 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaceX-Zoo: A PyTorch Toolbox for Face Recognition
Jan 13, 2021
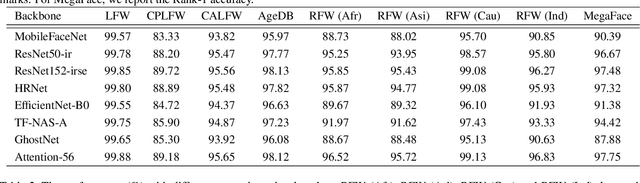
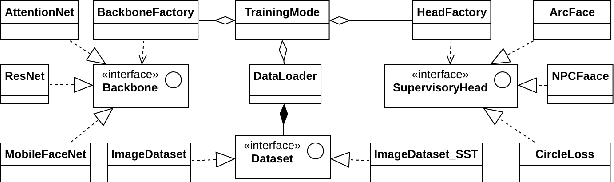
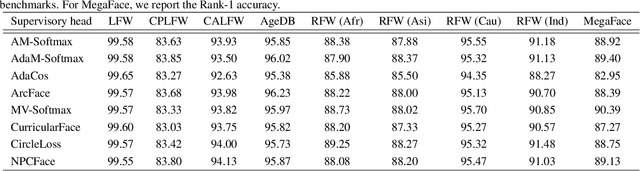
Deep learning based face recognition has achieved significant progress in recent years. Yet, the practical model production and further research of deep face recognition are in great need of corresponding public support. For example, the production of face representation network desires a modular training scheme to consider the proper choice from various candidates of state-of-the-art backbone and training supervision subject to the real-world face recognition demand; for performance analysis and comparison, the standard and automatic evaluation with a bunch of models on multiple benchmarks will be a desired tool as well; besides, a public groundwork is welcomed for deploying the face recognition in the shape of holistic pipeline. Furthermore, there are some newly-emerged challenges, such as the masked face recognition caused by the recent world-wide COVID-19 pandemic, which draws increasing attention in practical applications. A feasible and elegant solution is to build an easy-to-use unified framework to meet the above demands. To this end, we introduce a novel open-source framework, named FaceX-Zoo, which is oriented to the research-development community of face recognition. Resorting to the highly modular and scalable design, FaceX-Zoo provides a training module with various supervisory heads and backbones towards state-of-the-art face recognition, as well as a standardized evaluation module which enables to evaluate the models in most of the popular benchmarks just by editing a simple configuration. Also, a simple yet fully functional face SDK is provided for the validation and primary application of the trained models. Rather than including as many as possible of the prior techniques, we enable FaceX-Zoo to easily upgrade and extend along with the development of face related domains. The source code and models are available at https://github.com/JDAI-CV/FaceX-Zoo.
Synthetic Training for Monocular Human Mesh Recovery
Oct 27, 2020
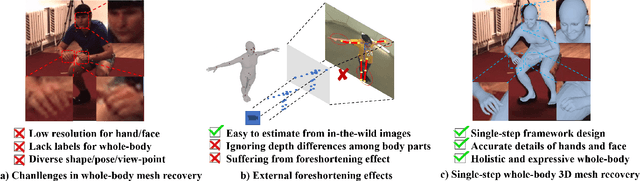
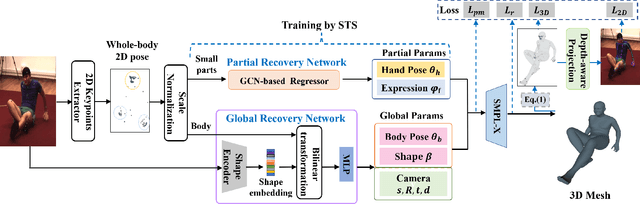
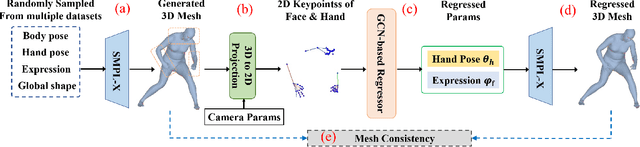
Recovering 3D human mesh from monocular images is a popular topic in computer vision and has a wide range of applications. This paper aims to estimate 3D mesh of multiple body parts (e.g., body, hands) with large-scale differences from a single RGB image. Existing methods are mostly based on iterative optimization, which is very time-consuming. We propose to train a single-shot model to achieve this goal. The main challenge is lacking training data that have complete 3D annotations of all body parts in 2D images. To solve this problem, we design a multi-branch framework to disentangle the regression of different body properties, enabling us to separate each component's training in a synthetic training manner using unpaired data available. Besides, to strengthen the generalization ability, most existing methods have used in-the-wild 2D pose datasets to supervise the estimated 3D pose via 3D-to-2D projection. However, we observe that the commonly used weak-perspective model performs poorly in dealing with the external foreshortening effect of camera projection. Therefore, we propose a depth-to-scale (D2S) projection to incorporate the depth difference into the projection function to derive per-joint scale variants for more proper supervision. The proposed method outperforms previous methods on the CMU Panoptic Studio dataset according to the evaluation results and achieves comparable results on the Human3.6M body and STB hand benchmarks. More impressively, the performance in close shot images gets significantly improved using the proposed D2S projection for weak supervision, while maintains obvious superiority in computational efficiency.
Joint Contrastive Learning with Infinite Possibilities
Oct 10, 2020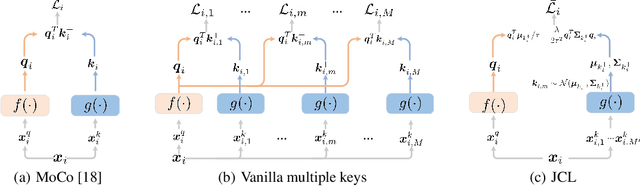
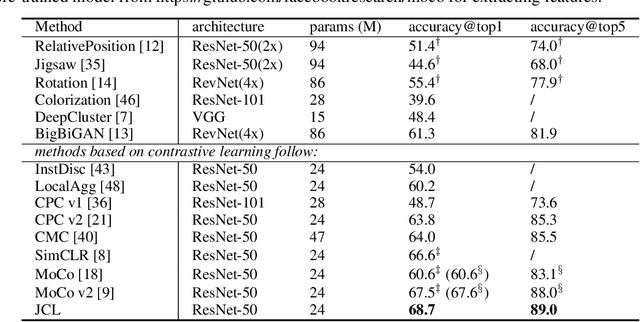
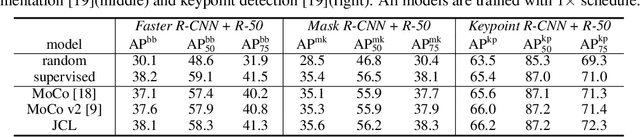
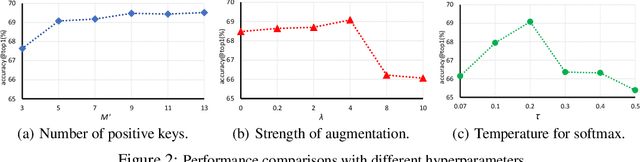
This paper explores useful modifications of the recent development in contrastive learning via novel probabilistic modeling. We derive a particular form of contrastive loss named Joint Contrastive Learning (JCL). JCL implicitly involves the simultaneous learning of an infinite number of query-key pairs, which poses tighter constraints when searching for invariant features. We derive an upper bound on this formulation that allows analytical solutions in an end-to-end training manner. While JCL is practically effective in numerous computer vision applications, we also theoretically unveil the certain mechanisms that govern the behavior of JCL. We demonstrate that the proposed formulation harbors an innate agency that strongly favors similarity within each instance-specific class, and therefore remains advantageous when searching for discriminative features among distinct instances. We evaluate these proposals on multiple benchmarks, demonstrating considerable improvements over existing algorithms. Code is publicly available at: https://github.com/caiqi/Joint-Contrastive-Learning.
The Elements of End-to-end Deep Face Recognition: A Survey of Recent Advances
Sep 28, 2020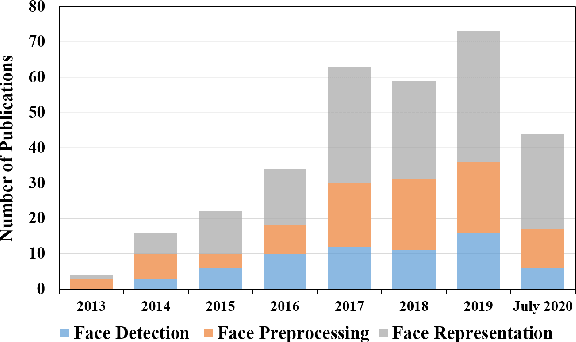
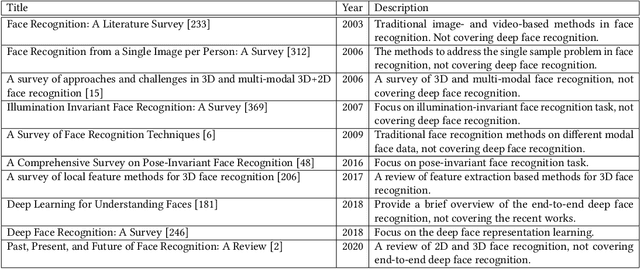
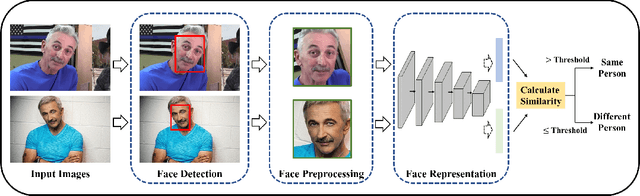
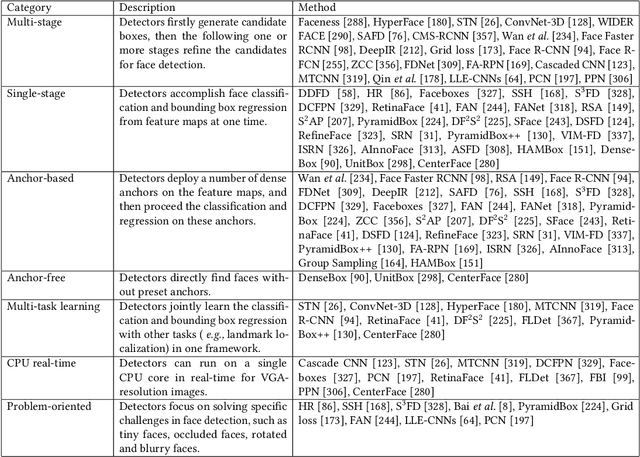
Face recognition is one of the most fundamental and long-standing topics in computer vision community. With the recent developments of deep convolutional neural networks and large-scale datasets, deep face recognition has made remarkable progress and been widely used in the real-world applications. Given a natural image or video frame as input, an end-to-end deep face recognition system outputs the face feature for recognition. To achieve this, the whole system is generally built with three key elements: face detection, face preprocessing, and face representation. The face detection locates faces in the image or frame. Then, the face preprocessing is proceeded to calibrate the faces to a canonical view and crop them to a normalized pixel size. Finally, in the stage of face representation, the discriminative features are extracted from the preprocessed faces for recognition. All of the three elements are fulfilled by deep convolutional neural networks. In this paper, we present a comprehensive survey about the recent advances of every element of the end-to-end deep face recognition, since the thriving deep learning techniques have greatly improved the capability of them. To start with, we introduce an overview of the end-to-end deep face recognition, which, as mentioned above, includes face detection, face preprocessing, and face representation. Then, we review the deep learning based advances of each element, respectively, covering many aspects such as the up-to-date algorithm designs, evaluation metrics, datasets, performance comparison, existing challenges, and promising directions for future research. We hope this survey could bring helpful thoughts to one for better understanding of the big picture of end-to-end face recognition and deeper exploration in a systematic way.
Learning to Localize Actions from Moments
Aug 31, 2020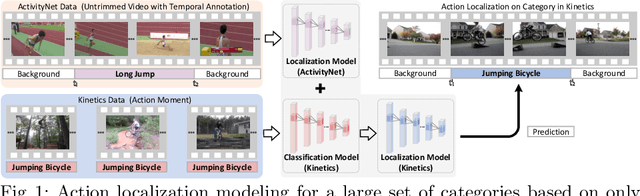
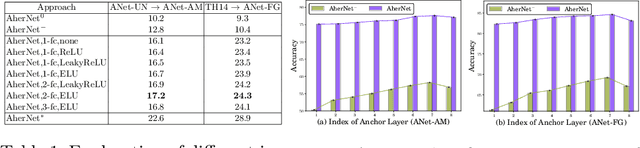
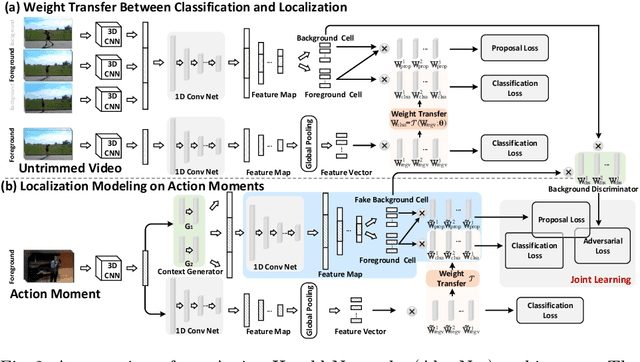
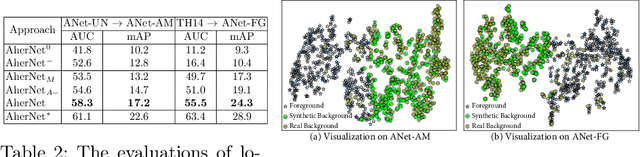
With the knowledge of action moments (i.e., trimmed video clips that each contains an action instance), humans could routinely localize an action temporally in an untrimmed video. Nevertheless, most practical methods still require all training videos to be labeled with temporal annotations (action category and temporal boundary) and develop the models in a fully-supervised manner, despite expensive labeling efforts and inapplicable to new categories. In this paper, we introduce a new design of transfer learning type to learn action localization for a large set of action categories, but only on action moments from the categories of interest and temporal annotations of untrimmed videos from a small set of action classes. Specifically, we present Action Herald Networks (AherNet) that integrate such design into an one-stage action localization framework. Technically, a weight transfer function is uniquely devised to build the transformation between classification of action moments or foreground video segments and action localization in synthetic contextual moments or untrimmed videos. The context of each moment is learnt through the adversarial mechanism to differentiate the generated features from those of background in untrimmed videos. Extensive experiments are conducted on the learning both across the splits of ActivityNet v1.3 and from THUMOS14 to ActivityNet v1.3. Our AherNet demonstrates the superiority even comparing to most fully-supervised action localization methods. More remarkably, we train AherNet to localize actions from 600 categories on the leverage of action moments in Kinetics-600 and temporal annotations from 200 classes in ActivityNet v1.3. Source code and data are available at \url{https://github.com/FuchenUSTC/AherNet}.
CenterHMR: a Bottom-up Single-shot Method for Multi-person 3D Mesh Recovery from a Single Image
Aug 27, 2020
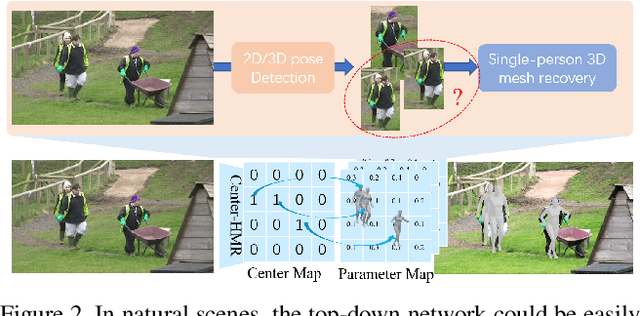
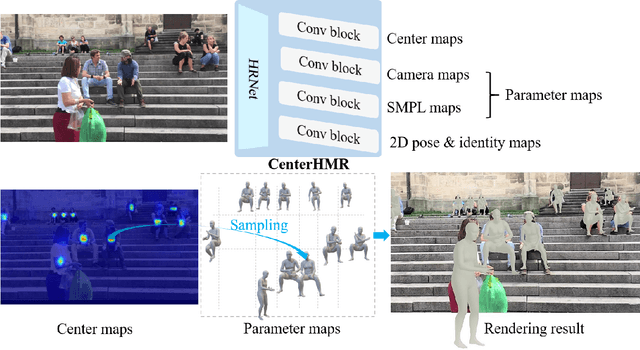

In this paper, we propose a method to recover multi-person 3D mesh from a single image. Existing methods follow a multi-stage detection-based pipeline, where the 3D mesh of each person is regressed from the cropped image patch. They have to suffer from the high complexity of the multi-stage process and the ambiguity of the image-level features. For example, it is hard for them to estimate multi-person 3D mesh from the inseparable crowded cases. Instead, in this paper, we present a novel bottom-up single-shot method, Center-based Human Mesh Recovery network (CenterHMR). The model is trained to simultaneously predict two maps, which represent the location of each human body center and the corresponding parameter vector of 3D human mesh at each center. This explicit center-based representation guarantees the pixel-level feature encoding. Besides, the 3D mesh result of each person is estimated from the features centered at the visible body parts, which improves the robustness under occlusion. CenterHMR surpasses previous methods on multi-person in-the-wild benchmark 3DPW and occlusion dataset 3DOH50K. Besides, CenterHMR has achieved a 2-nd place on ECCV 2020 3DPW Challenge. The code is released on https://github.com/Arthur151/CenterHMR.
Black Re-ID: A Head-shoulder Descriptor for the Challenging Problem of Person Re-Identification
Aug 19, 2020

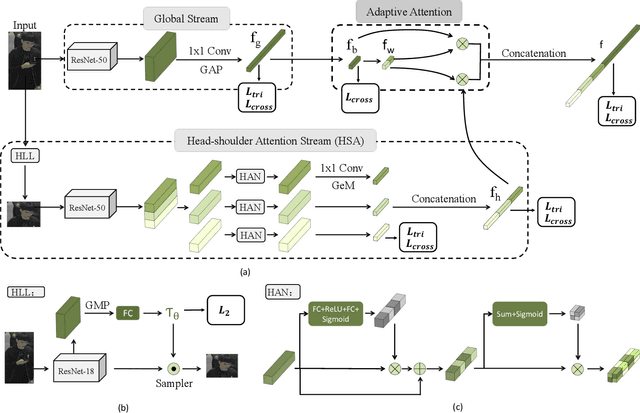
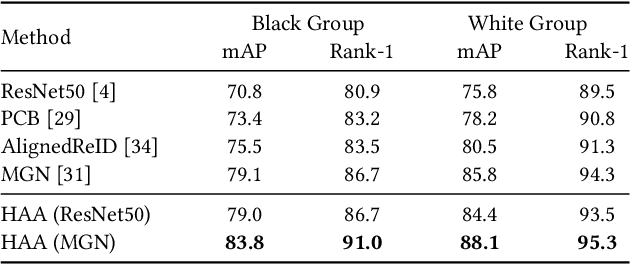
Person re-identification (Re-ID) aims at retrieving an input person image from a set of images captured by multiple cameras. Although recent Re-ID methods have made great success, most of them extract features in terms of the attributes of clothing (e.g., color, texture). However, it is common for people to wear black clothes or be captured by surveillance systems in low light illumination, in which cases the attributes of the clothing are severely missing. We call this problem the Black Re-ID problem. To solve this problem, rather than relying on the clothing information, we propose to exploit head-shoulder features to assist person Re-ID. The head-shoulder adaptive attention network (HAA) is proposed to learn the head-shoulder feature and an innovative ensemble method is designed to enhance the generalization of our model. Given the input person image, the ensemble method would focus on the head-shoulder feature by assigning a larger weight if the individual insides the image is in black clothing. Due to the lack of a suitable benchmark dataset for studying the Black Re-ID problem, we also contribute the first Black-reID dataset, which contains 1274 identities in training set. Extensive evaluations on the Black-reID, Market1501 and DukeMTMC-reID datasets show that our model achieves the best result compared with the state-of-the-art Re-ID methods on both Black and conventional Re-ID problems. Furthermore, our method is also proved to be effective in dealing with person Re-ID in similar clothing. Our code and dataset are avaliable on https://github.com/xbq1994/.
SeCo: Exploring Sequence Supervision for Unsupervised Representation Learning
Aug 03, 2020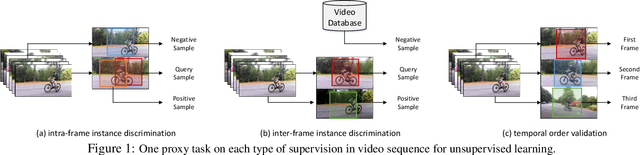
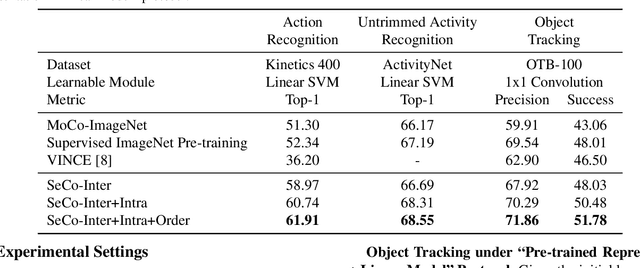
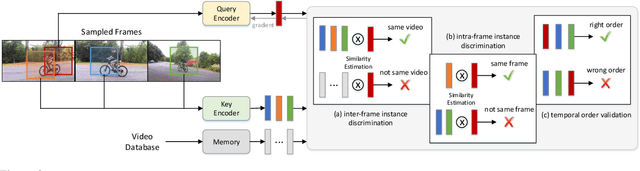
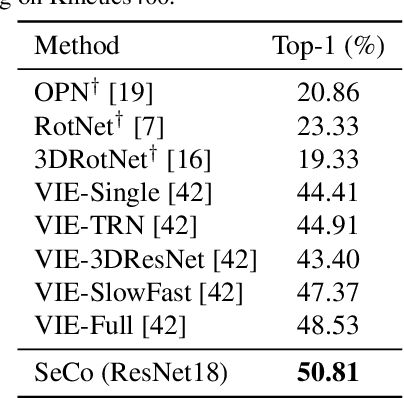
A steady momentum of innovations and breakthroughs has convincingly pushed the limits of unsupervised image representation learning. Compared to static 2D images, video has one more dimension (time). The inherent supervision existing in such sequential structure offers a fertile ground for building unsupervised learning models. In this paper, we compose a trilogy of exploring the basic and generic supervision in the sequence from spatial, spatiotemporal and sequential perspectives. We materialize the supervisory signals through determining whether a pair of samples is from one frame or from one video, and whether a triplet of samples is in the correct temporal order. We uniquely regard the signals as the foundation in contrastive learning and derive a particular form named Sequence Contrastive Learning (SeCo). SeCo shows superior results under the linear protocol on action recognition (Kinetics), untrimmed activity recognition (ActivityNet) and object tracking (OTB-100). More remarkably, SeCo demonstrates considerable improvements over recent unsupervised pre-training techniques, and leads the accuracy by 2.96% and 6.47% against fully-supervised ImageNet pre-training in action recognition task on UCF101 and HMDB51, respectively.
Pre-training for Video Captioning Challenge 2020 Summary
Jul 27, 2020
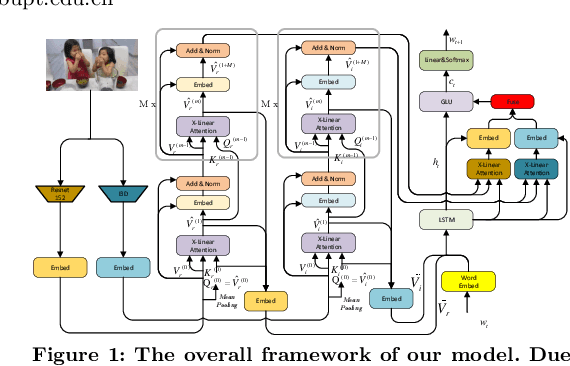
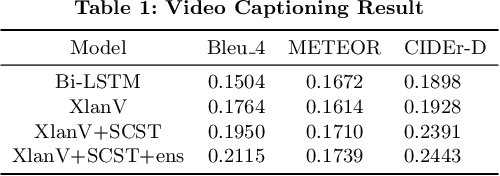
The Pre-training for Video Captioning Challenge 2020 Summary: results and challenge participants' technical reports.
Edge-aware Graph Representation Learning and Reasoning for Face Parsing
Jul 22, 2020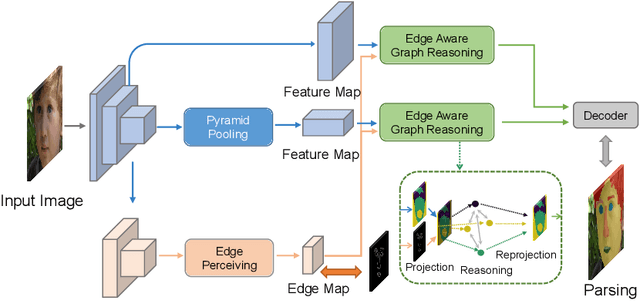
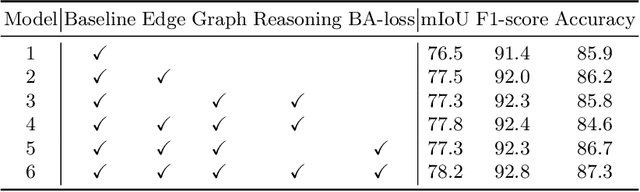
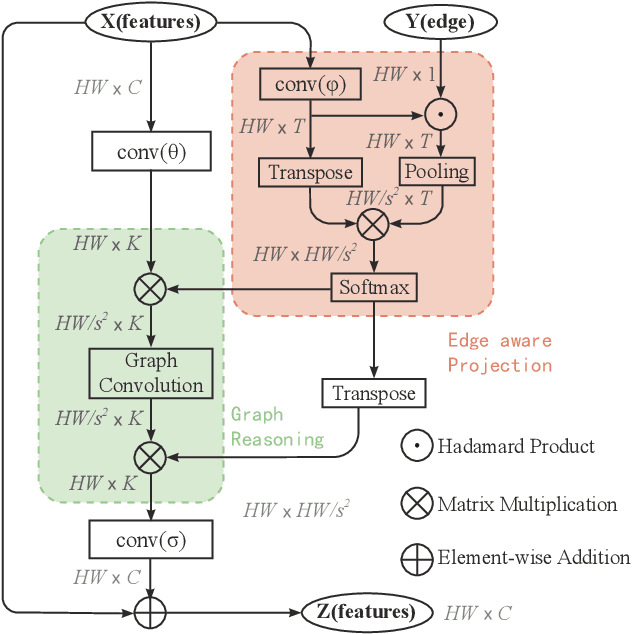

Face parsing infers a pixel-wise label to each facial component, which has drawn much attention recently. Previous methods have shown their efficiency in face parsing, which however overlook the correlation among different face regions. The correlation is a critical clue about the facial appearance, pose, expression etc., and should be taken into account for face parsing. To this end, we propose to model and reason the region-wise relations by learning graph representations, and leverage the edge information between regions for optimized abstraction. Specifically, we encode a facial image onto a global graph representation where a collection of pixels ("regions") with similar features are projected to each vertex. Our model learns and reasons over relations between the regions by propagating information across vertices on the graph. Furthermore, we incorporate the edge information to aggregate the pixel-wise features onto vertices, which emphasizes on the features around edges for fine segmentation along edges. The finally learned graph representation is projected back to pixel grids for parsing. Experiments demonstrate that our model outperforms state-of-the-art methods on the widely used Helen dataset, and also exhibits the superior performance on the large-scale CelebAMask-HQ and LaPa dataset. The code is available at https://github.com/tegusi/EAGRNet.