 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2D Floor Plan Segmentation Based on Down-sampling
Mar 24, 2023



In recent years, floor plan segmentation has gained significant attention due to its wide range of applications in floor plan reconstruction and robotics. In this paper, we propose a novel 2D floor plan segmentation technique based on a down-sampling approach. Our method employs continuous down-sampling on a floor plan to maintain its structural information while reducing its complexity. We demonstrate the effectiveness of our approach by presenting results obtained from both cluttered floor plans generated by a vacuum cleaning robot in unknown environments and a benchmark of floor plans. Our technique considerably reduces the computational and implementation complexity of floor plan segmentation, making it more suitable for real-world applications. Additionally, we discuss the appropriate metric for evaluating segmentation results. Overall, our approach yields promising results for 2D floor plan segmentation in cluttered environments.
End-to-end grasping policies for human-in-the-loop robots via deep reinforcement learning
Apr 26, 2021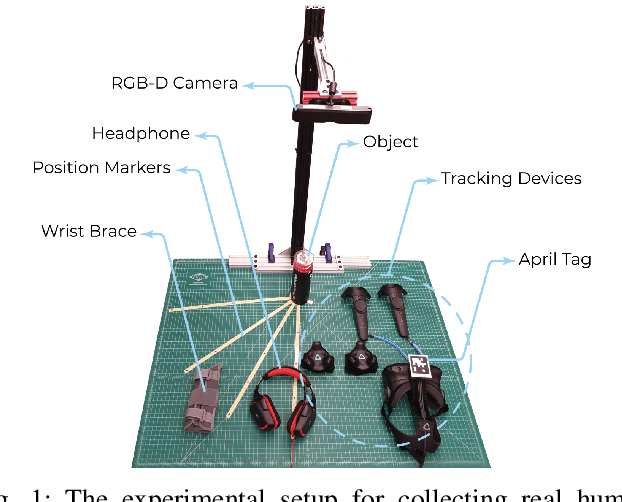

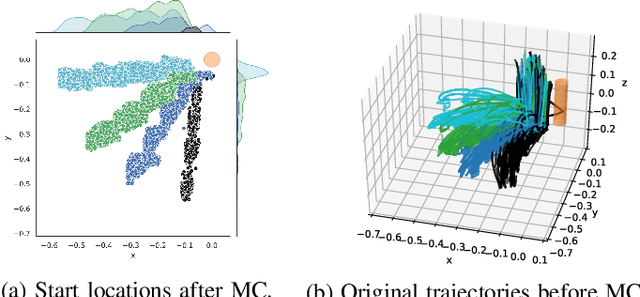
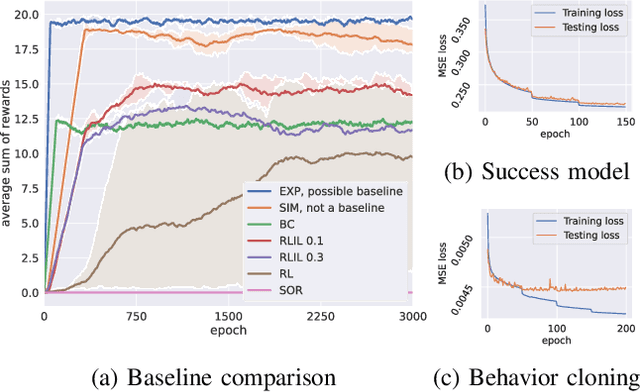
State-of-the-art human-in-the-loop robot grasping is hugely suffered by Electromyography (EMG) inference robustness issues. As a workaround, researchers have been looking into integrating EMG with other signals, often in an ad hoc manner. In this paper, we are presenting a method for end-to-end training of a policy for human-in-the-loop robot grasping on real reaching trajectories. For this purpose we use Reinforcement Learning (RL) and Imitation Learning (IL) in DEXTRON (DEXTerity enviRONment), a stochastic simulation environment with real human trajectories that are augmented and selected using a Monte Carlo (MC) simulation method. We also offer a success model which once trained on the expert policy data and the RL policy roll-out transitions, can provide transparency to how the deep policy works and when it is probably going to fail.
Multimodal Fusion of EMG and Vision for Human Grasp Intent Inference in Prosthetic Hand Control
Apr 08, 2021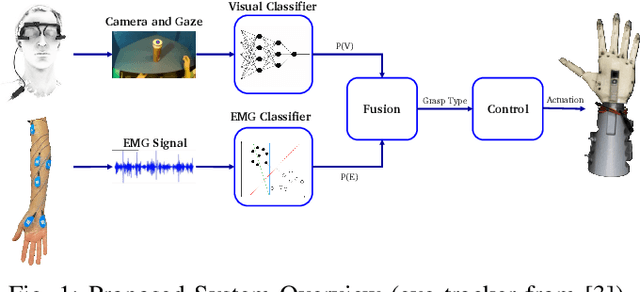
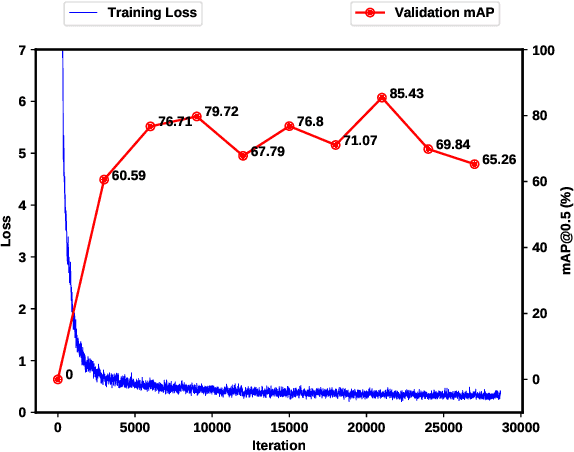
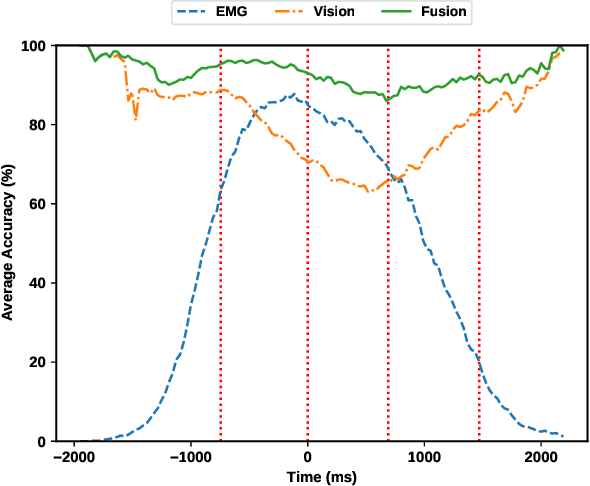
For lower arm amputees, robotic prosthetic hands offer the promise to regain the capability to perform fine object manipulation in activities of daily living. Current control methods based on physiological signals such as EEG and EMG are prone to poor inference outcomes due to motion artifacts, variability of skin electrode junction impedance over time, muscle fatigue, and other factors. Visual evidence is also susceptible to its own artifacts, most often due to object occlusion, lighting changes, variable shapes of objects depending on view-angle, among other factors. Multimodal evidence fusion using physiological and vision sensor measurements is a natural approach due to the complementary strengths of these modalities. In this paper, we present a Bayesian evidence fusion framework for grasp intent inference using eye-view video, gaze, and EMG from the forearm processed by neural network models. We analyze individual and fused performance as a function of time as the hand approaches the object to grasp it. For this purpose, we have also developed novel data processing and augmentation techniques to train neural network components. Our experimental data analyses demonstrate that EMG and visual evidence show complementary strengths, and as a consequence, fusion of multimodal evidence can outperform each individual evidence modality at any given time. Specifically, results indicate that, on average, fusion improves the instantaneous upcoming grasp type classification accuracy while in the reaching phase by 13.66% and 14.8%, relative to EMG and visual evidence individually. An overall fusion accuracy of 95.3% among 13 labels (compared to a chance level of 7.7%) is achieved, and more detailed analysis indicate that the correct grasp is inferred sufficiently early and with high confidence compared to the top contender, in order to allow successful robot actuation to close the loop.