 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study on Transformer vs RNN in Speech Applications
Sep 28, 2019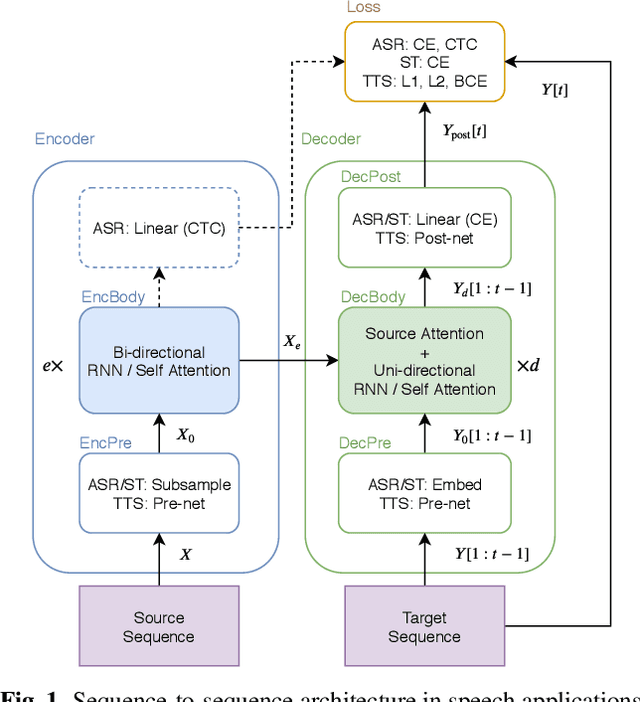
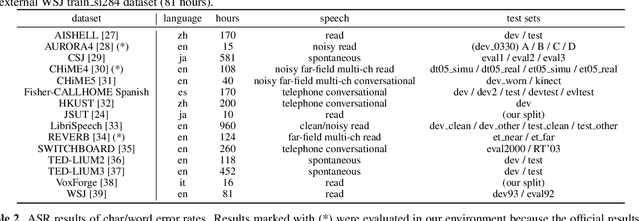
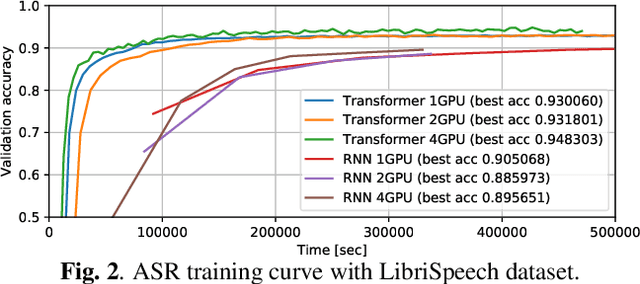
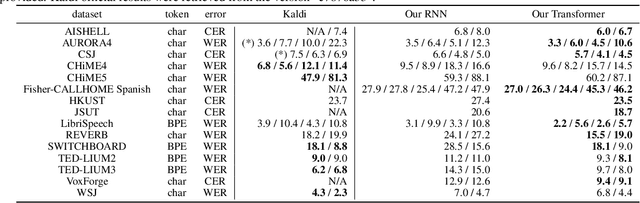
Sequence-to-sequence models have been widely used in end-to-end speech processing, for example, automatic speech recognition (ASR), speech translation (ST), and text-to-speech (TTS). This paper focuses on an emergent sequence-to-sequence model called Transformer, which achieves state-of-the-art performance in neural machine translation and other natural language processing applications. We undertook intensive studies in which we experimentally compared and analyzed Transformer and conventional recurrent neural networks (RNN) in a total of 15 ASR, one multilingual ASR, one ST, and two TTS benchmarks. Our experiments revealed various training tips and significant performance benefits obtained with Transformer for each task including the surprising superiority of Transformer in 13/15 ASR benchmarks in comparison with RNN. We are preparing to release Kaldi-style reproducible recipes using open source and publicly available datasets for all the ASR, ST, and TTS tasks for the community to succeed our exciting outcomes.
* Accepted at ASRU 2019
Multi-Stream End-to-End Speech Recognition
Jun 17, 2019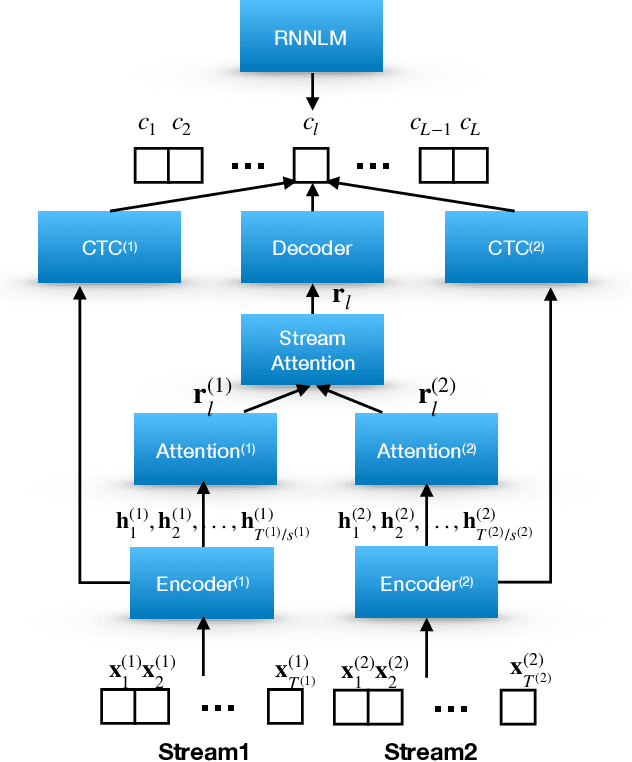
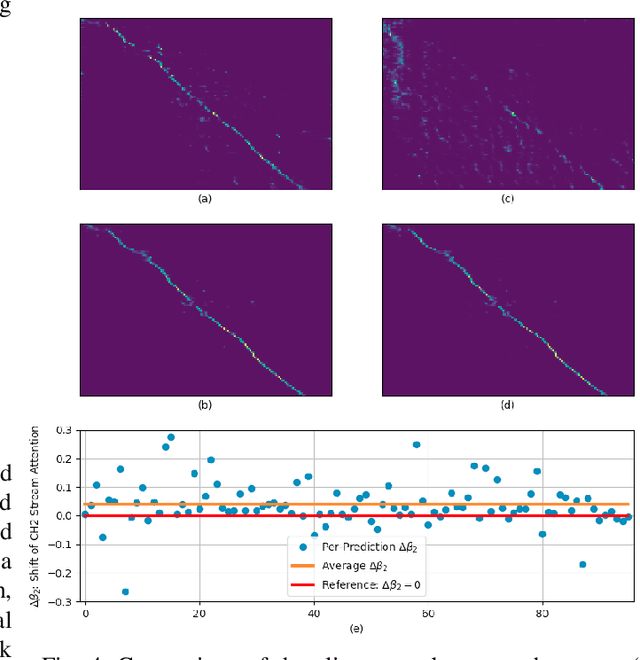
Attention-based methods and Connectionist Temporal Classification (CTC) network have been promising research directions for end-to-end (E2E) Automatic Speech Recognition (ASR). The joint CTC/Attention model has achieved great success by utilizing both architectures during multi-task training and joint decoding. In this work, we present a multi-stream framework based on joint CTC/Attention E2E ASR with parallel streams represented by separate encoders aiming to capture diverse information. On top of the regular attention networks, the Hierarchical Attention Network (HAN) is introduced to steer the decoder toward the most informative encoders. A separate CTC network is assigned to each stream to force monotonic alignments. Two representative framework have been proposed and discussed, which are Multi-Encoder Multi-Resolution (MEM-Res) framework and Multi-Encoder Multi-Array (MEM-Array) framework, respectively. In MEM-Res framework, two heterogeneous encoders with different architectures, temporal resolutions and separate CTC networks work in parallel to extract complimentary information from same acoustics. Experiments are conducted on Wall Street Journal (WSJ) and CHiME-4, resulting in relative Word Error Rate (WER) reduction of 18.0-32.1% and the best WER of 3.6% in the WSJ eval92 test set. The MEM-Array framework aims at improving the far-field ASR robustness using multiple microphone arrays which are activated by separate encoders. Compared with the best single-array results, the proposed framework has achieved relative WER reduction of 3.7% and 9.7% in AMI and DIRHA multi-array corpora, respectively, which also outperforms conventional fusion strategies.
Self-supervised Sequence-to-sequence ASR using Unpaired Speech and Text
Apr 30, 2019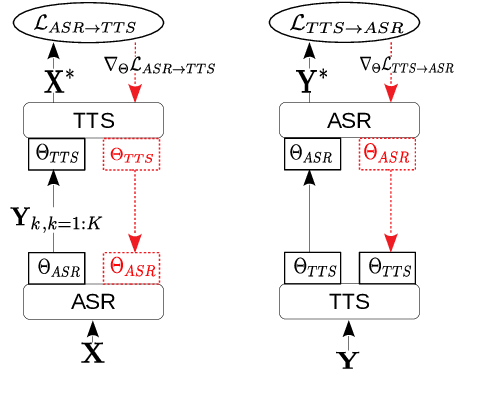
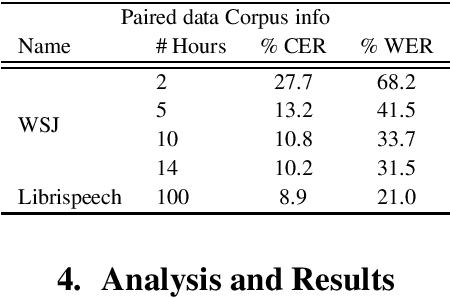
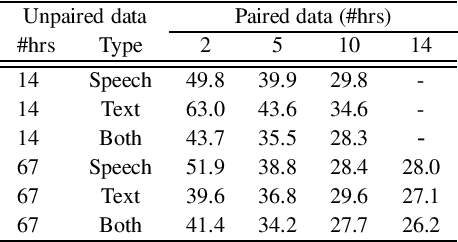
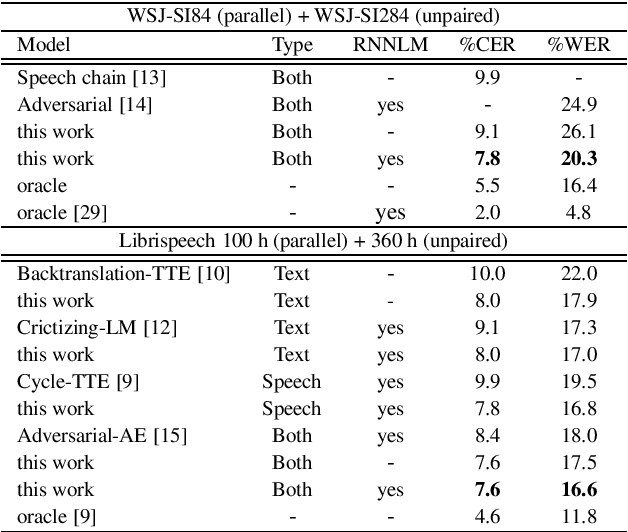
Sequence-to-sequence ASR models require large quantities of data to attain high performance. For this reason, there has been a recent surge in interest for self-supervised and supervised training in such models. This work builds upon recent results showing notable improvements in self-supervised training using cycle-consistency and related techniques. Such techniques derive training procedures and losses able to leverage unpaired speech and/or text data by combining ASR with text-to-speech (TTS) models. In particular, this work proposes a new self-supervised loss combining an end-to-end differentiable ASR$\rightarrow$TTS loss with a point estimate TTS$\rightarrow$ASR loss. The method is able to leverage both unpaired speech and text data to outperform recently proposed related techniques in terms of \%WER. We provide extensive results analyzing the impact of data quantity and speech and text modalities and show consistent gains across WSJ and Librispeech corpora. Our code is provided to reproduce the experiments.
Stream attention-based multi-array end-to-end speech recognition
Nov 12, 2018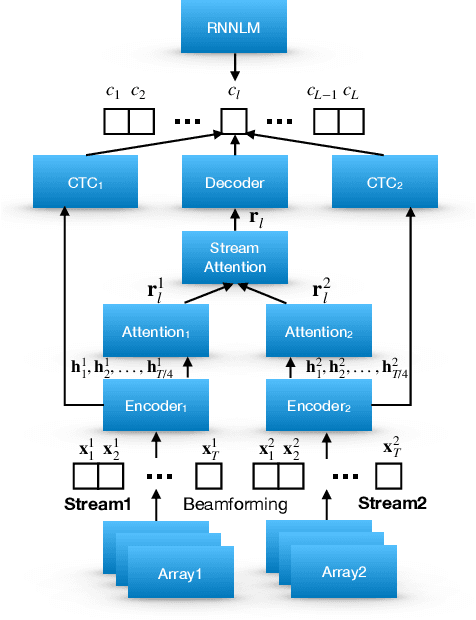
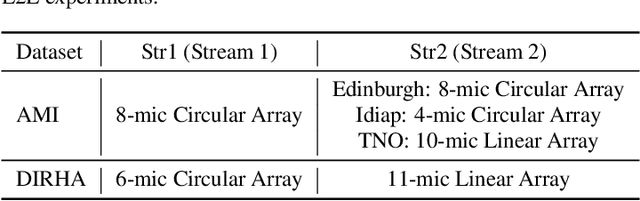
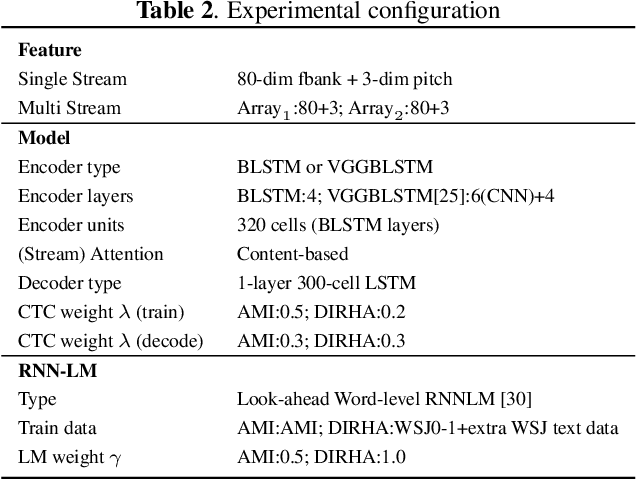
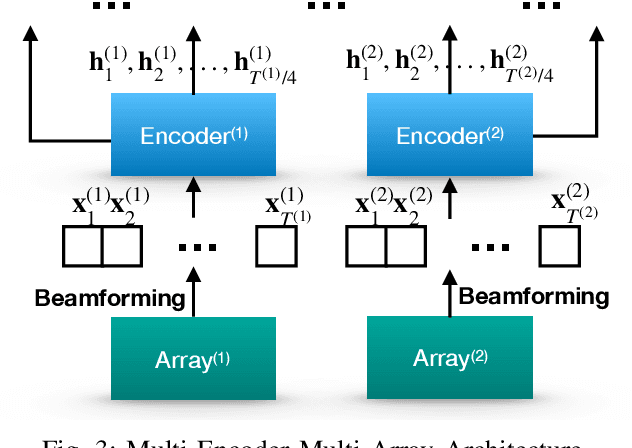
Automatic Speech Recognition (ASR) using multiple microphone arrays has achieved great success in the far-field robustness. Taking advantage of all the information that each array shares and contributes is crucial in this task. Motivated by the advances of joint Connectionist Temporal Classification (CTC)/attention mechanism in the End-to-End (E2E) ASR, a stream attention-based multi-array framework is proposed in this work. Microphone arrays, acting as information streams, are activated by separate encoders and decoded under the instruction of both CTC and attention networks. In terms of attention, a hierarchical structure is adopted. On top of the regular attention networks, stream attention is introduced to steer the decoder toward the most informative encoders. Experiments have been conducted on AMI and DIRHA multi-array corpora using the encoder-decoder architecture. Compared with the best single-array results, the proposed framework has achieved relative Word Error Rates (WERs) reduction of 3.7% and 9.7% in the two datasets, respectively, which is better than conventional strategies as well.
Multi-encoder multi-resolution framework for end-to-end speech recognition
Nov 12, 2018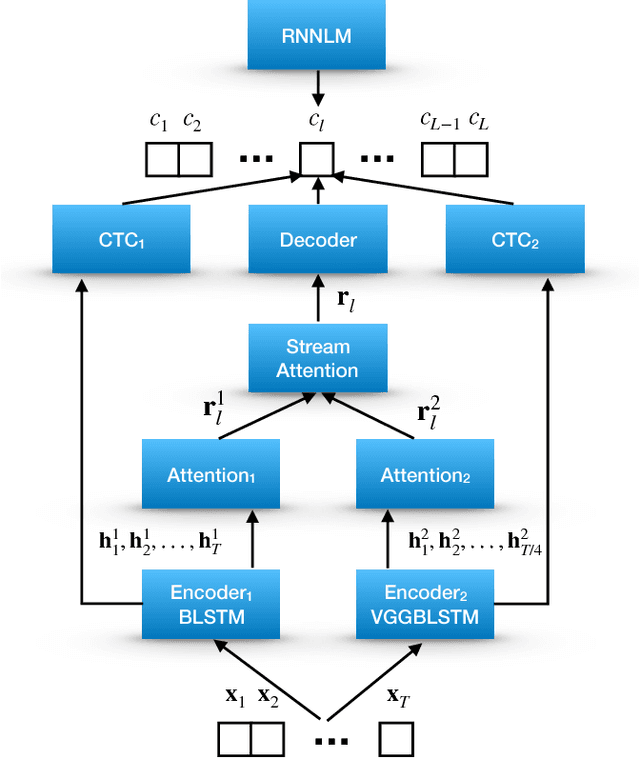
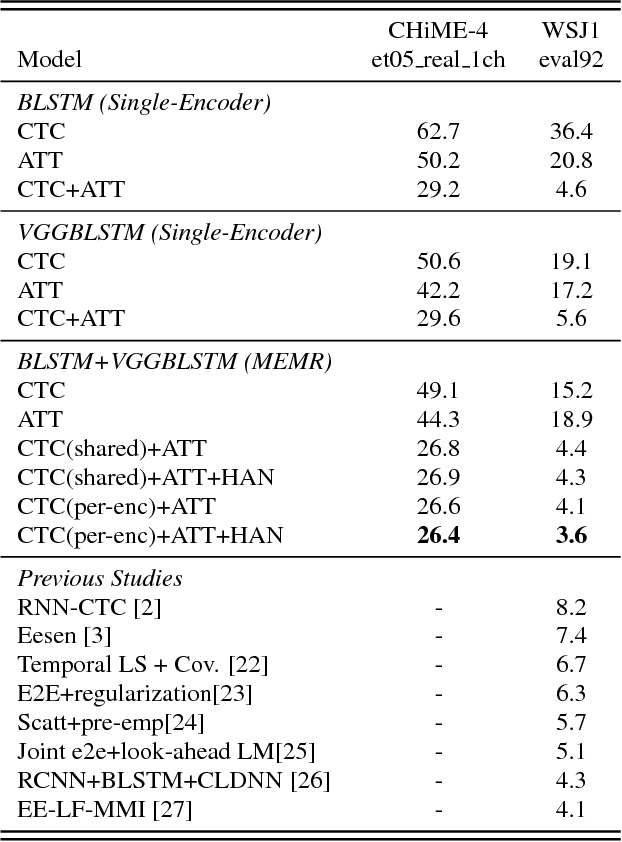
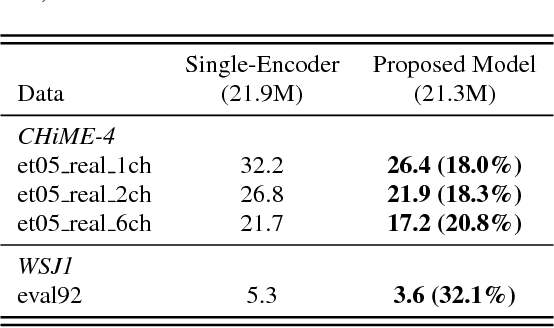

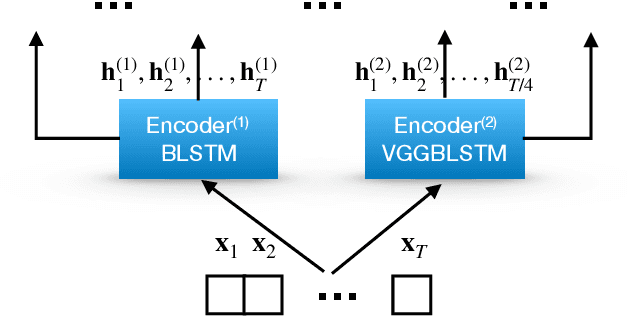
Attention-based methods and Connectionist Temporal Classification (CTC) network have been promising research directions for end-to-end Automatic Speech Recognition (ASR). The joint CTC/Attention model has achieved great success by utilizing both architectures during multi-task training and joint decoding. In this work, we present a novel Multi-Encoder Multi-Resolution (MEMR) framework based on the joint CTC/Attention model. Two heterogeneous encoders with different architectures, temporal resolutions and separate CTC networks work in parallel to extract complimentary acoustic information. A hierarchical attention mechanism is then used to combine the encoder-level information. To demonstrate the effectiveness of the proposed model, experiments are conducted on Wall Street Journal (WSJ) and CHiME-4, resulting in relative Word Error Rate (WER) reduction of 18.0-32.1%. Moreover, the proposed MEMR model achieves 3.6% WER in the WSJ eval92 test set, which is the best WER reported for an end-to-end system on this benchmark.
Vectorization of hypotheses and speech for faster beam search in encoder decoder-based speech recognition
Nov 12, 2018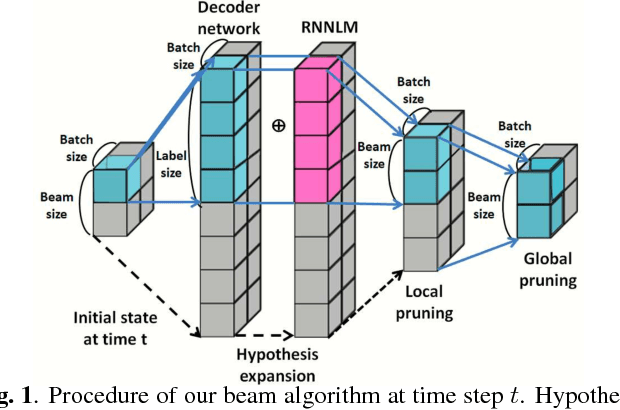
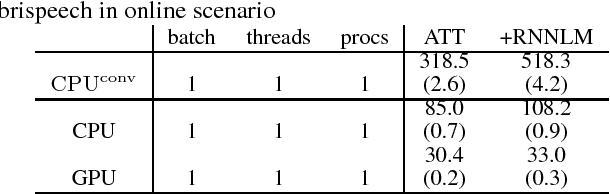
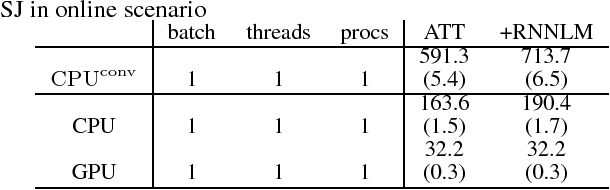
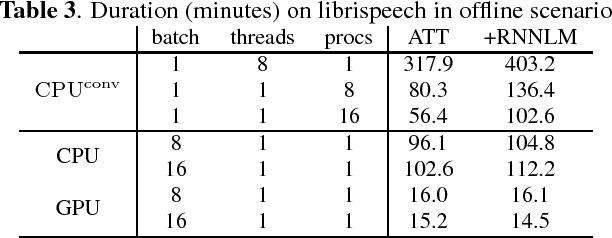
Attention-based encoder decoder network uses a left-to-right beam search algorithm in the inference step. The current beam search expands hypotheses and traverses the expanded hypotheses at the next time step. This traversal is implemented using a for-loop program in general, and it leads to speed down of the recognition process. In this paper, we propose a parallelism technique for beam search, which accelerates the search process by vectorizing multiple hypotheses to eliminate the for-loop program. We also propose a technique to batch multiple speech utterances for off-line recognition use, which reduces the for-loop program with regard to the traverse of multiple utterances. This extension is not trivial during beam search unlike during training due to several pruning and thresholding techniques for efficient decoding. In addition, our method can combine scores of external modules, RNNLM and CTC, in a batch as shallow fusion. We achieved 3.7 x speedup compared with the original beam search algorithm by vectoring hypotheses, and achieved 10.5 x speedup by further changing processing unit to GPU.
Analysis of Multilingual Sequence-to-Sequence speech recognition systems
Nov 07, 2018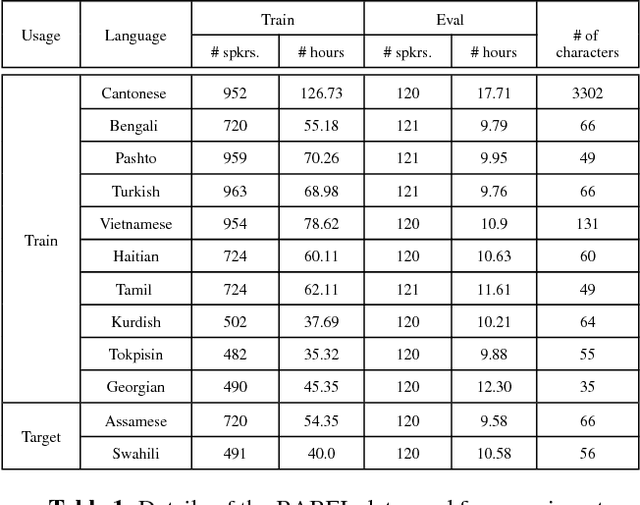
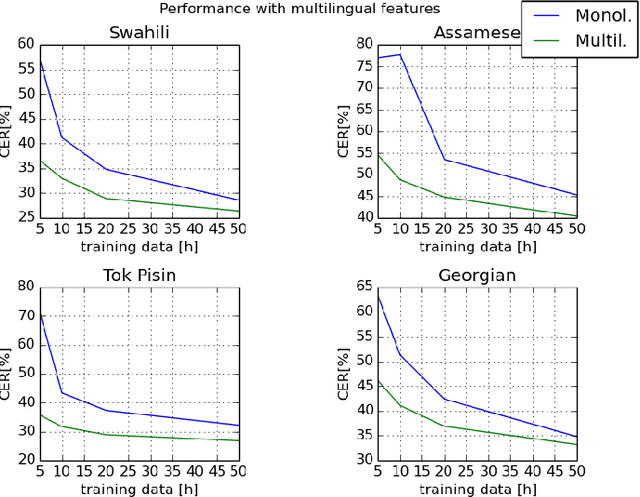
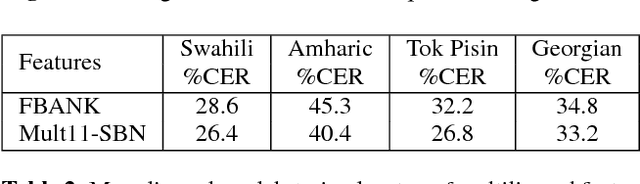
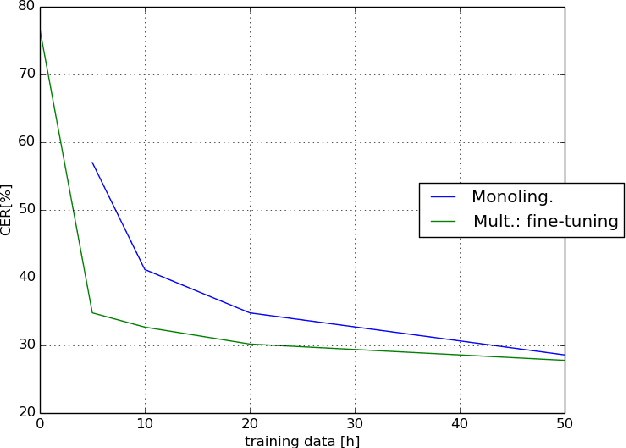
This paper investigates the applications of various multilingual approaches developed in conventional hidden Markov model (HMM) systems to sequence-to-sequence (seq2seq) automatic speech recognition (ASR). On a set composed of Babel data, we first show the effectiveness of multi-lingual training with stacked bottle-neck (SBN) features. Then we explore various architectures and training strategies of multi-lingual seq2seq models based on CTC-attention networks including combinations of output layer, CTC and/or attention component re-training. We also investigate the effectiveness of language-transfer learning in a very low resource scenario when the target language is not included in the original multi-lingual training data. Interestingly, we found multilingual features superior to multilingual models, and this finding suggests that we can efficiently combine the benefits of the HMM system with the seq2seq system through these multilingual feature techniques.
Promising Accurate Prefix Boosting for sequence-to-sequence ASR
Nov 07, 2018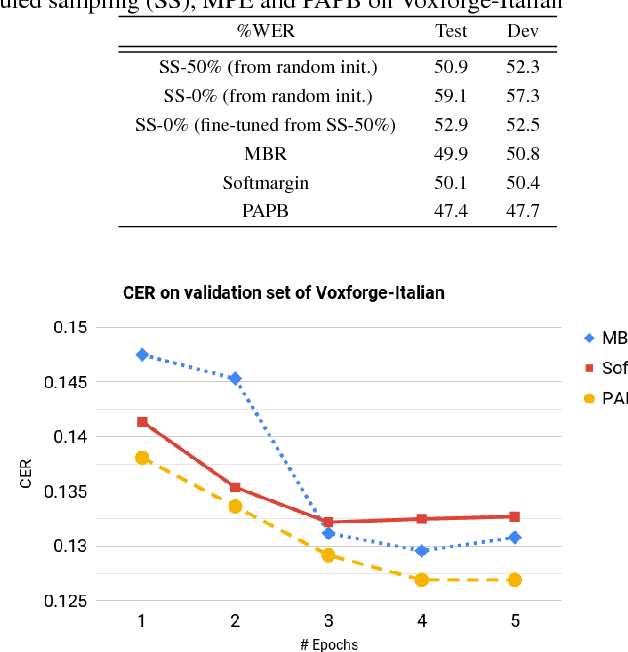
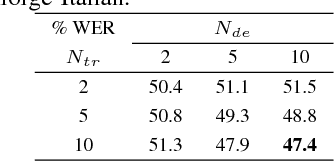
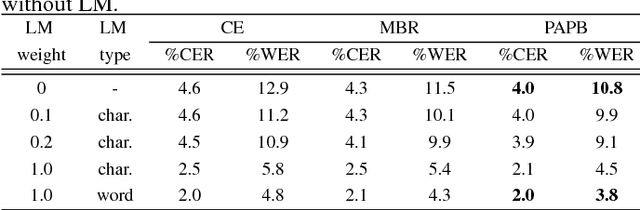
In this paper, we present promising accurate prefix boosting (PAPB), a discriminative training technique for attention based sequence-to-sequence (seq2seq) ASR. PAPB is devised to unify the training and testing scheme in an effective manner. The training procedure involves maximizing the score of each partial correct sequence obtained during beam search compared to other hypotheses. The training objective also includes minimization of token (character) error rate. PAPB shows its efficacy by achieving 10.8\% and 3.8\% WER with and without RNNLM respectively on Wall Street Journal dataset.
CNN-based MultiChannel End-to-End Speech Recognition for everyday home environments
Nov 07, 2018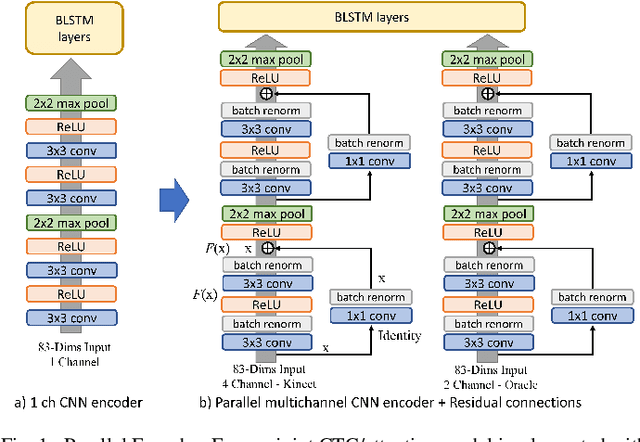

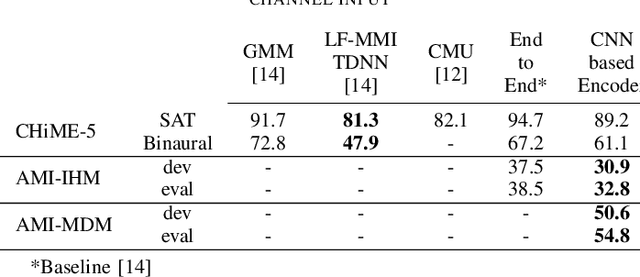
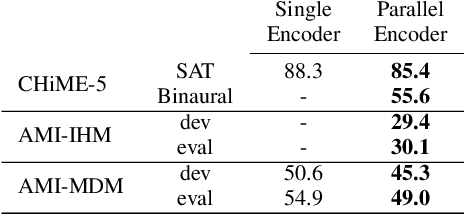
Casual conversations involving multiple speakers and noises from surrounding devices are part of everyday environments and pose challenges for automatic speech recognition systems. These challenges in speech recognition are target for the CHiME-5 challenge. In the present study, an attempt is made to overcome these challenges by employing a convolutional neural network (CNN)-based multichannel end-to-end speech recognition system. The system comprises an attention-based encoder-decoder neural network that directly generates a text as an output from a sound input. The mulitchannel CNN encoder, which uses residual connections and batch renormalization, is trained with augmented data, including white noise injection. The experimental results show that the word error rate (WER) was reduced by 11.9% absolute from the end-to-end baseline.
Cycle-consistency training for end-to-end speech recognition
Nov 02, 2018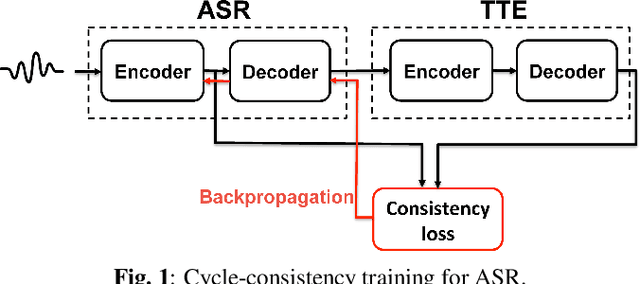
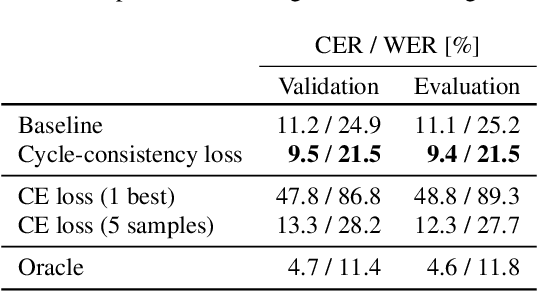
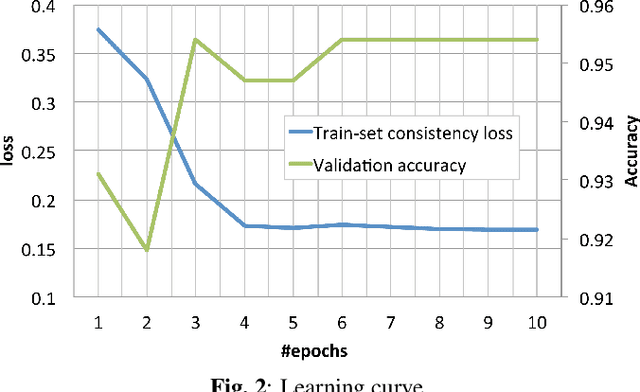

This paper presents a method to train end-to-end automatic speech recognition (ASR) models using unpaired data. Although the end-to-end approach can eliminate the need for expert knowledge such as pronunciation dictionaries to build ASR systems, it still requires a large amount of paired data, i.e., speech utterances and their transcriptions. Cycle-consistency losses have been recently proposed as a way to mitigate the problem of limited paired data. These approaches compose a reverse operation with a given transformation, e.g., text-to-speech (TTS) with ASR, to build a loss that only requires unsupervised data, speech in this example. Applying cycle consistency to ASR models is not trivial since fundamental information, such as speaker traits, are lost in the intermediate text bottleneck. To solve this problem, this work presents a loss that is based on the speech encoder state sequence instead of the raw speech signal. This is achieved by training a Text-To-Encoder model and defining a loss based on the encoder reconstruction error. Experimental results on the LibriSpeech corpus show that the proposed cycle-consistency training reduced the word error rate by 14.7% from an initial model trained with 100-hour paired data, using an additional 360 hours of audio data without transcriptions. We also investigate the use of text-only data mainly for language modeling to further improve the performance in the unpaired data training scenario.