 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereoNavNet: Learning to Navigate using Stereo Cameras with Auxiliary Occupancy Voxels
Mar 18, 2024Visual navigation has received significant attention recently. Most of the prior works focus on predicting navigation actions based on semantic features extracted from visual encoders. However, these approaches often rely on large datasets and exhibit limited generalizability. In contrast, our approach draws inspiration from traditional navigation planners that operate on geometric representations, such as occupancy maps. We propose StereoNavNet (SNN), a novel visual navigation approach employing a modular learning framework comprising perception and policy modules. Within the perception module, we estimate an auxiliary 3D voxel occupancy grid from stereo RGB images and extract geometric features from it. These features, along with user-defined goals, are utilized by the policy module to predict navigation actions. Through extensive empirical evaluation, we demonstrate that SNN outperforms baseline approaches in terms of success rates, success weighted by path length, and navigation error. Furthermore, SNN exhibits better generalizability, characterized by maintaining leading performance when navigating across previously unseen environments.
Design and Realization of a Benchmarking Testbed for Evaluating Autonomous Platooning Algorithms
Feb 14, 2024Autonomous vehicle platoons present near- and long-term opportunities to enhance operational efficiencies and save lives. The past 30 years have seen rapid development in the autonomous driving space, enabling new technologies that will alleviate the strain placed on human drivers and reduce vehicle emissions. This paper introduces a testbed for evaluating and benchmarking platooning algorithms on 1/10th scale vehicles with onboard sensors. To demonstrate the testbed's utility, we evaluate three algorithms, linear feedback and two variations of distributed model predictive control, and compare their results on a typical platooning scenario where the lead vehicle tracks a reference trajectory that changes speed multiple times. We validate our algorithms in simulation to analyze the performance as the platoon size increases, and find that the distributed model predictive control algorithms outperform linear feedback on hardware and in simulation.
Analysis and Perspectives on the ANA Avatar XPRIZE Competition
Jan 10, 2024



The ANA Avatar XPRIZE was a four-year competition to develop a robotic "avatar" system to allow a human operator to sense, communicate, and act in a remote environment as though physically present. The competition featured a unique requirement that judges would operate the avatars after less than one hour of training on the human-machine interfaces, and avatar systems were judged on both objective and subjective scoring metrics. This paper presents a unified summary and analysis of the competition from technical, judging, and organizational perspectives. We study the use of telerobotics technologies and innovations pursued by the competing teams in their avatar systems, and correlate the use of these technologies with judges' task performance and subjective survey ratings. It also summarizes perspectives from team leads, judges, and organizers about the competition's execution and impact to inform the future development of telerobotics and telepresence.
Shared Affordance-awareness via Augmented Reality for Proactive Assistance in Human-robot Collaboration
Dec 20, 2023Enabling humans and robots to collaborate effectively requires purposeful communication and an understanding of each other's affordances. Prior work in human-robot collaboration has incorporated knowledge of human affordances, i.e., their action possibilities in the current context, into autonomous robot decision-making. This "affordance awareness" is especially promising for service robots that need to know when and how to assist a person that cannot independently complete a task. However, robots still fall short in performing many common tasks autonomously. In this work-in-progress paper, we propose an augmented reality (AR) framework that bridges the gap in an assistive robot's capabilities by actively engaging with a human through a shared affordance-awareness representation. Leveraging the different perspectives from a human wearing an AR headset and a robot's equipped sensors, we can build a perceptual representation of the shared environment and model regions of respective agent affordances. The AR interface can also allow both agents to communicate affordances with one another, as well as prompt for assistance when attempting to perform an action outside their affordance region. This paper presents the main components of the proposed framework and discusses its potential through a domestic cleaning task experiment.
E(2)-Equivariant Graph Planning for Navigation
Sep 22, 2023



Learning for robot navigation presents a critical and challenging task. The scarcity and costliness of real-world datasets necessitate efficient learning approaches. In this letter, we exploit Euclidean symmetry in planning for 2D navigation, which originates from Euclidean transformations between reference frames and enables parameter sharing. To address the challenges of unstructured environments, we formulate the navigation problem as planning on a geometric graph and develop an equivariant message passing network to perform value iteration. Furthermore, to handle multi-camera input, we propose a learnable equivariant layer to lift features to a desired space. We conduct comprehensive evaluations across five diverse tasks encompassing structured and unstructured environments, along with maps of known and unknown, given point goals or semantic goals. Our experiments confirm the substantial benefits on training efficiency, stability, and generalization.
Mobile MoCap: Retroreflector Localization On-The-Go
Mar 23, 2023



Motion capture (MoCap) through tracking retroreflectors obtains high precision pose estimation, which is frequently used in robotics. Unlike MoCap, fiducial marker-based tracking methods do not require a static camera setup to perform relative localization. Popular pose-estimating systems based on fiducial markers have lower localization accuracy than MoCap. As a solution, we propose Mobile MoCap, a system that employs inexpensive near-infrared cameras for precise relative localization in dynamic environments. We present a retroreflector feature detector that performs 6-DoF (six degrees-of-freedom) tracking and operates with minimal camera exposure times to reduce motion blur. To evaluate different localization techniques in a mobile robot setup, we mount our Mobile MoCap system, as well as a standard RGB camera, onto a precision-controlled linear rail for the purposes of retroreflective and fiducial marker tracking, respectively. We benchmark the two systems against each other, varying distance, marker viewing angle, and relative velocities. Our stereo-based Mobile MoCap approach obtains higher position and orientation accuracy than the fiducial approach. The code for Mobile MoCap is implemented in ROS 2 and made publicly available at https://github.com/RIVeR-Lab/mobile_mocap.
Contact-Implicit Planning and Control for Non-Prehensile Manipulation Using State-Triggered Constraints
Oct 18, 2022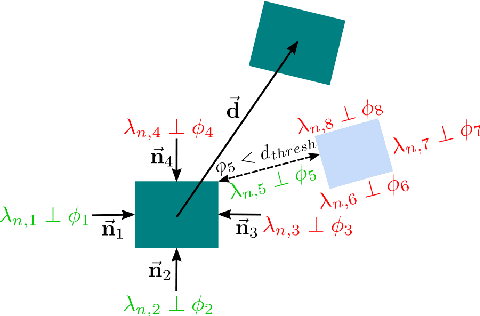
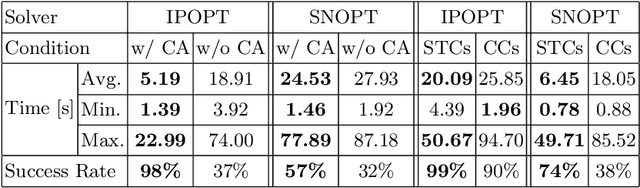
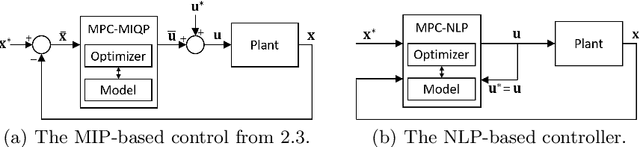
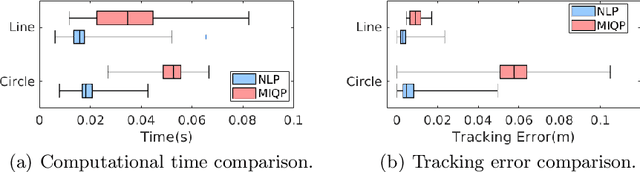
We present a contact-implicit planning approach that can generate contact-interaction trajectories for non-prehensile manipulation problems without tuning or a tailored initial guess and with high success rates. This is achieved by leveraging the concept of state-triggered constraints (STCs) to capture the hybrid dynamics induced by discrete contact modes without explicitly reasoning about the combinatorics. STCs enable triggering arbitrary constraints by a strict inequality condition in a continuous way. We first use STCs to develop an automatic contact constraint activation method to minimize the effective constraint space based on the utility of contact candidates for a given task. Then, we introduce a re-formulation of the Coulomb friction model based on STCs that is more efficient for the discovery of tangential forces than the well-studied complementarity constraints-based approach. Last, we include the proposed friction model in the planning and control of quasi-static planar pushing. The performance of the STC-based contact activation and friction methods is evaluated by extensive simulation experiments in a dynamic pushing scenario. The results demonstrate that our methods outperform the baselines based on complementarity constraints with a significant decrease in the planning time and a higher success rate. We then compare the proposed quasi-static pushing controller against a mixed-integer programming-based approach in simulation and find that our method is computationally more efficient and provides a better tracking accuracy, with the added benefit of not requiring an initial control trajectory. Finally, we present hardware experiments demonstrating the usability of our framework in executing complex trajectories in real-time even with a low-accuracy tracking system.
StereoVoxelNet: Real-Time Obstacle Detection Based on Occupancy Voxels from a Stereo Camera Using Deep Neural Networks
Sep 18, 2022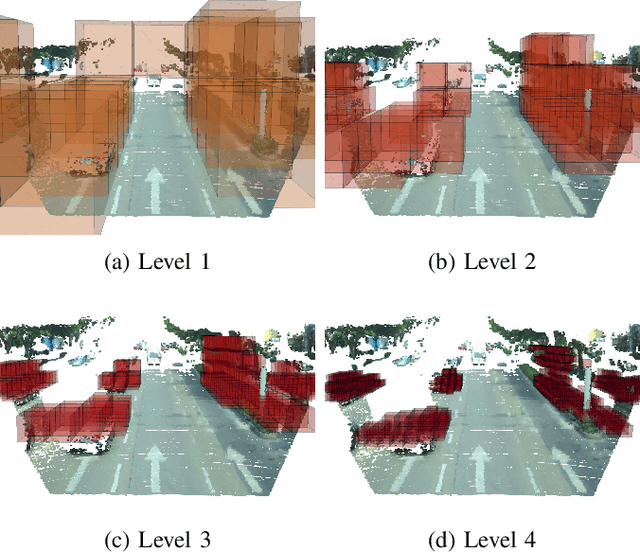

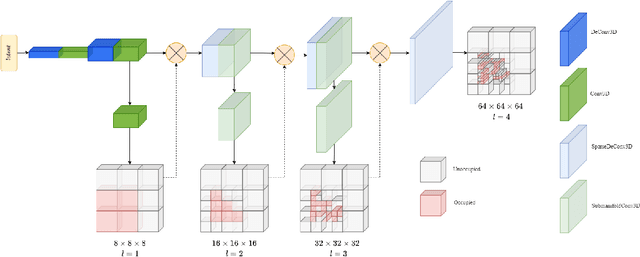

Obstacle detection is a safety-critical problem in robot navigation, where stereo matching is a popular vision-based approach. While deep neural networks have shown impressive results in computer vision, most of the previous obstacle detection works only leverage traditional stereo matching techniques to meet the computational constraints for real-time feedback. This paper proposes a computationally efficient method that leverages a deep neural network to detect occupancy from stereo images directly. Instead of learning the point cloud correspondence from the stereo data, our approach extracts the compact obstacle distribution based on volumetric representations. In addition, we prune the computation of safety irrelevant spaces in a coarse-to-fine manner based on octrees generated by the decoder. As a result, we achieve real-time performance on the onboard computer (NVIDIA Jetson TX2). Our approach detects obstacles accurately in the range of 32 meters and achieves better IoU (Intersection over Union) and CD (Chamfer Distance) scores with only 2% of the computation cost of the state-of-the-art stereo model. Furthermore, we validate our method's robustness and real-world feasibility through autonomous navigation experiments with a real robot. Hence, our work contributes toward closing the gap between the stereo-based system in robot perception and state-of-the-art stereo models in computer vision. To counter the scarcity of high-quality real-world indoor stereo datasets, we collect a 1.36 hours stereo dataset with a Jackal robot which is used to fine-tune our model. The dataset, the code, and more visualizations are available at https://lhy.xyz/stereovoxelnet/
Pregrasp Object Material Classification by a Novel Gripper Design with Integrated Spectroscopy
Jul 03, 2022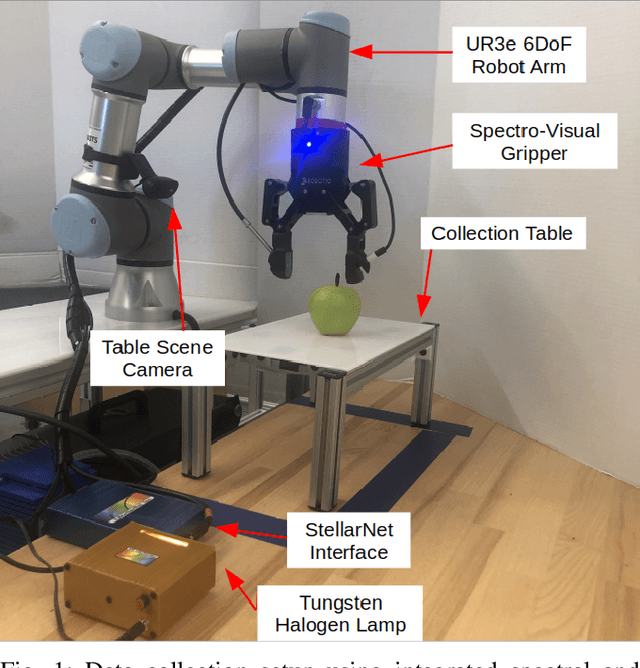
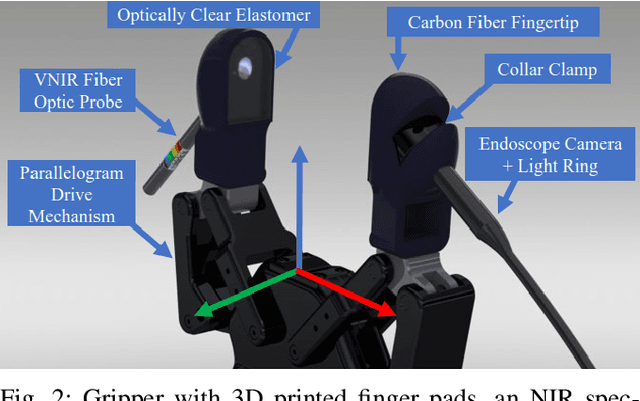
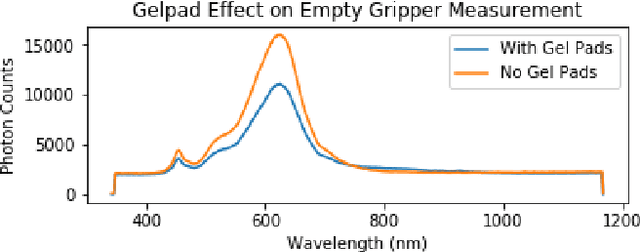

Robots benefit from being able to classify objects they interact with or manipulate based on their material properties. This capability ensures fine manipulation of complex objects through proper grasp pose and force selection. Prior work has focused on haptic or visual processing to determine material type at grasp time. In this work, we introduce a novel parallel robot gripper design and a method for collecting spectral readings and visual images from within the gripper finger. We train a nonlinear Support Vector Machine (SVM) that can classify the material of the object about to be grasped through recursive estimation, with increasing confidence as the distance from the finger tips to the object decreases. In order to validate the hardware design and classification method, we collect samples from 16 real and fake fruit varieties (composed of polystyrene/plastic) resulting in a dataset containing spectral curves, scene images, and high-resolution texture images as the objects are grasped, lifted, and released. Our modeling method demonstrates an accuracy of 96.4% in classifying objects in a 32 class decision problem. This represents a performance improvement by 29.4% over the state of the art computer vision algorithms at distinguishing between visually similar materials. In contrast to prior work, our recursive estimation model accounts for increasing spectral signal strength and allows for decisions to be made as the gripper approaches an object. We conclude that spectroscopy is a promising sensing modality for enabling robots to not only classify grasped objects but also understand their underlying material composition.
Tactile Pose Estimation and Policy Learning for Unknown Object Manipulation
Mar 21, 2022
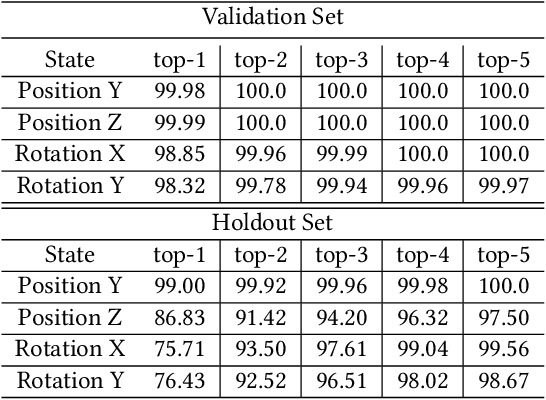
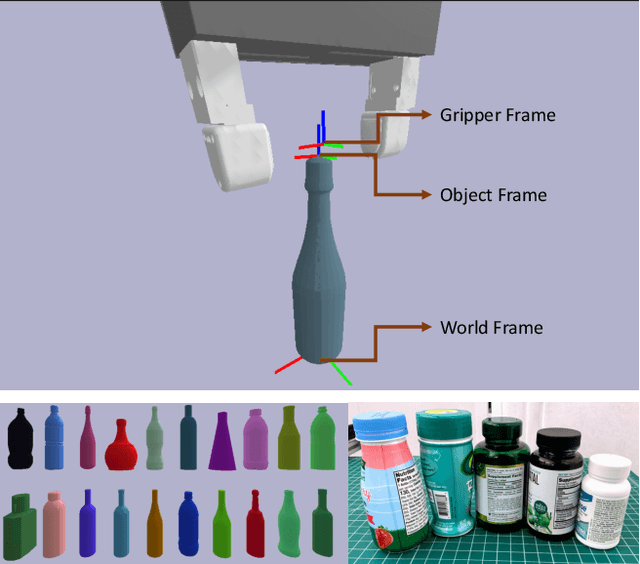

Object pose estimation methods allow finding locations of objects in unstructured environments. This is a highly desired skill for autonomous robot manipulation as robots need to estimate the precise poses of the objects in order to manipulate them. In this paper, we investigate the problems of tactile pose estimation and manipulation for category-level objects. Our proposed method uses a Bayes filter with a learned tactile observation model and a deterministic motion model. Later, we train policies using deep reinforcement learning where the agents use the belief estimation from the Bayes filter. Our models are trained in simulation and transferred to the real world. We analyze the reliability and the performance of our framework through a series of simulated and real-world experiments and compare our method to the baseline work. Our results show that the learned tactile observation model can localize the pose of novel objects at 2-mm and 1-degree resolution for position and orientation, respectively. Furthermore, we experiment on a bottle opening task where the gripper needs to reach the desired grasp state.