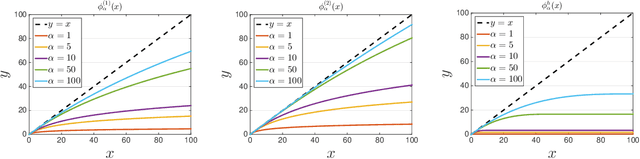
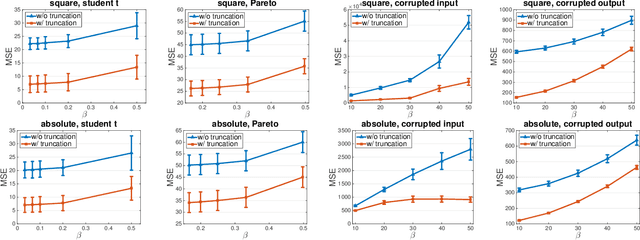
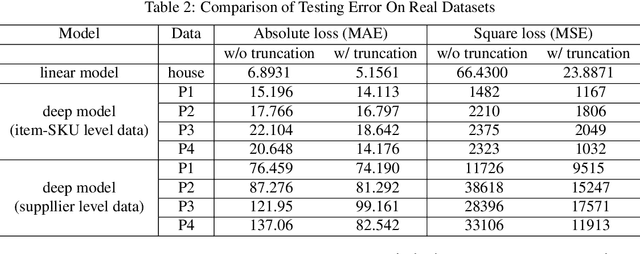
Learning with a {\it convex loss} function has been a dominating paradigm for many years. It remains an interesting question how non-convex loss functions help improve the generalization of learning with broad applicability. In this paper, we study a family of objective functions formed by truncating traditional loss functions, which is applicable to both shallow learning and deep learning. Truncating loss functions has potential to be less vulnerable and more robust to large noise in observations that could be adversarial. More importantly, it is a generic technique without assuming the knowledge of noise distribution. To justify non-convex learning with truncated losses, we establish excess risk bounds of empirical risk minimization based on truncated losses for heavy-tailed output, and statistical error of an approximate stationary point found by stochastic gradient descent (SGD) method. Our experiments for shallow and deep learning for regression with outliers, corrupted data and heavy-tailed noise further justify the proposed method.
Fast Rates of ERM and Stochastic Approximation: Adaptive to Error Bound Conditions
May 11, 2018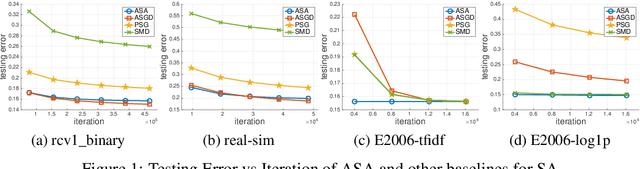
Error bound conditions (EBC) are properties that characterize the growth of an objective function when a point is moved away from the optimal set. They have recently received increasing attention in the field of optimization for developing optimization algorithms with fast convergence. However, the studies of EBC in statistical learning are hitherto still limited. The main contributions of this paper are two-fold. First, we develop fast and intermediate rates of empirical risk minimization (ERM) under EBC for risk minimization with Lipschitz continuous, and smooth convex random functions. Second, we establish fast and intermediate rates of an efficient stochastic approximation (SA) algorithm for risk minimization with Lipschitz continuous random functions, which requires only one pass of $n$ samples and adapts to EBC. For both approaches, the convergence rates span a full spectrum between $\widetilde O(1/\sqrt{n})$ and $\widetilde O(1/n)$ depending on the power constant in EBC, and could be even faster than $O(1/n)$ in special cases for ERM. Moreover, these convergence rates are automatically adaptive without using any knowledge of EBC. Overall, this work not only strengthens the understanding of ERM for statistical learning but also brings new fast stochastic algorithms for solving a broad range of statistical learning problems.
RSG: Beating Subgradient Method without Smoothness and Strong Convexity
Apr 18, 2018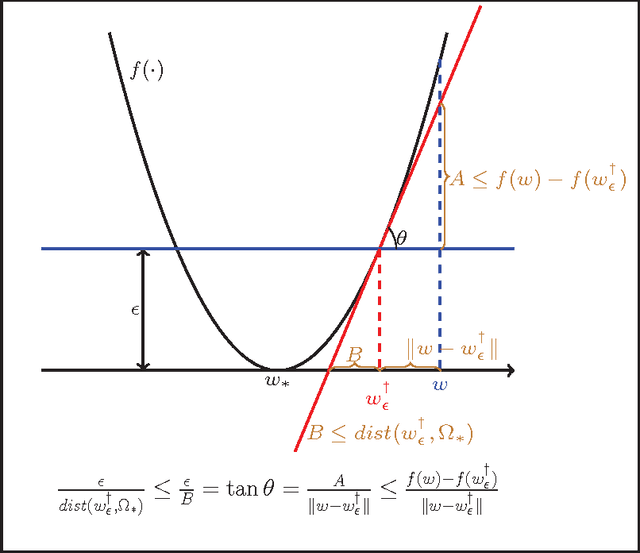
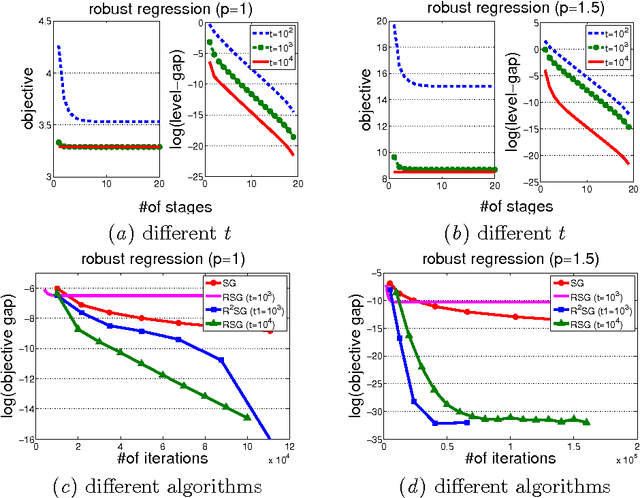
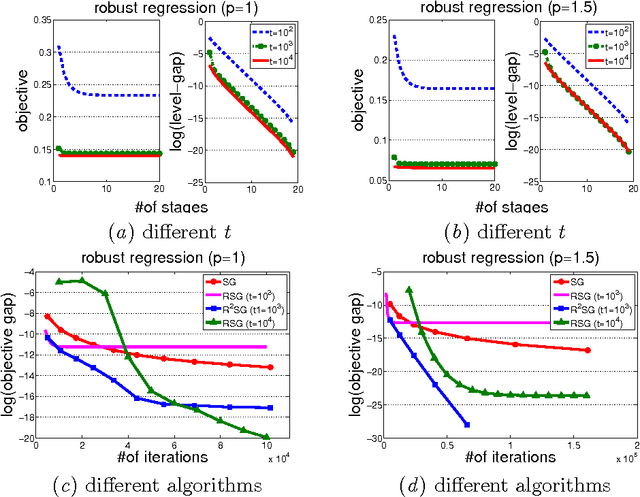
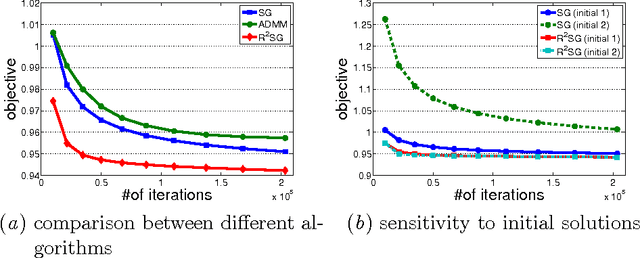
In this paper, we study the efficiency of a {\bf R}estarted {\bf S}ub{\bf G}radient (RSG) method that periodically restarts the standard subgradient method (SG). We show that, when applied to a broad class of convex optimization problems, RSG method can find an $\epsilon$-optimal solution with a low complexity than SG method. In particular, we first show that RSG can reduce the dependence of SG's iteration complexity on the distance between the initial solution and the optimal set to that between the $\epsilon$-level set and the optimal set. In addition, we show the advantages of RSG over SG in solving three different families of convex optimization problems. (a) For the problems whose epigraph is a polyhedron, RSG is shown to converge linearly. (b) For the problems with local quadratic growth property, RSG has an $O(\frac{1}{\epsilon}\log(\frac{1}{\epsilon}))$ iteration complexity. (c) For the problems that admit a local Kurdyka-\L ojasiewicz property with a power constant of $\beta\in[0,1)$, RSG has an $O(\frac{1}{\epsilon^{2\beta}}\log(\frac{1}{\epsilon}))$ iteration complexity. On the contrary, with only the standard analysis, the iteration complexity of SG is known to be $O(\frac{1}{\epsilon^2})$ for these three classes of problems. The novelty of our analysis lies at exploiting the lower bound of the first-order optimality residual at the $\epsilon$-level set. It is this novelty that allows us to explore the local properties of functions (e.g., local quadratic growth property, local Kurdyka-\L ojasiewicz property, more generally local error bounds) to develop the improved convergence of RSG. We demonstrate the effectiveness of the proposed algorithms on several machine learning tasks including regression and classification.
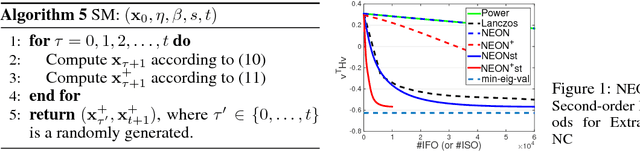
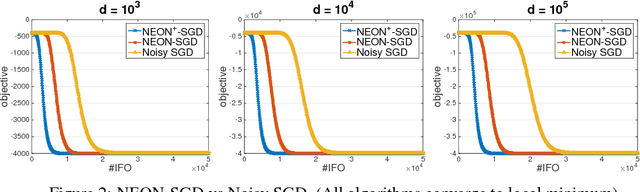
NEON+: Accelerated Gradient Methods for Extracting Negative Curvature for Non-Convex Optimization
Mar 01, 2018Accelerated gradient (AG) methods are breakthroughs in convex optimization, improving the convergence rate of the gradient descent method for optimization with smooth functions. However, the analysis of AG methods for non-convex optimization is still limited. It remains an open question whether AG methods from convex optimization can accelerate the convergence of the gradient descent method for finding local minimum of non-convex optimization problems. This paper provides an affirmative answer to this question. In particular, we analyze two renowned variants of AG methods (namely Polyak's Heavy Ball method and Nesterov's Accelerated Gradient method) for extracting the negative curvature from random noise, which is central to escaping from saddle points. By leveraging the proposed AG methods for extracting the negative curvature, we present a new AG algorithm with double loops for non-convex optimization~\footnote{this is in contrast to a single-loop AG algorithm proposed in a recent manuscript~\citep{AGNON}, which directly analyzed the Nesterov's AG method for non-convex optimization and appeared online on November 29, 2017. However, we emphasize that our work is an independent work, which is inspired by our earlier work~\citep{NEON17} and is based on a different novel analysis.}, which converges to second-order stationary point $\x$ such that $\|\nabla f(\x)\|\leq \epsilon$ and $\nabla^2 f(\x)\geq -\sqrt{\epsilon} I$ with $\widetilde O(1/\epsilon^{1.75})$ iteration complexity, improving that of gradient descent method by a factor of $\epsilon^{-0.25}$ and matching the best iteration complexity of second-order Hessian-free methods for non-convex optimization.
First-order Stochastic Algorithms for Escaping From Saddle Points in Almost Linear Time
Mar 01, 2018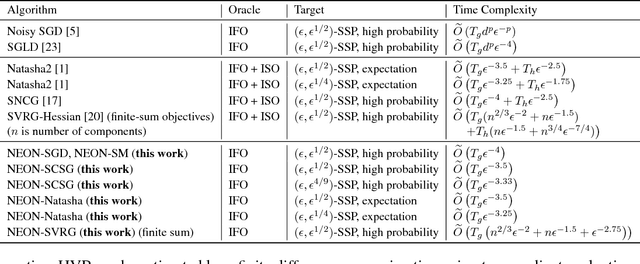
Two classes of methods have been proposed for escaping from saddle points with one using the second-order information carried by the Hessian and the other adding the noise into the first-order information. The existing analysis for algorithms using noise in the first-order information is quite involved and hides the essence of added noise, which hinder further improvements of these algorithms. In this paper, we present a novel perspective of noise-adding technique, i.e., adding the noise into the first-order information can help extract the negative curvature from the Hessian matrix, and provide a formal reasoning of this perspective by analyzing a simple first-order procedure. More importantly, the proposed procedure enables one to design purely first-order stochastic algorithms for escaping from non-degenerate saddle points with a much better time complexity (almost linear time in terms of the problem's dimensionality). In particular, we develop a {\bf first-order stochastic algorithm} based on our new technique and an existing algorithm that only converges to a first-order stationary point to enjoy a time complexity of {$\widetilde O(d/\epsilon^{3.5})$ for finding a nearly second-order stationary point $\bf{x}$ such that $\|\nabla F(bf{x})\|\leq \epsilon$ and $\nabla^2 F(bf{x})\geq -\sqrt{\epsilon}I$ (in high probability), where $F(\cdot)$ denotes the objective function and $d$ is the dimensionality of the problem. To the best of our knowledge, this is the best theoretical result of first-order algorithms for stochastic non-convex optimization, which is even competitive with if not better than existing stochastic algorithms hinging on the second-order information.
Efficient Feature Screening for Lasso-Type Problems via Hybrid Safe-Strong Rules
Nov 21, 2017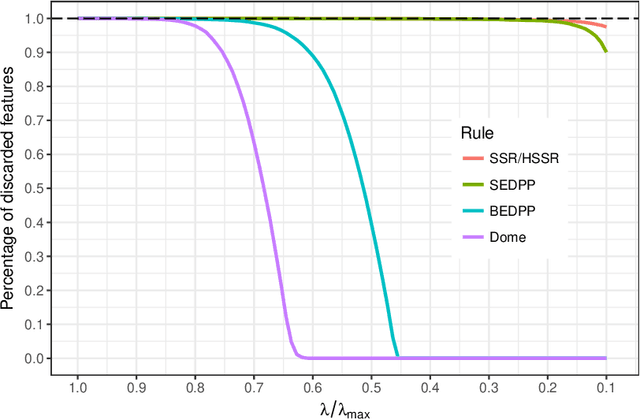

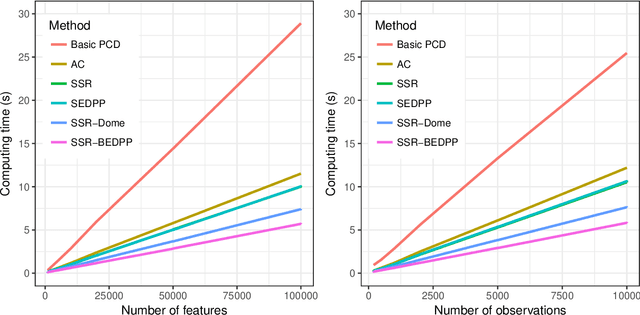
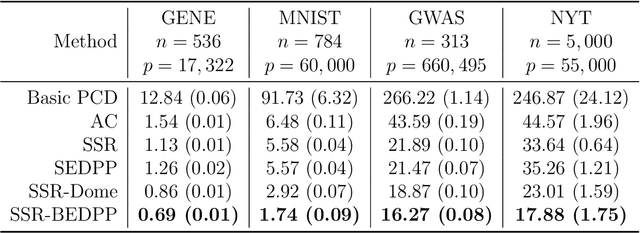
The lasso model has been widely used for model selection in data mining, machine learning, and high-dimensional statistical analysis. However, due to the ultrahigh-dimensional, large-scale data sets collected in many real-world applications, it remains challenging to solve the lasso problems even with state-of-the-art algorithms. Feature screening is a powerful technique for addressing the Big Data challenge by discarding inactive features from the lasso optimization. In this paper, we propose a family of hybrid safe-strong rules (HSSR) which incorporate safe screening rules into the sequential strong rule (SSR) to remove unnecessary computational burden. In particular, we present two instances of HSSR, namely SSR-Dome and SSR-BEDPP, for the standard lasso problem. We further extend SSR-BEDPP to the elastic net and group lasso problems to demonstrate the generalizability of the hybrid screening idea. Extensive numerical experiments with synthetic and real data sets are conducted for both the standard lasso and the group lasso problems. Results show that our proposed hybrid rules substantially outperform existing state-of-the-art rules.