 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Mechanistic Interpretability Transfer Across Data Modalities? A Cross-Domain Causal Circuit Analysis of Variational Autoencoders
Mar 22, 2026Although mechanism-based interpretability has generated an abundance of insight for discriminative network analysis, generative models are less understood -- particularly outside of image-related applications. We investigate how much of the causal circuitry found within image-related variational autoencoders (VAEs) will generalize to tabular data, as VAEs are increasingly used for imputation, anomaly detection, and synthetic data generation. In addition to extending a four-level causal intervention framework to four tabular and one image benchmark across five different VAE architectures (with 75 individual training runs per architecture and three random seed values for each run), this paper introduces three new techniques: posterior-calibration of Causal Effect Strength (CES), path-specific activation patching, and Feature-Group Disentanglement (FGD). The results from our experiments demonstrate that: (i) Tabular VAEs have circuits with modularity that is approximately 50% lower than their image counterparts. (ii) $β$-VAE experiences nearly complete collapse in CES scores when applied to heterogeneous tabular features (0.043 CES score for tabular data compared to 0.133 CES score for images), which can be directly attributed to reconstruction quality degradation (r = -0.886 correlation coefficient between CES and MSE). (iii) CES successfully captures nine of eleven statistically significant architecture differences using Holm--Šidák corrections. (iv) Interventions with high specificity predict the highest downstream AUC values (r = 0.460, p < .001). This study challenges the common assumption that architectural guidance from image-related studies can be transferred to tabular datasets.
Fundamental Limits of Neural Network Sparsification: Evidence from Catastrophic Interpretability Collapse
Mar 18, 2026Extreme neural network sparsification (90% activation reduction) presents a critical challenge for mechanistic interpretability: understanding whether interpretable features survive aggressive compression. This work investigates feature survival under severe capacity constraints in hybrid Variational Autoencoder--Sparse Autoencoder (VAE-SAE) architectures. We introduce an adaptive sparsity scheduling framework that progressively reduces active neurons from 500 to 50 over 50 training epochs, and provide empirical evidence for fundamental limits of the sparsification-interpretability relationship. Testing across two benchmark datasets -- dSprites and Shapes3D -- with both Top-k and L1 sparsification methods, our key finding reveals a pervasive paradox: while global representation quality (measured by Mutual Information Gap) remains stable, local feature interpretability collapses systematically. Under Top-k sparsification, dead neuron rates reach $34.4\pm0.9\%$ on dSprites and $62.7\pm1.3\%$ on Shapes3D at k=50. L1 regularization -- a fundamentally different "soft constraint" paradigm -- produces equal or worse collapse: $41.7\pm4.4\%$ on dSprites and $90.6\pm0.5\%$ on Shapes3D. Extended training for 100 additional epochs fails to recover dead neurons, and the collapse pattern is robust across all tested threshold definitions. Critically, the collapse scales with dataset complexity: Shapes3D (RGB, 6 factors) shows $1.8\times$ more dead neurons than dSprites (grayscale, 5 factors) under Top-k and $2.2\times$ under L1. These findings establish that interpretability collapse under sparsification is intrinsic to the compression process rather than an artifact of any particular algorithm, training duration, or threshold choice.
HinTel-AlignBench: A Framework and Benchmark for Hindi-Telugu with English-Aligned Samples
Nov 19, 2025With nearly 1.5 billion people and more than 120 major languages, India represents one of the most diverse regions in the world. As multilingual Vision-Language Models (VLMs) gain prominence, robust evaluation methodologies are essential to drive progress toward equitable AI for low-resource languages. Current multilingual VLM evaluations suffer from four major limitations: reliance on unverified auto-translations, narrow task/domain coverage, limited sample sizes, and lack of cultural and natively sourced Question-Answering (QA). To address these gaps, we present a scalable framework to evaluate VLMs in Indian languages and compare it with performance in English. Using the framework, we generate HinTel-AlignBench, a benchmark that draws from diverse sources in Hindi and Telugu with English-aligned samples. Our contributions are threefold: (1) a semi-automated dataset creation framework combining back-translation, filtering, and human verification; (2) the most comprehensive vision-language benchmark for Hindi and and Telugu, including adapted English datasets (VQAv2, RealWorldQA, CLEVR-Math) and native novel Indic datasets (JEE for STEM, VAANI for cultural grounding) with approximately 4,000 QA pairs per language; and (3) a detailed performance analysis of various State-of-the-Art (SOTA) open-weight and closed-source VLMs. We find a regression in performance for tasks in English versus in Indian languages for 4 out of 5 tasks across all the models, with an average regression of 8.3 points in Hindi and 5.5 points for Telugu. We categorize common failure modes to highlight concrete areas of improvement in multilingual multimodal understanding.
GASCADE: Grouped Summarization of Adverse Drug Event for Enhanced Cancer Pharmacovigilance
May 07, 2025In the realm of cancer treatment, summarizing adverse drug events (ADEs) reported by patients using prescribed drugs is crucial for enhancing pharmacovigilance practices and improving drug-related decision-making. While the volume and complexity of pharmacovigilance data have increased, existing research in this field has predominantly focused on general diseases rather than specifically addressing cancer. This work introduces the task of grouped summarization of adverse drug events reported by multiple patients using the same drug for cancer treatment. To address the challenge of limited resources in cancer pharmacovigilance, we present the MultiLabeled Cancer Adverse Drug Reaction and Summarization (MCADRS) dataset. This dataset includes pharmacovigilance posts detailing patient concerns regarding drug efficacy and adverse effects, along with extracted labels for drug names, adverse drug events, severity, and adversity of reactions, as well as summaries of ADEs for each drug. Additionally, we propose the Grouping and Abstractive Summarization of Cancer Adverse Drug events (GASCADE) framework, a novel pipeline that combines the information extraction capabilities of Large Language Models (LLMs) with the summarization power of the encoder-decoder T5 model. Our work is the first to apply alignment techniques, including advanced algorithms like Direct Preference Optimization, to encoder-decoder models using synthetic datasets for summarization tasks. Through extensive experiments, we demonstrate the superior performance of GASCADE across various metrics, validated through both automated assessments and human evaluations. This multitasking approach enhances drug-related decision-making and fosters a deeper understanding of patient concerns, paving the way for advancements in personalized and responsive cancer care. The code and dataset used in this work are publicly available.
ARDDQN: Attention Recurrent Double Deep Q-Network for UAV Coverage Path Planning and Data Harvesting
May 17, 2024



Unmanned Aerial Vehicles (UAVs) have gained popularity in data harvesting (DH) and coverage path planning (CPP) to survey a given area efficiently and collect data from aerial perspectives, while data harvesting aims to gather information from various Internet of Things (IoT) sensor devices, coverage path planning guarantees that every location within the designated area is visited with minimal redundancy and maximum efficiency. We propose the ARDDQN (Attention-based Recurrent Double Deep Q Network), which integrates double deep Q-networks (DDQN) with recurrent neural networks (RNNs) and an attention mechanism to generate path coverage choices that maximize data collection from IoT devices and to learn a control scheme for the UAV that generalizes energy restrictions. We employ a structured environment map comprising a compressed global environment map and a local map showing the UAV agent's locate efficiently scaling to large environments. We have compared Long short-term memory (LSTM), Bi-directional long short-term memory (Bi-LSTM), Gated recurrent unit (GRU) and Bidirectional gated recurrent unit (Bi-GRU) as recurrent neural networks (RNN) to the result without RNN We propose integrating the LSTM with the Attention mechanism to the existing DDQN model, which works best on evolution parameters, i.e., data collection, landing, and coverage ratios for the CPP and data harvesting scenarios.
Collisionless Pattern Discovery in Robot Swarms Using Deep Reinforcement Learning
Sep 20, 2022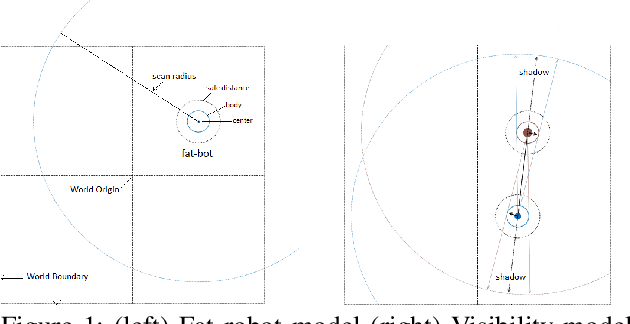
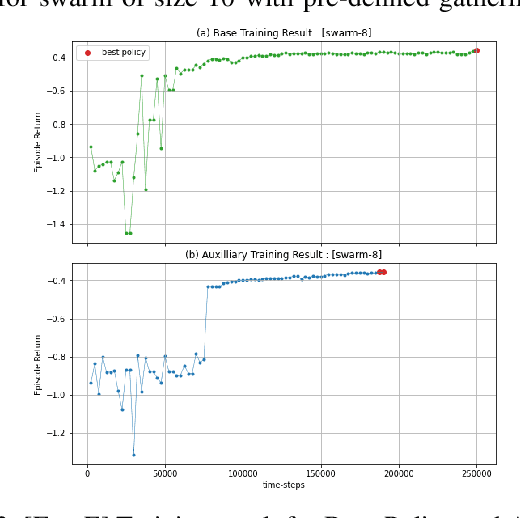

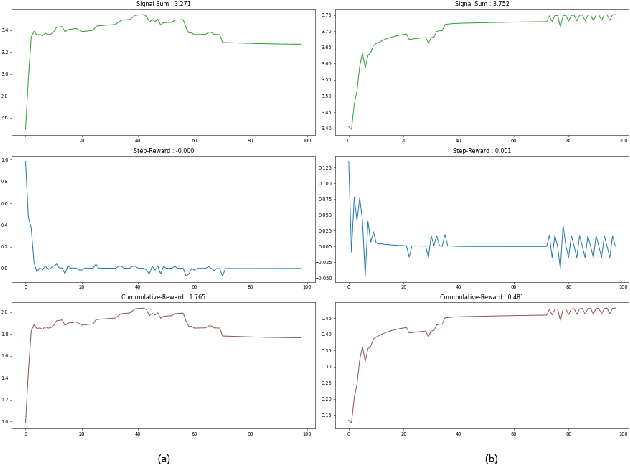
We present a deep reinforcement learning-based framework for automatically discovering patterns available in any given initial configuration of fat robot swarms. In particular, we model the problem of collision-less gathering and mutual visibility in fat robot swarms and discover patterns for solving them using our framework. We show that by shaping reward signals based on certain constraints like mutual visibility and safe proximity, the robots can discover collision-less trajectories leading to well-formed gathering and visibility patterns.