 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent Advances in Monocular 2D and 3D Human Pose Estimation: A Deep Learning Perspective
Apr 23, 2021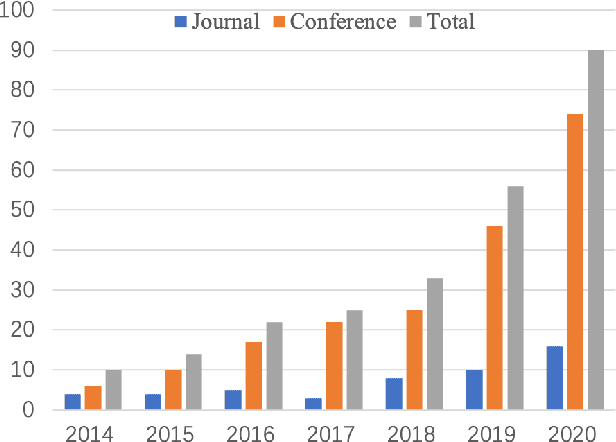
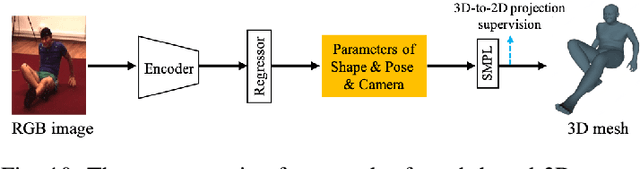

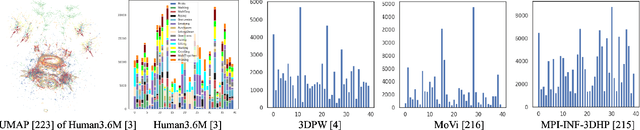
Estimation of the human pose from a monocular camera has been an emerging research topic in the computer vision community with many applications. Recently, benefited from the deep learning technologies, a significant amount of research efforts have greatly advanced the monocular human pose estimation both in 2D and 3D areas. Although there have been some works to summarize the different approaches, it still remains challenging for researchers to have an in-depth view of how these approaches work. In this paper, we provide a comprehensive and holistic 2D-to-3D perspective to tackle this problem. We categorize the mainstream and milestone approaches since the year 2014 under unified frameworks. By systematically summarizing the differences and connections between these approaches, we further analyze the solutions for challenging cases, such as the lack of data, the inherent ambiguity between 2D and 3D, and the complex multi-person scenarios. We also summarize the pose representation styles, benchmarks, evaluation metrics, and the quantitative performance of popular approaches. Finally, we discuss the challenges and give deep thinking of promising directions for future research. We believe this survey will provide the readers with a deep and insightful understanding of monocular human pose estimation.
Towards NIR-VIS Masked Face Recognition
Apr 14, 2021
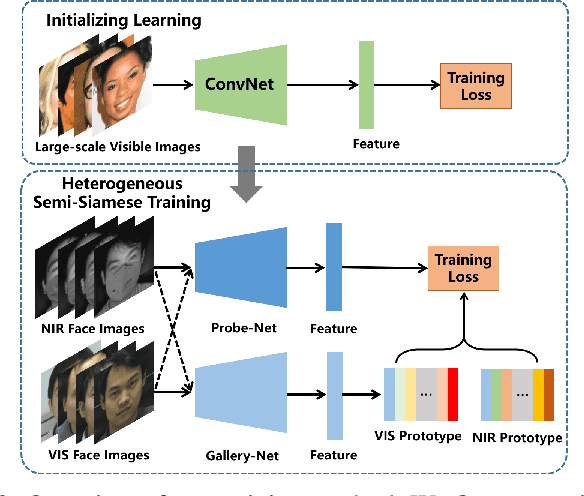
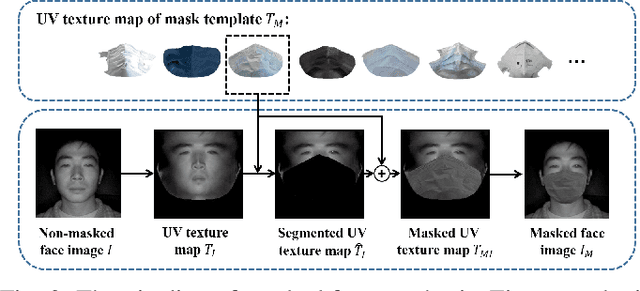

Near-infrared to visible (NIR-VIS) face recognition is the most common case in heterogeneous face recognition, which aims to match a pair of face images captured from two different modalities. Existing deep learning based methods have made remarkable progress in NIR-VIS face recognition, while it encounters certain newly-emerged difficulties during the pandemic of COVID-19, since people are supposed to wear facial masks to cut off the spread of the virus. We define this task as NIR-VIS masked face recognition, and find it problematic with the masked face in the NIR probe image. First, the lack of masked face data is a challenging issue for the network training. Second, most of the facial parts (cheeks, mouth, nose etc.) are fully occluded by the mask, which leads to a large amount of loss of information. Third, the domain gap still exists in the remaining facial parts. In such scenario, the existing methods suffer from significant performance degradation caused by the above issues. In this paper, we aim to address the challenge of NIR-VIS masked face recognition from the perspectives of training data and training method. Specifically, we propose a novel heterogeneous training method to maximize the mutual information shared by the face representation of two domains with the help of semi-siamese networks. In addition, a 3D face reconstruction based approach is employed to synthesize masked face from the existing NIR image. Resorting to these practices, our solution provides the domain-invariant face representation which is also robust to the mask occlusion. Extensive experiments on three NIR-VIS face datasets demonstrate the effectiveness and cross-dataset-generalization capacity of our method.
Exploiting Relationship for Complex-scene Image Generation
Apr 01, 2021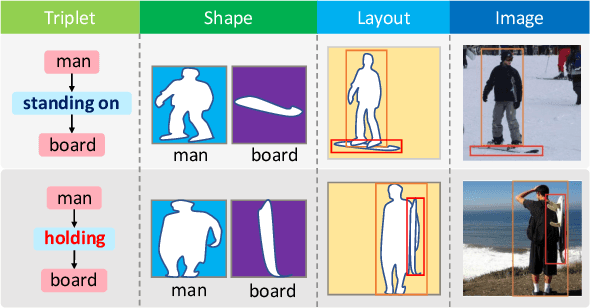
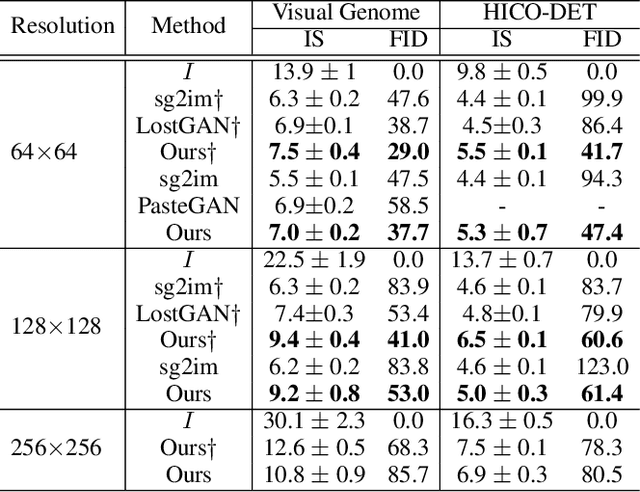
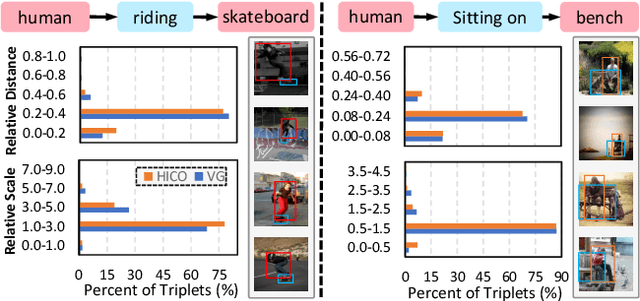

The significant progress on Generative Adversarial Networks (GANs) has facilitated realistic single-object image generation based on language input. However, complex-scene generation (with various interactions among multiple objects) still suffers from messy layouts and object distortions, due to diverse configurations in layouts and appearances. Prior methods are mostly object-driven and ignore their inter-relations that play a significant role in complex-scene images. This work explores relationship-aware complex-scene image generation, where multiple objects are inter-related as a scene graph. With the help of relationships, we propose three major updates in the generation framework. First, reasonable spatial layouts are inferred by jointly considering the semantics and relationships among objects. Compared to standard location regression, we show relative scales and distances serve a more reliable target. Second, since the relations between objects significantly influence an object's appearance, we design a relation-guided generator to generate objects reflecting their relationships. Third, a novel scene graph discriminator is proposed to guarantee the consistency between the generated image and the input scene graph. Our method tends to synthesize plausible layouts and objects, respecting the interplay of multiple objects in an image. Experimental results on Visual Genome and HICO-DET datasets show that our proposed method significantly outperforms prior arts in terms of IS and FID metrics. Based on our user study and visual inspection, our method is more effective in generating logical layout and appearance for complex-scenes.
Dive into Ambiguity: Latent Distribution Mining and Pairwise Uncertainty Estimation for Facial Expression Recognition
Apr 01, 2021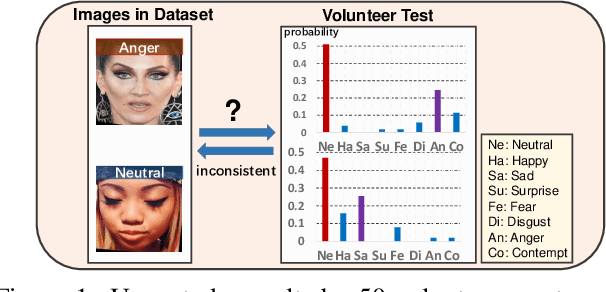
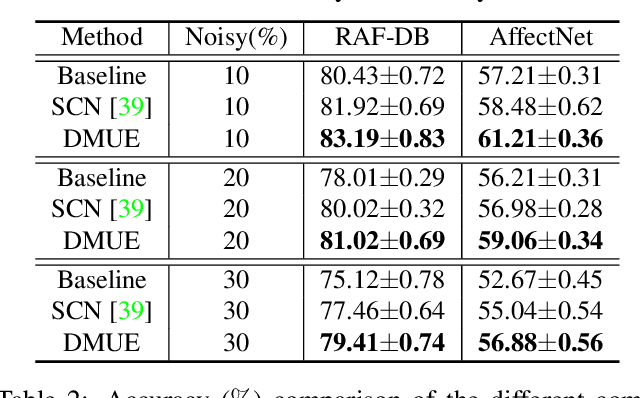
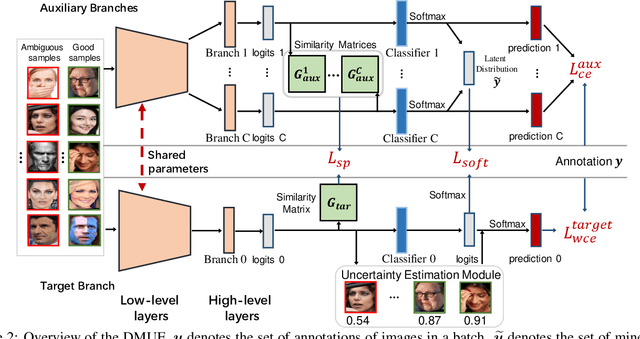
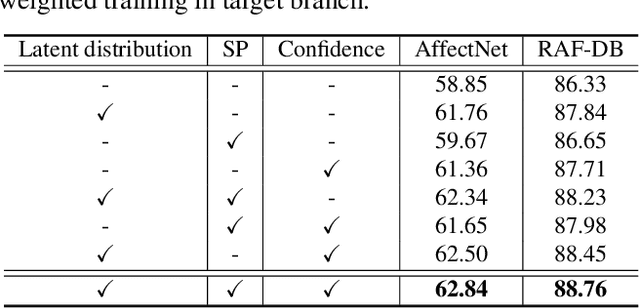
Due to the subjective annotation and the inherent interclass similarity of facial expressions, one of key challenges in Facial Expression Recognition (FER) is the annotation ambiguity. In this paper, we proposes a solution, named DMUE, to address the problem of annotation ambiguity from two perspectives: the latent Distribution Mining and the pairwise Uncertainty Estimation. For the former, an auxiliary multi-branch learning framework is introduced to better mine and describe the latent distribution in the label space. For the latter, the pairwise relationship of semantic feature between instances are fully exploited to estimate the ambiguity extent in the instance space. The proposed method is independent to the backbone architectures, and brings no extra burden for inference. The experiments are conducted on the popular real-world benchmarks and the synthetic noisy datasets. Either way, the proposed DMUE stably achieves leading performance.
Group-aware Label Transfer for Domain Adaptive Person Re-identification
Mar 23, 2021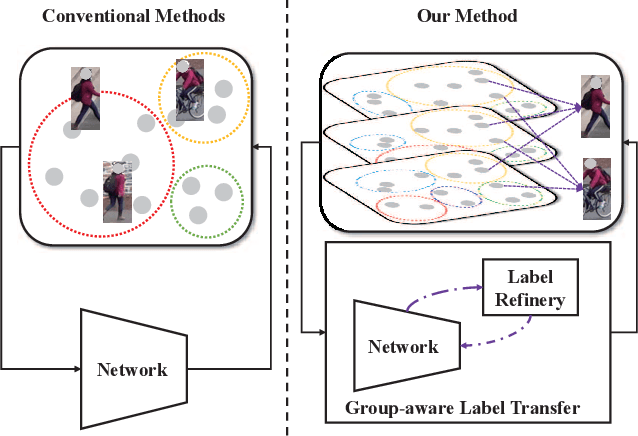
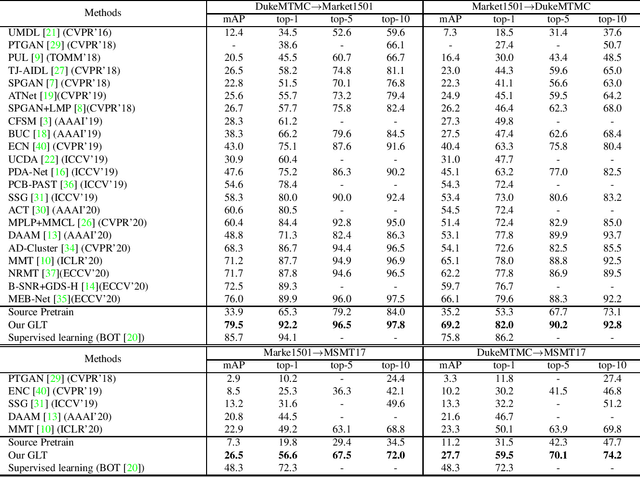
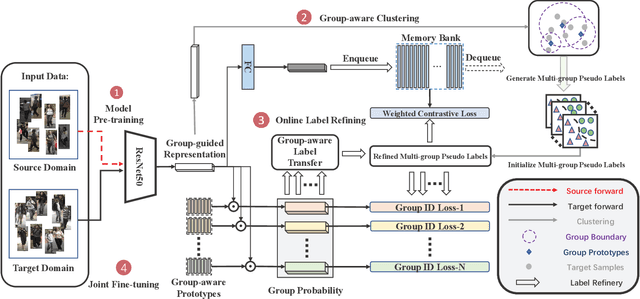
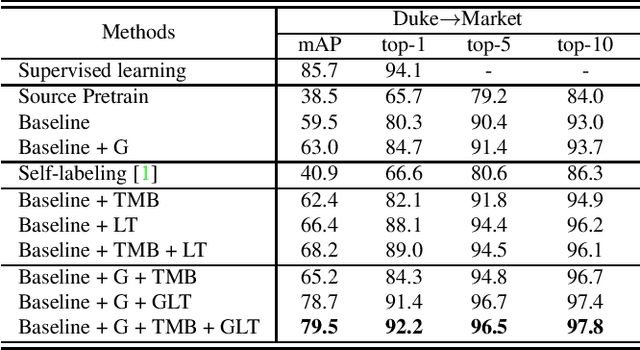
Unsupervised Domain Adaptive (UDA) person re-identification (ReID) aims at adapting the model trained on a labeled source-domain dataset to a target-domain dataset without any further annotations. Most successful UDA-ReID approaches combine clustering-based pseudo-label prediction with representation learning and perform the two steps in an alternating fashion. However, offline interaction between these two steps may allow noisy pseudo labels to substantially hinder the capability of the model. In this paper, we propose a Group-aware Label Transfer (GLT) algorithm, which enables the online interaction and mutual promotion of pseudo-label prediction and representation learning. Specifically, a label transfer algorithm simultaneously uses pseudo labels to train the data while refining the pseudo labels as an online clustering algorithm. It treats the online label refinery problem as an optimal transport problem, which explores the minimum cost for assigning M samples to N pseudo labels. More importantly, we introduce a group-aware strategy to assign implicit attribute group IDs to samples. The combination of the online label refining algorithm and the group-aware strategy can better correct the noisy pseudo label in an online fashion and narrow down the search space of the target identity. The effectiveness of the proposed GLT is demonstrated by the experimental results (Rank-1 accuracy) for Market1501$\to$DukeMTMC (82.0\%) and DukeMTMC$\to$Market1501 (92.2\%), remarkably closing the gap between unsupervised and supervised performance on person re-identification.
AttriMeter: An Attribute-guided Metric Interpreter for Person Re-Identification
Mar 02, 2021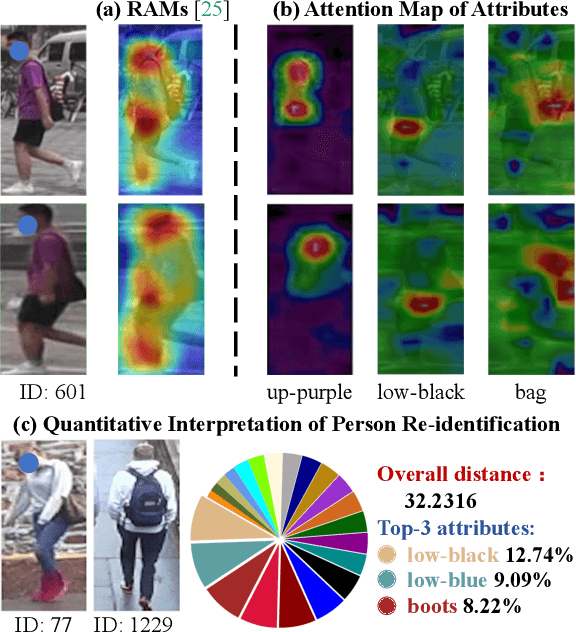

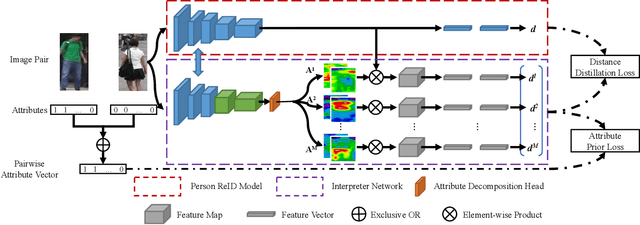
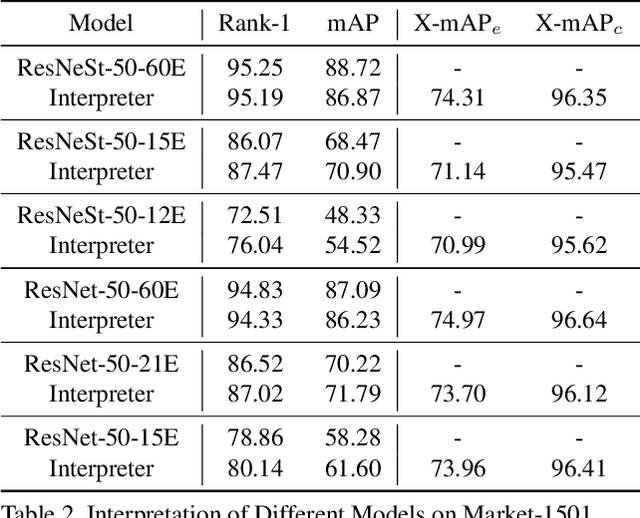
Person Re-identification (ReID) has achieved significant improvement due to the adoption of Convolutional Neural Networks (CNNs). However, person ReID systems only provide a distance or similarity when matching two persons, which makes users hardly understand why they are similar or not. Therefore, we propose an Attribute-guided Metric Interpreter, named AttriMeter, to semantically and quantitatively explain the results of CNN-based ReID models. The AttriMeter has a pluggable structure that can be grafted on arbitrary target models, i.e., the ReID models that need to be interpreted. With an attribute decomposition head, it can learn to generate a group of attribute-guided attention maps (AAMs) from the target model. By applying AAMs to features of two persons from the target model, their distance will be decomposed into a set of attribute-guided components that can measure the contributions of individual attributes. Moreover, we design a distance distillation loss to guarantee the consistency between the results from the target model and the decomposed components from AttriMeter, and an attribute prior loss to eliminate the biases caused by the unbalanced distribution of attributes. Finally, extensive experiments and analysis on a variety of ReID models and datasets show the effectiveness of AttriMeter.
TraND: Transferable Neighborhood Discovery for Unsupervised Cross-domain Gait Recognition
Feb 09, 2021
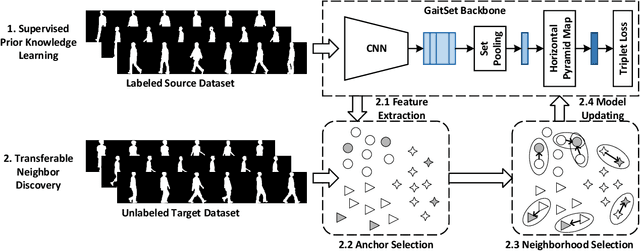
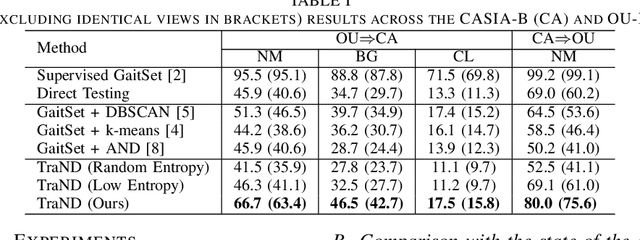
Gait, i.e., the movement pattern of human limbs during locomotion, is a promising biometric for the identification of persons. Despite significant improvement in gait recognition with deep learning, existing studies still neglect a more practical but challenging scenario -- unsupervised cross-domain gait recognition which aims to learn a model on a labeled dataset then adapts it to an unlabeled dataset. Due to the domain shift and class gap, directly applying a model trained on one source dataset to other target datasets usually obtains very poor results. Therefore, this paper proposes a Transferable Neighborhood Discovery (TraND) framework to bridge the domain gap for unsupervised cross-domain gait recognition. To learn effective prior knowledge for gait representation, we first adopt a backbone network pre-trained on the labeled source data in a supervised manner. Then we design an end-to-end trainable approach to automatically discover the confident neighborhoods of unlabeled samples in the latent space. During training, the class consistency indicator is adopted to select confident neighborhoods of samples based on their entropy measurements. Moreover, we explore a high-entropy-first neighbor selection strategy, which can effectively transfer prior knowledge to the target domain. Our method achieves state-of-the-art results on two public datasets, i.e., CASIA-B and OU-LP.
Scheduled Sampling in Vision-Language Pretraining with Decoupled Encoder-Decoder Network
Jan 27, 2021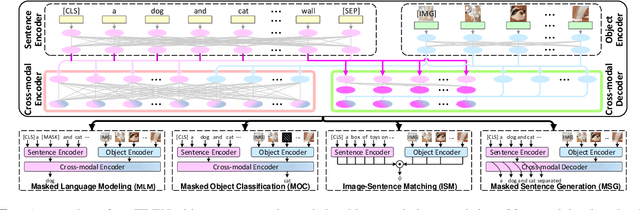
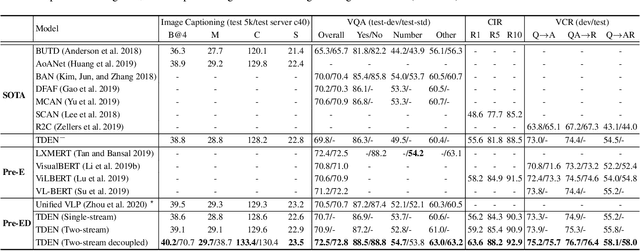

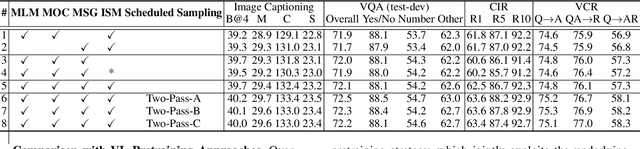
Despite having impressive vision-language (VL) pretraining with BERT-based encoder for VL understanding, the pretraining of a universal encoder-decoder for both VL understanding and generation remains challenging. The difficulty originates from the inherently different peculiarities of the two disciplines, e.g., VL understanding tasks capitalize on the unrestricted message passing across modalities, while generation tasks only employ visual-to-textual message passing. In this paper, we start with a two-stream decoupled design of encoder-decoder structure, in which two decoupled cross-modal encoder and decoder are involved to separately perform each type of proxy tasks, for simultaneous VL understanding and generation pretraining. Moreover, for VL pretraining, the dominant way is to replace some input visual/word tokens with mask tokens and enforce the multi-modal encoder/decoder to reconstruct the original tokens, but no mask token is involved when fine-tuning on downstream tasks. As an alternative, we propose a primary scheduled sampling strategy that elegantly mitigates such discrepancy via pretraining encoder-decoder in a two-pass manner. Extensive experiments demonstrate the compelling generalizability of our pretrained encoder-decoder by fine-tuning on four VL understanding and generation downstream tasks. Source code is available at \url{https://github.com/YehLi/TDEN}.
CM-NAS: Rethinking Cross-Modality Neural Architectures for Visible-Infrared Person Re-Identification
Jan 21, 2021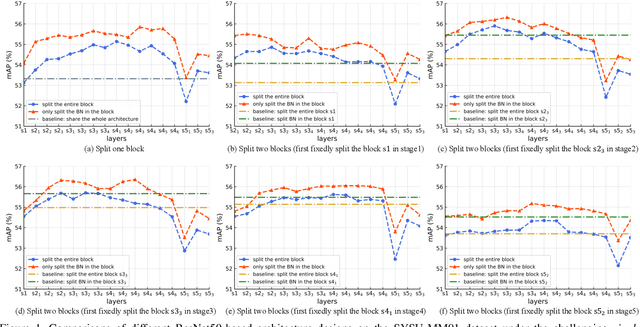
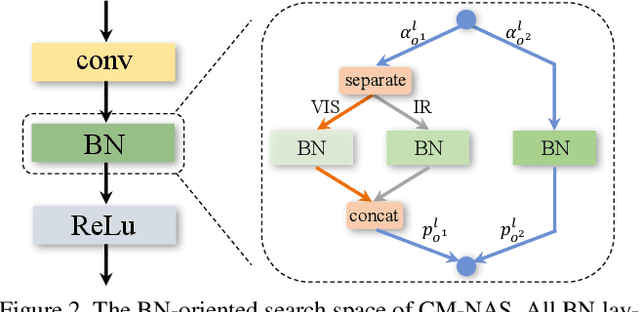
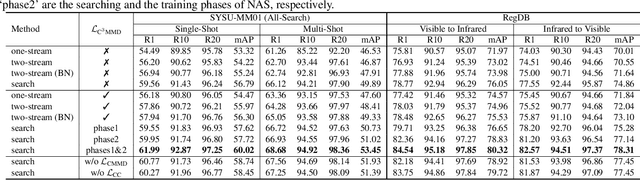
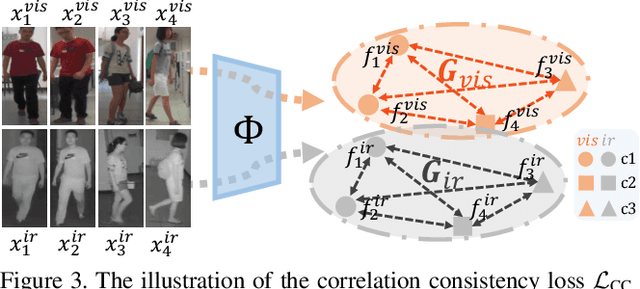
Visible-Infrared person re-identification (VI-ReID) aims at matching cross-modality pedestrian images, breaking through the limitation of single-modality person ReID in dark environment. In order to mitigate the impact of large modality discrepancy, existing works manually design various two-stream architectures to separately learn modality-specific and modality-sharable representations. Such a manual design routine, however, highly depends on massive experiments and empirical practice, which is time consuming and labor intensive. In this paper, we systematically study the manually designed architectures, and identify that appropriately splitting Batch Normalization (BN) layers to learn modality-specific representations will bring a great boost towards cross-modality matching. Based on this observation, the essential objective is to find the optimal splitting scheme for each BN layer. To this end, we propose a novel method, named Cross-Modality Neural Architecture Search (CM-NAS). It consists of a BN-oriented search space in which the standard optimization can be fulfilled subject to the cross-modality task. Besides, in order to better guide the search process, we further formulate a new Correlation Consistency based Class-specific Maximum Mean Discrepancy (C3MMD) loss. Apart from the modality discrepancy, it also concerns the similarity correlations, which have been overlooked before, in the two modalities. Resorting to these advantages, our method outperforms state-of-the-art counterparts in extensive experiments, improving the Rank-1/mAP by 6.70%/6.13% on SYSU-MM01 and 12.17%/11.23% on RegDB. The source code will be released soon.
Adaptive Graph Representation Learning and Reasoning for Face Parsing
Jan 18, 2021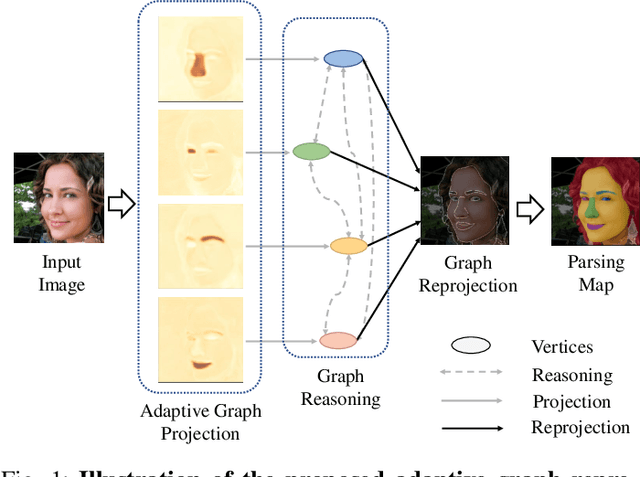
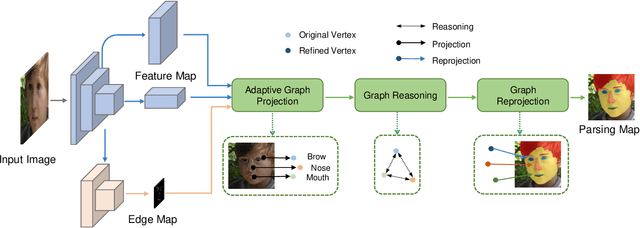

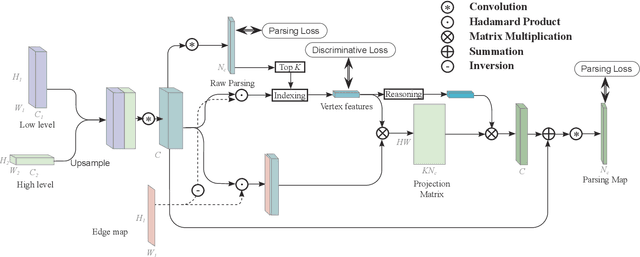
Face parsing infers a pixel-wise label to each facial component, which has drawn much attention recently. Previous methods have shown their success in face parsing, which however overlook the correlation among facial components. As a matter of fact, the component-wise relationship is a critical clue in discriminating ambiguous pixels in facial area. To address this issue, we propose adaptive graph representation learning and reasoning over facial components, aiming to learn representative vertices that describe each component, exploit the component-wise relationship and thereby produce accurate parsing results against ambiguity. In particular, we devise an adaptive and differentiable graph abstraction method to represent the components on a graph via pixel-to-vertex projection under the initial condition of a predicted parsing map, where pixel features within a certain facial region are aggregated onto a vertex. Further, we explicitly incorporate the image edge as a prior in the model, which helps to discriminate edge and non-edge pixels during the projection, thus leading to refined parsing results along the edges. Then, our model learns and reasons over the relations among components by propagating information across vertices on the graph. Finally, the refined vertex features are projected back to pixel grids for the prediction of the final parsing map. To train our model, we propose a discriminative loss to penalize small distances between vertices in the feature space, which leads to distinct vertices with strong semantics. Experimental results show the superior performance of the proposed model on multiple face parsing datasets, along with the validation on the human parsing task to demonstrate the generalizability of our model.