 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-free Test Time Adaptation for Out-Of-Distribution Detection
Nov 28, 2023



Out-of-distribution (OOD) detection is essential for the reliability of ML models. Most existing methods for OOD detection learn a fixed decision criterion from a given in-distribution dataset and apply it universally to decide if a data point is OOD. Recent work~\cite{fang2022is} shows that given only in-distribution data, it is impossible to reliably detect OOD data without extra assumptions. Motivated by the theoretical result and recent exploration of test-time adaptation methods, we propose a Non-Parametric Test Time \textbf{Ada}ptation framework for \textbf{O}ut-Of-\textbf{D}istribution \textbf{D}etection (\abbr). Unlike conventional methods, \abbr utilizes online test samples for model adaptation during testing, enhancing adaptability to changing data distributions. The framework incorporates detected OOD instances into decision-making, reducing false positive rates, particularly when ID and OOD distributions overlap significantly. We demonstrate the effectiveness of \abbr through comprehensive experiments on multiple OOD detection benchmarks, extensive empirical studies show that \abbr significantly improves the performance of OOD detection over state-of-the-art methods. Specifically, \abbr reduces the false positive rate (FPR95) by $23.23\%$ on the CIFAR-10 benchmarks and $38\%$ on the ImageNet-1k benchmarks compared to the advanced methods. Lastly, we theoretically verify the effectiveness of \abbr.
One Fits All: Universal Time Series Analysis by Pretrained LM and Specially Designed Adaptors
Nov 24, 2023Despite the impressive achievements of pre-trained models in the fields of natural language processing (NLP) and computer vision (CV), progress in the domain of time series analysis has been limited. In contrast to NLP and CV, where a single model can handle various tasks, time series analysis still relies heavily on task-specific methods for activities such as classification, anomaly detection, forecasting, and few-shot learning. The primary obstacle to developing a pre-trained model for time series analysis is the scarcity of sufficient training data. In our research, we overcome this obstacle by utilizing pre-trained models from language or CV, which have been trained on billions of data points, and apply them to time series analysis. We assess the effectiveness of the pre-trained transformer model in two ways. Initially, we maintain the original structure of the self-attention and feedforward layers in the residual blocks of the pre-trained language or image model, using the Frozen Pre-trained Transformer (FPT) for time series analysis with the addition of projection matrices for input and output. Additionally, we introduce four unique adapters, designed specifically for downstream tasks based on the pre-trained model, including forecasting and anomaly detection. These adapters are further enhanced with efficient parameter tuning, resulting in superior performance compared to all state-of-the-art methods.Our comprehensive experimental studies reveal that (a) the simple FPT achieves top-tier performance across various time series analysis tasks; and (b) fine-tuning the FPT with the custom-designed adapters can further elevate its performance, outshining specialized task-specific models.
DCdetector: Dual Attention Contrastive Representation Learning for Time Series Anomaly Detection
Jun 17, 2023Time series anomaly detection is critical for a wide range of applications. It aims to identify deviant samples from the normal sample distribution in time series. The most fundamental challenge for this task is to learn a representation map that enables effective discrimination of anomalies. Reconstruction-based methods still dominate, but the representation learning with anomalies might hurt the performance with its large abnormal loss. On the other hand, contrastive learning aims to find a representation that can clearly distinguish any instance from the others, which can bring a more natural and promising representation for time series anomaly detection. In this paper, we propose DCdetector, a multi-scale dual attention contrastive representation learning model. DCdetector utilizes a novel dual attention asymmetric design to create the permutated environment and pure contrastive loss to guide the learning process, thus learning a permutation invariant representation with superior discrimination abilities. Extensive experiments show that DCdetector achieves state-of-the-art results on multiple time series anomaly detection benchmark datasets. Code is publicly available at https://github.com/DAMO-DI-ML/KDD2023-DCdetector.
GCformer: An Efficient Framework for Accurate and Scalable Long-Term Multivariate Time Series Forecasting
Jun 14, 2023



Transformer-based models have emerged as promising tools for time series forecasting. However, these model cannot make accurate prediction for long input time series. On the one hand, they failed to capture global dependencies within time series data. On the other hand, the long input sequence usually leads to large model size and high time complexity. To address these limitations, we present GCformer, which combines a structured global convolutional branch for processing long input sequences with a local Transformer-based branch for capturing short, recent signals. A cohesive framework for a global convolution kernel has been introduced, utilizing three distinct parameterization methods. The selected structured convolutional kernel in the global branch has been specifically crafted with sublinear complexity, thereby allowing for the efficient and effective processing of lengthy and noisy input signals. Empirical studies on six benchmark datasets demonstrate that GCformer outperforms state-of-the-art methods, reducing MSE error in multivariate time series benchmarks by 4.38% and model parameters by 61.92%. In particular, the global convolutional branch can serve as a plug-in block to enhance the performance of other models, with an average improvement of 31.93\%, including various recently published Transformer-based models. Our code is publicly available at https://github.com/zyj-111/GCformer.
SaDI: A Self-adaptive Decomposed Interpretable Framework for Electric Load Forecasting under Extreme Events
Jun 14, 2023



Accurate prediction of electric load is crucial in power grid planning and management. In this paper, we solve the electric load forecasting problem under extreme events such as scorching heats. One challenge for accurate forecasting is the lack of training samples under extreme conditions. Also load usually changes dramatically in these extreme conditions, which calls for interpretable model to make better decisions. In this paper, we propose a novel forecasting framework, named Self-adaptive Decomposed Interpretable framework~(SaDI), which ensembles long-term trend, short-term trend, and period modelings to capture temporal characteristics in different components. The external variable triggered loss is proposed for the imbalanced learning under extreme events. Furthermore, Generalized Additive Model (GAM) is employed in the framework for desirable interpretability. The experiments on both Central China electric load and public energy meters from buildings show that the proposed SaDI framework achieves average 22.14% improvement compared with the current state-of-the-art algorithms in forecasting under extreme events in terms of daily mean of normalized RMSE. Code, Public datasets, and Appendix are available at: https://doi.org/10.24433/CO.9696980.v1 .
Make Transformer Great Again for Time Series Forecasting: Channel Aligned Robust Dual Transformer
May 24, 2023Recent studies have demonstrated the great power of deep learning methods, particularly Transformer and MLP, for time series forecasting. Despite its success in NLP and CV, many studies found that Transformer is less effective than MLP for time series forecasting. In this work, we design a special Transformer, i.e., channel-aligned robust dual Transformer (CARD for short), that addresses key shortcomings of Transformer in time series forecasting. First, CARD introduces a dual Transformer structure that allows it to capture both temporal correlations among signals and dynamical dependence among multiple variables over time. Second, we introduce a robust loss function for time series forecasting to alleviate the potential overfitting issue. This new loss function weights the importance of forecasting over a finite horizon based on prediction uncertainties. Our evaluation of multiple long-term and short-term forecasting datasets demonstrates that CARD significantly outperforms state-of-the-art time series forecasting methods, including both Transformer and MLP-based models.
How Expressive are Spectral-Temporal Graph Neural Networks for Time Series Forecasting?
May 11, 2023Spectral-temporal graph neural network is a promising abstraction underlying most time series forecasting models that are based on graph neural networks (GNNs). However, more is needed to know about the underpinnings of this branch of methods. In this paper, we establish a theoretical framework that unravels the expressive power of spectral-temporal GNNs. Our results show that linear spectral-temporal GNNs are universal under mild assumptions, and their expressive power is bounded by our extended first-order Weisfeiler-Leman algorithm on discrete-time dynamic graphs. To make our findings useful in practice on valid instantiations, we discuss related constraints in detail and outline a theoretical blueprint for designing spatial and temporal modules in spectral domains. Building on these insights and to demonstrate how powerful spectral-temporal GNNs are based on our framework, we propose a simple instantiation named Temporal Graph GegenConv (TGC), which significantly outperforms most existing models with only linear components and shows better model efficiency.
Power Time Series Forecasting by Pretrained LM
Feb 23, 2023



The diversity and domain dependence of time series data pose significant challenges in transferring learning to time series forecasting. In this study, we examine the effectiveness of using a transformer model that has been pre-trained on natural language or image data and then fine-tuned for time series forecasting with minimal modifications, specifically, without altering the self-attention and feedforward layers of the residual blocks. This model, known as the Frozen Pretrained Transformer (FPT), is evaluated through fine-tuning on time series forecasting tasks under Zero-Shot, Few-Shot, and normal sample size conditions. Our results demonstrate that pre-training on natural language or images can lead to a comparable or state-of-the-art performance in cross-modality time series forecasting tasks, in contrast to previous studies that focused on fine-tuning within the same modality as the pre-training data. Additionally, we provide a comprehensive theoretical analysis of the universality and the functionality of the FPT. The code is publicly available at https://anonymous.4open.science/r/Pretrained-LM-for-TSForcasting-C561.
TFAD: A Decomposition Time Series Anomaly Detection Architecture with Time-Frequency Analysis
Oct 18, 2022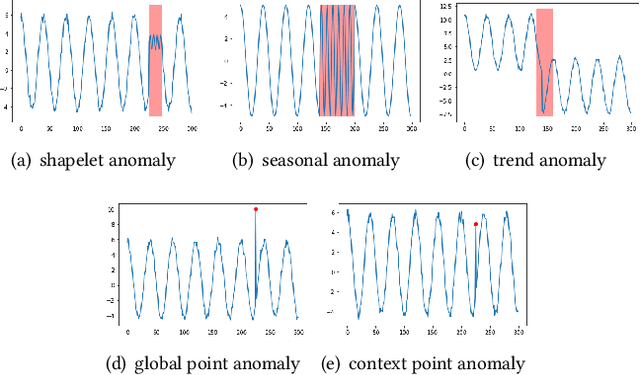
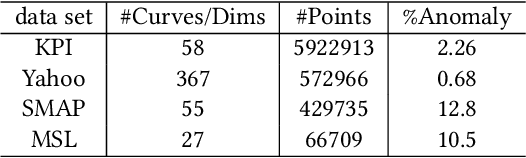
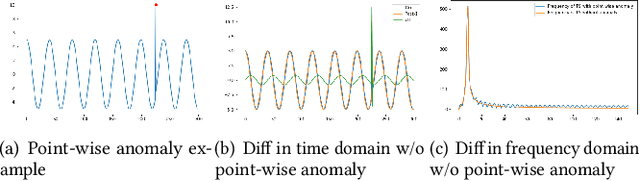
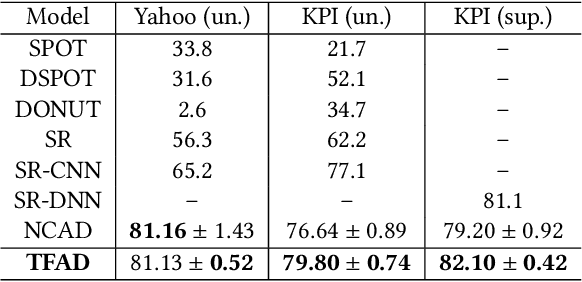
Time series anomaly detection is a challenging problem due to the complex temporal dependencies and the limited label data. Although some algorithms including both traditional and deep models have been proposed, most of them mainly focus on time-domain modeling, and do not fully utilize the information in the frequency domain of the time series data. In this paper, we propose a Time-Frequency analysis based time series Anomaly Detection model, or TFAD for short, to exploit both time and frequency domains for performance improvement. Besides, we incorporate time series decomposition and data augmentation mechanisms in the designed time-frequency architecture to further boost the abilities of performance and interpretability. Empirical studies on widely used benchmark datasets show that our approach obtains state-of-the-art performance in univariate and multivariate time series anomaly detection tasks. Code is provided at https://github.com/DAMO-DI-ML/CIKM22-TFAD.
TreeDRNet:A Robust Deep Model for Long Term Time Series Forecasting
Jun 24, 2022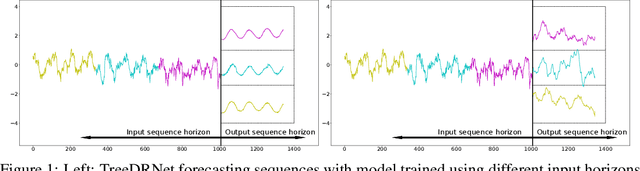
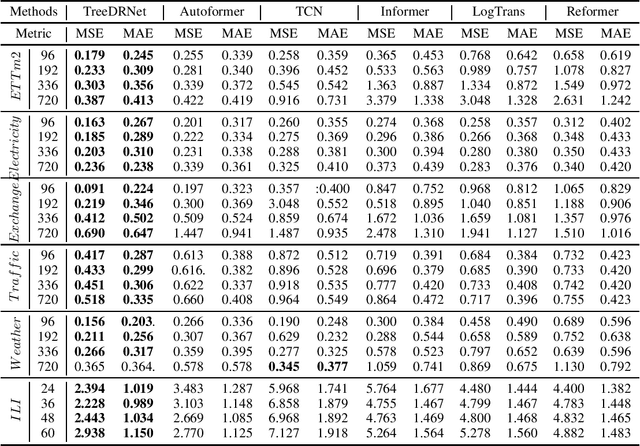
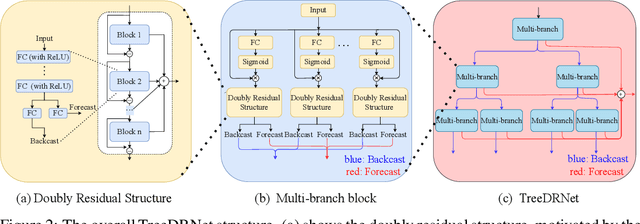

Various deep learning models, especially some latest Transformer-based approaches, have greatly improved the state-of-art performance for long-term time series forecasting.However, those transformer-based models suffer a severe deterioration performance with prolonged input length, which prohibits them from using extended historical info.Moreover, these methods tend to handle complex examples in long-term forecasting with increased model complexity, which often leads to a significant increase in computation and less robustness in performance(e.g., overfitting). We propose a novel neural network architecture, called TreeDRNet, for more effective long-term forecasting. Inspired by robust regression, we introduce doubly residual link structure to make prediction more robust.Built upon Kolmogorov-Arnold representation theorem, we explicitly introduce feature selection, model ensemble, and a tree structure to further utilize the extended input sequence, which improves the robustness and representation power of TreeDRNet. Unlike previous deep models for sequential forecasting work, TreeDRNet is built entirely on multilayer perceptron and thus enjoys high computational efficiency. Our extensive empirical studies show that TreeDRNet is significantly more effective than state-of-the-art methods, reducing prediction errors by 20% to 40% for multivariate time series. In particular, TreeDRNet is over 10 times more efficient than transformer-based methods. The code will be released soon.