 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning across Meta-Tasks for Few-Shot Learning
Mar 09, 2020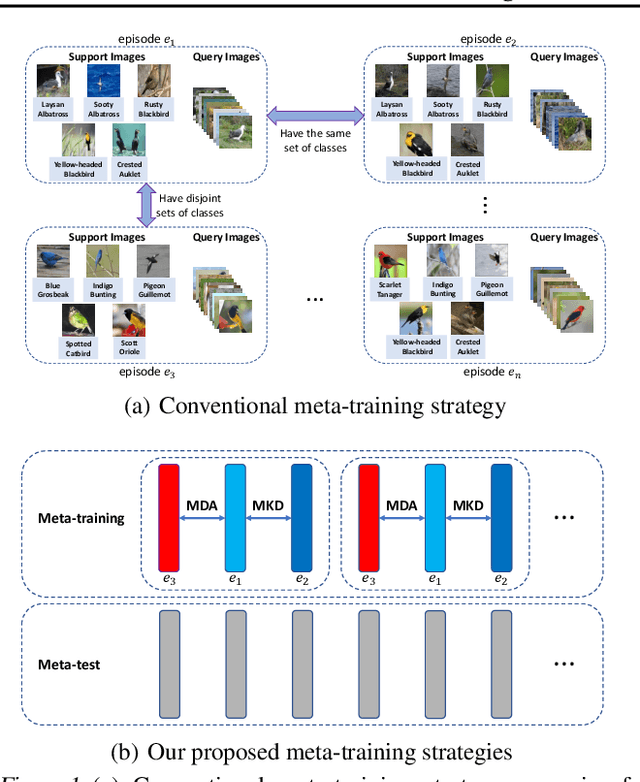
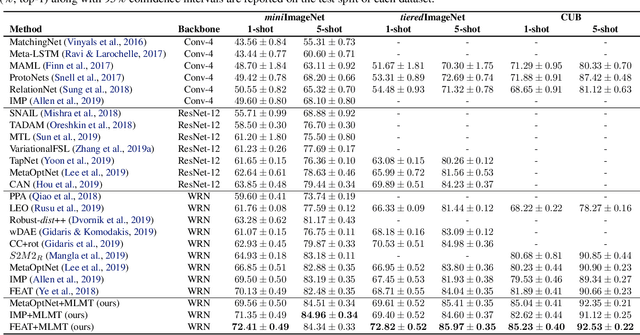
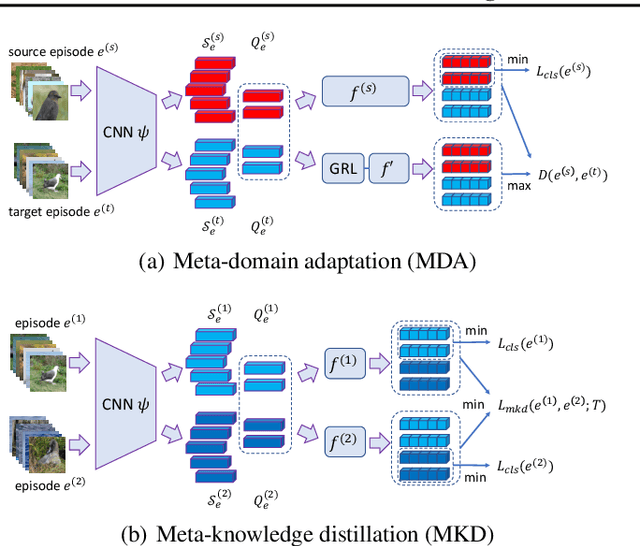
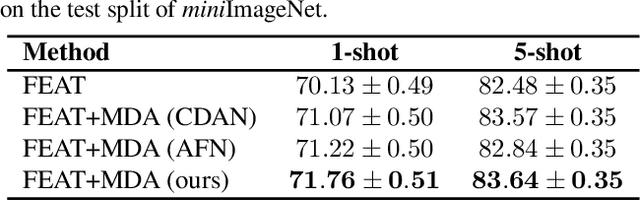
Existing meta-learning based few-shot learning (FSL) methods typically adopt an episodic training strategy whereby each episode contains a meta-task. Across episodes, these tasks are sampled randomly and their relationships are ignored. In this paper, we argue that the inter-meta-task relationships should be exploited and those tasks are sampled strategically to assist in meta-learning. Specifically, we consider the relationships defined over two types of meta-task pairs and propose different strategies to exploit them. (1) Two meta-tasks with disjoint sets of classes: this pair is interesting because it is reminiscent of the relationship between the source seen classes and target unseen classes, featured with domain gap caused by class differences. A novel learning objective termed meta-domain adaptation (MDA) is proposed to make the meta-learned model more robust to the domain gap. (2) Two meta-tasks with identical sets of classes: this pair is useful because it can be employed to learn models that are robust against poorly sampled few-shots. To that end, a novel meta-knowledge distillation (MKD) objective is formulated. Extensive experiments demonstrate that both MDA and MKD significantly boost the performance of a variety of FSL methods, resulting in new state-of-the-art on three benchmarks.
AdarGCN: Adaptive Aggregation GCN for Few-Shot Learning
Mar 09, 2020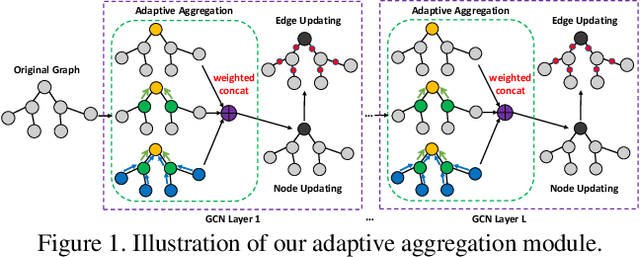
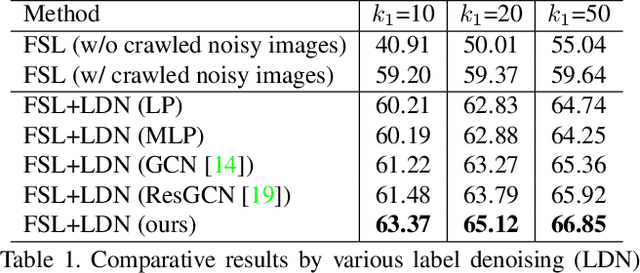
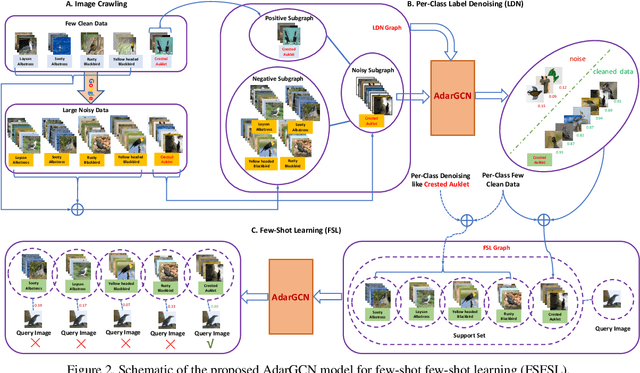
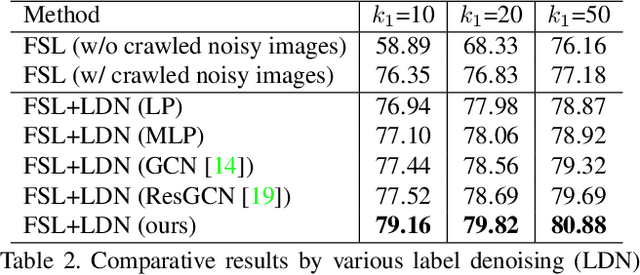
Existing few-shot learning (FSL) methods assume that there exist sufficient training samples from source classes for knowledge transfer to target classes with few training samples. However, this assumption is often invalid, especially when it comes to fine-grained recognition. In this work, we define a new FSL setting termed few-shot fewshot learning (FSFSL), under which both the source and target classes have limited training samples. To overcome the source class data scarcity problem, a natural option is to crawl images from the web with class names as search keywords. However, the crawled images are inevitably corrupted by large amount of noise (irrelevant images) and thus may harm the performance. To address this problem, we propose a graph convolutional network (GCN)-based label denoising (LDN) method to remove the irrelevant images. Further, with the cleaned web images as well as the original clean training images, we propose a GCN-based FSL method. For both the LDN and FSL tasks, a novel adaptive aggregation GCN (AdarGCN) model is proposed, which differs from existing GCN models in that adaptive aggregation is performed based on a multi-head multi-level aggregation module. With AdarGCN, how much and how far information carried by each graph node is propagated in the graph structure can be determined automatically, therefore alleviating the effects of both noisy and outlying training samples. Extensive experiments show the superior performance of our AdarGCN under both the new FSFSL and the conventional FSL settings.
Sketch Less for More: On-the-Fly Fine-Grained Sketch Based Image Retrieval
Mar 05, 2020
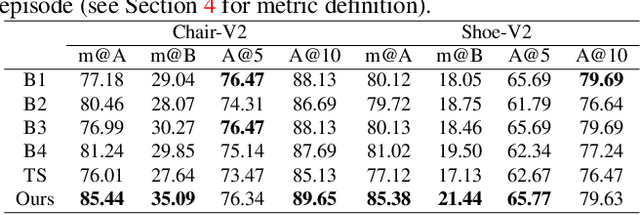
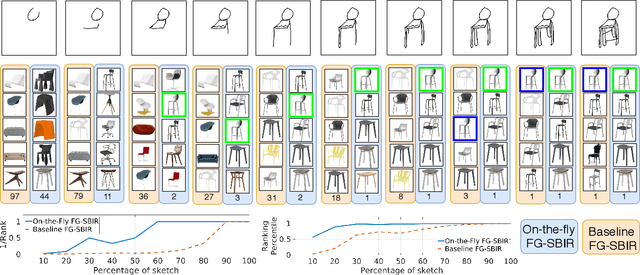
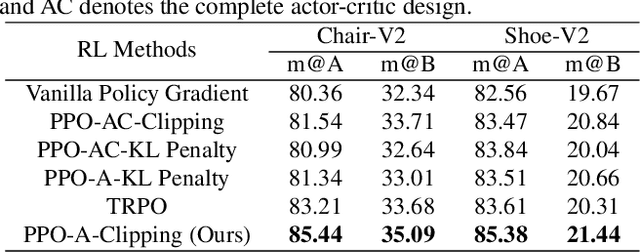
Fine-grained sketch-based image retrieval (FG-SBIR) addresses the problem of retrieving a particular photo instance given a user's query sketch. Its widespread applicability is however hindered by the fact that drawing a sketch takes time, and most people struggle to draw a complete and faithful sketch. In this paper, we reformulate the conventional FG-SBIR framework to tackle these challenges, with the ultimate goal of retrieving the target photo with the least number of strokes possible. We further propose an on-the-fly design that starts retrieving as soon as the user starts drawing. To accomplish this, we devise a reinforcement learning-based cross-modal retrieval framework that directly optimizes rank of the ground-truth photo over a complete sketch drawing episode. Additionally, we introduce a novel reward scheme that circumvents the problems related to irrelevant sketch strokes, and thus provides us with a more consistent rank list during the retrieval. We achieve superior early-retrieval efficiency over state-of-the-art methods and alternative baselines on two publicly available fine-grained sketch retrieval datasets.
Fine-Grained Instance-Level Sketch-Based Video Retrieval
Feb 21, 2020
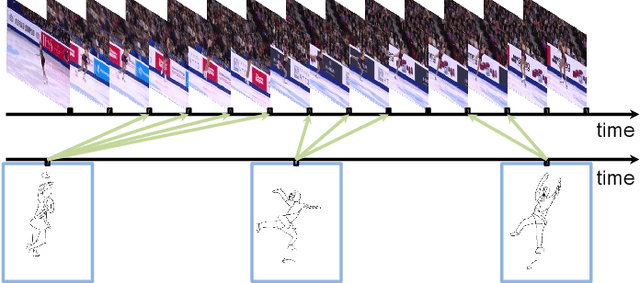

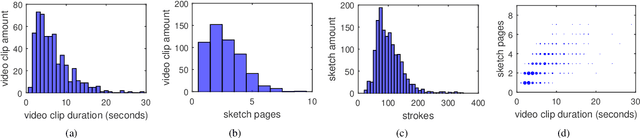
Existing sketch-analysis work studies sketches depicting static objects or scenes. In this work, we propose a novel cross-modal retrieval problem of fine-grained instance-level sketch-based video retrieval (FG-SBVR), where a sketch sequence is used as a query to retrieve a specific target video instance. Compared with sketch-based still image retrieval, and coarse-grained category-level video retrieval, this is more challenging as both visual appearance and motion need to be simultaneously matched at a fine-grained level. We contribute the first FG-SBVR dataset with rich annotations. We then introduce a novel multi-stream multi-modality deep network to perform FG-SBVR under both strong and weakly supervised settings. The key component of the network is a relation module, designed to prevent model over-fitting given scarce training data. We show that this model significantly outperforms a number of existing state-of-the-art models designed for video analysis.
Towards Byzantine-resilient Learning in Decentralized Systems
Feb 20, 2020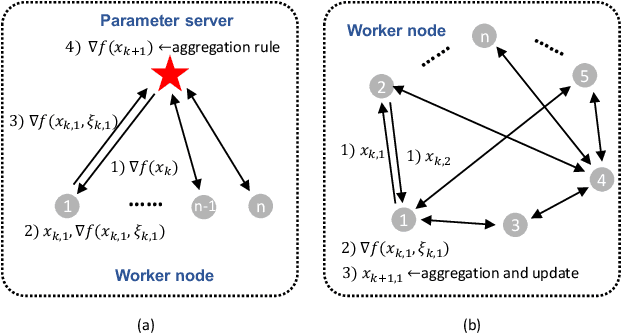

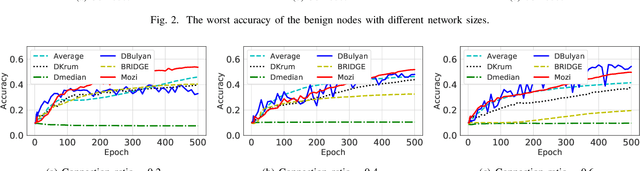
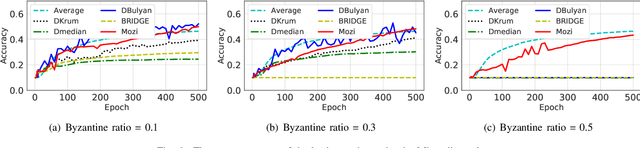
With the proliferation of IoT and edge computing, decentralized learning is becoming more promising. When designing a distributed learning system, one major challenge to consider is Byzantine Fault Tolerance (BFT). Past works have researched Byzantine-resilient solutions for centralized distributed learning. However, there are currently no satisfactory solutions with strong efficiency and security in decentralized systems. In this paper, we propose a novel algorithm, Mozi, to achieve BFT in decentralized learning systems. Specifically, Mozi provides a uniform Byzantine-resilient aggregation rule for benign nodes to select the useful parameter updates and filter out the malicious ones in each training iteration. It guarantees that each benign node in a decentralized system can train a correct model under very strong Byzantine attacks with an arbitrary number of faulty nodes. We perform the theoretical analysis to prove the uniform convergence of our proposed algorithm. Experimental evaluations demonstrate the high security and efficiency of Mozi compared to all existing solutions.
Few-Shot Learning as Domain Adaptation: Algorithm and Analysis
Feb 12, 2020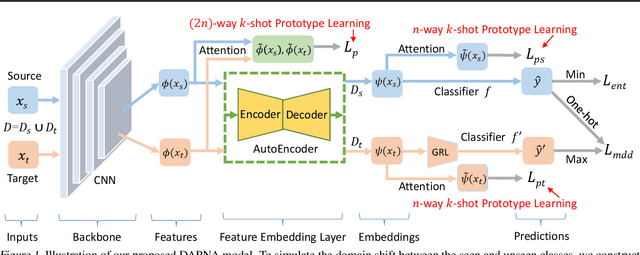
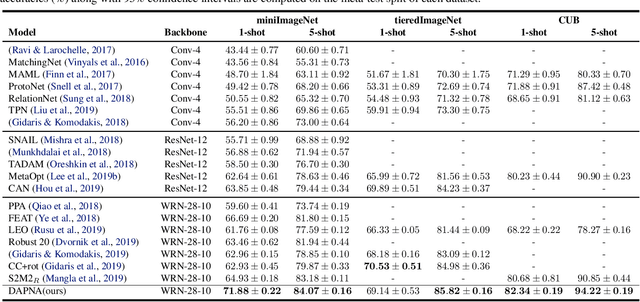
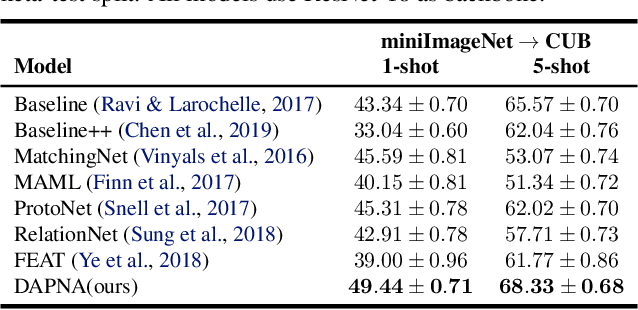
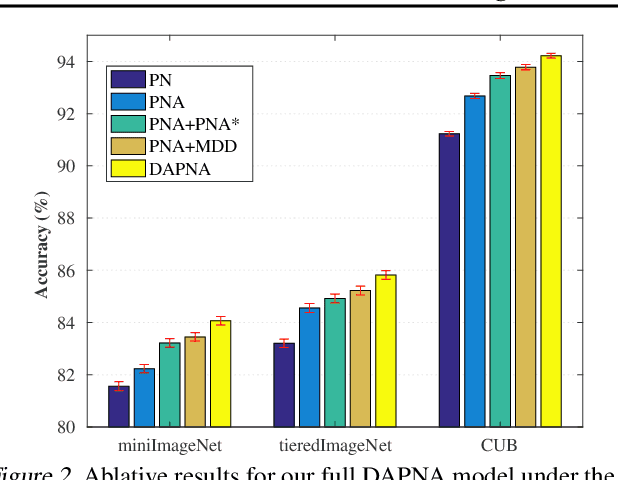
To recognize the unseen classes with only few samples, few-shot learning (FSL) uses prior knowledge learned from the seen classes. A major challenge for FSL is that the distribution of the unseen classes is different from that of those seen, resulting in poor generalization even when a model is meta-trained on the seen classes. This class-difference-caused distribution shift can be considered as a special case of domain shift. In this paper, for the first time, we propose a domain adaptation prototypical network with attention (DAPNA) to explicitly tackle such a domain shift problem in a meta-learning framework. Specifically, armed with a set transformer based attention module, we construct each episode with two sub-episodes without class overlap on the seen classes to simulate the domain shift between the seen and unseen classes. To align the feature distributions of the two sub-episodes with limited training samples, a feature transfer network is employed together with a margin disparity discrepancy (MDD) loss. Importantly, theoretical analysis is provided to give the learning bound of our DAPNA. Extensive experiments show that our DAPNA outperforms the state-of-the-art FSL alternatives, often by significant margins.
Deep Learning for Person Re-identification: A Survey and Outlook
Jan 13, 2020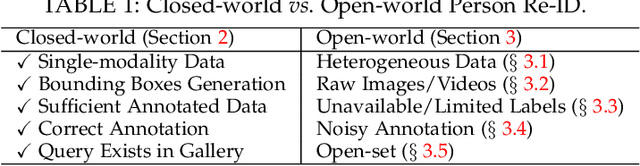

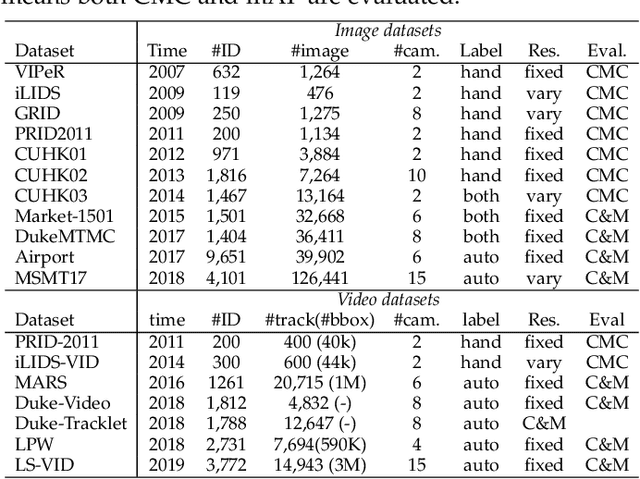
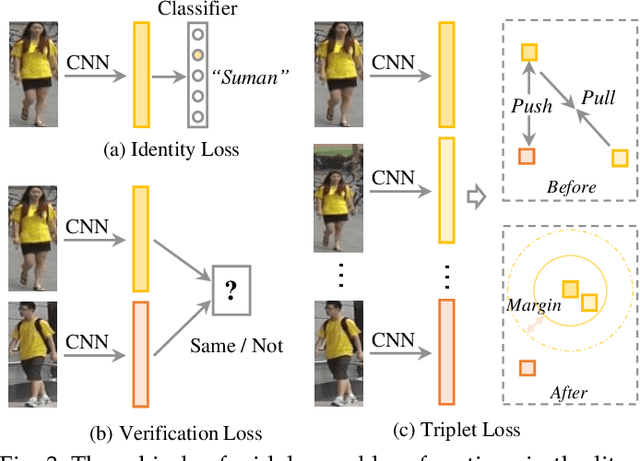
Person re-identification (Re-ID) aims at retrieving a person of interest across multiple non-overlapping cameras. With the advancement of deep neural networks and increasing demand of intelligent video surveillance, it has gained significantly increased interest in the computer vision community. By dissecting the involved components in developing a person Re-ID system, we categorize it into the closed-world and open-world settings. The widely studied closed-world setting is usually applied under various research-oriented assumptions, and has achieved inspiring success using deep learning techniques on a number of datasets. We first conduct a comprehensive overview with in-depth analysis for closed-world person Re-ID from three different perspectives, including deep feature representation learning, deep metric learning and ranking optimization. With the performance saturation under closed-world setting, the research focus for person Re-ID has recently shifted to the open-world setting, facing more challenging issues. This setting is closer to practical applications under specific scenarios. We summarize the open-world Re-ID in terms of five different aspects. By analyzing the advantages of existing methods, we design a powerful AGW baseline, achieving state-of-the-art or at least comparable performance on both single- and cross-modality Re-ID tasks. Meanwhile, we introduce a new evaluation metric (mINP) for person Re-ID, indicating the cost for finding all the correct matches, which provides an additional criteria to evaluate the Re-ID system for real applications. Finally, some important yet under-investigated open issues are discussed.
Torchreid: A Library for Deep Learning Person Re-Identification in Pytorch
Oct 22, 2019


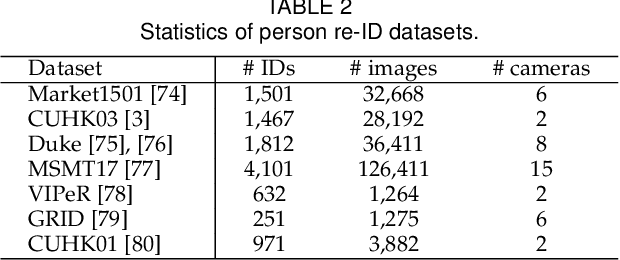
Person re-identification (re-ID), which aims to re-identify people across different camera views, has been significantly advanced by deep learning in recent years, particularly with convolutional neural networks (CNNs). In this paper, we present Torchreid, a software library built on PyTorch that allows fast development and end-to-end training and evaluation of deep re-ID models. As a general-purpose framework for person re-ID research, Torchreid provides (1) unified data loaders that support 15 commonly used re-ID benchmark datasets covering both image and video domains, (2) streamlined pipelines for quick development and benchmarking of deep re-ID models, and (3) implementations of the latest re-ID CNN architectures along with their pre-trained models to facilitate reproducibility as well as future research. With a high-level modularity in its design, Torchreid offers a great flexibility to allow easy extension to new datasets, CNN models and loss functions.
Learning Generalisable Omni-Scale Representations for Person Re-Identification
Oct 22, 2019
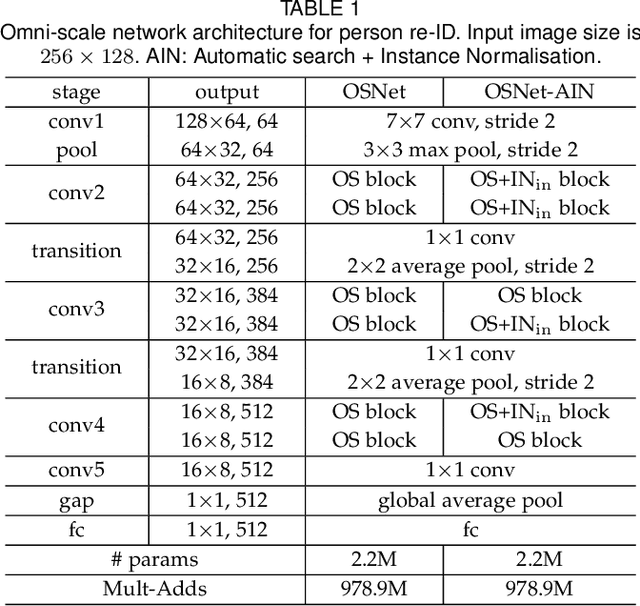
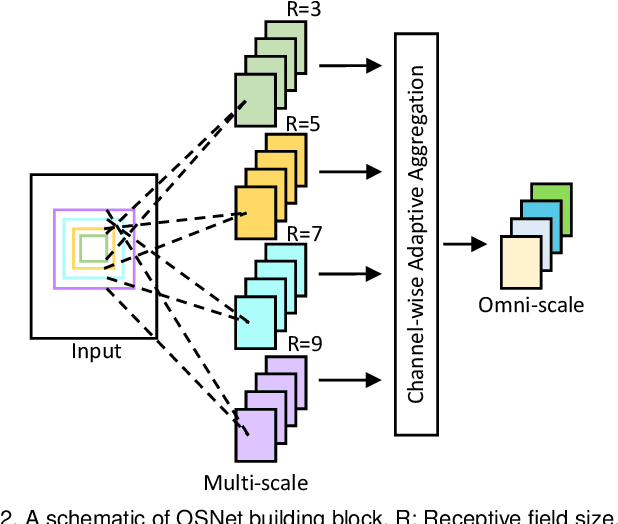
An effective person re-identification (re-ID) model should learn feature representations that are both discriminative, for distinguishing similar-looking people, and generalisable, for deployment across datasets without any adaptation. In this paper, we develop novel CNN architectures to address both challenges. First, we present a re-ID CNN termed omni-scale network (OSNet) to learn features that not only capture different spatial scales but also encapsulate a synergistic combination of multiple scales, namely omni-scale features. The basic building block consists of multiple convolutional streams, each detecting features at a certain scale. For omni-scale feature learning, a unified aggregation gate is introduced to dynamically fuse multi-scale features with channel-wise weights. OSNet is lightweight as its building blocks comprise factorised convolutions. Second, to improve generalisable feature learning, we introduce instance normalisation (IN) layers into OSNet to cope with cross-dataset discrepancies. Further, to determine the optimal placements of these IN layers in the architecture, we formulate an efficient differentiable architecture search algorithm. Extensive experiments show that, in the conventional same-dataset setting, OSNet achieves state-of-the-art performance, despite being much smaller than existing re-ID models. In the more challenging yet practical cross-dataset setting, OSNet beats most recent unsupervised domain adaptation methods without requiring any target data for model adaptation. Our code and models are released at \texttt{https://github.com/KaiyangZhou/deep-person-reid}.
Few-Shot Learning with Global Class Representations
Aug 14, 2019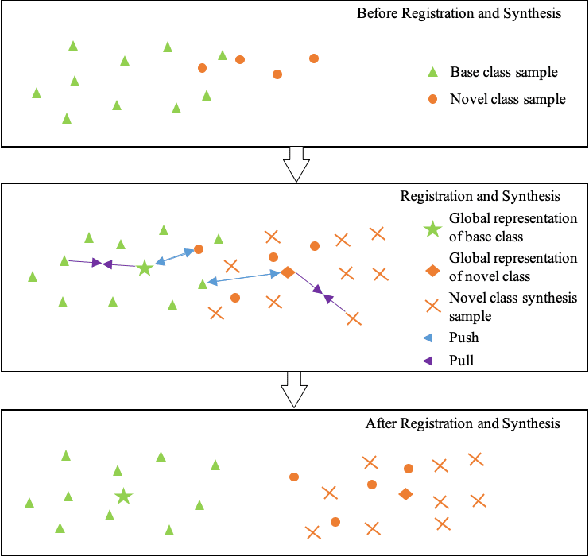
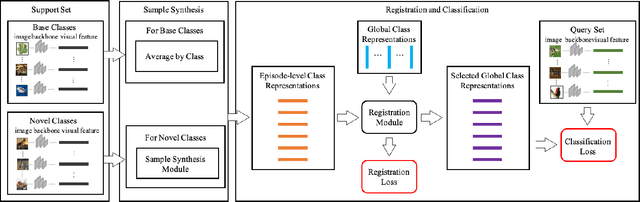
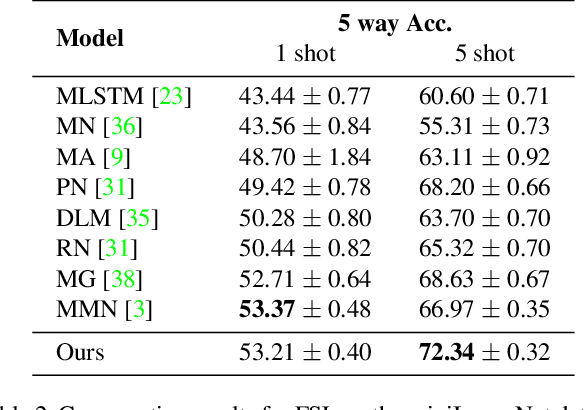
In this paper, we propose to tackle the challenging few-shot learning (FSL) problem by learning global class representations using both base and novel class training samples. In each training episode, an episodic class mean computed from a support set is registered with the global representation via a registration module. This produces a registered global class representation for computing the classification loss using a query set. Though following a similar episodic training pipeline as existing meta learning based approaches, our method differs significantly in that novel class training samples are involved in the training from the beginning. To compensate for the lack of novel class training samples, an effective sample synthesis strategy is developed to avoid overfitting. Importantly, by joint base-novel class training, our approach can be easily extended to a more practical yet challenging FSL setting, i.e., generalized FSL, where the label space of test data is extended to both base and novel classes. Extensive experiments show that our approach is effective for both of the two FSL settings.