 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation of End-To-End Speaker-Attributed ASR for Continuous Multi-Talker Recordings
Aug 11, 2020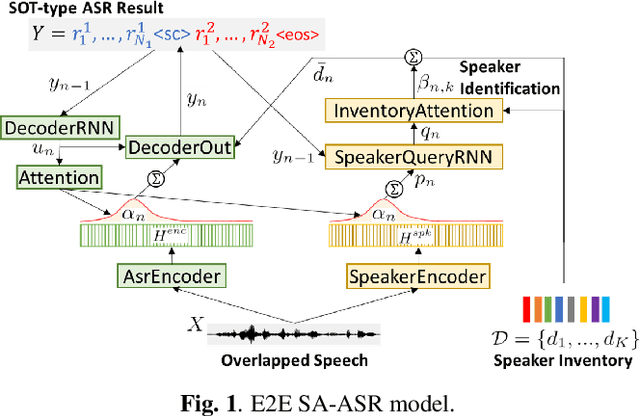
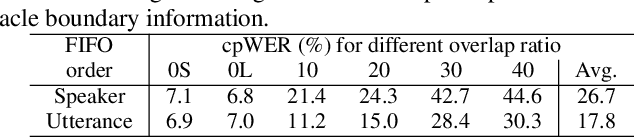
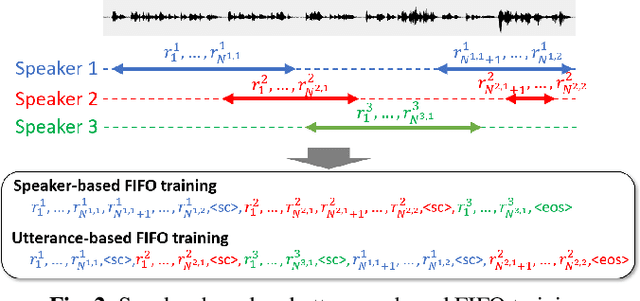
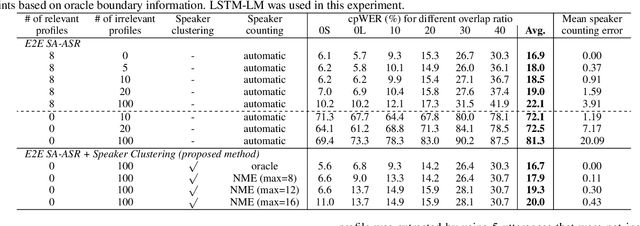
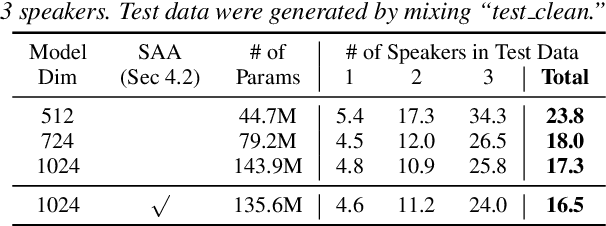
Recently, an end-to-end (E2E) speaker-attributed automatic speech recognition (SA-ASR) model was proposed as a joint model of speaker counting, speech recognition and speaker identification for monaural overlapped speech. It showed promising results for simulated speech mixtures consisting of various numbers of speakers. However, the model required prior knowledge of speaker profiles to perform speaker identification, which significantly limited the application of the model. In this paper, we extend the prior work by addressing the case where no speaker profile is available. Specifically, we perform speaker counting and clustering by using the internal speaker representations of the E2E SA-ASR model to diarize the utterances of the speakers whose profiles are missing from the speaker inventory. We also propose a simple modification to the reference labels of the E2E SA-ASR training which helps handle continuous multi-talker recordings well. We conduct a comprehensive investigation of the original E2E SA-ASR and the proposed method on the monaural LibriCSS dataset. Compared to the original E2E SA-ASR with relevant speaker profiles, the proposed method achieves a close performance without any prior speaker knowledge. We also show that the source-target attention in the E2E SA-ASR model provides information about the start and end times of the hypotheses.
Joint Speaker Counting, Speech Recognition, and Speaker Identification for Overlapped Speech of Any Number of Speakers
Jun 19, 2020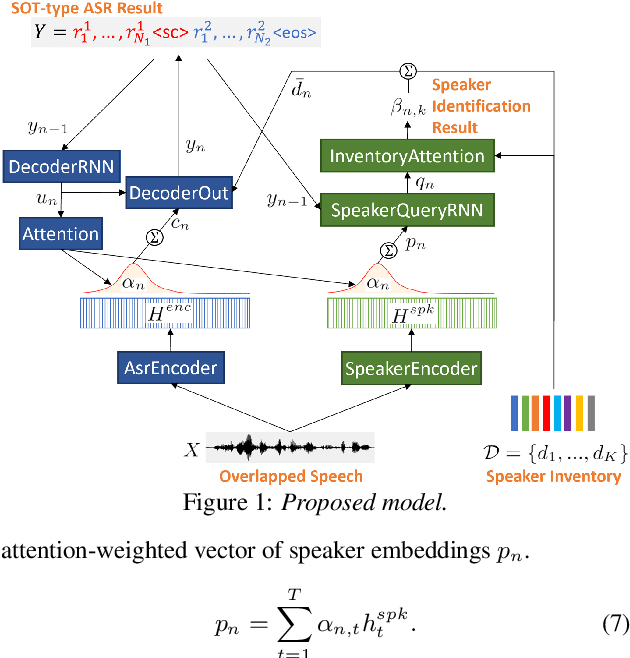
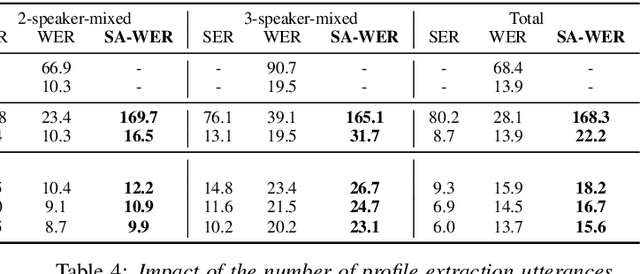
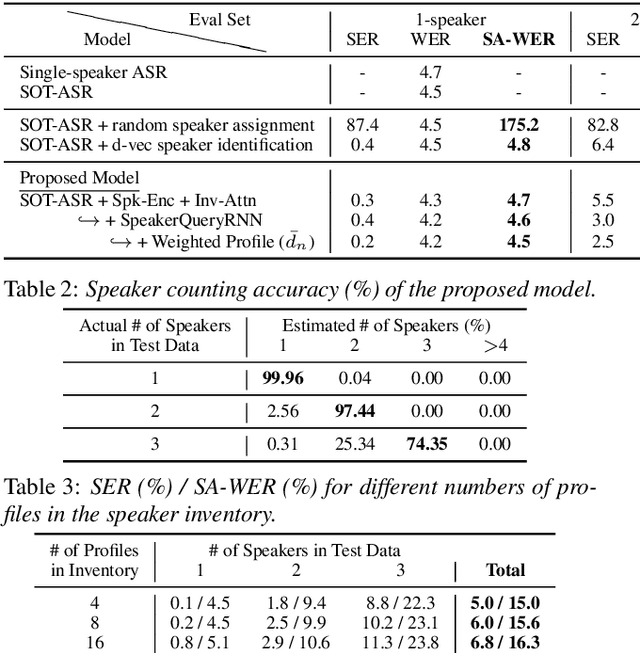
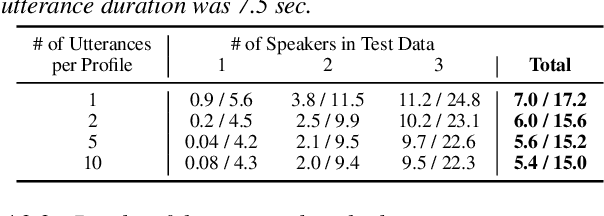
In this paper, we propose a joint model for simultaneous speaker counting, speech recognition, and speaker identification on monaural overlapped speech. Our model is built on serialized output training (SOT) with attention-based encoder-decoder, a recently proposed method for recognizing overlapped speech comprising an arbitrary number of speakers. We extend the SOT model by introducing a speaker inventory as an auxiliary input to produce speaker labels as well as multi-speaker transcriptions. All model parameters are optimized by speaker-attributed maximum mutual information criterion, which represents a joint probability for overlapped speech recognition and speaker identification. Experiments on LibriSpeech corpus show that our proposed method achieves significantly better speaker-attributed word error rate than the baseline that separately performs overlapped speech recognition and speaker identification.
CHiME-6 Challenge:Tackling Multispeaker Speech Recognition for Unsegmented Recordings
May 02, 2020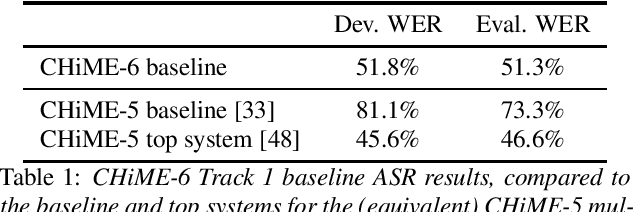

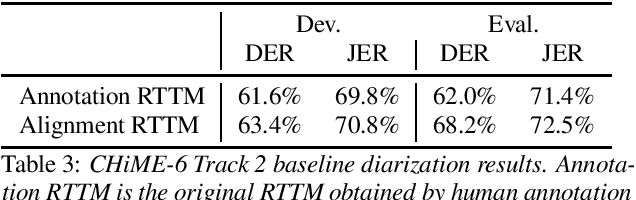

Following the success of the 1st, 2nd, 3rd, 4th and 5th CHiME challenges we organize the 6th CHiME Speech Separation and Recognition Challenge (CHiME-6). The new challenge revisits the previous CHiME-5 challenge and further considers the problem of distant multi-microphone conversational speech diarization and recognition in everyday home environments. Speech material is the same as the previous CHiME-5 recordings except for accurate array synchronization. The material was elicited using a dinner party scenario with efforts taken to capture data that is representative of natural conversational speech. This paper provides a baseline description of the CHiME-6 challenge for both segmented multispeaker speech recognition (Track 1) and unsegmented multispeaker speech recognition (Track 2). Of note, Track 2 is the first challenge activity in the community to tackle an unsegmented multispeaker speech recognition scenario with a complete set of reproducible open source baselines providing speech enhancement, speaker diarization, and speech recognition modules.
Neural Speech Separation Using Spatially Distributed Microphones
Apr 28, 2020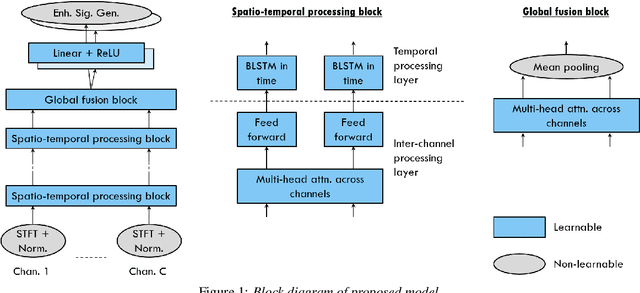
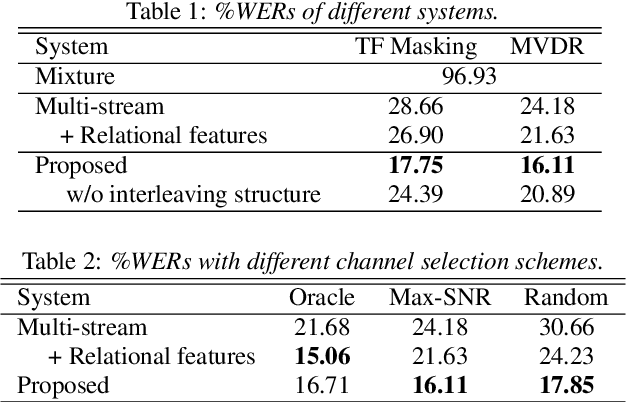
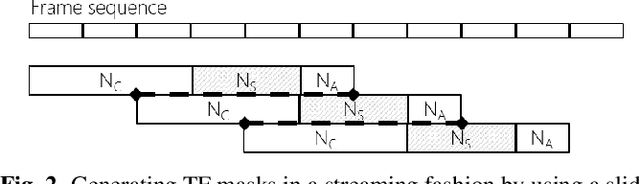
This paper proposes a neural network based speech separation method using spatially distributed microphones. Unlike with traditional microphone array settings, neither the number of microphones nor their spatial arrangement is known in advance, which hinders the use of conventional multi-channel speech separation neural networks based on fixed size input. To overcome this, a novel network architecture is proposed that interleaves inter-channel processing layers and temporal processing layers. The inter-channel processing layers apply a self-attention mechanism along the channel dimension to exploit the information obtained with a varying number of microphones. The temporal processing layers are based on a bidirectional long short term memory (BLSTM) model and applied to each channel independently. The proposed network leverages information across time and space by stacking these two kinds of layers alternately. Our network estimates time-frequency (TF) masks for each speaker, which are then used to generate enhanced speech signals either with TF masking or beamforming. Speech recognition experimental results show that the proposed method significantly outperforms baseline multi-channel speech separation systems.
Serialized Output Training for End-to-End Overlapped Speech Recognition
Mar 28, 2020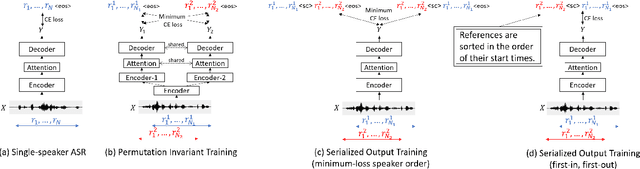
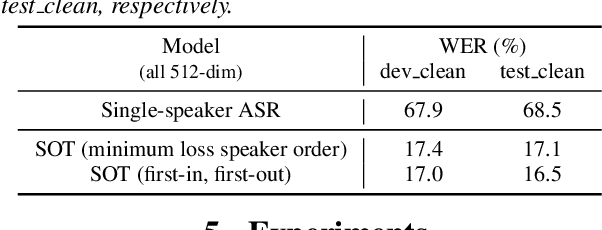
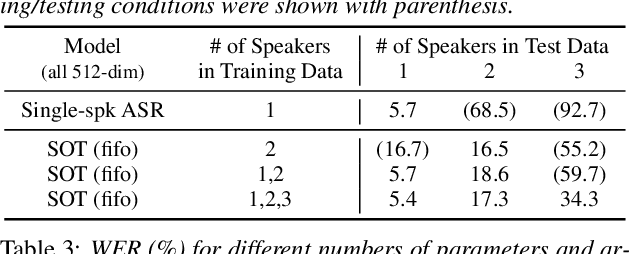
This paper proposes serialized output training (SOT), a novel framework for multi-speaker overlapped speech recognition based on an attention-based encoder-decoder approach. Instead of having multiple output layers as with the permutation invariant training (PIT), SOT uses a model with only one output layer that generates the transcriptions of multiple speakers one after another. The attention and decoder modules take care of producing multiple transcriptions from overlapped speech. SOT has two advantages over PIT: (1) no limitation in the maximum number of speakers, and (2) an ability to model the dependencies among outputs for different speakers. We also propose a simple trick to reduce the complexity of processing each training sample from $O(S!)$ to $O(1)$, where $S$ is the number of the speakers in the training sample, by using the start times of the constituent source utterances. Experimental results on LibriSpeech corpus show that the SOT models can transcribe overlapped speech with variable numbers of speakers significantly better than PIT-based models. We also show that the SOT models can accurately count the number of speakers in the input audio.
Continuous speech separation: dataset and analysis
Jan 30, 2020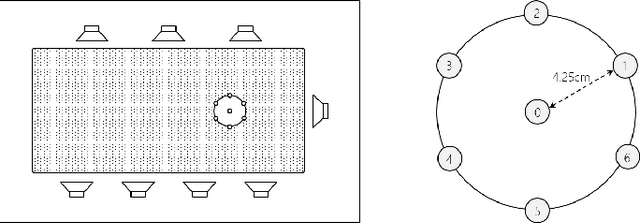
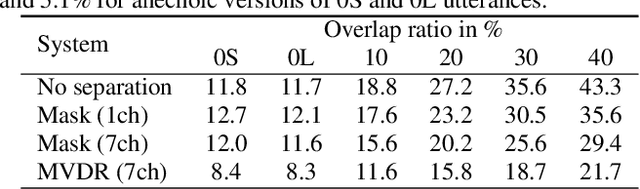
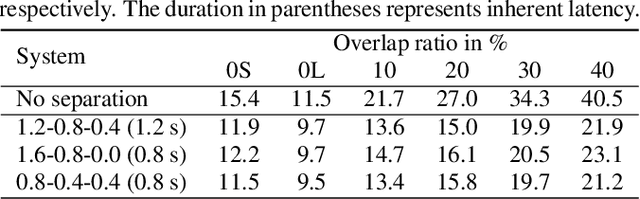
This paper describes a dataset and protocols for evaluating continuous speech separation algorithms. Most prior studies on speech separation use pre-segmented signals of artificially mixed speech utterances which are mostly \emph{fully} overlapped, and the algorithms are evaluated based on signal-to-distortion ratio or similar performance metrics. However, in natural conversations, a speech signal is continuous, containing both overlapped and overlap-free components. In addition, the signal-based metrics have very weak correlations with automatic speech recognition (ASR) accuracy. We think that not only does this make it hard to assess the practical relevance of the tested algorithms, it also hinders researchers from developing systems that can be readily applied to real scenarios. In this paper, we define continuous speech separation (CSS) as a task of generating a set of non-overlapped speech signals from a \textit{continuous} audio stream that contains multiple utterances that are \emph{partially} overlapped by a varying degree. A new real recorded dataset, called LibriCSS, is derived from LibriSpeech by concatenating the corpus utterances to simulate a conversation and capturing the audio replays with far-field microphones. A Kaldi-based ASR evaluation protocol is also established by using a well-trained multi-conditional acoustic model. By using this dataset, several aspects of a recently proposed speaker-independent CSS algorithm are investigated. The dataset and evaluation scripts are available to facilitate the research in this direction.
Advances in Online Audio-Visual Meeting Transcription
Dec 10, 2019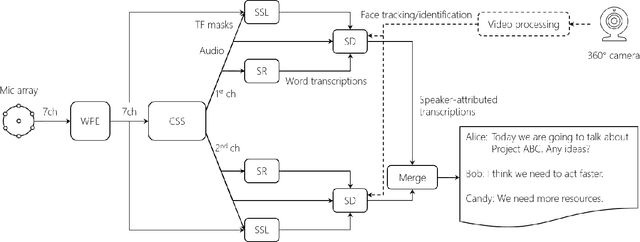

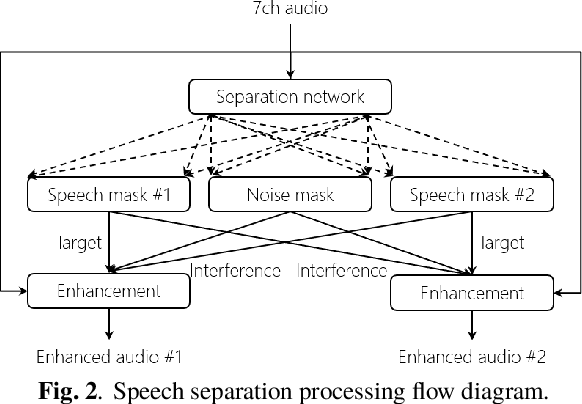
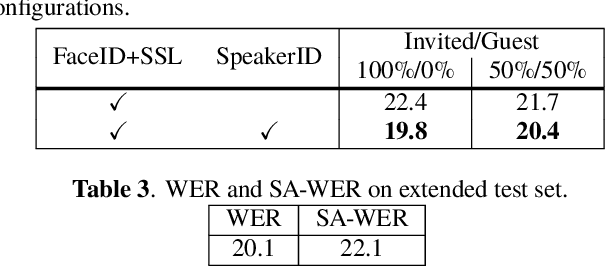
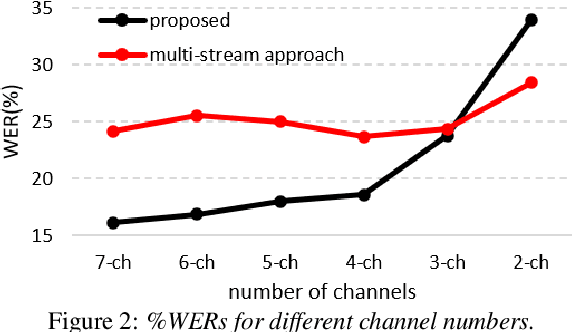
This paper describes a system that generates speaker-annotated transcripts of meetings by using a microphone array and a 360-degree camera. The hallmark of the system is its ability to handle overlapped speech, which has been an unsolved problem in realistic settings for over a decade. We show that this problem can be addressed by using a continuous speech separation approach. In addition, we describe an online audio-visual speaker diarization method that leverages face tracking and identification, sound source localization, speaker identification, and, if available, prior speaker information for robustness to various real world challenges. All components are integrated in a meeting transcription framework called SRD, which stands for "separate, recognize, and diarize". Experimental results using recordings of natural meetings involving up to 11 attendees are reported. The continuous speech separation improves a word error rate (WER) by 16.1% compared with a highly tuned beamformer. When a complete list of meeting attendees is available, the discrepancy between WER and speaker-attributed WER is only 1.0%, indicating accurate word-to-speaker association. This increases marginally to 1.6% when 50% of the attendees are unknown to the system.
End-to-end Microphone Permutation and Number Invariant Multi-channel Speech Separation
Nov 26, 2019
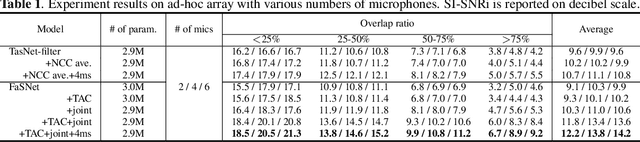
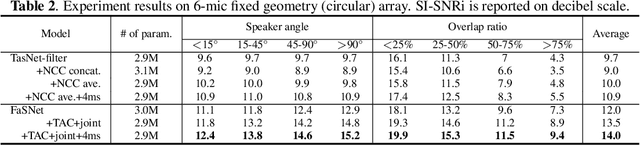
An important problem in ad-hoc microphone speech separation is how to guarantee the robustness of a system with respect to the locations and numbers of microphones. The former requires the system to be invariant to different indexing of the microphones with the same locations, while the latter requires the system to be able to process inputs with varying dimensions. Conventional optimization-based beamforming techniques satisfy these requirements by definition, while for deep learning-based end-to-end systems those constraints are not fully addressed. In this paper, we propose transform-average-concatenate (TAC), a simple design paradigm for channel permutation and number invariant multi-channel speech separation. Based on the filter-and-sum network (FaSNet), a recently proposed end-to-end time-domain beamforming system, we show how TAC significantly improves the separation performance across various numbers of microphones in noisy reverberant separation tasks with ad-hoc arrays. Moreover, we show that TAC also significantly improves the separation performance with fixed geometry array configuration, further proving the effectiveness of the proposed paradigm in the general problem of multi-microphone speech separation.
Dual-path RNN: efficient long sequence modeling for time-domain single-channel speech separation
Oct 14, 2019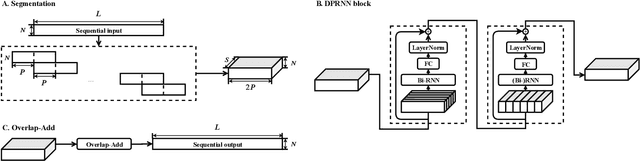
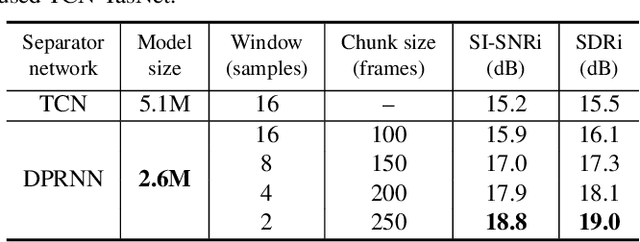
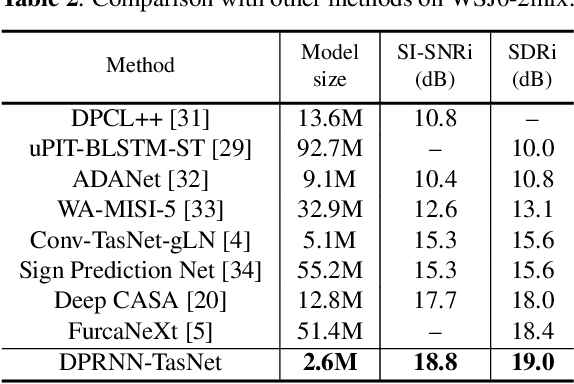
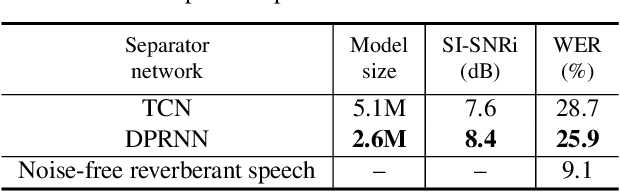
Recent studies in deep learning-based speech separation have proven the superiority of time-domain approaches to conventional time-frequency-based methods. Unlike the time-frequency domain approaches, the time-domain separation systems often receive input sequences consisting of a huge number of time steps, which introduces challenges for modeling extremely long sequences. Conventional recurrent neural networks (RNNs) are not effective for modeling such long sequences due to optimization difficulties, while one-dimensional convolutional neural networks (1-D CNNs) cannot perform utterance-level sequence modeling when its receptive field is smaller than the sequence length. In this paper, we propose dual-path recurrent neural network (DPRNN), a simple yet effective method for organizing RNN layers in a deep structure to model extremely long sequences. DPRNN splits the long sequential input into smaller chunks and applies intra- and inter-chunk operations iteratively, where the input length can be made proportional to the square root of the original sequence length in each operation. Experiments show that by replacing 1-D CNN with DPRNN and apply sample-level modeling in the time-domain audio separation network (TasNet), a new state-of-the-art performance on WSJ0-2mix is achieved with a 20 times smaller model than the previous best system.
DOVER: A Method for Combining Diarization Outputs
Sep 17, 2019
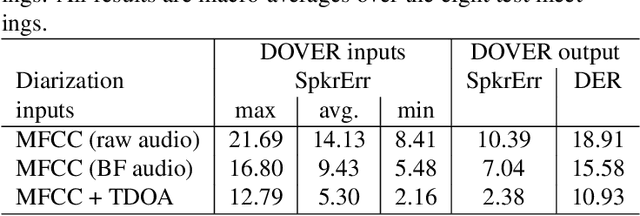
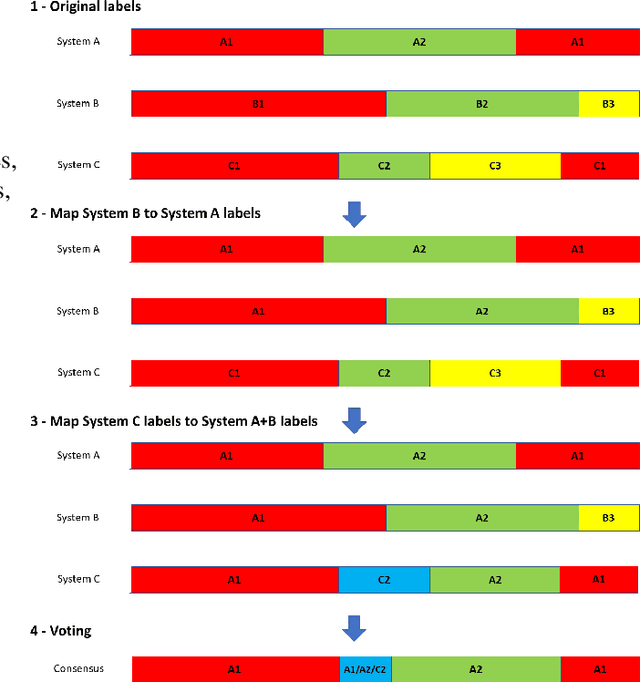
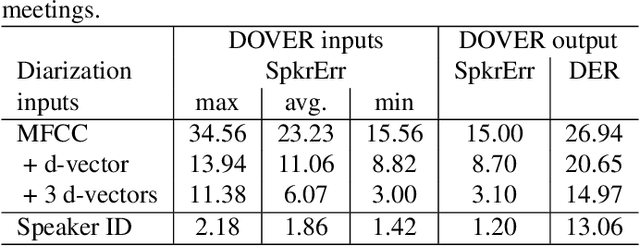
Speech recognition and other natural language tasks have long benefited from voting-based algorithms as a method to aggregate outputs from several systems to achieve a higher accuracy than any of the individual systems. Diarization, the task of segmenting an audio stream into speaker-homogeneous and co-indexed regions, has so far not seen the benefit of this strategy because the structure of the task does not lend itself to a simple voting approach. This paper presents DOVER (diarization output voting error reduction), an algorithm for weighted voting among diarization hypotheses, in the spirit of the ROVER algorithm for combining speech recognition hypotheses. We evaluate the algorithm for diarization of meeting recordings with multiple microphones, and find that it consistently reduces diarization error rate over the average of results from individual channels, and often improves on the single best channel chosen by an oracle.