 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for Bayesian 3D Hand Pose Estimation
Oct 01, 2020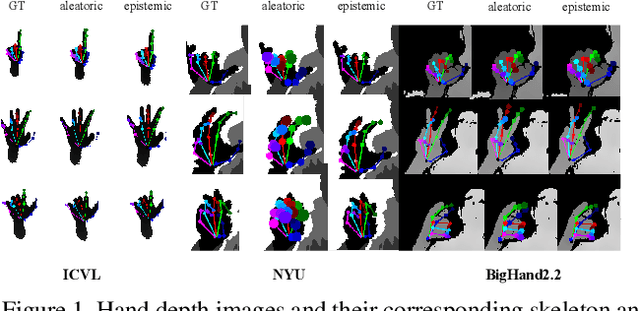
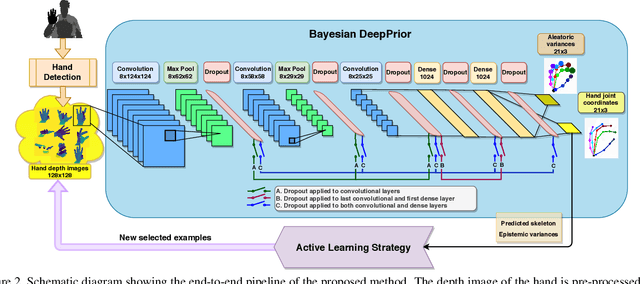
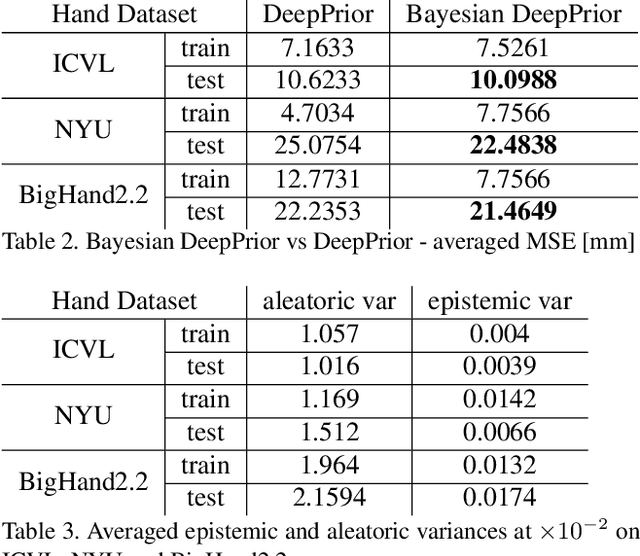
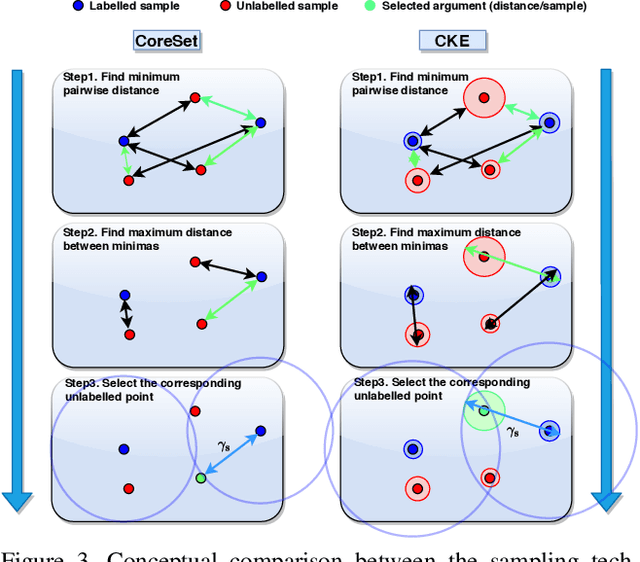
We propose a Bayesian approximation to a deep learning architecture for 3D hand pose estimation. Through this framework, we explore and analyse the two types of uncertainties that are influenced either by data or by the learning capability. Furthermore, we draw comparisons against the standard estimator over three popular benchmarks. The first contribution lies in outperforming the baseline while in the second part we address the active learning application. We also show that with a newly proposed acquisition function, our Bayesian 3D hand pose estimator obtains lowest errors with the least amount of data. The underlying code is publicly available at https://github.com/razvancaramalau/al_bhpe.
3D Dense Geometry-Guided Facial Expression Synthesis by Adversarial Learning
Sep 30, 2020
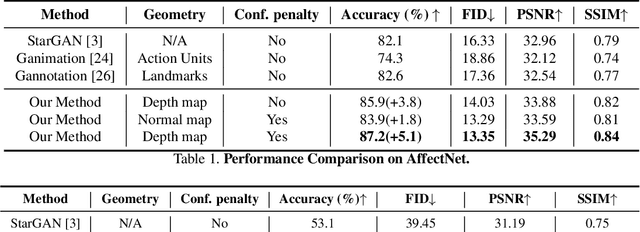
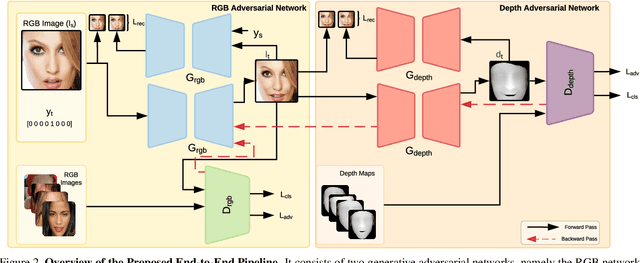

Manipulating facial expressions is a challenging task due to fine-grained shape changes produced by facial muscles and the lack of input-output pairs for supervised learning. Unlike previous methods using Generative Adversarial Networks (GAN), which rely on cycle-consistency loss or sparse geometry (landmarks) loss for expression synthesis, we propose a novel GAN framework to exploit 3D dense (depth and surface normals) information for expression manipulation. However, a large-scale dataset containing RGB images with expression annotations and their corresponding depth maps is not available. To this end, we propose to use an off-the-shelf state-of-the-art 3D reconstruction model to estimate the depth and create a large-scale RGB-Depth dataset after a manual data clean-up process. We utilise this dataset to minimise the novel depth consistency loss via adversarial learning (note we do not have ground truth depth maps for generated face images) and the depth categorical loss of synthetic data on the discriminator. In addition, to improve the generalisation and lower the bias of the depth parameters, we propose to use a novel confidence regulariser on the discriminator side of the framework. We extensively performed both quantitative and qualitative evaluations on two publicly available challenging facial expression benchmarks: AffectNet and RaFD. Our experiments demonstrate that the proposed method outperforms the competitive baseline and existing arts by a large margin.
Physics-Based Dexterous Manipulations with Estimated Hand Poses and Residual Reinforcement Learning
Aug 07, 2020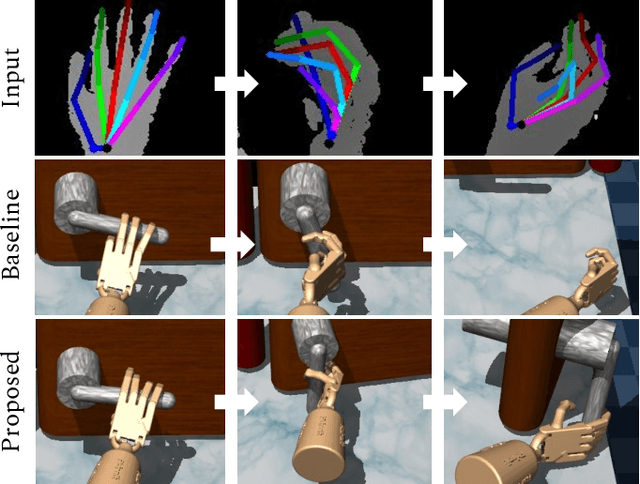
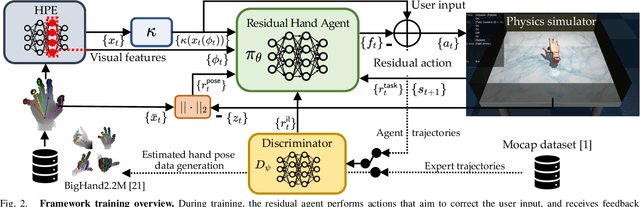
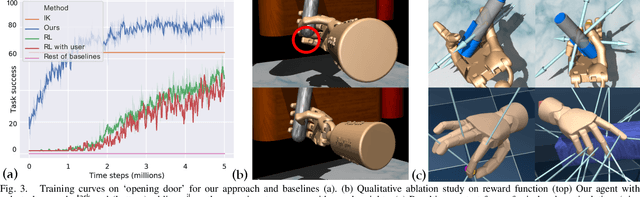
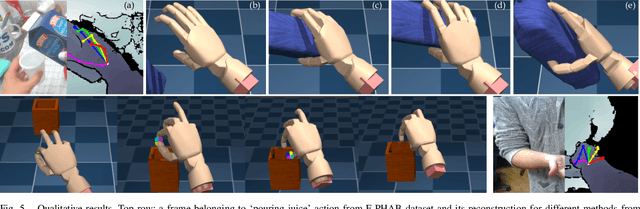
Dexterous manipulation of objects in virtual environments with our bare hands, by using only a depth sensor and a state-of-the-art 3D hand pose estimator (HPE), is challenging. While virtual environments are ruled by physics, e.g. object weights and surface frictions, the absence of force feedback makes the task challenging, as even slight inaccuracies on finger tips or contact points from HPE may make the interactions fail. Prior arts simply generate contact forces in the direction of the fingers' closures, when finger joints penetrate virtual objects. Although useful for simple grasping scenarios, they cannot be applied to dexterous manipulations such as in-hand manipulation. Existing reinforcement learning (RL) and imitation learning (IL) approaches train agents that learn skills by using task-specific rewards, without considering any online user input. In this work, we propose to learn a model that maps noisy input hand poses to target virtual poses, which introduces the needed contacts to accomplish the tasks on a physics simulator. The agent is trained in a residual setting by using a model-free hybrid RL+IL approach. A 3D hand pose estimation reward is introduced leading to an improvement on HPE accuracy when the physics-guided corrected target poses are remapped to the input space. As the model corrects HPE errors by applying minor but crucial joint displacements for contacts, this helps to keep the generated motion visually close to the user input. Since HPE sequences performing successful virtual interactions do not exist, a data generation scheme to train and evaluate the system is proposed. We test our framework in two applications that use hand pose estimates for dexterous manipulations: hand-object interactions in VR and hand-object motion reconstruction in-the-wild.
Sequential Graph Convolutional Network for Active Learning
Jun 18, 2020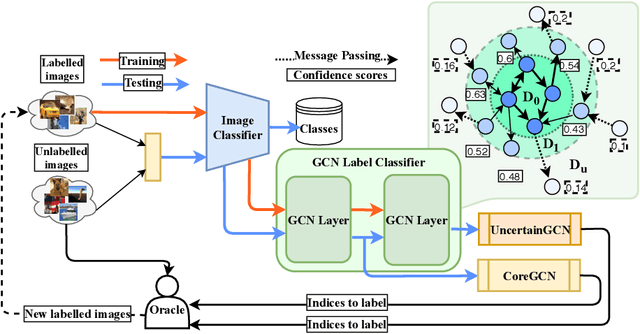

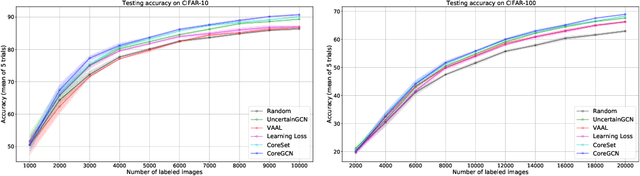
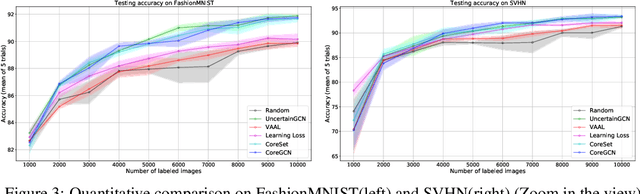
We propose a novel generic sequential Graph Convolution Network (GCN) training for Active Learning. Each of the unlabelled and labelled examples is represented through a pre-trained learner as nodes of a graph and their similarities as edges. With the available few labelled examples as seed annotations, the parameters of the Graphs are optimised to minimise the binary cross-entropy loss to identify labelled vs unlabelled. Based on the confidence score of the nodes in the graph we sub-sample unlabelled examples to annotate where inherited uncertainties correlate. With the newly annotated examples along with the existing ones, the parameters of the graph are optimised to minimise the modified objective. We evaluated our method on four publicly available image classification benchmarks. Our method outperforms several competitive baselines and existing arts. The implementations of this paper can be found here: https://github.com/razvancaramalau/Sequential-GCN-for-Active-Learning
Modelling Hierarchical Structure between Dialogue Policy and Natural Language Generator with Option Framework for Task-oriented Dialogue System
Jun 11, 2020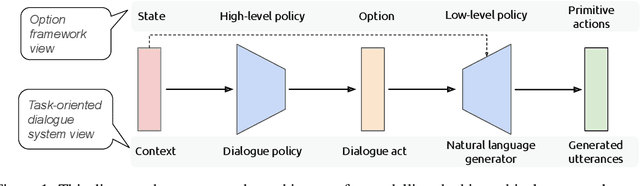
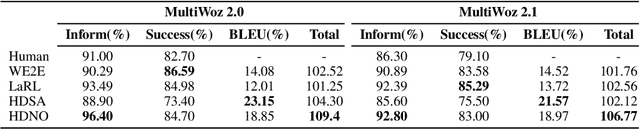
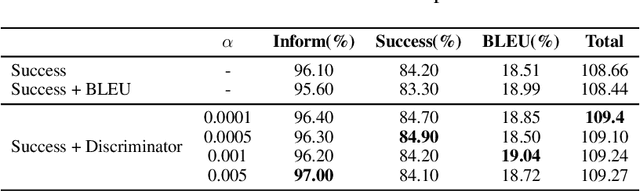

Designing task-oriented dialogue systems is a challenging research topic, since it needs not only to generate utterances fulfilling user requests but also to guarantee the comprehensibility. Many previous works trained end-to-end (E2E) models with supervised learning (SL), however, the bias in annotated system utterances remains as a bottleneck. Reinforcement learning (RL) deals with the problem through using non-differentiable evaluation metrics (e.g., the success rate) as rewards. Nonetheless, existing works with RL showed that the comprehensibility of generated system utterances could be corrupted when improving the performance on fulfilling user requests. In our work, we (1) propose modelling the hierarchical structure between dialogue policy and natural language generator (NLG) with the option framework, called HDNO; (2) train HDNO with hierarchical reinforcement learning (HRL), as well as suggest alternating updates between dialogue policy and NLG during HRL inspired by fictitious play, to preserve the comprehensibility of generated system utterances while improving fulfilling user requests; and (3) propose using a discriminator modelled with language models as an additional reward to further improve the comprehensibility. We test HDNO on MultiWoz 2.0 and MultiWoz 2.1, the datasets on multi-domain dialogues, in comparison with word-level E2E model trained with RL, LaRL and HDSA, showing a significant improvement on the total performance evaluated with automatic metrics.
MatchGAN: A Self-Supervised Semi-Supervised Conditional Generative Adversarial Network
Jun 11, 2020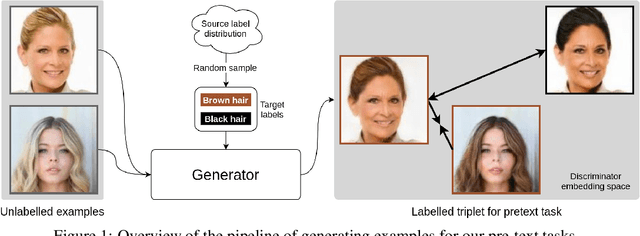
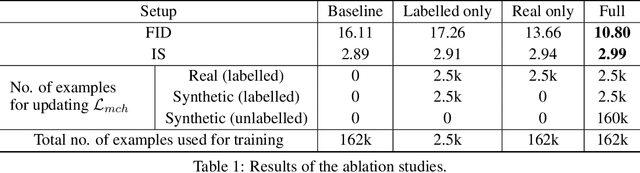
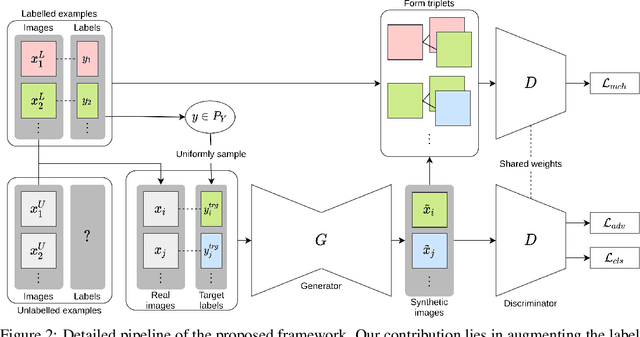
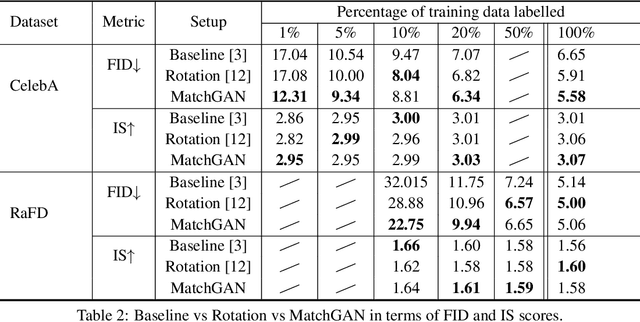
We propose a novel self-supervised semi-supervised learning approach for conditional Generative Adversarial Networks (GANs). Unlike previous self-supervised learning approaches which define pretext tasks by performing augmentations on the image space such as applying geometric transformations or predicting relationships between image patches, our approach leverages the label space. We train our network to learn the distribution of the source domain using the few labelled examples available by uniformly sampling source labels and assigning them as target labels for unlabelled examples from the same distribution. The translated images on the side of the generator are then grouped into positive and negative pairs by comparing their corresponding target labels, which are then used to optimise an auxiliary triplet objective on the discriminator's side. We tested our method on two challenging benchmarks, CelebA and RaFD, and evaluated the results using standard metrics including Frechet Inception Distance, Inception Score, and Attribute Classification Rate. Extensive empirical evaluation demonstrates the effectiveness of our proposed method over competitive baselines and existing arts. In particular, our method is able to surpass the baseline with only 20% of the labelled examples used to train the baseline.
Measuring Generalisation to Unseen Viewpoints, Articulations, Shapes and Objects for 3D Hand Pose Estimation under Hand-Object Interaction
Mar 30, 2020
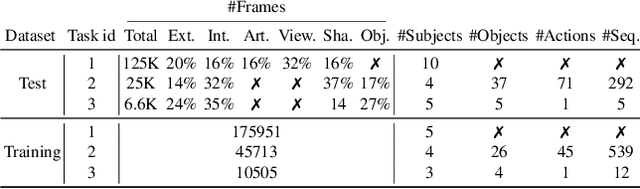
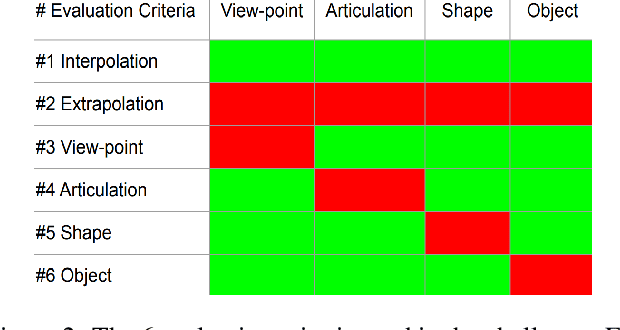
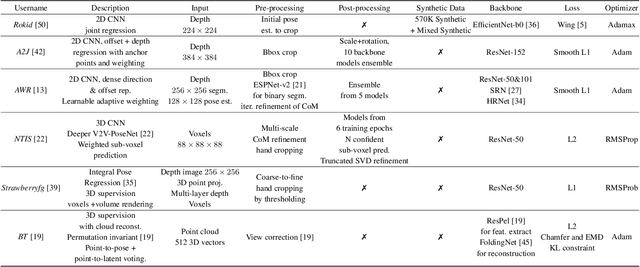
In this work, we study how well different type of approaches generalise in the task of 3D hand pose estimation under hand-object interaction and single hand scenarios. We show that the accuracy of state-of-the-art methods can drop, and that they fail mostly on poses absent from the training set. Unfortunately, since the space of hand poses is highly dimensional, it is inherently not feasible to cover the whole space densely, despite recent efforts in collecting large-scale training datasets. This sampling problem is even more severe when hands are interacting with objects and/or inputs are RGB rather than depth images, as RGB images also vary with lighting conditions and colors. To address these issues, we designed a public challenge to evaluate the abilities of current 3D hand pose estimators~(HPEs) to interpolate and extrapolate the poses of a training set. More exactly, our challenge is designed (a) to evaluate the influence of both depth and color modalities on 3D hand pose estimation, under the presence or absence of objects; (b) to assess the generalisation abilities \wrt~four main axes: shapes, articulations, viewpoints, and objects; (c) to explore the use of a synthetic hand model to fill the gaps of current datasets. Through the challenge, the overall accuracy has dramatically improved over the baseline, especially on extrapolation tasks, from 27mm to 13mm mean joint error. Our analyses highlight the impacts of: Data pre-processing, ensemble approaches, the use of MANO model, and different HPE methods/backbones.
Tackling Two Challenges of 6D Object Pose Estimation: Lack of Real Annotated RGB Images and Scalability to Number of Objects
Mar 27, 2020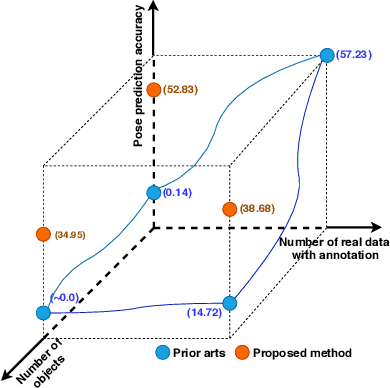
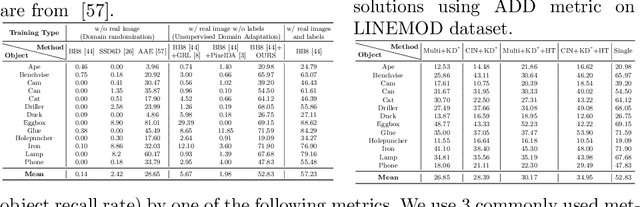
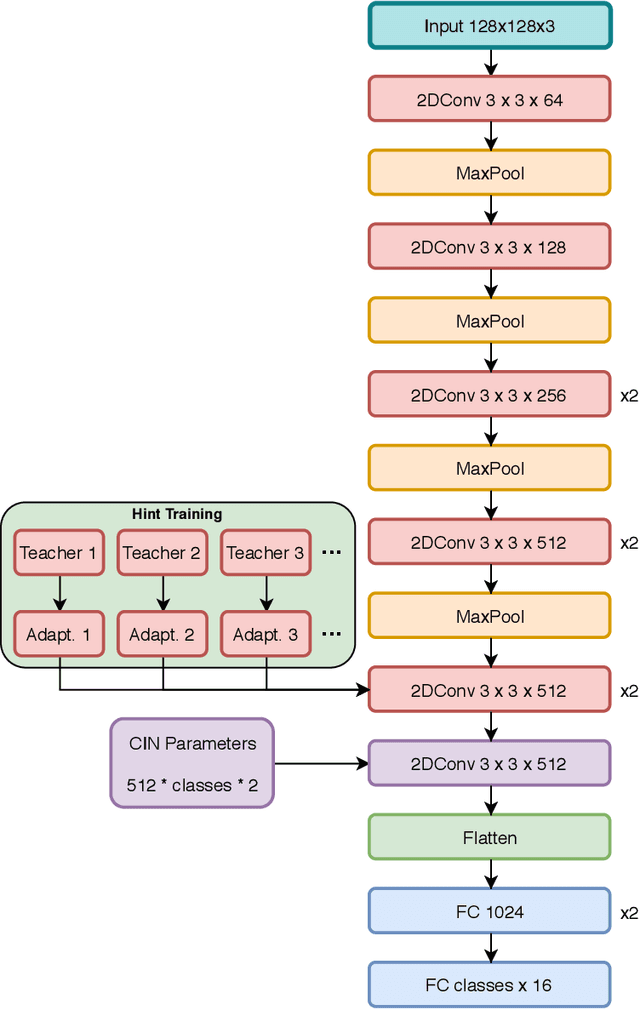
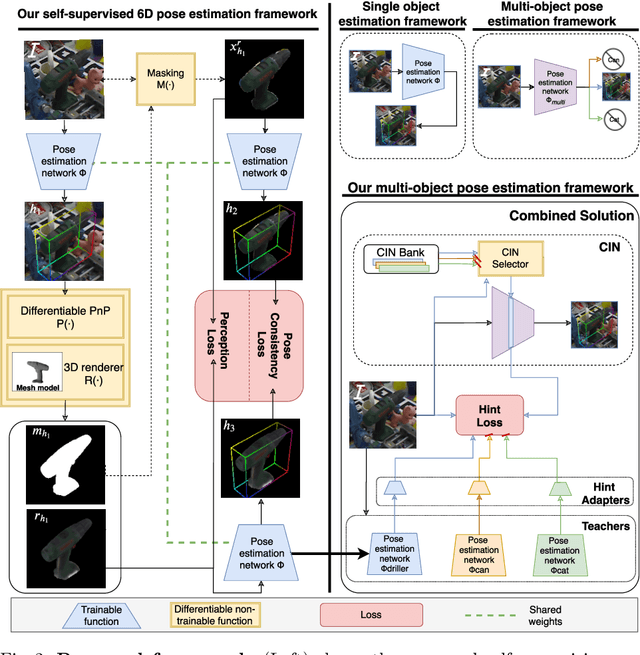
State-of-the-art methods for 6D object pose estimation typically train a Deep Neural Network per object, and its training data first comes from a 3D object mesh. Models trained with synthetic data alone do not generalise well, and training a model for multiple objects sharply drops its accuracy. In this work, we address these two main challenges for 6D object pose estimation and investigate viable methods in experiments. For lack of real RGB data with pose annotations, we propose a novel self-supervision method via pose consistency. For scalability to multiple objects, we apply additional parameterisation to a backbone network and distill knowledge from teachers to a student network for model compression. We further evaluate the combination of the two methods for settings where we are given only synthetic data and a single network for multiple objects. In experiments using LINEMOD, LINEMOD OCCLUSION and T-LESS datasets, the methods significantly boost baseline accuracies and are comparable with the upper bounds, i.e., object specific networks trained on real data with pose labels.
Additive Angular Margin for Few Shot Learning to Classify Clinical Endoscopy Images
Mar 26, 2020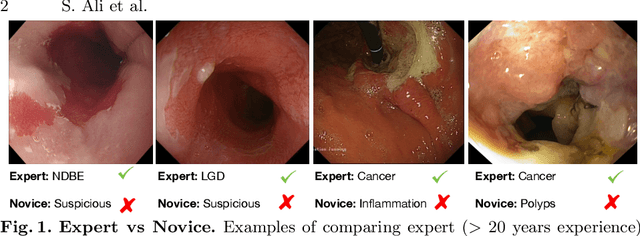
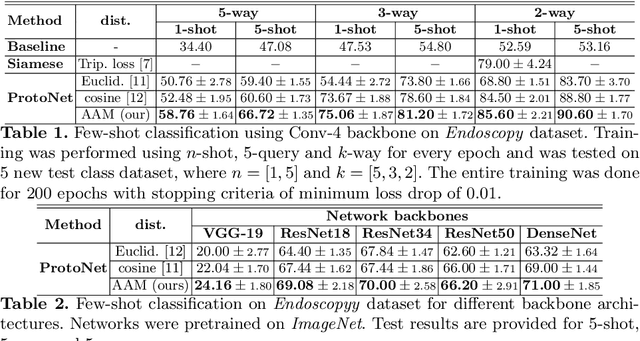
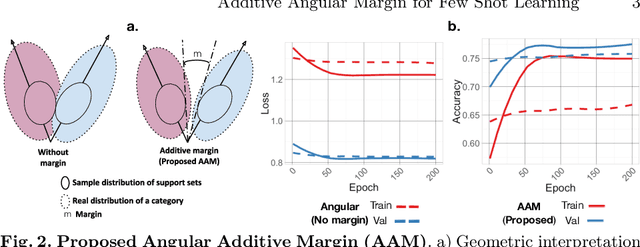
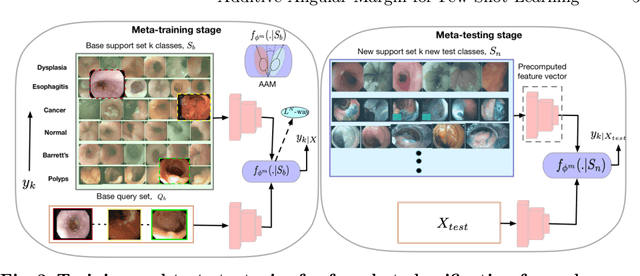
Endoscopy is a widely used imaging modality to diagnose and treat diseases in hollow organs as for example the gastrointestinal tract, the kidney and the liver. However, due to varied modalities and use of different imaging protocols at various clinical centers impose significant challenges when generalising deep learning models. Moreover, the assembly of large datasets from different clinical centers can introduce a huge label bias that renders any learnt model unusable. Also, when using new modality or presence of images with rare patterns, a bulk amount of similar image data and their corresponding labels are required for training these models. In this work, we propose to use a few-shot learning approach that requires less training data and can be used to predict label classes of test samples from an unseen dataset. We propose a novel additive angular margin metric in the framework of prototypical network in few-shot learning setting. We compare our approach to the several established methods on a large cohort of multi-center, multi-organ, and multi-modal endoscopy data. The proposed algorithm outperforms existing state-of-the-art methods.
EventSR: From Asynchronous Events to Image Reconstruction, Restoration, and Super-Resolution via End-to-End Adversarial Learning
Mar 17, 2020
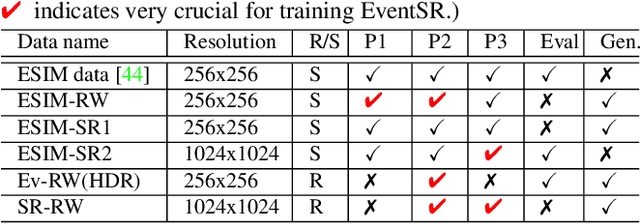
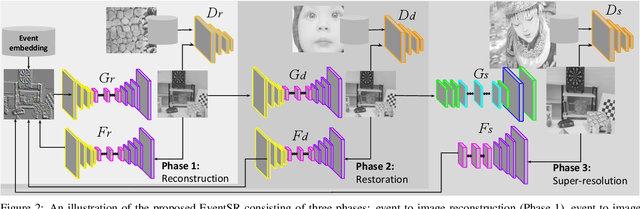
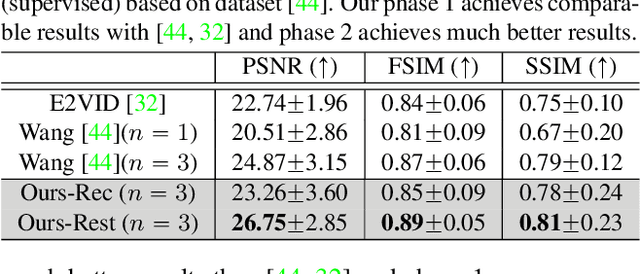
Event cameras sense intensity changes and have many advantages over conventional cameras. To take advantage of event cameras, some methods have been proposed to reconstruct intensity images from event streams. However, the outputs are still in low resolution (LR), noisy, and unrealistic. The low-quality outputs stem broader applications of event cameras, where high spatial resolution (HR) is needed as well as high temporal resolution, dynamic range, and no motion blur. We consider the problem of reconstructing and super-resolving intensity images from LR events, when no ground truth (GT) HR images and down-sampling kernels are available. To tackle the challenges, we propose a novel end-to-end pipeline that reconstructs LR images from event streams, enhances the image qualities and upsamples the enhanced images, called EventSR. For the absence of real GT images, our method is primarily unsupervised, deploying adversarial learning. To train EventSR, we create an open dataset including both real-world and simulated scenes. The use of both datasets boosts up the network performance, and the network architectures and various loss functions in each phase help improve the image qualities. The whole pipeline is trained in three phases. While each phase is mainly for one of the three tasks, the networks in earlier phases are fine-tuned by respective loss functions in an end-to-end manner. Experimental results show that EventSR reconstructs high-quality SR images from events for both simulated and real-world data.