 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal Contrastive Distillation for Instructional Activity Anticipation
Jan 18, 2022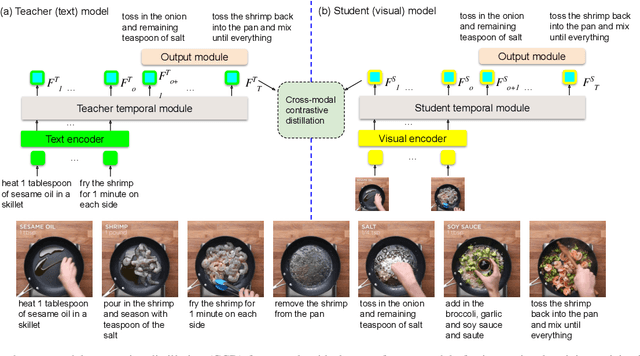
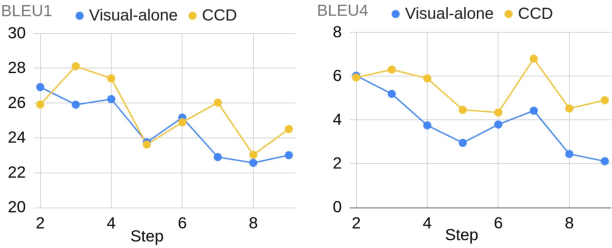

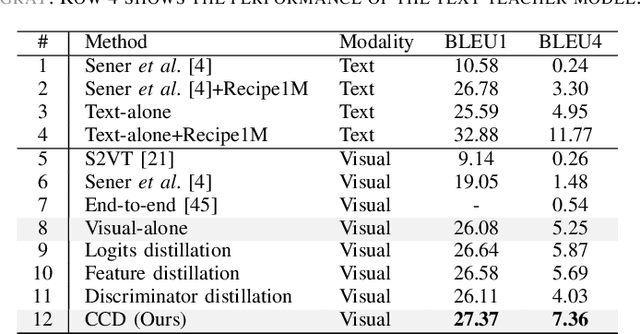
In this study, we aim to predict the plausible future action steps given an observation of the past and study the task of instructional activity anticipation. Unlike previous anticipation tasks that aim at action label prediction, our work targets at generating natural language outputs that provide interpretable and accurate descriptions of future action steps. It is a challenging task due to the lack of semantic information extracted from the instructional videos. To overcome this challenge, we propose a novel knowledge distillation framework to exploit the related external textual knowledge to assist the visual anticipation task. However, previous knowledge distillation techniques generally transfer information within the same modality. To bridge the gap between the visual and text modalities during the distillation process, we devise a novel cross-modal contrastive distillation (CCD) scheme, which facilitates knowledge distillation between teacher and student in heterogeneous modalities with the proposed cross-modal distillation loss. We evaluate our method on the Tasty Videos dataset. CCD improves the anticipation performance of the visual-alone student model by a large margin of 40.2% relatively in BLEU4. Our approach also outperforms the state-of-the-art approaches by a large margin.
Motion-Focused Contrastive Learning of Video Representations
Jan 11, 2022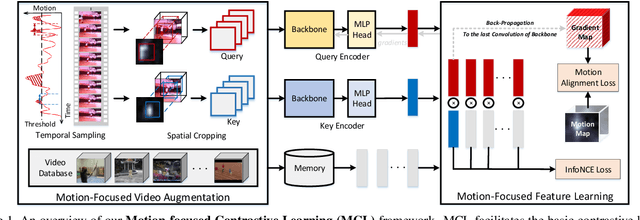
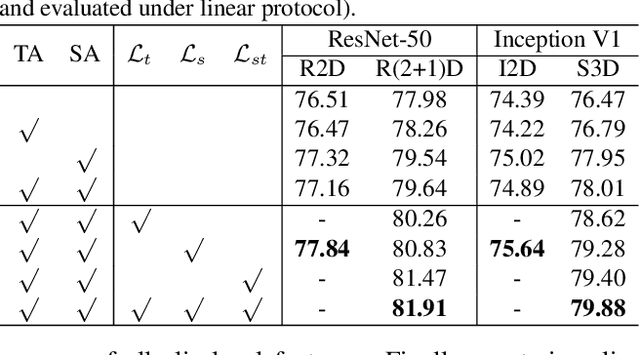
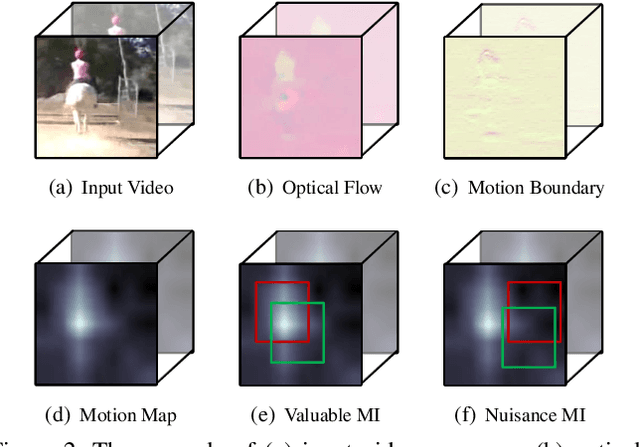

Motion, as the most distinct phenomenon in a video to involve the changes over time, has been unique and critical to the development of video representation learning. In this paper, we ask the question: how important is the motion particularly for self-supervised video representation learning. To this end, we compose a duet of exploiting the motion for data augmentation and feature learning in the regime of contrastive learning. Specifically, we present a Motion-focused Contrastive Learning (MCL) method that regards such duet as the foundation. On one hand, MCL capitalizes on optical flow of each frame in a video to temporally and spatially sample the tubelets (i.e., sequences of associated frame patches across time) as data augmentations. On the other hand, MCL further aligns gradient maps of the convolutional layers to optical flow maps from spatial, temporal and spatio-temporal perspectives, in order to ground motion information in feature learning. Extensive experiments conducted on R(2+1)D backbone demonstrate the effectiveness of our MCL. On UCF101, the linear classifier trained on the representations learnt by MCL achieves 81.91% top-1 accuracy, outperforming ImageNet supervised pre-training by 6.78%. On Kinetics-400, MCL achieves 66.62% top-1 accuracy under the linear protocol. Code is available at https://github.com/YihengZhang-CV/MCL-Motion-Focused-Contrastive-Learning.
Representing Videos as Discriminative Sub-graphs for Action Recognition
Jan 11, 2022

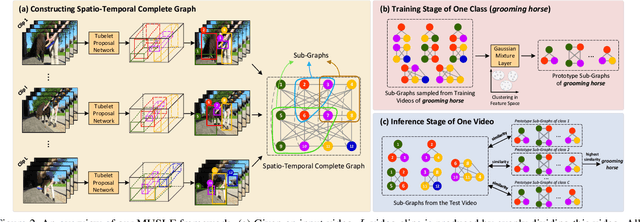
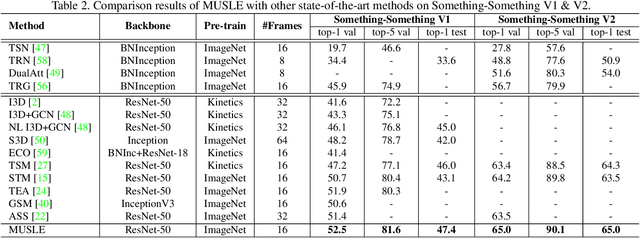
Human actions are typically of combinatorial structures or patterns, i.e., subjects, objects, plus spatio-temporal interactions in between. Discovering such structures is therefore a rewarding way to reason about the dynamics of interactions and recognize the actions. In this paper, we introduce a new design of sub-graphs to represent and encode the discriminative patterns of each action in the videos. Specifically, we present MUlti-scale Sub-graph LEarning (MUSLE) framework that novelly builds space-time graphs and clusters the graphs into compact sub-graphs on each scale with respect to the number of nodes. Technically, MUSLE produces 3D bounding boxes, i.e., tubelets, in each video clip, as graph nodes and takes dense connectivity as graph edges between tubelets. For each action category, we execute online clustering to decompose the graph into sub-graphs on each scale through learning Gaussian Mixture Layer and select the discriminative sub-graphs as action prototypes for recognition. Extensive experiments are conducted on both Something-Something V1 & V2 and Kinetics-400 datasets, and superior results are reported when comparing to state-of-the-art methods. More remarkably, our MUSLE achieves to-date the best reported accuracy of 65.0% on Something-Something V2 validation set.
Uni-EDEN: Universal Encoder-Decoder Network by Multi-Granular Vision-Language Pre-training
Jan 11, 2022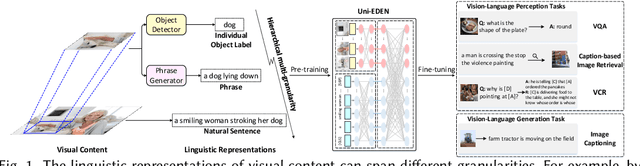
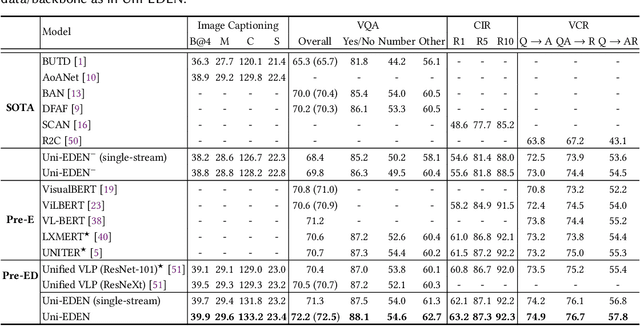
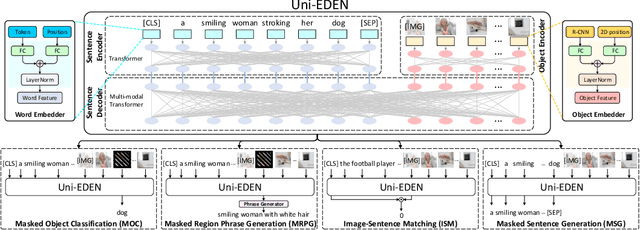
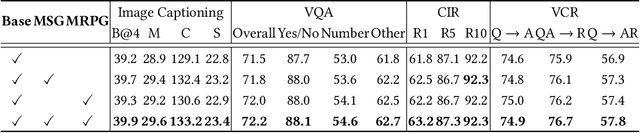
Vision-language pre-training has been an emerging and fast-developing research topic, which transfers multi-modal knowledge from rich-resource pre-training task to limited-resource downstream tasks. Unlike existing works that predominantly learn a single generic encoder, we present a pre-trainable Universal Encoder-DEcoder Network (Uni-EDEN) to facilitate both vision-language perception (e.g., visual question answering) and generation (e.g., image captioning). Uni-EDEN is a two-stream Transformer based structure, consisting of three modules: object and sentence encoders that separately learns the representations of each modality, and sentence decoder that enables both multi-modal reasoning and sentence generation via inter-modal interaction. Considering that the linguistic representations of each image can span different granularities in this hierarchy including, from simple to comprehensive, individual label, a phrase, and a natural sentence, we pre-train Uni-EDEN through multi-granular vision-language proxy tasks: Masked Object Classification (MOC), Masked Region Phrase Generation (MRPG), Image-Sentence Matching (ISM), and Masked Sentence Generation (MSG). In this way, Uni-EDEN is endowed with the power of both multi-modal representation extraction and language modeling. Extensive experiments demonstrate the compelling generalizability of Uni-EDEN by fine-tuning it to four vision-language perception and generation downstream tasks.
Smart Director: An Event-Driven Directing System for Live Broadcasting
Jan 11, 2022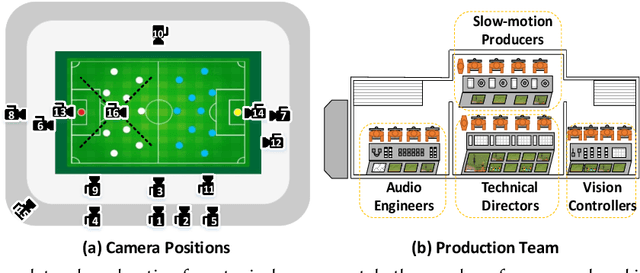
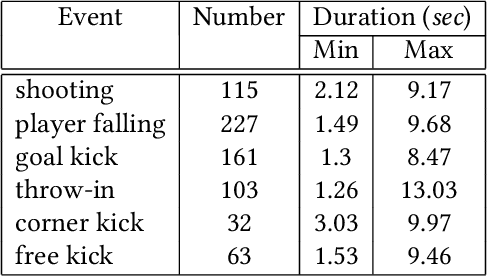
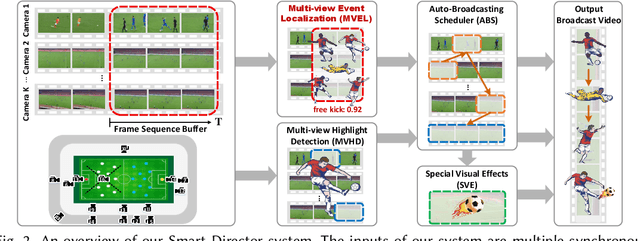
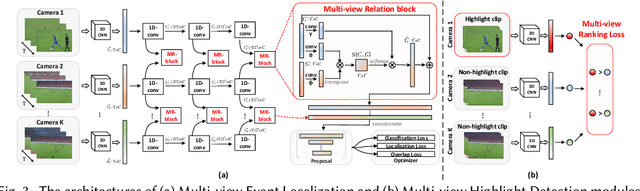
Live video broadcasting normally requires a multitude of skills and expertise with domain knowledge to enable multi-camera productions. As the number of cameras keep increasing, directing a live sports broadcast has now become more complicated and challenging than ever before. The broadcast directors need to be much more concentrated, responsive, and knowledgeable, during the production. To relieve the directors from their intensive efforts, we develop an innovative automated sports broadcast directing system, called Smart Director, which aims at mimicking the typical human-in-the-loop broadcasting process to automatically create near-professional broadcasting programs in real-time by using a set of advanced multi-view video analysis algorithms. Inspired by the so-called "three-event" construction of sports broadcast, we build our system with an event-driven pipeline consisting of three consecutive novel components: 1) the Multi-view Event Localization to detect events by modeling multi-view correlations, 2) the Multi-view Highlight Detection to rank camera views by the visual importance for view selection, 3) the Auto-Broadcasting Scheduler to control the production of broadcasting videos. To our best knowledge, our system is the first end-to-end automated directing system for multi-camera sports broadcasting, completely driven by the semantic understanding of sports events. It is also the first system to solve the novel problem of multi-view joint event detection by cross-view relation modeling. We conduct both objective and subjective evaluations on a real-world multi-camera soccer dataset, which demonstrate the quality of our auto-generated videos is comparable to that of the human-directed. Thanks to its faster response, our system is able to capture more fast-passing and short-duration events which are usually missed by human directors.
Boosting Video Representation Learning with Multi-Faceted Integration
Jan 11, 2022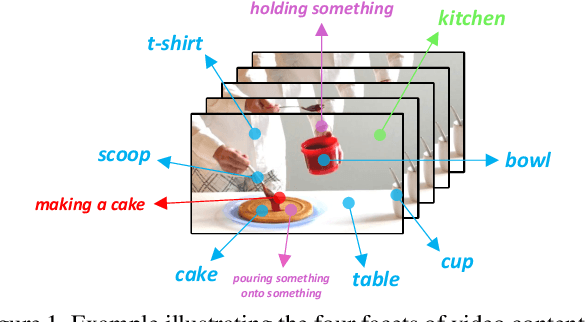
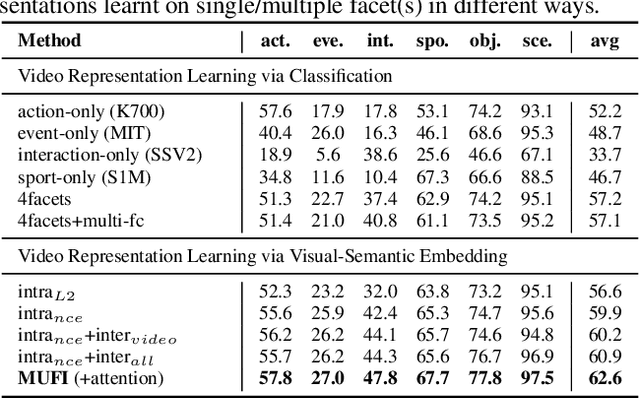
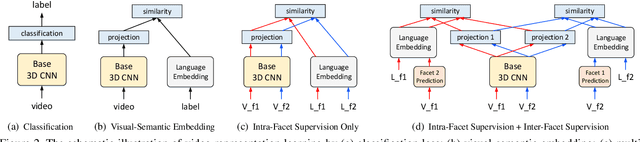
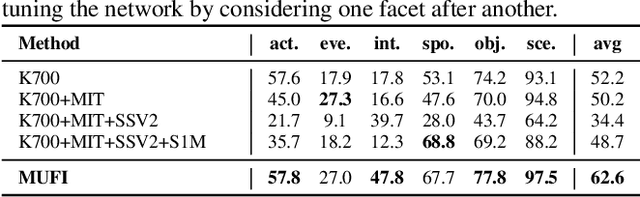
Video content is multifaceted, consisting of objects, scenes, interactions or actions. The existing datasets mostly label only one of the facets for model training, resulting in the video representation that biases to only one facet depending on the training dataset. There is no study yet on how to learn a video representation from multifaceted labels, and whether multifaceted information is helpful for video representation learning. In this paper, we propose a new learning framework, MUlti-Faceted Integration (MUFI), to aggregate facets from different datasets for learning a representation that could reflect the full spectrum of video content. Technically, MUFI formulates the problem as visual-semantic embedding learning, which explicitly maps video representation into a rich semantic embedding space, and jointly optimizes video representation from two perspectives. One is to capitalize on the intra-facet supervision between each video and its own label descriptions, and the second predicts the "semantic representation" of each video from the facets of other datasets as the inter-facet supervision. Extensive experiments demonstrate that learning 3D CNN via our MUFI framework on a union of four large-scale video datasets plus two image datasets leads to superior capability of video representation. The pre-learnt 3D CNN with MUFI also shows clear improvements over other approaches on several downstream video applications. More remarkably, MUFI achieves 98.1%/80.9% on UCF101/HMDB51 for action recognition and 101.5% in terms of CIDEr-D score on MSVD for video captioning.
Condensing a Sequence to One Informative Frame for Video Recognition
Jan 11, 2022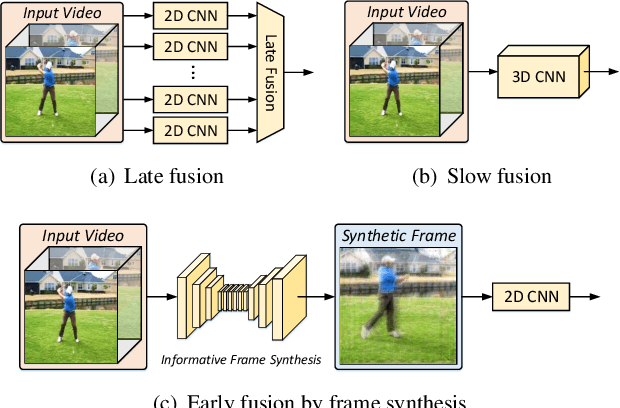
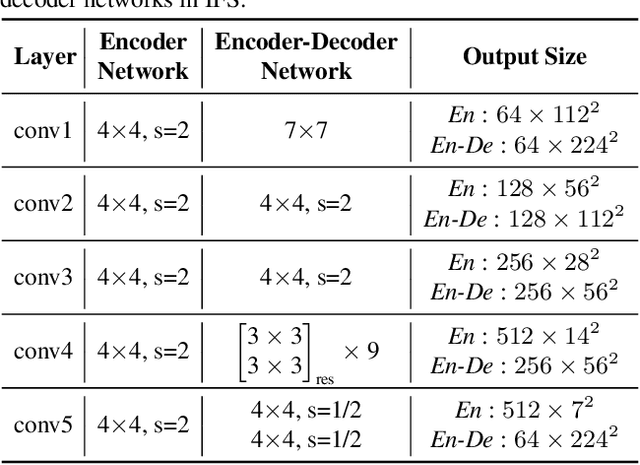
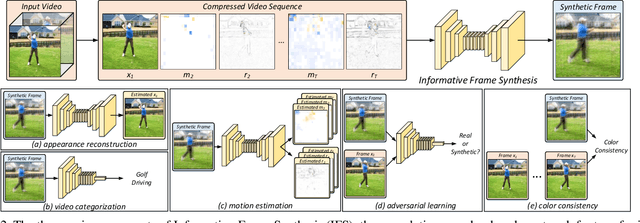
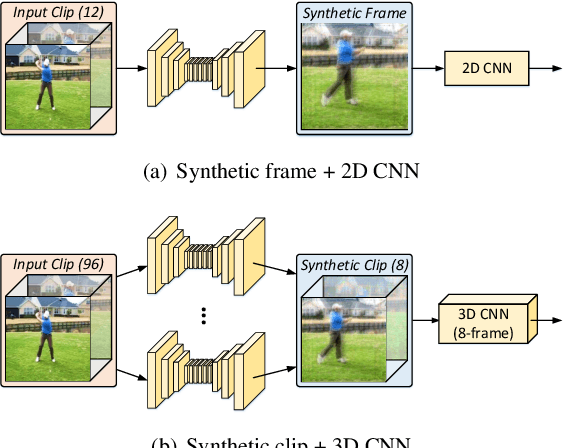
Video is complex due to large variations in motion and rich content in fine-grained visual details. Abstracting useful information from such information-intensive media requires exhaustive computing resources. This paper studies a two-step alternative that first condenses the video sequence to an informative "frame" and then exploits off-the-shelf image recognition system on the synthetic frame. A valid question is how to define "useful information" and then distill it from a video sequence down to one synthetic frame. This paper presents a novel Informative Frame Synthesis (IFS) architecture that incorporates three objective tasks, i.e., appearance reconstruction, video categorization, motion estimation, and two regularizers, i.e., adversarial learning, color consistency. Each task equips the synthetic frame with one ability, while each regularizer enhances its visual quality. With these, by jointly learning the frame synthesis in an end-to-end manner, the generated frame is expected to encapsulate the required spatio-temporal information useful for video analysis. Extensive experiments are conducted on the large-scale Kinetics dataset. When comparing to baseline methods that map video sequence to a single image, IFS shows superior performance. More remarkably, IFS consistently demonstrates evident improvements on image-based 2D networks and clip-based 3D networks, and achieves comparable performance with the state-of-the-art methods with less computational cost.
Optimization Planning for 3D ConvNets
Jan 11, 2022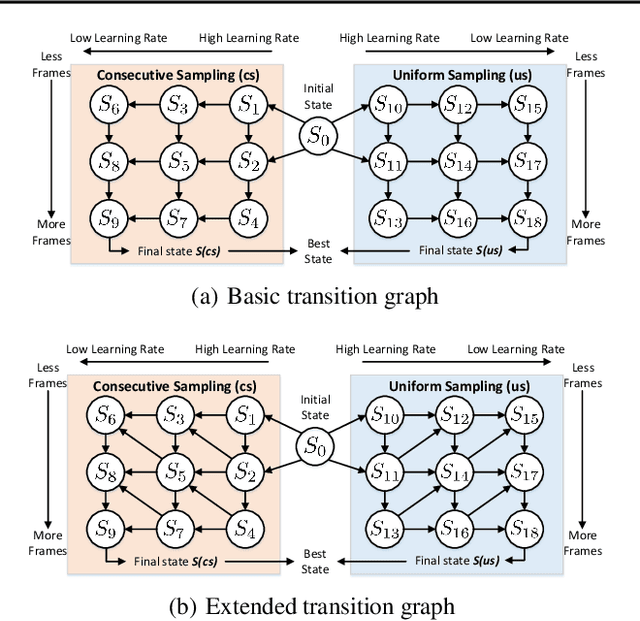

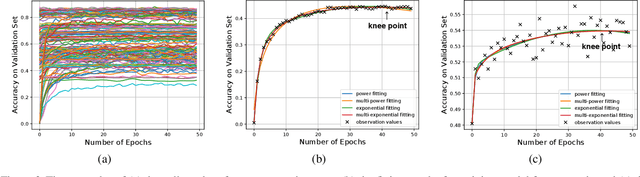
It is not trivial to optimally learn a 3D Convolutional Neural Networks (3D ConvNets) due to high complexity and various options of the training scheme. The most common hand-tuning process starts from learning 3D ConvNets using short video clips and then is followed by learning long-term temporal dependency using lengthy clips, while gradually decaying the learning rate from high to low as training progresses. The fact that such process comes along with several heuristic settings motivates the study to seek an optimal "path" to automate the entire training. In this paper, we decompose the path into a series of training "states" and specify the hyper-parameters, e.g., learning rate and the length of input clips, in each state. The estimation of the knee point on the performance-epoch curve triggers the transition from one state to another. We perform dynamic programming over all the candidate states to plan the optimal permutation of states, i.e., optimization path. Furthermore, we devise a new 3D ConvNets with a unique design of dual-head classifier to improve spatial and temporal discrimination. Extensive experiments on seven public video recognition benchmarks demonstrate the advantages of our proposal. With the optimization planning, our 3D ConvNets achieves superior results when comparing to the state-of-the-art recognition methods. More remarkably, we obtain the top-1 accuracy of 80.5% and 82.7% on Kinetics-400 and Kinetics-600 datasets, respectively. Source code is available at https://github.com/ZhaofanQiu/Optimization-Planning-for-3D-ConvNets.
Responsive Listening Head Generation: A Benchmark Dataset and Baseline
Dec 27, 2021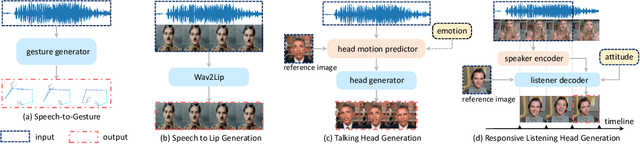
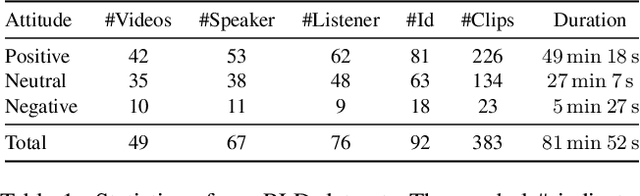

Responsive listening during face-to-face conversations is a critical element of social interaction and is well established in psychological research. Through non-verbal signals response to the speakers' words, intonations, or behaviors in real-time, listeners show how they are engaged in dialogue. In this work, we build the Responsive Listener Dataset (RLD), a conversation video corpus collected from the public resources featuring 67 speakers, 76 listeners with three different attitudes. We define the responsive listening head generation task as the synthesis of a non-verbal head with motions and expressions reacting to the multiple inputs, including the audio and visual signal of the speaker. Unlike speech-driven gesture or talking head generation, we introduce more modals in this task, hoping to benefit several research fields, including human-to-human interaction, video-to-video translation, cross-modal understanding, and generation. Furthermore, we release an attitude conditioned listening head generation baseline. Project page: \url{https://project.mhzhou.com/rld}.
Putting People in their Place: Monocular Regression of 3D People in Depth
Dec 15, 2021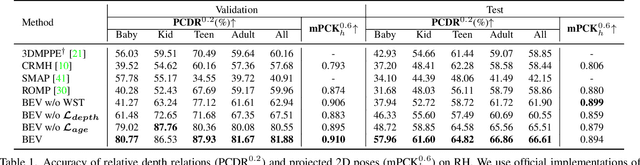
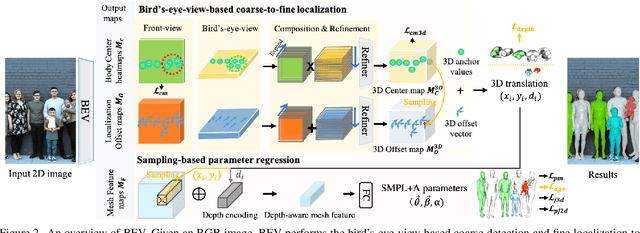

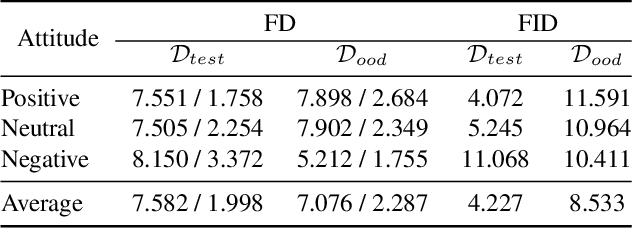
Given an image with multiple people, our goal is to directly regress the pose and shape of all the people as well as their relative depth. Inferring the depth of a person in an image, however, is fundamentally ambiguous without knowing their height. This is particularly problematic when the scene contains people of very different sizes, e.g. from infants to adults. To solve this, we need several things. First, we develop a novel method to infer the poses and depth of multiple people in a single image. While previous work that estimates multiple people does so by reasoning in the image plane, our method, called BEV, adds an additional imaginary Bird's-Eye-View representation to explicitly reason about depth. BEV reasons simultaneously about body centers in the image and in depth and, by combing these, estimates 3D body position. Unlike prior work, BEV is a single-shot method that is end-to-end differentiable. Second, height varies with age, making it impossible to resolve depth without also estimating the age of people in the image. To do so, we exploit a 3D body model space that lets BEV infer shapes from infants to adults. Third, to train BEV, we need a new dataset. Specifically, we create a "Relative Human" (RH) dataset that includes age labels and relative depth relationships between the people in the images. Extensive experiments on RH and AGORA demonstrate the effectiveness of the model and training scheme. BEV outperforms existing methods on depth reasoning, child shape estimation, and robustness to occlusion. The code and dataset will be released for research purposes.