 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Label Shift in Tabular In-Context Learning via Test-Time Posterior Adjustment
May 06, 2026TabPFN has recently gained attention as a foundation model for tabular datasets, achieving strong performance by leveraging in-context learning on synthetic data. However, we find that TabPFN is vulnerable to label shift, often overfitting to the majority class in the training dataset. To address this limitation, we propose DistPFN, the first test-time posterior adjustment method designed for tabular foundation models. DistPFN rescales predicted class probabilities by downweighting the influence of the training prior (i.e., the class distribution of the context) and emphasizing the contribution of the model's predicted posterior, without architectural modification or additional training. We further introduce DistPFN-T, which incorporates temperature scaling to adaptively control the adjustment strength based on the discrepancy between prior and posterior. We evaluate our methods on over 250 OpenML datasets, demonstrating substantial improvements for various TabPFN-based models in classification tasks under label shift, while maintaining strong performance in standard settings without label shift. Code is available at this repository: https://github.com/seunghan96/DistPFN.
FinSTaR: Towards Financial Reasoning with Time Series Reasoning Models
May 05, 2026Time series (TS) reasoning models (TSRMs) have shown promising capabilities in general domains, yet they consistently fail on financial domain, which exhibit unique characteristics. We propose a general 2x2 capability taxonomy for TSRMs by crossing 1) single-entity vs. multi-entity analysis with 2) assessment of the current state vs. prediction of future behavior. We instantiate this taxonomy in the financial domain -- where the distinction between deterministic assessment and stochastic prediction is particularly critical -- as ten financial reasoning tasks, forming the FinTSR-Bench benchmark based on S&P stocks. To this end, we propose FinSTaR (Financial Time Series Thinking and Reasoning), trained on FinTSR-Bench with distinct chain-of-thought (CoT) strategies tailored to each category. For assessment, which is deterministic (i.e., computable from observable data), we employ Compute-in-CoT, a programmatic CoT that enables models to derive answers directly from raw prices. For prediction, which is inherently stochastic (i.e., subject to unobservable factors), we adopt Scenario-Aware CoT, which generates diverse scenarios before making a judgment, mirroring how financial analysts reason under uncertainty. The proposed method achieves 78.9% average accuracy on FinTSR-Bench, substantially outperforming LLM and TSRM baselines. Furthermore, we show that the four capability categories are complementary and mutually reinforcing through joint training, and that Scenario-Aware CoT consistently improves prediction accuracy over standard CoT. Code is publicly available at: https://github.com/seunghan96/FinSTaR.
Rethinking Multimodal Fusion for Time Series: Auxiliary Modalities Need Constrained Fusion
Mar 23, 2026Recent advances in multimodal learning have motivated the integration of auxiliary modalities such as text or vision into time series (TS) forecasting. However, most existing methods provide limited gains, often improving performance only in specific datasets or relying on architecture-specific designs that limit generalization. In this paper, we show that multimodal models with naive fusion strategies (e.g., simple addition or concatenation) often underperform unimodal TS models, which we attribute to the uncontrolled integration of auxiliary modalities which may introduce irrelevant information. Motivated by this observation, we explore various constrained fusion methods designed to control such integration and find that they consistently outperform naive fusion methods. Furthermore, we propose Controlled Fusion Adapter (CFA), a simple plug-in method that enables controlled cross-modal interactions without modifying the TS backbone, integrating only relevant textual information aligned with TS dynamics. CFA employs low-rank adapters to filter irrelevant textual information before fusing it into temporal representations. We conduct over 20K experiments across various datasets and TS/text models, demonstrating the effectiveness of the constrained fusion methods including CFA. Code is publicly available at: https://github.com/seunghan96/cfa/.
Cross-RAG: Zero-Shot Retrieval-Augmented Time Series Forecasting via Cross-Attention
Mar 16, 2026Recent advances in time series foundation models (TSFMs) demonstrate strong expressive capacity through large-scale pretraining across diverse time series domains. Zero-shot time series forecasting with TSFMs, however, exhibits limited generalization to unseen datasets, which retrieval-augmented forecasting addresses by leveraging an external knowledge base. Existing approaches rely on a fixed number of retrieved samples that may introduce irrelevant information. To this end, we propose Cross-RAG, a zero-shot retrieval-augmented forecasting framework that selectively attends to query-relevant retrieved samples. Cross-RAG models input-level relevance between the query and retrieved samples via query-retrieval cross-attention, while jointly incorporating information from the query and retrieved samples. Extensive experiments demonstrate that Cross-RAG consistently improves zero-shot forecasting performance across various TSFMs and RAG methods, and additional analyses confirm its effectiveness across diverse retrieval scenarios. Code is available at https://github.com/seunghan96/cross-rag/.
FinTexTS: Financial Text-Paired Time-Series Dataset via Semantic-Based and Multi-Level Pairing
Mar 03, 2026The financial domain involves a variety of important time-series problems. Recently, time-series analysis methods that jointly leverage textual and numerical information have gained increasing attention. Accordingly, numerous efforts have been made to construct text-paired time-series datasets in the financial domain. However, financial markets are characterized by complex interdependencies, in which a company's stock price is influenced not only by company-specific events but also by events in other companies and broader macroeconomic factors. Existing approaches that pair text with financial time-series data based on simple keyword matching often fail to capture such complex relationships. To address this limitation, we propose a semantic-based and multi-level pairing framework. Specifically, we extract company-specific context for the target company from SEC filings and apply an embedding-based matching mechanism to retrieve semantically relevant news articles based on this context. Furthermore, we classify news articles into four levels (macro-level, sector-level, related company-level, and target-company level) using large language models (LLMs), enabling multi-level pairing of news articles with the target company. Applying this framework to publicly-available news datasets, we construct \textbf{FinTexTS}, a new large-scale text-paired stock price dataset. Experimental results on \textbf{FinTexTS} demonstrate the effectiveness of our semantic-based and multi-level pairing strategy in stock price forecasting. In addition to publicly-available news underlying \textbf{FinTexTS}, we show that applying our method to proprietary yet carefully curated news sources leads to higher-quality paired data and improved stock price forecasting performance.
Adaptive Information Routing for Multimodal Time Series Forecasting
Dec 23, 2025Time series forecasting is a critical task for artificial intelligence with numerous real-world applications. Traditional approaches primarily rely on historical time series data to predict the future values. However, in practical scenarios, this is often insufficient for accurate predictions due to the limited information available. To address this challenge, multimodal time series forecasting methods which incorporate additional data modalities, mainly text data, alongside time series data have been explored. In this work, we introduce the Adaptive Information Routing (AIR) framework, a novel approach for multimodal time series forecasting. Unlike existing methods that treat text data on par with time series data as interchangeable auxiliary features for forecasting, AIR leverages text information to dynamically guide the time series model by controlling how and to what extent multivariate time series information should be combined. We also present a text-refinement pipeline that employs a large language model to convert raw text data into a form suitable for multimodal forecasting, and we introduce a benchmark that facilitates multimodal forecasting experiments based on this pipeline. Experiment results with the real world market data such as crude oil price and exchange rates demonstrate that AIR effectively modulates the behavior of the time series model using textual inputs, significantly enhancing forecasting accuracy in various time series forecasting tasks.
THEME : Enhancing Thematic Investing with Semantic Stock Representations and Temporal Dynamics
Aug 23, 2025Thematic investing aims to construct portfolios aligned with structural trends, yet selecting relevant stocks remains challenging due to overlapping sector boundaries and evolving market dynamics. To address this challenge, we construct the Thematic Representation Set (TRS), an extended dataset that begins with real-world thematic ETFs and expands upon them by incorporating industry classifications and financial news to overcome their coverage limitations. The final dataset contains both the explicit mapping of themes to their constituent stocks and the rich textual profiles for each. Building on this dataset, we introduce \textsc{THEME}, a hierarchical contrastive learning framework. By representing the textual profiles of themes and stocks as embeddings, \textsc{THEME} first leverages their hierarchical relationship to achieve semantic alignment. Subsequently, it refines these semantic embeddings through a temporal refinement stage that incorporates individual stock returns. The final stock representations are designed for effective retrieval of thematically aligned assets with strong return potential. Empirical results show that \textsc{THEME} outperforms strong baselines across multiple retrieval metrics and significantly improves performance in portfolio construction. By jointly modeling thematic relationships from text and market dynamics from returns, \textsc{THEME} provides a scalable and adaptive solution for navigating complex investment themes.
Deformable Graph Convolutional Networks
Dec 29, 2021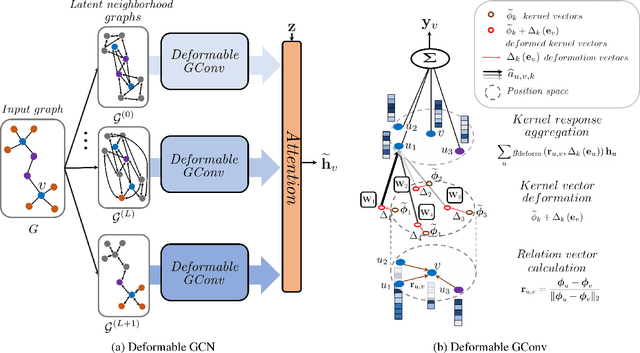
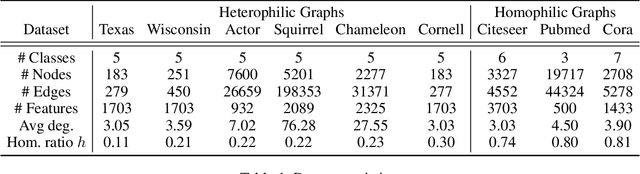
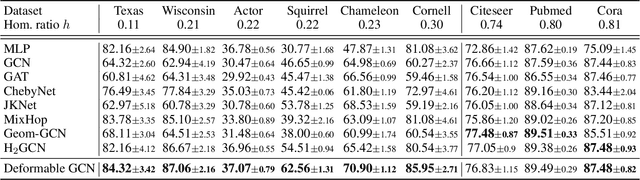
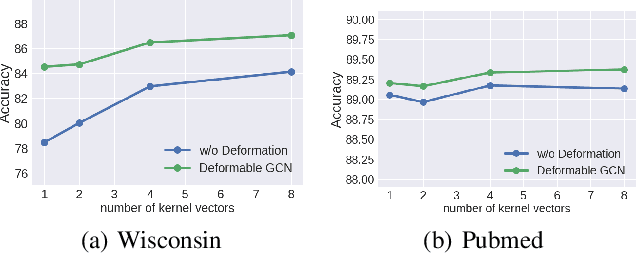
Graph neural networks (GNNs) have significantly improved the representation power for graph-structured data. Despite of the recent success of GNNs, the graph convolution in most GNNs have two limitations. Since the graph convolution is performed in a small local neighborhood on the input graph, it is inherently incapable to capture long-range dependencies between distance nodes. In addition, when a node has neighbors that belong to different classes, i.e., heterophily, the aggregated messages from them often negatively affect representation learning. To address the two common problems of graph convolution, in this paper, we propose Deformable Graph Convolutional Networks (Deformable GCNs) that adaptively perform convolution in multiple latent spaces and capture short/long-range dependencies between nodes. Separated from node representations (features), our framework simultaneously learns the node positional embeddings (coordinates) to determine the relations between nodes in an end-to-end fashion. Depending on node position, the convolution kernels are deformed by deformation vectors and apply different transformations to its neighbor nodes. Our extensive experiments demonstrate that Deformable GCNs flexibly handles the heterophily and achieve the best performance in node classification tasks on six heterophilic graph datasets.
Graph Transformer Networks: Learning Meta-path Graphs to Improve GNNs
Jun 11, 2021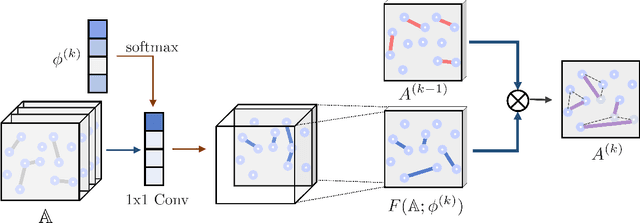
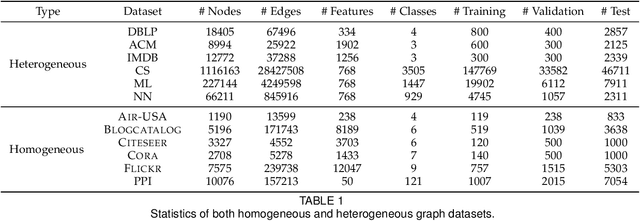
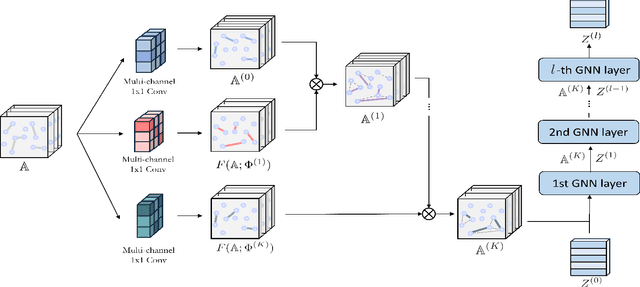
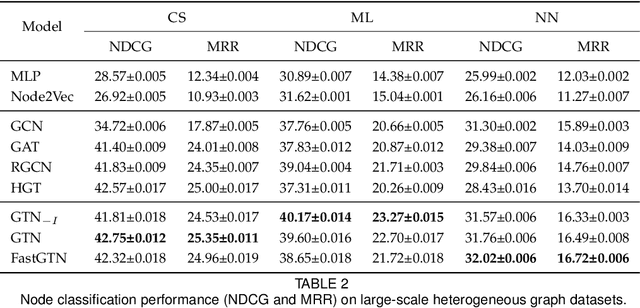
Graph Neural Networks (GNNs) have been widely applied to various fields due to their powerful representations of graph-structured data. Despite the success of GNNs, most existing GNNs are designed to learn node representations on the fixed and homogeneous graphs. The limitations especially become problematic when learning representations on a misspecified graph or a heterogeneous graph that consists of various types of nodes and edges. To address this limitations, we propose Graph Transformer Networks (GTNs) that are capable of generating new graph structures, which preclude noisy connections and include useful connections (e.g., meta-paths) for tasks, while learning effective node representations on the new graphs in an end-to-end fashion. We further propose enhanced version of GTNs, Fast Graph Transformer Networks (FastGTNs), that improve scalability of graph transformations. Compared to GTNs, FastGTNs are 230x faster and use 100x less memory while allowing the identical graph transformations as GTNs. In addition, we extend graph transformations to the semantic proximity of nodes allowing non-local operations beyond meta-paths. Extensive experiments on both homogeneous graphs and heterogeneous graphs show that GTNs and FastGTNs with non-local operations achieve the state-of-the-art performance for node classification tasks. The code is available: https://github.com/seongjunyun/Graph_Transformer_Networks