 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboPianist: A Benchmark for High-Dimensional Robot Control
Apr 09, 2023



We introduce a new benchmarking suite for high-dimensional control, targeted at testing high spatial and temporal precision, coordination, and planning, all with an underactuated system frequently making-and-breaking contacts. The proposed challenge is mastering the piano through bi-manual dexterity, using a pair of simulated anthropomorphic robot hands. We call it RoboPianist, and the initial version covers a broad set of 150 variable-difficulty songs. We investigate both model-free and model-based methods on the benchmark, characterizing their performance envelopes. We observe that while certain existing methods, when well-tuned, can achieve impressive levels of performance in certain aspects, there is significant room for improvement. RoboPianist provides a rich quantitative benchmarking environment, with human-interpretable results, high ease of expansion by simply augmenting the repertoire with new songs, and opportunities for further research, including in multi-task learning, zero-shot generalization, multimodal (sound, vision, touch) learning, and imitation. Supplementary information, including videos of our control policies, can be found at https://kzakka.com/robopianist/
Mnemosyne: Learning to Train Transformers with Transformers
Feb 02, 2023Training complex machine learning (ML) architectures requires a compute and time consuming process of selecting the right optimizer and tuning its hyper-parameters. A new paradigm of learning optimizers from data has emerged as a better alternative to hand-designed ML optimizers. We propose Mnemosyne optimizer, that uses Performers: implicit low-rank attention Transformers. It can learn to train entire neural network architectures including other Transformers without any task-specific optimizer tuning. We show that Mnemosyne: (a) generalizes better than popular LSTM optimizer, (b) in particular can successfully train Vision Transformers (ViTs) while meta--trained on standard MLPs and (c) can initialize optimizers for faster convergence in Robotics applications. We believe that these results open the possibility of using Transformers to build foundational optimization models that can address the challenges of regular Transformer training. We complement our results with an extensive theoretical analysis of the compact associative memory used by Mnemosyne.
Single-Level Differentiable Contact Simulation
Dec 13, 2022



We present a differentiable formulation of rigid-body contact dynamics for objects and robots represented as compositions of convex primitives. Existing optimization-based approaches simulating contact between convex primitives rely on a bilevel formulation that separates collision detection and contact simulation. These approaches are unreliable in realistic contact simulation scenarios because isolating the collision detection problem introduces contact location non-uniqueness. Our approach combines contact simulation and collision detection into a unified single-level optimization problem. This disambiguates the collision detection problem in a physics-informed manner. Compared to previous differentiable simulation approaches, our formulation features improved simulation robustness and a reduction in computational complexity by more than an order of magnitude. We illustrate the contact and collision differentiability on a robotic manipulation task requiring optimization-through-contact. We provide a numerically efficient implementation of our formulation in the Julia language called Silico.jl.
Robotic Table Wiping via Reinforcement Learning and Whole-body Trajectory Optimization
Oct 19, 2022
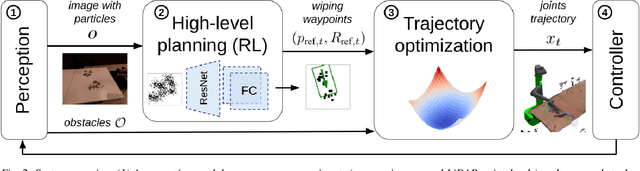

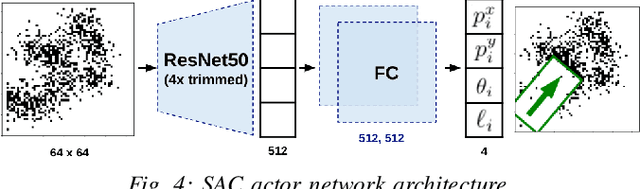
We propose a framework to enable multipurpose assistive mobile robots to autonomously wipe tables to clean spills and crumbs. This problem is challenging, as it requires planning wiping actions while reasoning over uncertain latent dynamics of crumbs and spills captured via high-dimensional visual observations. Simultaneously, we must guarantee constraints satisfaction to enable safe deployment in unstructured cluttered environments. To tackle this problem, we first propose a stochastic differential equation to model crumbs and spill dynamics and absorption with a robot wiper. Using this model, we train a vision-based policy for planning wiping actions in simulation using reinforcement learning (RL). To enable zero-shot sim-to-real deployment, we dovetail the RL policy with a whole-body trajectory optimization framework to compute base and arm joint trajectories that execute the desired wiping motions while guaranteeing constraints satisfaction. We extensively validate our approach in simulation and on hardware. Video: https://youtu.be/inORKP4F3EI
Learning Model Predictive Controllers with Real-Time Attention for Real-World Navigation
Sep 24, 2022
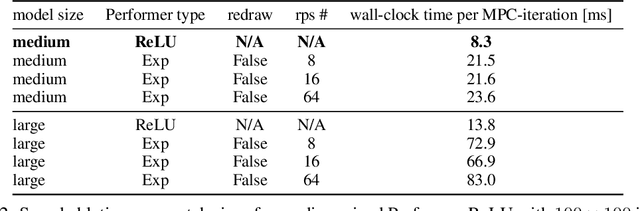


Despite decades of research, existing navigation systems still face real-world challenges when deployed in the wild, e.g., in cluttered home environments or in human-occupied public spaces. To address this, we present a new class of implicit control policies combining the benefits of imitation learning with the robust handling of system constraints from Model Predictive Control (MPC). Our approach, called Performer-MPC, uses a learned cost function parameterized by vision context embeddings provided by Performers -- a low-rank implicit-attention Transformer. We jointly train the cost function and construct the controller relying on it, effectively solving end-to-end the corresponding bi-level optimization problem. We show that the resulting policy improves standard MPC performance by leveraging a few expert demonstrations of the desired navigation behavior in different challenging real-world scenarios. Compared with a standard MPC policy, Performer-MPC achieves >40% better goal reached in cluttered environments and >65% better on social metrics when navigating around humans.
Multiscale Sensor Fusion and Continuous Control with Neural CDEs
Mar 16, 2022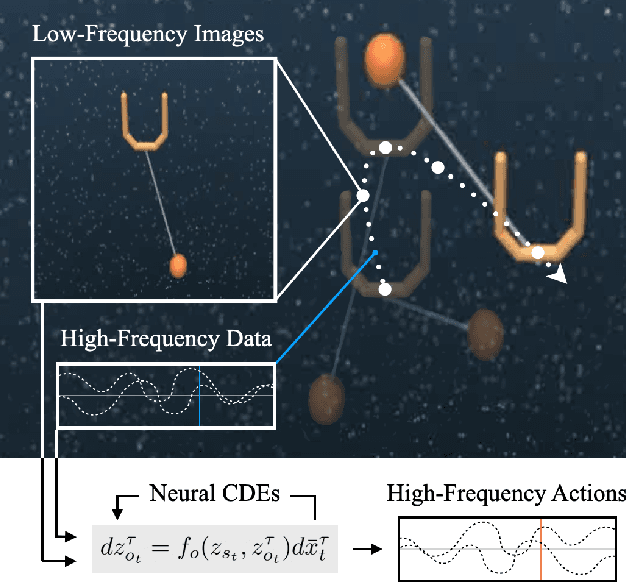
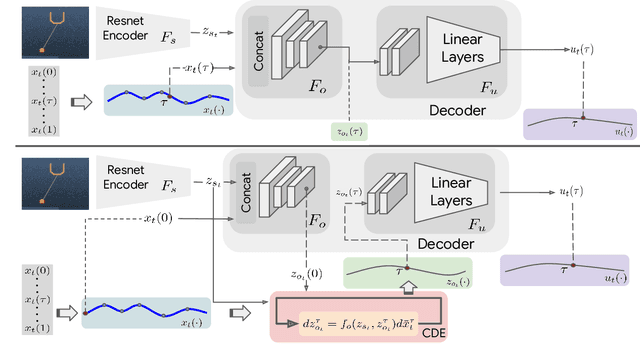
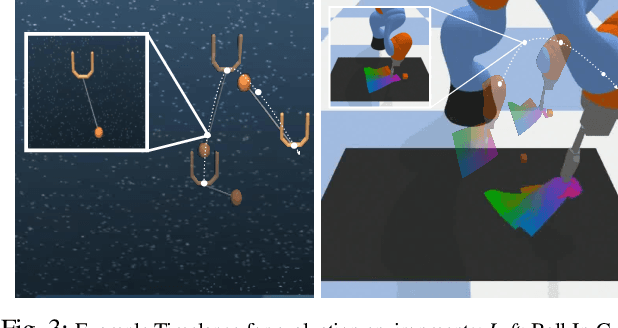
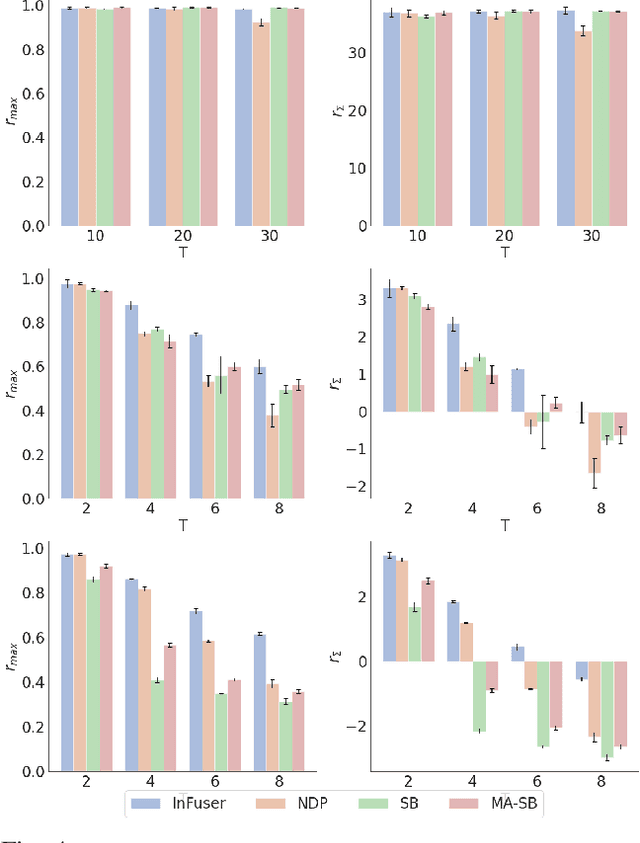
Though robot learning is often formulated in terms of discrete-time Markov decision processes (MDPs), physical robots require near-continuous multiscale feedback control. Machines operate on multiple asynchronous sensing modalities, each with different frequencies, e.g., video frames at 30Hz, proprioceptive state at 100Hz, force-torque data at 500Hz, etc. While the classic approach is to batch observations into fixed-time windows then pass them through feed-forward encoders (e.g., with deep networks), we show that there exists a more elegant approach -- one that treats policy learning as modeling latent state dynamics in continuous-time. Specifically, we present 'InFuser', a unified architecture that trains continuous time-policies with Neural Controlled Differential Equations (CDEs). InFuser evolves a single latent state representation over time by (In)tegrating and (Fus)ing multi-sensory observations (arriving at different frequencies), and inferring actions in continuous-time. This enables policies that can react to multi-frequency multi sensory feedback for truly end-to-end visuomotor control, without discrete-time assumptions. Behavior cloning experiments demonstrate that InFuser learns robust policies for dynamic tasks (e.g., swinging a ball into a cup) notably outperforming several baselines in settings where observations from one sensing modality can arrive at much sparser intervals than others.
Trajectory Optimization with Optimization-Based Dynamics
Sep 10, 2021



We present a framework for bi-level trajectory optimization in which a system's dynamics are encoded as the solution to a constrained optimization problem and smooth gradients of this lower-level problem are passed to an upper-level trajectory optimizer. This optimization-based dynamics representation enables constraint handling, additional variables, and non-smooth forces to be abstracted away from the upper-level optimizer, and allows classical unconstrained optimizers to synthesize trajectories for more complex systems. We provide a path-following method for efficient evaluation of constrained dynamics and utilize the implicit-function theorem to compute smooth gradients of this representation. We demonstrate the framework by modeling systems from locomotion, aerospace, and manipulation domains including: acrobot with joint limits, cart-pole subject to Coulomb friction, Raibert hopper, rocket landing with thrust limits, and planar-push task with optimization-based dynamics and then optimize trajectories using iterative LQR.
Learning Stabilizable Nonlinear Dynamics with Contraction-Based Regularization
Jul 29, 2019
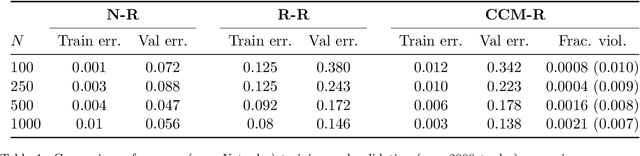
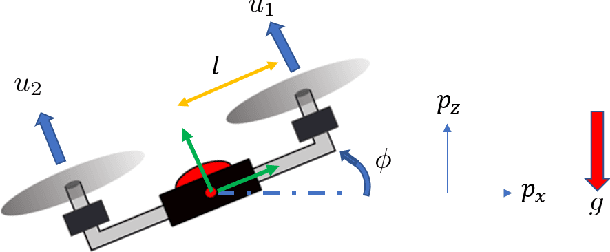

We propose a novel framework for learning stabilizable nonlinear dynamical systems for continuous control tasks in robotics. The key contribution is a control-theoretic regularizer for dynamics fitting rooted in the notion of stabilizability, a constraint which guarantees the existence of robust tracking controllers for arbitrary open-loop trajectories generated with the learned system. Leveraging tools from contraction theory and statistical learning in Reproducing Kernel Hilbert Spaces, we formulate stabilizable dynamics learning as a functional optimization with convex objective and bi-convex functional constraints. Under a mild structural assumption and relaxation of the functional constraints to sampling-based constraints, we derive the optimal solution with a modified Representer theorem. Finally, we utilize random matrix feature approximations to reduce the dimensionality of the search parameters and formulate an iterative convex optimization algorithm that jointly fits the dynamics functions and searches for a certificate of stabilizability. We validate the proposed algorithm in simulation for a planar quadrotor, and on a quadrotor hardware testbed emulating planar dynamics. We verify, both in simulation and on hardware, significantly improved trajectory generation and tracking performance with the control-theoretic regularized model over models learned using traditional regression techniques, especially when learning from small supervised datasets. The results support the conjecture that the use of stabilizability constraints as a form of regularization can help prune the hypothesis space in a manner that is tailored to the downstream task of trajectory generation and feedback control, resulting in models that are not only dramatically better conditioned, but also data efficient.
Improving Robustness of Machine Translation with Synthetic Noise
Apr 10, 2019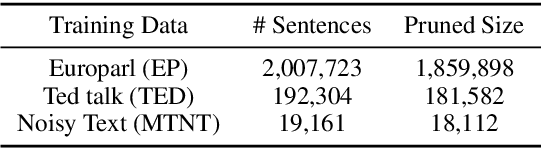

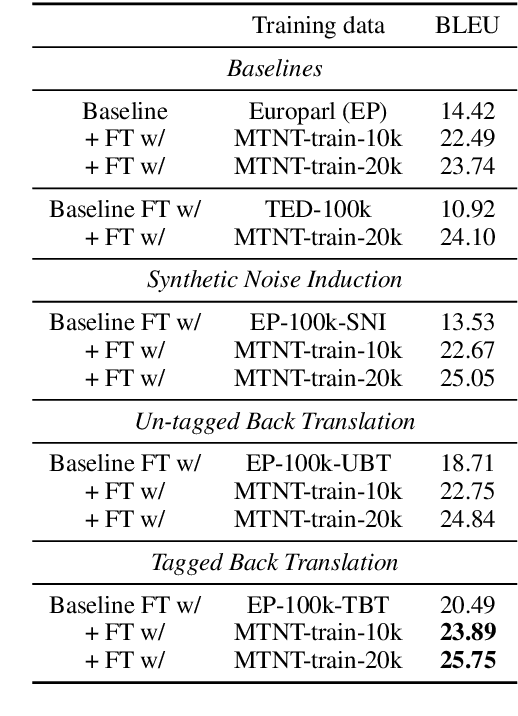
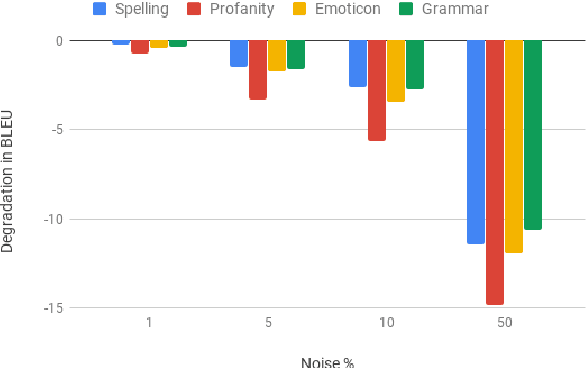
Modern Machine Translation (MT) systems perform consistently well on clean, in-domain text. However most human generated text, particularly in the realm of social media, is full of typos, slang, dialect, idiolect and other noise which can have a disastrous impact on the accuracy of output translation. In this paper we leverage the Machine Translation of Noisy Text (MTNT) dataset to enhance the robustness of MT systems by emulating naturally occurring noise in otherwise clean data. Synthesizing noise in this manner we are ultimately able to make a vanilla MT system resilient to naturally occurring noise and partially mitigate loss in accuracy resulting therefrom.
Learning Stabilizable Dynamical Systems via Control Contraction Metrics
Nov 11, 2018

We propose a novel framework for learning stabilizable nonlinear dynamical systems for continuous control tasks in robotics. The key idea is to develop a new control-theoretic regularizer for dynamics fitting rooted in the notion of stabilizability, which guarantees that the learned system can be accompanied by a robust controller capable of stabilizing any open-loop trajectory that the system may generate. By leveraging tools from contraction theory, statistical learning, and convex optimization, we provide a general and tractable semi-supervised algorithm to learn stabilizable dynamics, which can be applied to complex underactuated systems. We validated the proposed algorithm on a simulated planar quadrotor system and observed notably improved trajectory generation and tracking performance with the control-theoretic regularized model over models learned using traditional regression techniques, especially when using a small number of demonstration examples. The results presented illustrate the need to infuse standard model-based reinforcement learning algorithms with concepts drawn from nonlinear control theory for improved reliability.