 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Temporal Filtering in Video Models
Nov 15, 2022Video temporal dynamics is conventionally modeled with 3D spatial-temporal kernel or its factorized version comprised of 2D spatial kernel and 1D temporal kernel. The modeling power, nevertheless, is limited by the fixed window size and static weights of a kernel along the temporal dimension. The pre-determined kernel size severely limits the temporal receptive fields and the fixed weights treat each spatial location across frames equally, resulting in sub-optimal solution for long-range temporal modeling in natural scenes. In this paper, we present a new recipe of temporal feature learning, namely Dynamic Temporal Filter (DTF), that novelly performs spatial-aware temporal modeling in frequency domain with large temporal receptive field. Specifically, DTF dynamically learns a specialized frequency filter for every spatial location to model its long-range temporal dynamics. Meanwhile, the temporal feature of each spatial location is also transformed into frequency feature spectrum via 1D Fast Fourier Transform (FFT). The spectrum is modulated by the learnt frequency filter, and then transformed back to temporal domain with inverse FFT. In addition, to facilitate the learning of frequency filter in DTF, we perform frame-wise aggregation to enhance the primary temporal feature with its temporal neighbors by inter-frame correlation. It is feasible to plug DTF block into ConvNets and Transformer, yielding DTF-Net and DTF-Transformer. Extensive experiments conducted on three datasets demonstrate the superiority of our proposals. More remarkably, DTF-Transformer achieves an accuracy of 83.5% on Kinetics-400 dataset. Source code is available at \url{https://github.com/FuchenUSTC/DTF}.
Out-of-Distribution Detection with Hilbert-Schmidt Independence Optimization
Sep 26, 2022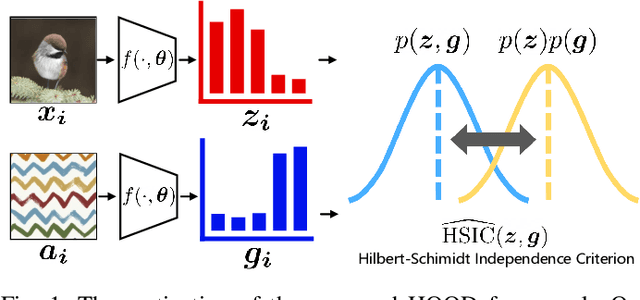
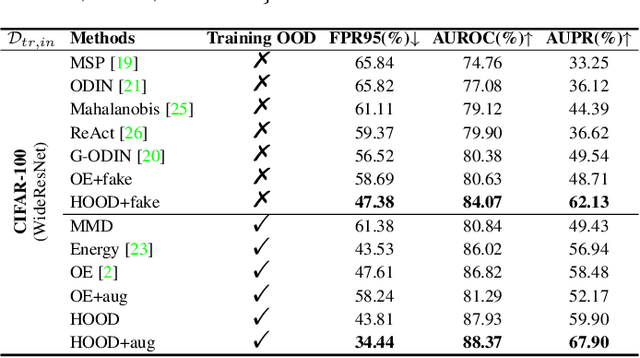
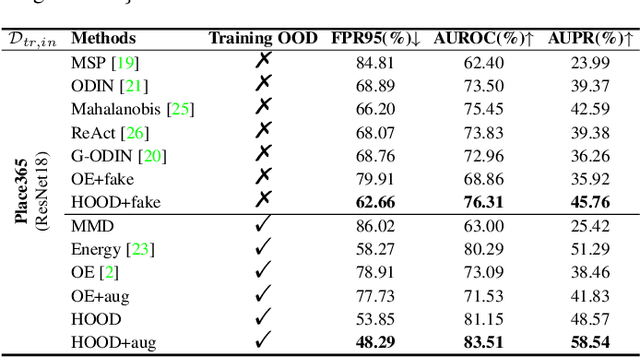
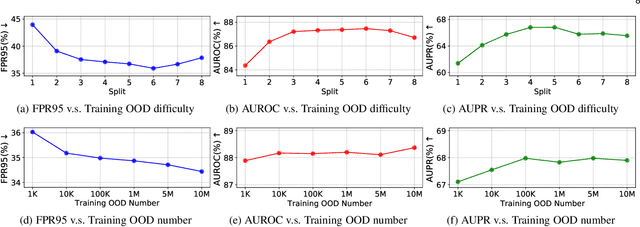
Outlier detection tasks have been playing a critical role in AI safety. There has been a great challenge to deal with this task. Observations show that deep neural network classifiers usually tend to incorrectly classify out-of-distribution (OOD) inputs into in-distribution classes with high confidence. Existing works attempt to solve the problem by explicitly imposing uncertainty on classifiers when OOD inputs are exposed to the classifier during training. In this paper, we propose an alternative probabilistic paradigm that is both practically useful and theoretically viable for the OOD detection tasks. Particularly, we impose statistical independence between inlier and outlier data during training, in order to ensure that inlier data reveals little information about OOD data to the deep estimator during training. Specifically, we estimate the statistical dependence between inlier and outlier data through the Hilbert-Schmidt Independence Criterion (HSIC), and we penalize such metric during training. We also associate our approach with a novel statistical test during the inference time coupled with our principled motivation. Empirical results show that our method is effective and robust for OOD detection on various benchmarks. In comparison to SOTA models, our approach achieves significant improvement regarding FPR95, AUROC, and AUPR metrics. Code is available: \url{https://github.com/jylins/hood}.
Generalized One-shot Domain Adaption of Generative Adversarial Networks
Sep 08, 2022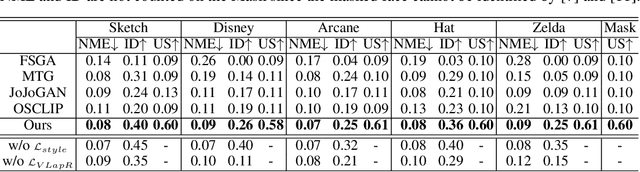
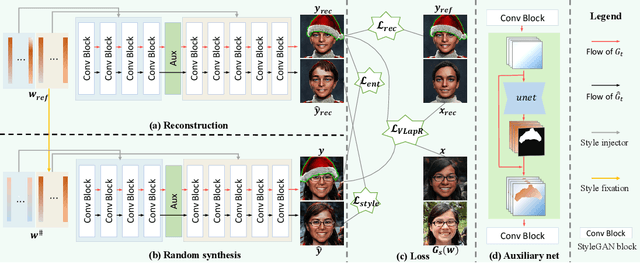

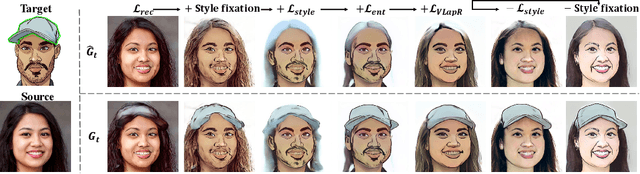
The adaption of Generative Adversarial Network (GAN) aims to transfer a pre-trained GAN to a given domain with limited training data. In this paper, we focus on the one-shot case, which is more challenging and rarely explored in previous works. We consider that the adaptation from source domain to target domain can be decoupled into two parts: the transfer of global style like texture and color, and the emergence of new entities that do not belong to the source domain. While previous works mainly focus on the style transfer, we propose a novel and concise framework\footnote{\url{https://github.com/thevoidname/Generalized-One-shot-GAN-Adaption}} to address the \textit{generalized one-shot adaption} task for both style and entity transfer, in which a reference image and its binary entity mask are provided. Our core objective is to constrain the gap between the internal distributions of the reference and syntheses by sliced Wasserstein distance. To better achieve it, style fixation is used at first to roughly obtain the exemplary style, and an auxiliary network is introduced to the original generator to disentangle entity and style transfer. Besides, to realize cross-domain correspondence, we propose the variational Laplacian regularization to constrain the smoothness of the adapted generator. Both quantitative and qualitative experiments demonstrate the effectiveness of our method in various scenarios.
WOC: A Handy Webcam-based 3D Online Chatroom
Sep 02, 2022
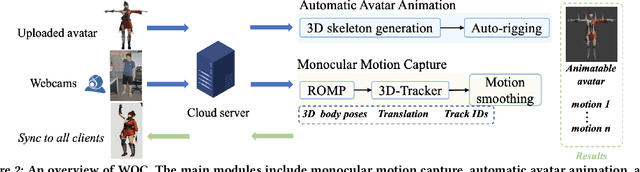
We develop WOC, a webcam-based 3D virtual online chatroom for multi-person interaction, which captures the 3D motion of users and drives their individual 3D virtual avatars in real-time. Compared to the existing wearable equipment-based solution, WOC offers convenient and low-cost 3D motion capture with a single camera. To promote the immersive chat experience, WOC provides high-fidelity virtual avatar manipulation, which also supports the user-defined characters. With the distributed data flow service, the system delivers highly synchronized motion and voice for all users. Deployed on the website and no installation required, users can freely experience the virtual online chat at https://yanch.cloud.
Lightweight and Progressively-Scalable Networks for Semantic Segmentation
Jul 27, 2022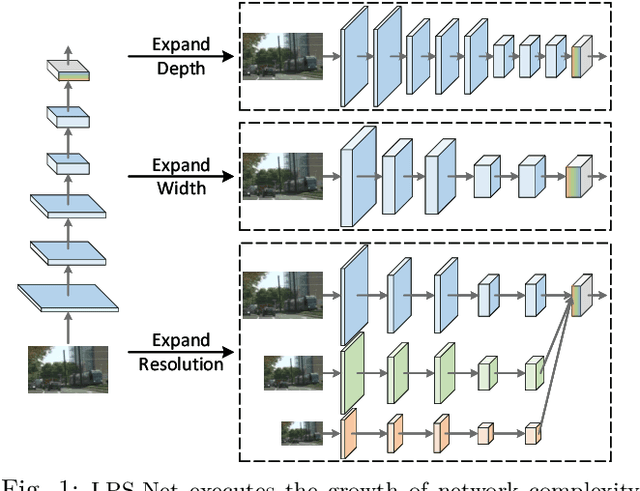

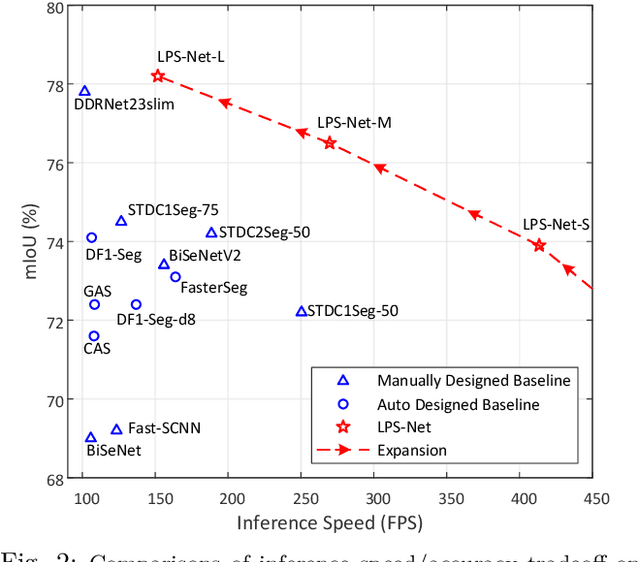
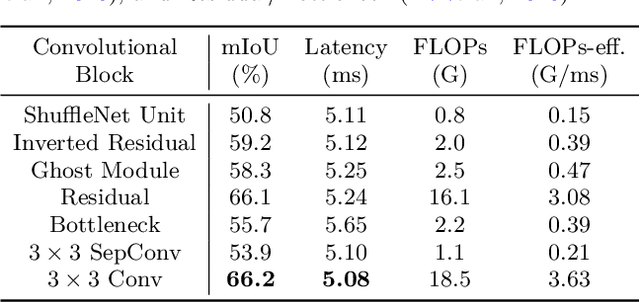
Multi-scale learning frameworks have been regarded as a capable class of models to boost semantic segmentation. The problem nevertheless is not trivial especially for the real-world deployments, which often demand high efficiency in inference latency. In this paper, we thoroughly analyze the design of convolutional blocks (the type of convolutions and the number of channels in convolutions), and the ways of interactions across multiple scales, all from lightweight standpoint for semantic segmentation. With such in-depth comparisons, we conclude three principles, and accordingly devise Lightweight and Progressively-Scalable Networks (LPS-Net) that novelly expands the network complexity in a greedy manner. Technically, LPS-Net first capitalizes on the principles to build a tiny network. Then, LPS-Net progressively scales the tiny network to larger ones by expanding a single dimension (the number of convolutional blocks, the number of channels, or the input resolution) at one time to meet the best speed/accuracy tradeoff. Extensive experiments conducted on three datasets consistently demonstrate the superiority of LPS-Net over several efficient semantic segmentation methods. More remarkably, our LPS-Net achieves 73.4% mIoU on Cityscapes test set, with the speed of 413.5FPS on an NVIDIA GTX 1080Ti, leading to a performance improvement by 1.5% and a 65% speed-up against the state-of-the-art STDC. Code is available at \url{https://github.com/YihengZhang-CV/LPS-Net}.
Dual Vision Transformer
Jul 12, 2022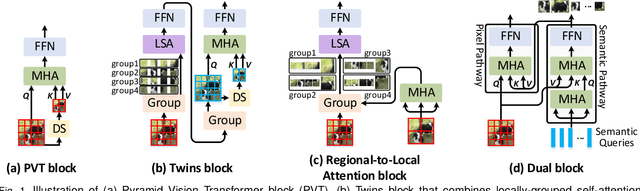
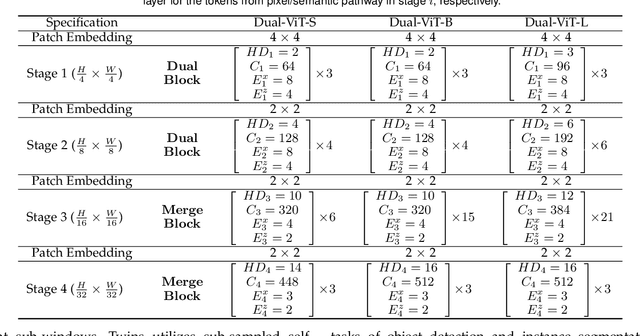
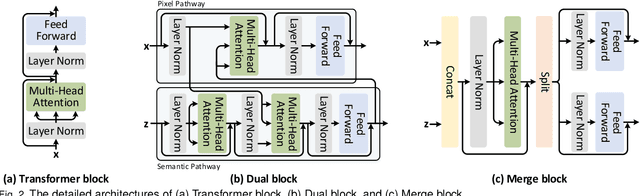
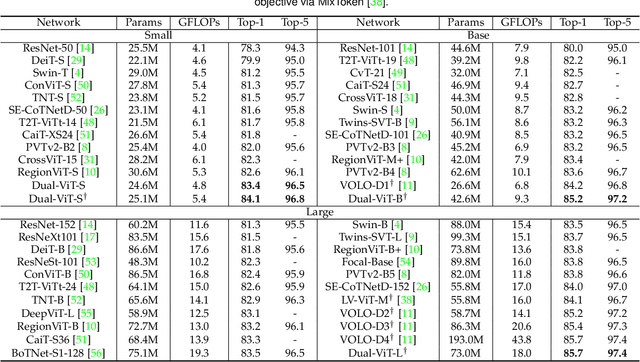
Prior works have proposed several strategies to reduce the computational cost of self-attention mechanism. Many of these works consider decomposing the self-attention procedure into regional and local feature extraction procedures that each incurs a much smaller computational complexity. However, regional information is typically only achieved at the expense of undesirable information lost owing to down-sampling. In this paper, we propose a novel Transformer architecture that aims to mitigate the cost issue, named Dual Vision Transformer (Dual-ViT). The new architecture incorporates a critical semantic pathway that can more efficiently compress token vectors into global semantics with reduced order of complexity. Such compressed global semantics then serve as useful prior information in learning finer pixel level details, through another constructed pixel pathway. The semantic pathway and pixel pathway are then integrated together and are jointly trained, spreading the enhanced self-attention information in parallel through both of the pathways. Dual-ViT is henceforth able to reduce the computational complexity without compromising much accuracy. We empirically demonstrate that Dual-ViT provides superior accuracy than SOTA Transformer architectures with reduced training complexity. Source code is available at \url{https://github.com/YehLi/ImageNetModel}.
Wave-ViT: Unifying Wavelet and Transformers for Visual Representation Learning
Jul 11, 2022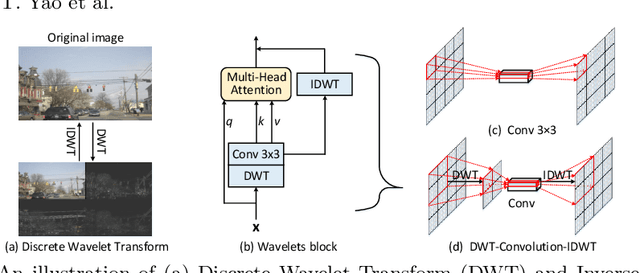
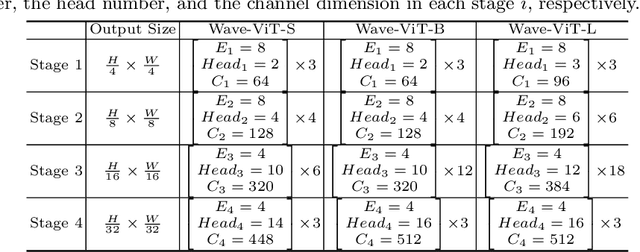
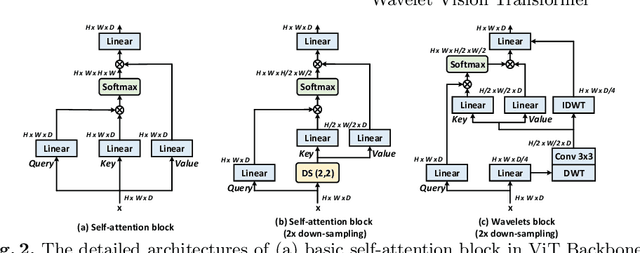
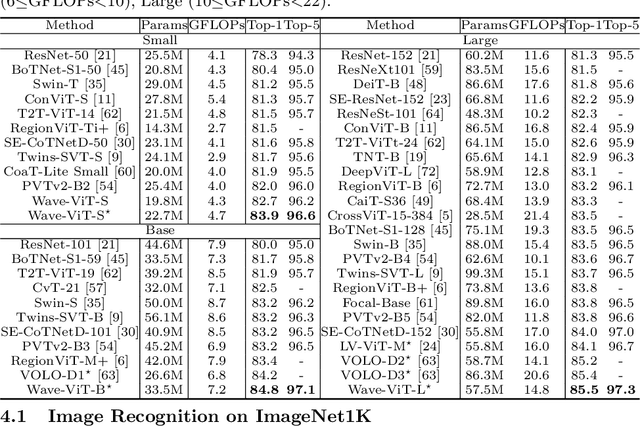
Multi-scale Vision Transformer (ViT) has emerged as a powerful backbone for computer vision tasks, while the self-attention computation in Transformer scales quadratically w.r.t. the input patch number. Thus, existing solutions commonly employ down-sampling operations (e.g., average pooling) over keys/values to dramatically reduce the computational cost. In this work, we argue that such over-aggressive down-sampling design is not invertible and inevitably causes information dropping especially for high-frequency components in objects (e.g., texture details). Motivated by the wavelet theory, we construct a new Wavelet Vision Transformer (\textbf{Wave-ViT}) that formulates the invertible down-sampling with wavelet transforms and self-attention learning in a unified way. This proposal enables self-attention learning with lossless down-sampling over keys/values, facilitating the pursuing of a better efficiency-vs-accuracy trade-off. Furthermore, inverse wavelet transforms are leveraged to strengthen self-attention outputs by aggregating local contexts with enlarged receptive field. We validate the superiority of Wave-ViT through extensive experiments over multiple vision tasks (e.g., image recognition, object detection and instance segmentation). Its performances surpass state-of-the-art ViT backbones with comparable FLOPs. Source code is available at \url{https://github.com/YehLi/ImageNetModel}.
Video2StyleGAN: Encoding Video in Latent Space for Manipulation
Jun 27, 2022
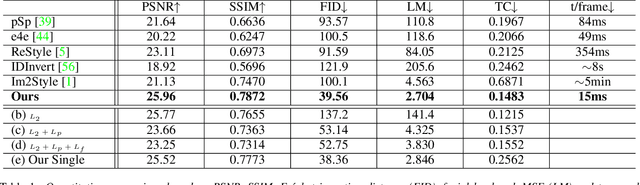
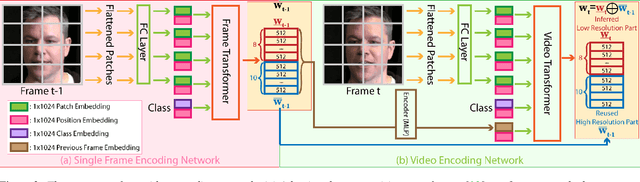
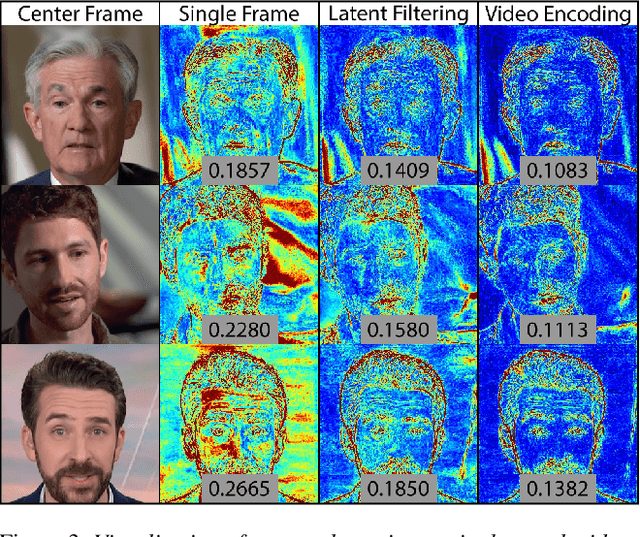
Many recent works have been proposed for face image editing by leveraging the latent space of pretrained GANs. However, few attempts have been made to directly apply them to videos, because 1) they do not guarantee temporal consistency, 2) their application is limited by their processing speed on videos, and 3) they cannot accurately encode details of face motion and expression. To this end, we propose a novel network to encode face videos into the latent space of StyleGAN for semantic face video manipulation. Based on the vision transformer, our network reuses the high-resolution portion of the latent vector to enforce temporal consistency. To capture subtle face motions and expressions, we design novel losses that involve sparse facial landmarks and dense 3D face mesh. We have thoroughly evaluated our approach and successfully demonstrated its application to various face video manipulations. Particularly, we propose a novel network for pose/expression control in a 3D coordinate system. Both qualitative and quantitative results have shown that our approach can significantly outperform existing single image methods, while achieving real-time (66 fps) speed.
Bi-Calibration Networks for Weakly-Supervised Video Representation Learning
Jun 21, 2022

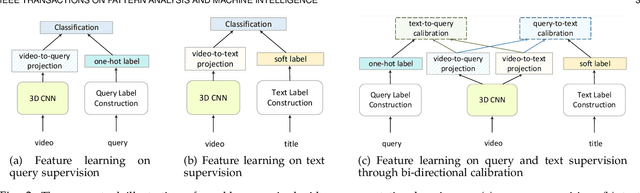
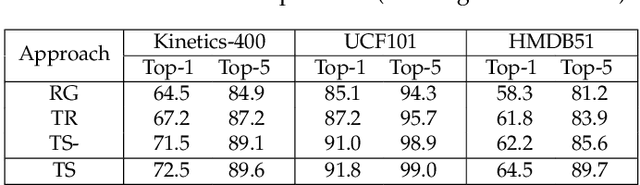
The leverage of large volumes of web videos paired with the searched queries or surrounding texts (e.g., title) offers an economic and extensible alternative to supervised video representation learning. Nevertheless, modeling such weakly visual-textual connection is not trivial due to query polysemy (i.e., many possible meanings for a query) and text isomorphism (i.e., same syntactic structure of different text). In this paper, we introduce a new design of mutual calibration between query and text to boost weakly-supervised video representation learning. Specifically, we present Bi-Calibration Networks (BCN) that novelly couples two calibrations to learn the amendment from text to query and vice versa. Technically, BCN executes clustering on all the titles of the videos searched by an identical query and takes the centroid of each cluster as a text prototype. The query vocabulary is built directly on query words. The video-to-text/video-to-query projections over text prototypes/query vocabulary then start the text-to-query or query-to-text calibration to estimate the amendment to query or text. We also devise a selection scheme to balance the two corrections. Two large-scale web video datasets paired with query and title for each video are newly collected for weakly-supervised video representation learning, which are named as YOVO-3M and YOVO-10M, respectively. The video features of BCN learnt on 3M web videos obtain superior results under linear model protocol on downstream tasks. More remarkably, BCN trained on the larger set of 10M web videos with further fine-tuning leads to 1.6%, and 1.8% gains in top-1 accuracy on Kinetics-400, and Something-Something V2 datasets over the state-of-the-art TDN, and ACTION-Net methods with ImageNet pre-training. Source code and datasets are available at \url{https://github.com/FuchenUSTC/BCN}.
Stand-Alone Inter-Frame Attention in Video Models
Jun 14, 2022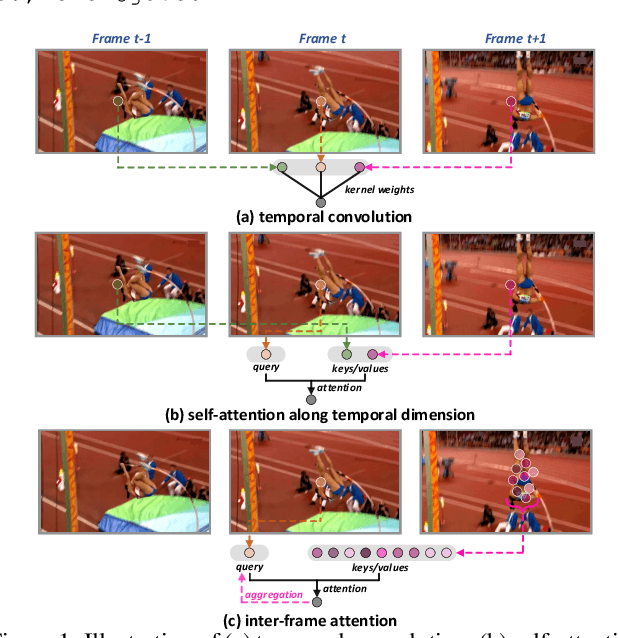
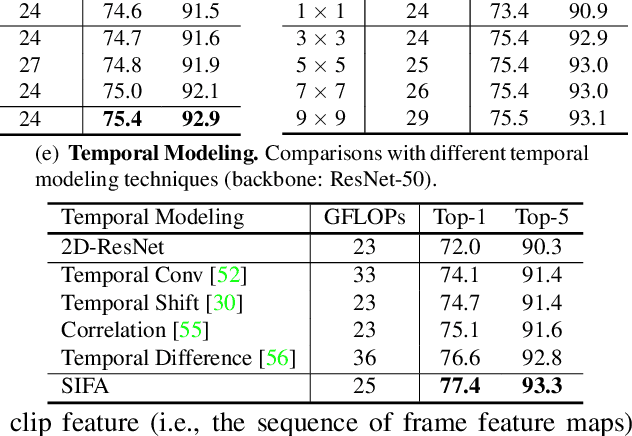
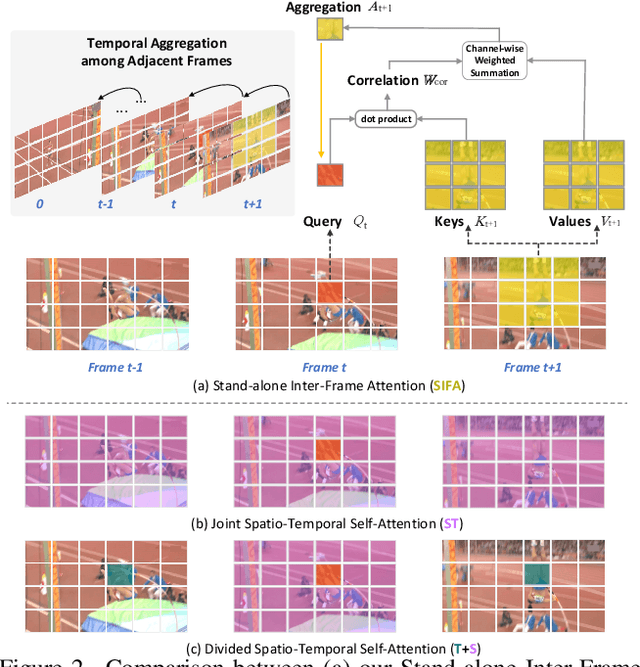
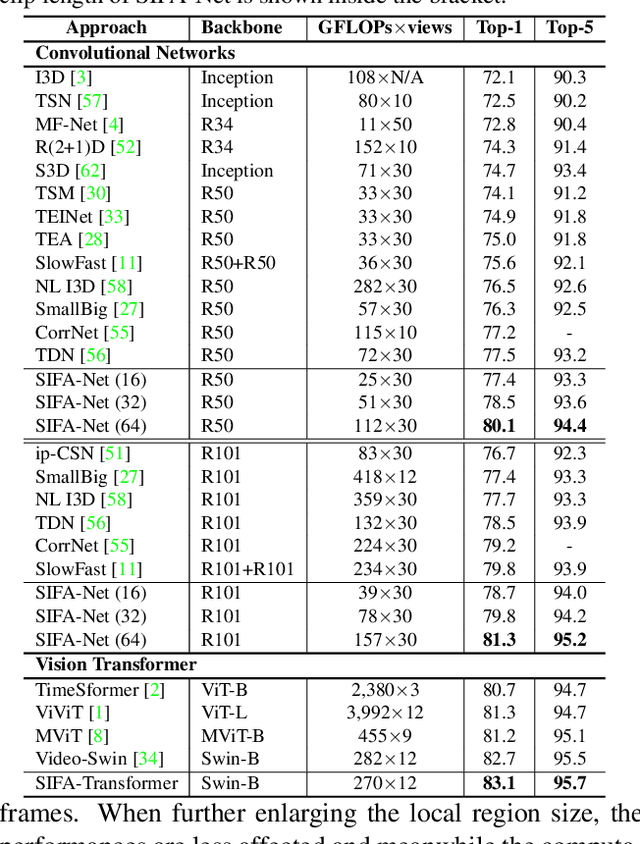
Motion, as the uniqueness of a video, has been critical to the development of video understanding models. Modern deep learning models leverage motion by either executing spatio-temporal 3D convolutions, factorizing 3D convolutions into spatial and temporal convolutions separately, or computing self-attention along temporal dimension. The implicit assumption behind such successes is that the feature maps across consecutive frames can be nicely aggregated. Nevertheless, the assumption may not always hold especially for the regions with large deformation. In this paper, we present a new recipe of inter-frame attention block, namely Stand-alone Inter-Frame Attention (SIFA), that novelly delves into the deformation across frames to estimate local self-attention on each spatial location. Technically, SIFA remoulds the deformable design via re-scaling the offset predictions by the difference between two frames. Taking each spatial location in the current frame as the query, the locally deformable neighbors in the next frame are regarded as the keys/values. Then, SIFA measures the similarity between query and keys as stand-alone attention to weighted average the values for temporal aggregation. We further plug SIFA block into ConvNets and Vision Transformer, respectively, to devise SIFA-Net and SIFA-Transformer. Extensive experiments conducted on four video datasets demonstrate the superiority of SIFA-Net and SIFA-Transformer as stronger backbones. More remarkably, SIFA-Transformer achieves an accuracy of 83.1% on Kinetics-400 dataset. Source code is available at \url{https://github.com/FuchenUSTC/SIFA}.