 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Object Detection Using Unsupervised Image Translation
Jan 16, 2026Unsupervised domain adaptation for object detection addresses the adaption of detectors trained in a source domain to work accurately in an unseen target domain. Recently, methods approaching the alignment of the intermediate features proven to be promising, achieving state-of-the-art results. However, these methods are laborious to implement and hard to interpret. Although promising, there is still room for improvements to close the performance gap toward the upper-bound (when training with the target data). In this work, we propose a method to generate an artificial dataset in the target domain to train an object detector. We employed two unsupervised image translators (CycleGAN and an AdaIN-based model) using only annotated data from the source domain and non-annotated data from the target domain. Our key contributions are the proposal of a less complex yet more effective method that also has an improved interpretability. Results on real-world scenarios for autonomous driving show significant improvements, outperforming state-of-the-art methods in most cases, further closing the gap toward the upper-bound.
Budget-Aware Pruning: Handling Multiple Domains with Less Parameters
Sep 20, 2023Deep learning has achieved state-of-the-art performance on several computer vision tasks and domains. Nevertheless, it still has a high computational cost and demands a significant amount of parameters. Such requirements hinder the use in resource-limited environments and demand both software and hardware optimization. Another limitation is that deep models are usually specialized into a single domain or task, requiring them to learn and store new parameters for each new one. Multi-Domain Learning (MDL) attempts to solve this problem by learning a single model that is capable of performing well in multiple domains. Nevertheless, the models are usually larger than the baseline for a single domain. This work tackles both of these problems: our objective is to prune models capable of handling multiple domains according to a user-defined budget, making them more computationally affordable while keeping a similar classification performance. We achieve this by encouraging all domains to use a similar subset of filters from the baseline model, up to the amount defined by the user's budget. Then, filters that are not used by any domain are pruned from the network. The proposed approach innovates by better adapting to resource-limited devices while, to our knowledge, being the only work that handles multiple domains at test time with fewer parameters and lower computational complexity than the baseline model for a single domain.
Parameter Sharing in Budget-Aware Adapters for Multi-Domain Learning
Oct 14, 2022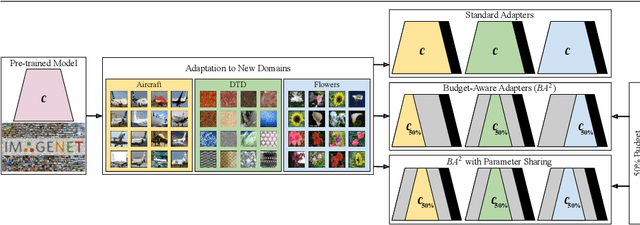
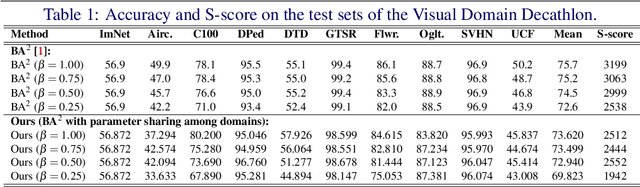
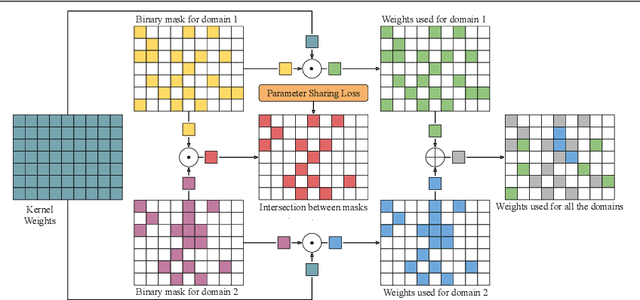
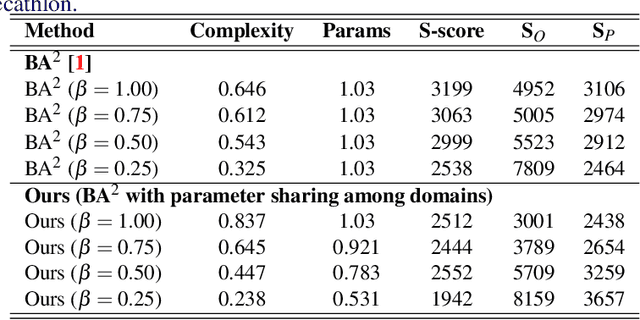
Deep learning has achieved state-of-the-art performance on several computer vision tasks and domains. Nevertheless, it still demands a high computational cost and a significant amount of parameters that need to be learned for each new domain. Such requirements hinder the use in resource-limited environments and demand both software and hardware optimization. Multi-domain learning addresses this problem by adapting to new domains while retaining the knowledge of the original domain. One limitation of most multi-domain learning approaches is that they usually are not designed for taking into account the resources available to the user. Recently, some works that can reduce computational complexity and amount of parameters to fit the user needs have been proposed, but they need the entire original model to handle all the domains together. This work proposes a method capable of adapting to a user-defined budget while encouraging parameter sharing among domains. Hence, filters that are not used by any domain can be pruned from the network at test time. The proposed approach innovates by better adapting to resource-limited devices while being able to handle multiple domains at test time with fewer parameters and lower computational complexity than the baseline model.
Unsupervised Domain Adaptation for Video Transformers in Action Recognition
Jul 26, 2022
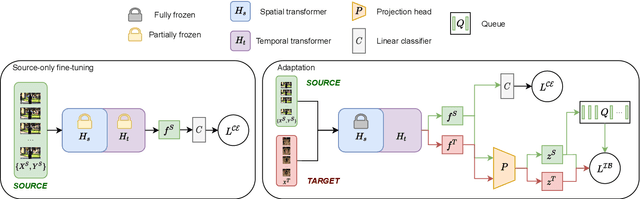
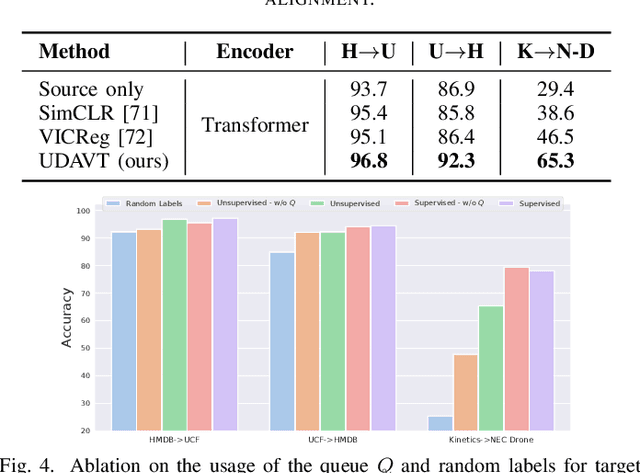
Over the last few years, Unsupervised Domain Adaptation (UDA) techniques have acquired remarkable importance and popularity in computer vision. However, when compared to the extensive literature available for images, the field of videos is still relatively unexplored. On the other hand, the performance of a model in action recognition is heavily affected by domain shift. In this paper, we propose a simple and novel UDA approach for video action recognition. Our approach leverages recent advances on spatio-temporal transformers to build a robust source model that better generalises to the target domain. Furthermore, our architecture learns domain invariant features thanks to the introduction of a novel alignment loss term derived from the Information Bottleneck principle. We report results on two video action recognition benchmarks for UDA, showing state-of-the-art performance on HMDB$\leftrightarrow$UCF, as well as on Kinetics$\rightarrow$NEC-Drone, which is more challenging. This demonstrates the effectiveness of our method in handling different levels of domain shift. The source code is available at https://github.com/vturrisi/UDAVT.
Deep Learning-based Type Identification of Volumetric MRI Sequences
Jun 06, 2021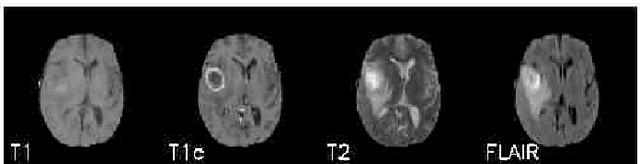
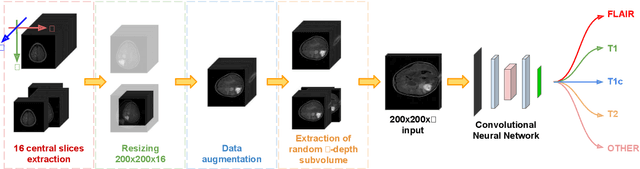
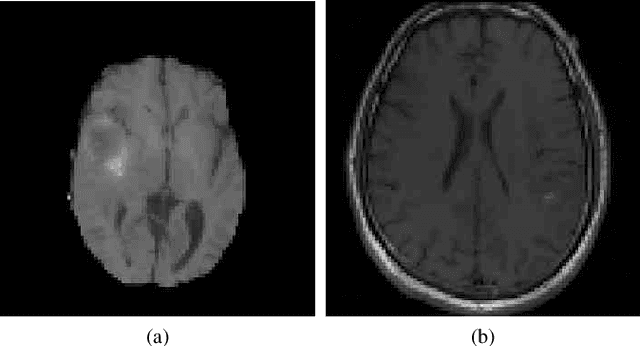
The analysis of Magnetic Resonance Imaging (MRI) sequences enables clinical professionals to monitor the progression of a brain tumor. As the interest for automatizing brain volume MRI analysis increases, it becomes convenient to have each sequence well identified. However, the unstandardized naming of MRI sequences makes their identification difficult for automated systems, as well as makes it difficult for researches to generate or use datasets for machine learning research. In the face of that, we propose a system for identifying types of brain MRI sequences based on deep learning. By training a Convolutional Neural Network (CNN) based on 18-layer ResNet architecture, our system can classify a volumetric brain MRI as a FLAIR, T1, T1c or T2 sequence, or whether it does not belong to any of these classes. The network was evaluated on publicly available datasets comprising both, pre-processed (BraTS dataset) and non-pre-processed (TCGA-GBM dataset), image types with diverse acquisition protocols, requiring only a few slices of the volume for training. Our system can classify among sequence types with an accuracy of 96.81%.
Copycat CNN: Are Random Non-Labeled Data Enough to Steal Knowledge from Black-box Models?
Jan 21, 2021
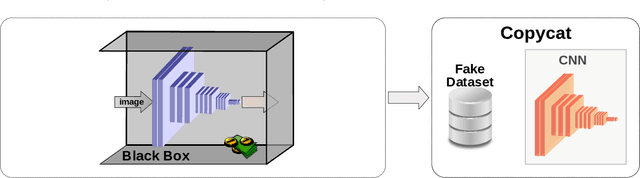

Convolutional neural networks have been successful lately enabling companies to develop neural-based products, which demand an expensive process, involving data acquisition and annotation; and model generation, usually requiring experts. With all these costs, companies are concerned about the security of their models against copies and deliver them as black-boxes accessed by APIs. Nonetheless, we argue that even black-box models still have some vulnerabilities. In a preliminary work, we presented a simple, yet powerful, method to copy black-box models by querying them with natural random images. In this work, we consolidate and extend the copycat method: (i) some constraints are waived; (ii) an extensive evaluation with several problems is performed; (iii) models are copied between different architectures; and, (iv) a deeper analysis is performed by looking at the copycat behavior. Results show that natural random images are effective to generate copycats for several problems.
* The code is available at https://github.com/jeiks/Stealing_DL_Models
Deep traffic light detection by overlaying synthetic context on arbitrary natural images
Nov 10, 2020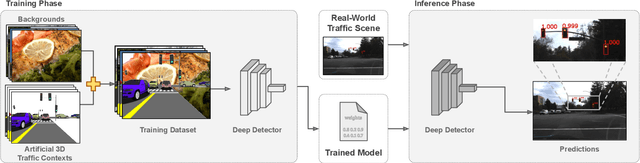
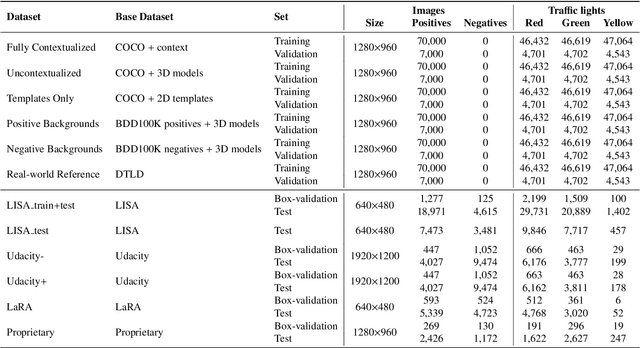
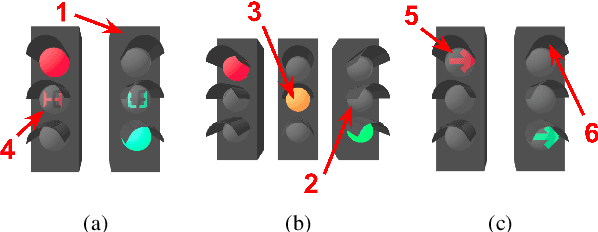
Deep neural networks come as an effective solution to many problems associated with autonomous driving. By providing real image samples with traffic context to the network, the model learns to detect and classify elements of interest, such as pedestrians, traffic signs, and traffic lights. However, acquiring and annotating real data can be extremely costly in terms of time and effort. In this context, we propose a method to generate artificial traffic-related training data for deep traffic light detectors. This data is generated using basic non-realistic computer graphics to blend fake traffic scenes on top of arbitrary image backgrounds that are not related to the traffic domain. Thus, a large amount of training data can be generated without annotation efforts. Furthermore, it also tackles the intrinsic data imbalance problem in traffic light datasets, caused mainly by the low amount of samples of the yellow state. Experiments show that it is possible to achieve results comparable to those obtained with real training data from the problem domain, yielding an average mAP and an average F1-score which are each nearly 4 p.p. higher than the respective metrics obtained with a real-world reference model.
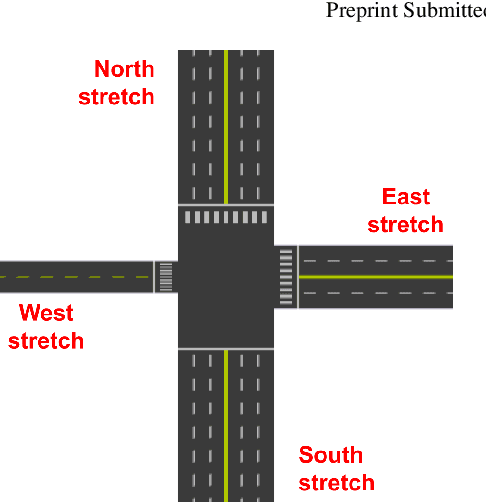
What is the Best Grid-Map for Self-Driving Cars Localization? An Evaluation under Diverse Types of Illumination, Traffic, and Environment
Sep 19, 2020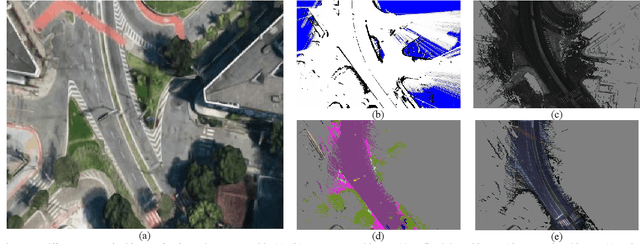
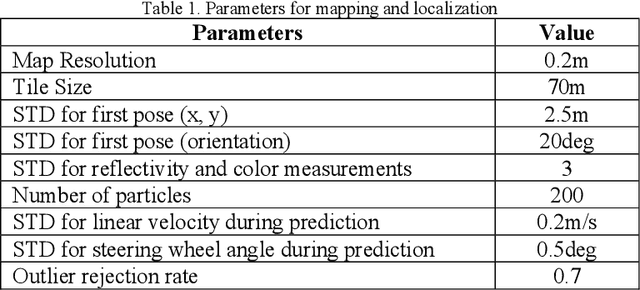
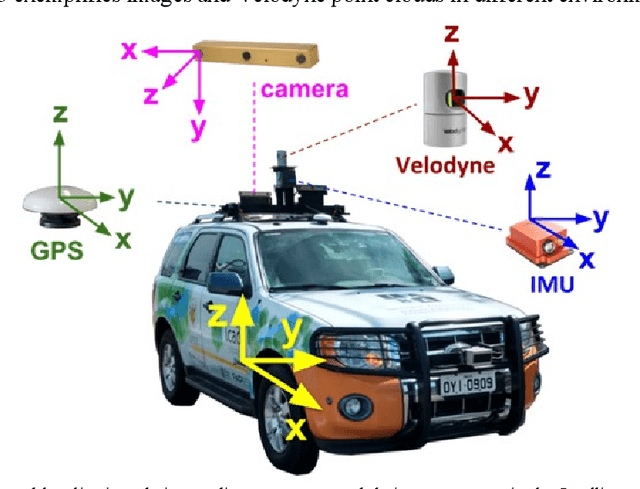
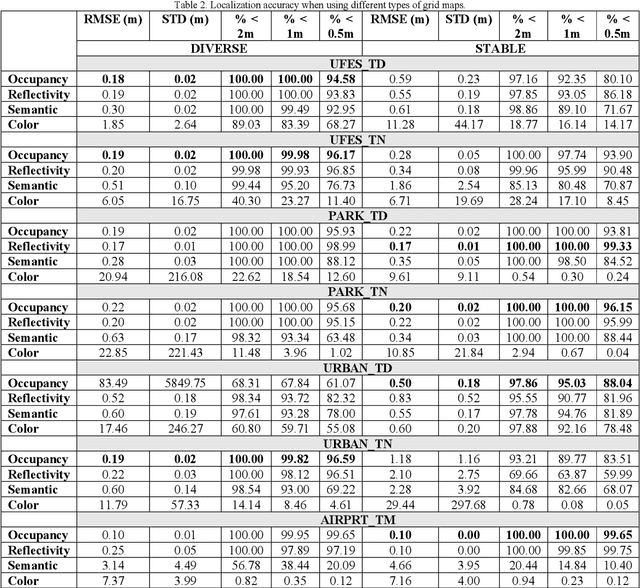
The localization of self-driving cars is needed for several tasks such as keeping maps updated, tracking objects, and planning. Localization algorithms often take advantage of maps for estimating the car pose. Since maintaining and using several maps is computationally expensive, it is important to analyze which type of map is more adequate for each application. In this work, we provide data for such analysis by comparing the accuracy of a particle filter localization when using occupancy, reflectivity, color, or semantic grid maps. To the best of our knowledge, such evaluation is missing in the literature. For building semantic and colour grid maps, point clouds from a Light Detection and Ranging (LiDAR) sensor are fused with images captured by a front-facing camera. Semantic information is extracted from images with a deep neural network. Experiments are performed in varied environments, under diverse conditions of illumination and traffic. Results show that occupancy grid maps lead to more accurate localization, followed by reflectivity grid maps. In most scenarios, the localization with semantic grid maps kept the position tracking without catastrophic losses, but with errors from 2 to 3 times bigger than the previous. Colour grid maps led to inaccurate and unstable localization even using a robust metric, the entropy correlation coefficient, for comparing online data and the map.
Deep Traffic Sign Detection and Recognition Without Target Domain Real Images
Jul 30, 2020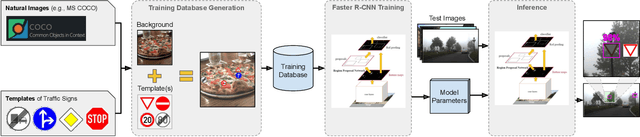
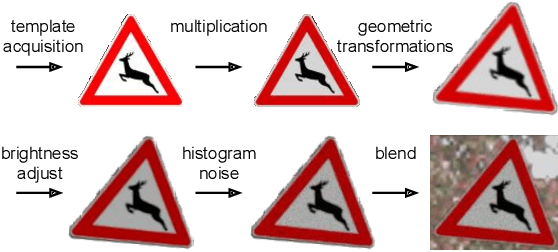


Deep learning has been successfully applied to several problems related to autonomous driving, often relying on large databases of real target-domain images for proper training. The acquisition of such real-world data is not always possible in the self-driving context, and sometimes their annotation is not feasible. Moreover, in many tasks, there is an intrinsic data imbalance that most learning-based methods struggle to cope with. Particularly, traffic sign detection is a challenging problem in which these three issues are seen altogether. To address these challenges, we propose a novel database generation method that requires only (i) arbitrary natural images, i.e., requires no real image from the target-domain, and (ii) templates of the traffic signs. The method does not aim at overcoming the training with real data, but to be a compatible alternative when the real data is not available. The effortlessly generated database is shown to be effective for the training of a deep detector on traffic signs from multiple countries. On large data sets, training with a fully synthetic data set almost matches the performance of training with a real one. When compared to training with a smaller data set of real images, training with synthetic images increased the accuracy by 12.25%. The proposed method also improves the performance of the detector when target-domain data are available.
Self-supervised Deep Reconstruction of Mixed Strip-shredded Text Documents
Jul 01, 2020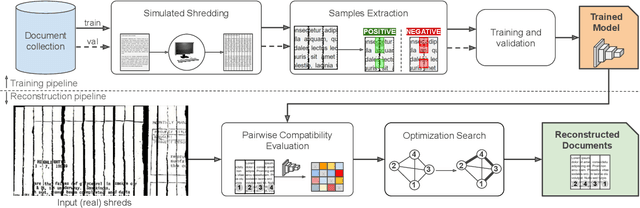

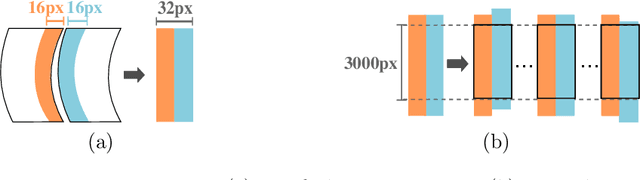
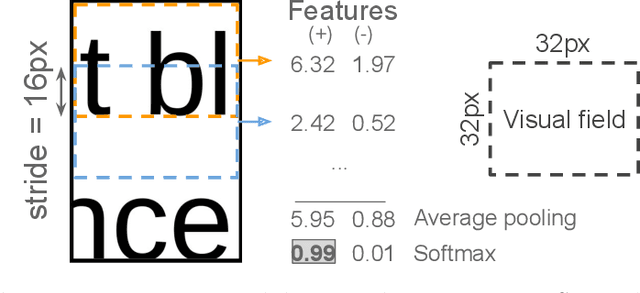
The reconstruction of shredded documents consists of coherently arranging fragments of paper (shreds) to recover the original document(s). A great challenge in computational reconstruction is to properly evaluate the compatibility between the shreds. While traditional pixel-based approaches are not robust to real shredding, more sophisticated solutions compromise significantly time performance. The solution presented in this work extends our previous deep learning method for single-page reconstruction to a more realistic/complex scenario: the reconstruction of several mixed shredded documents at once. In our approach, the compatibility evaluation is modeled as a two-class (valid or invalid) pattern recognition problem. The model is trained in a self-supervised manner on samples extracted from simulated-shredded documents, which obviates manual annotation. Experimental results on three datasets -- including a new collection of 100 strip-shredded documents produced for this work -- have shown that the proposed method outperforms the competing ones on complex scenarios, achieving accuracy superior to 90%.