 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Permission Manipulation: Can We Trust Large Multimodal Model Powered GUI Agents?
Jan 18, 2026Large multimodal model powered GUI agents are emerging as high-privilege operators on mobile platforms, entrusted with perceiving screen content and injecting inputs. However, their design operates under the implicit assumption of Visual Atomicity: that the UI state remains invariant between observation and action. We demonstrate that this assumption is fundamentally invalid in Android, creating a critical attack surface. We present Action Rebinding, a novel attack that allows a seemingly-benign app with zero dangerous permissions to rebind an agent's execution. By exploiting the inevitable observation-to-action gap inherent in the agent's reasoning pipeline, the attacker triggers foreground transitions to rebind the agent's planned action toward the target app. We weaponize the agent's task-recovery logic and Android's UI state preservation to orchestrate programmable, multi-step attack chains. Furthermore, we introduce an Intent Alignment Strategy (IAS) that manipulates the agent's reasoning process to rationalize UI states, enabling it to bypass verification gates (e.g., confirmation dialogs) that would otherwise be rejected. We evaluate Action Rebinding Attacks on six widely-used Android GUI agents across 15 tasks. Our results demonstrate a 100% success rate for atomic action rebinding and the ability to reliably orchestrate multi-step attack chains. With IAS, the success rate in bypassing verification gates increases (from 0% to up to 100%). Notably, the attacker application requires no sensitive permissions and contains no privileged API calls, achieving a 0% detection rate across malware scanners (e.g., VirusTotal). Our findings reveal a fundamental architectural flaw in current agent-OS integration and provide critical insights for the secure design of future agent systems. To access experimental logs and demonstration videos, please contact yi_qian@smail.nju.edu.cn.
Less is more: Embracing sparsity and interpolation with Esiformer for time series forecasting
Oct 08, 2024Time series forecasting has played a significant role in many practical fields. But time series data generated from real-world applications always exhibits high variance and lots of noise, which makes it difficult to capture the inherent periodic patterns of the data, hurting the prediction accuracy significantly. To address this issue, we propose the Esiformer, which apply interpolation on the original data, decreasing the overall variance of the data and alleviating the influence of noise. What's more, we enhanced the vanilla transformer with a robust Sparse FFN. It can enhance the representation ability of the model effectively, and maintain the excellent robustness, avoiding the risk of overfitting compared with the vanilla implementation. Through evaluations on challenging real-world datasets, our method outperforms leading model PatchTST, reducing MSE by 6.5% and MAE by 5.8% in multivariate time series forecasting. Code is available at: https://github.com/yyg1282142265/Esiformer/tree/main.
Backdoor Attacks and Defenses on Semantic-Symbol Reconstruction in Semantic Communications
Apr 20, 2024



Semantic communication is of crucial importance for the next-generation wireless communication networks. The existing works have developed semantic communication frameworks based on deep learning. However, systems powered by deep learning are vulnerable to threats such as backdoor attacks and adversarial attacks. This paper delves into backdoor attacks targeting deep learning-enabled semantic communication systems. Since current works on backdoor attacks are not tailored for semantic communication scenarios, a new backdoor attack paradigm on semantic symbols (BASS) is introduced, based on which the corresponding defense measures are designed. Specifically, a training framework is proposed to prevent BASS. Additionally, reverse engineering-based and pruning-based defense strategies are designed to protect against backdoor attacks in semantic communication. Simulation results demonstrate the effectiveness of both the proposed attack paradigm and the defense strategies.
Second-Order Fine-Tuning without Pain for LLMs:A Hessian Informed Zeroth-Order Optimizer
Feb 23, 2024Fine-tuning large language models (LLMs) with classic first-order optimizers entails prohibitive GPU memory due to the backpropagation process. Recent works have turned to zeroth-order optimizers for fine-tuning, which save substantial memory by using two forward passes. However, these optimizers are plagued by the heterogeneity of parameter curvatures across different dimensions. In this work, we propose HiZOO, a diagonal Hessian informed zeroth-order optimizer which is the first work to leverage the diagonal Hessian to enhance zeroth-order optimizer for fine-tuning LLMs. What's more, HiZOO avoids the expensive memory cost and only increases one forward pass per step. Extensive experiments on various models (350M~66B parameters) indicate that HiZOO improves model convergence, significantly reducing training steps and effectively enhancing model accuracy. Moreover, we visualize the optimization trajectories of HiZOO on test functions, illustrating its effectiveness in handling heterogeneous curvatures. Lastly, we provide theoretical proofs of convergence for HiZOO. Code is publicly available at https://anonymous.4open.science/r/HiZOO27F8.
Sparse-VQ Transformer: An FFN-Free Framework with Vector Quantization for Enhanced Time Series Forecasting
Feb 08, 2024



Time series analysis is vital for numerous applications, and transformers have become increasingly prominent in this domain. Leading methods customize the transformer architecture from NLP and CV, utilizing a patching technique to convert continuous signals into segments. Yet, time series data are uniquely challenging due to significant distribution shifts and intrinsic noise levels. To address these two challenges,we introduce the Sparse Vector Quantized FFN-Free Transformer (Sparse-VQ). Our methodology capitalizes on a sparse vector quantization technique coupled with Reverse Instance Normalization (RevIN) to reduce noise impact and capture sufficient statistics for forecasting, serving as an alternative to the Feed-Forward layer (FFN) in the transformer architecture. Our FFN-free approach trims the parameter count, enhancing computational efficiency and reducing overfitting. Through evaluations across ten benchmark datasets, including the newly introduced CAISO dataset, Sparse-VQ surpasses leading models with a 7.84% and 4.17% decrease in MAE for univariate and multivariate time series forecasting, respectively. Moreover, it can be seamlessly integrated with existing transformer-based models to elevate their performance.
GCformer: An Efficient Framework for Accurate and Scalable Long-Term Multivariate Time Series Forecasting
Jun 14, 2023



Transformer-based models have emerged as promising tools for time series forecasting. However, these model cannot make accurate prediction for long input time series. On the one hand, they failed to capture global dependencies within time series data. On the other hand, the long input sequence usually leads to large model size and high time complexity. To address these limitations, we present GCformer, which combines a structured global convolutional branch for processing long input sequences with a local Transformer-based branch for capturing short, recent signals. A cohesive framework for a global convolution kernel has been introduced, utilizing three distinct parameterization methods. The selected structured convolutional kernel in the global branch has been specifically crafted with sublinear complexity, thereby allowing for the efficient and effective processing of lengthy and noisy input signals. Empirical studies on six benchmark datasets demonstrate that GCformer outperforms state-of-the-art methods, reducing MSE error in multivariate time series benchmarks by 4.38% and model parameters by 61.92%. In particular, the global convolutional branch can serve as a plug-in block to enhance the performance of other models, with an average improvement of 31.93\%, including various recently published Transformer-based models. Our code is publicly available at https://github.com/zyj-111/GCformer.
A New Implementation of Federated Learning for Privacy and Security Enhancement
Aug 03, 2022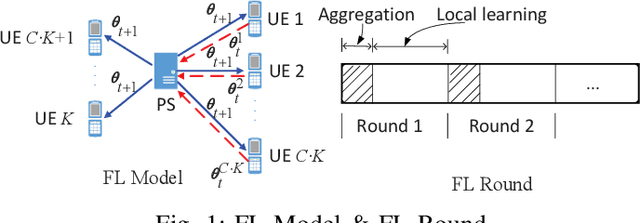
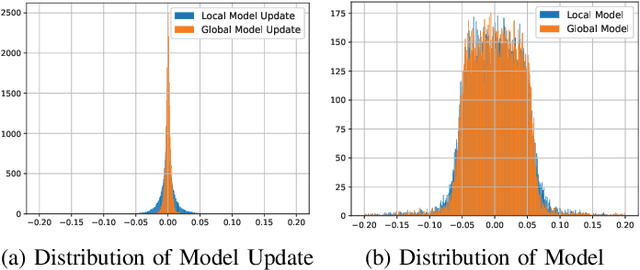
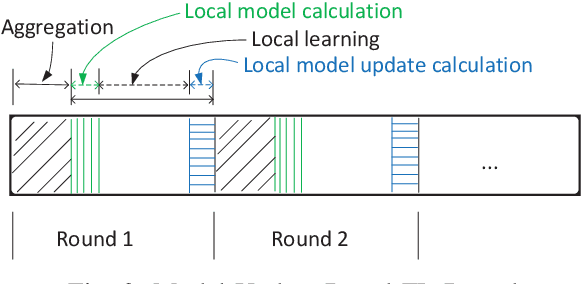
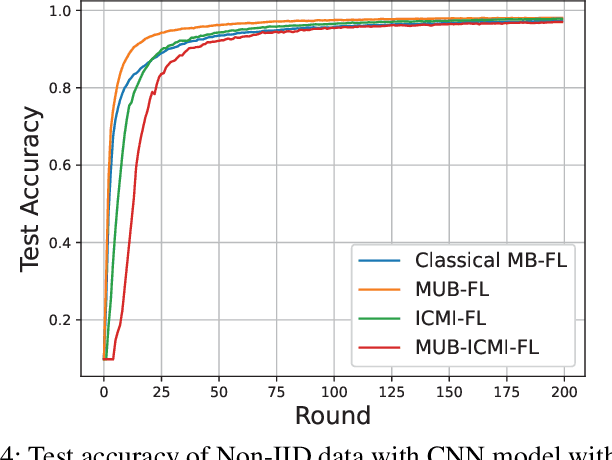
Motivated by the ever-increasing concerns on personal data privacy and the rapidly growing data volume at local clients, federated learning (FL) has emerged as a new machine learning setting. An FL system is comprised of a central parameter server and multiple local clients. It keeps data at local clients and learns a centralized model by sharing the model parameters learned locally. No local data needs to be shared, and privacy can be well protected. Nevertheless, since it is the model instead of the raw data that is shared, the system can be exposed to the poisoning model attacks launched by malicious clients. Furthermore, it is challenging to identify malicious clients since no local client data is available on the server. Besides, membership inference attacks can still be performed by using the uploaded model to estimate the client's local data, leading to privacy disclosure. In this work, we first propose a model update based federated averaging algorithm to defend against Byzantine attacks such as additive noise attacks and sign-flipping attacks. The individual client model initialization method is presented to provide further privacy protections from the membership inference attacks by hiding the individual local machine learning model. When combining these two schemes, privacy and security can be both effectively enhanced. The proposed schemes are proved to converge experimentally under non-IID data distribution when there are no attacks. Under Byzantine attacks, the proposed schemes perform much better than the classical model based FedAvg algorithm.
Noise and Edge Based Dual Branch Image Manipulation Detection
Jul 02, 2022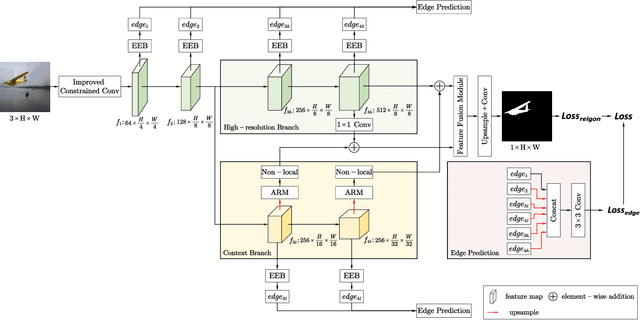
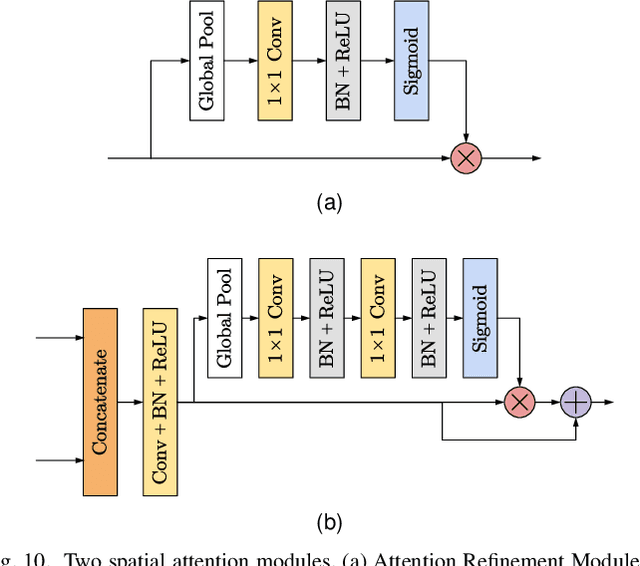
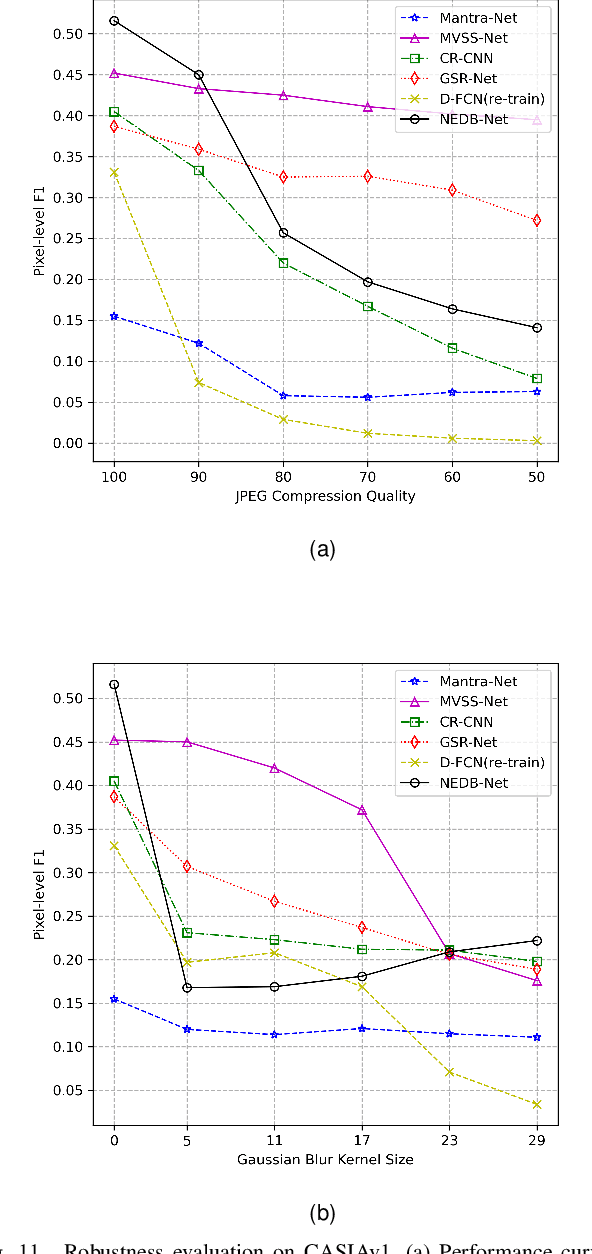
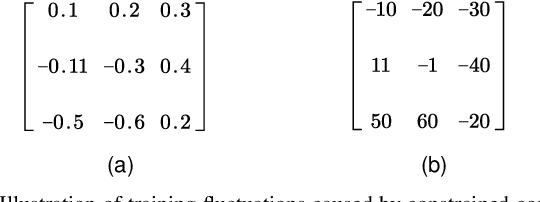
Unlike ordinary computer vision tasks that focus more on the semantic content of images, the image manipulation detection task pays more attention to the subtle information of image manipulation. In this paper, the noise image extracted by the improved constrained convolution is used as the input of the model instead of the original image to obtain more subtle traces of manipulation. Meanwhile, the dual-branch network, consisting of a high-resolution branch and a context branch, is used to capture the traces of artifacts as much as possible. In general, most manipulation leaves manipulation artifacts on the manipulation edge. A specially designed manipulation edge detection module is constructed based on the dual-branch network to identify these artifacts better. The correlation between pixels in an image is closely related to their distance. The farther the two pixels are, the weaker the correlation. We add a distance factor to the self-attention module to better describe the correlation between pixels. Experimental results on four publicly available image manipulation datasets demonstrate the effectiveness of our model.
Multi-Agent Deep Reinforcement Learning enabled Computation Resource Allocation in a Vehicular Cloud Network
Aug 17, 2020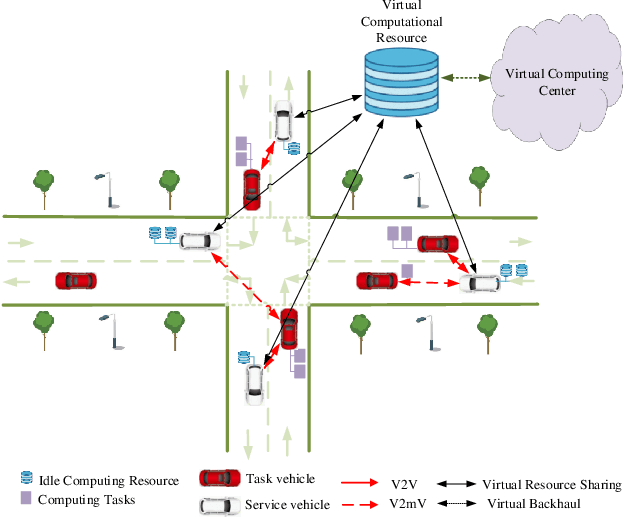
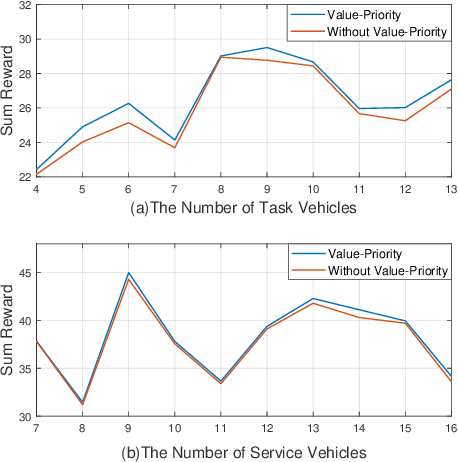
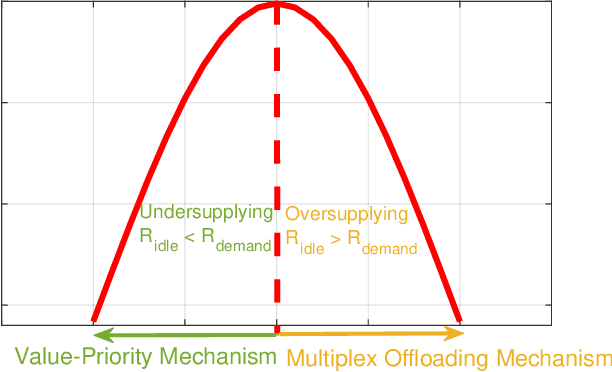
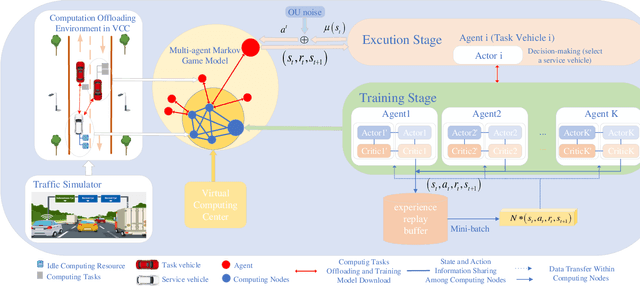
In this paper, we investigate the computational resource allocation problem in a distributed Ad-Hoc vehicular network with no centralized infrastructure support. To support the ever increasing computational needs in such a vehicular network, the distributed virtual cloud network (VCN) is formed, based on which a computational resource sharing scheme through offloading among nearby vehicles is proposed. In view of the time-varying computational resource in VCN, the statistical distribution characteristics for computational resource are analyzed in detail. Thereby, a resource-aware combinatorial optimization objective mechanism is proposed. To alleviate the non-stationary environment caused by the typically multi-agent environment in VCN, we adopt a centralized training and decentralized execution framework. In addition, for the objective optimization problem, we model it as a Markov game and propose a DRL based multi-agent deep deterministic reinforcement learning (MADDPG) algorithm to solve it. Interestingly, to overcome the dilemma of lacking a real central control unit in VCN, the allocation is actually completed on the vehicles in a distributed manner. The simulation results are presented to demonstrate our scheme's effectiveness.