 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Intelligibility Classifiers from 550k Disordered Speech Samples
Mar 15, 2023We developed dysarthric speech intelligibility classifiers on 551,176 disordered speech samples contributed by a diverse set of 468 speakers, with a range of self-reported speaking disorders and rated for their overall intelligibility on a five-point scale. We trained three models following different deep learning approaches and evaluated them on ~94K utterances from 100 speakers. We further found the models to generalize well (without further training) on the TORGO database (100% accuracy), UASpeech (0.93 correlation), ALS-TDI PMP (0.81 AUC) datasets as well as on a dataset of realistic unprompted speech we gathered (106 dysarthric and 76 control speakers,~2300 samples).
Clinical BERTScore: An Improved Measure of Automatic Speech Recognition Performance in Clinical Settings
Mar 13, 2023


Automatic Speech Recognition (ASR) in medical contexts has the potential to save time, cut costs, increase report accuracy, and reduce physician burnout. However, the healthcare industry has been slower to adopt this technology, in part due to the importance of avoiding medically-relevant transcription mistakes. In this work, we present the Clinical BERTScore (CBERTScore), an ASR metric that penalizes clinically-relevant mistakes more than others. We demonstrate that this metric more closely aligns with clinician preferences on medical sentences as compared to other metrics (WER, BLUE, METEOR, etc), sometimes by wide margins. We collect a benchmark of 13 clinician preferences on 149 realistic medical sentences called the Clinician Transcript Preference benchmark (CTP), demonstrate that CBERTScore more closely matches what clinicians prefer, and release the benchmark for the community to further develop clinically-aware ASR metrics.
Assessing ASR Model Quality on Disordered Speech using BERTScore
Sep 21, 2022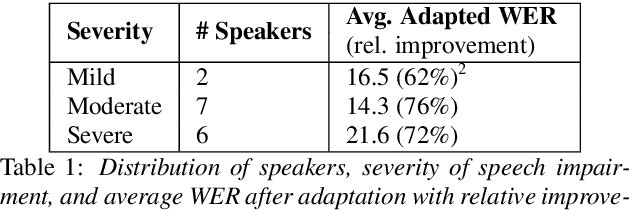
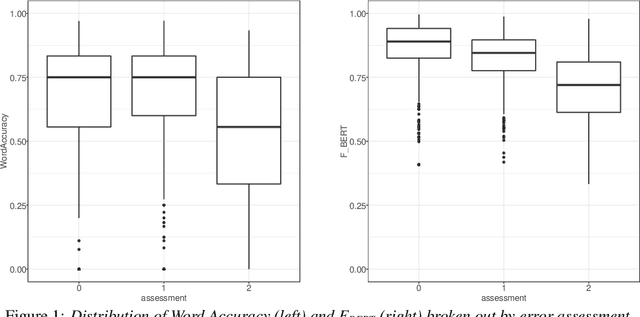
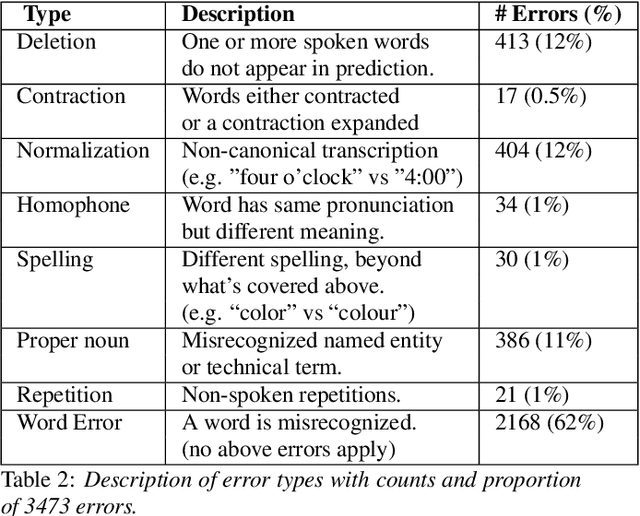
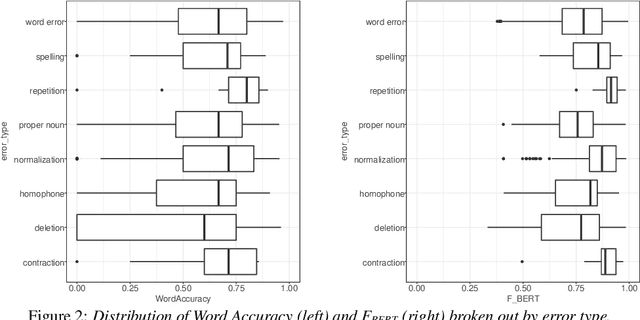
Word Error Rate (WER) is the primary metric used to assess automatic speech recognition (ASR) model quality. It has been shown that ASR models tend to have much higher WER on speakers with speech impairments than typical English speakers. It is hard to determine if models can be be useful at such high error rates. This study investigates the use of BERTScore, an evaluation metric for text generation, to provide a more informative measure of ASR model quality and usefulness. Both BERTScore and WER were compared to prediction errors manually annotated by Speech Language Pathologists for error type and assessment. BERTScore was found to be more correlated with human assessment of error type and assessment. BERTScore was specifically more robust to orthographic changes (contraction and normalization errors) where meaning was preserved. Furthermore, BERTScore was a better fit of error assessment than WER, as measured using an ordinal logistic regression and the Akaike's Information Criterion (AIC). Overall, our findings suggest that BERTScore can complement WER when assessing ASR model performance from a practical perspective, especially for accessibility applications where models are useful even at lower accuracy than for typical speech.
Is Attention All NeRF Needs?
Jul 27, 2022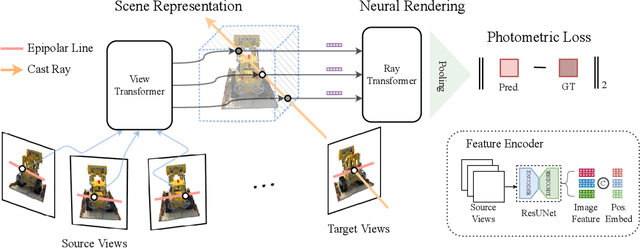
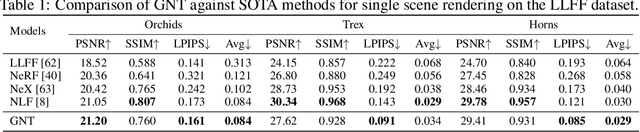
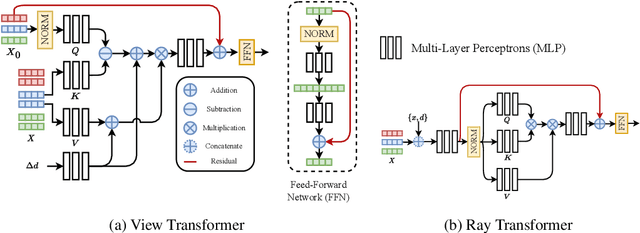
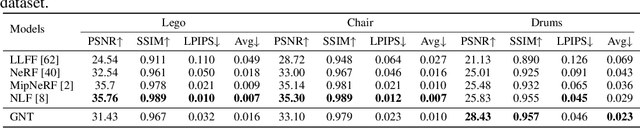
We present Generalizable NeRF Transformer (GNT), a pure, unified transformer-based architecture that efficiently reconstructs Neural Radiance Fields (NeRFs) on the fly from source views. Unlike prior works on NeRF that optimize a per-scene implicit representation by inverting a handcrafted rendering equation, GNT achieves generalizable neural scene representation and rendering, by encapsulating two transformer-based stages. The first stage of GNT, called view transformer, leverages multi-view geometry as an inductive bias for attention-based scene representation, and predicts coordinate-aligned features by aggregating information from epipolar lines on the neighboring views. The second stage of GNT, named ray transformer, renders novel views by ray marching and directly decodes the sequence of sampled point features using the attention mechanism. Our experiments demonstrate that when optimized on a single scene, GNT can successfully reconstruct NeRF without explicit rendering formula, and even improve the PSNR by ~1.3dB on complex scenes due to the learnable ray renderer. When trained across various scenes, GNT consistently achieves the state-of-the-art performance when transferring to forward-facing LLFF dataset (LPIPS ~20%, SSIM ~25%$) and synthetic blender dataset (LPIPS ~20%, SSIM ~4%). In addition, we show that depth and occlusion can be inferred from the learned attention maps, which implies that the pure attention mechanism is capable of learning a physically-grounded rendering process. All these results bring us one step closer to the tantalizing hope of utilizing transformers as the "universal modeling tool" even for graphics. Please refer to our project page for video results: https://vita-group.github.io/GNT/.
Context-Aware Abbreviation Expansion Using Large Language Models
May 11, 2022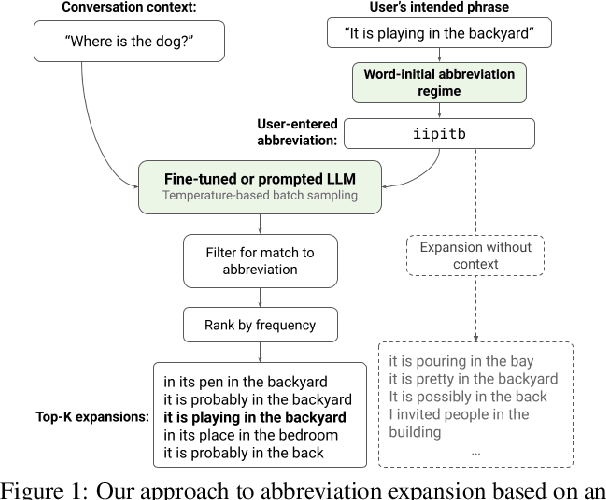


Motivated by the need for accelerating text entry in augmentative and alternative communication (AAC) for people with severe motor impairments, we propose a paradigm in which phrases are abbreviated aggressively as primarily word-initial letters. Our approach is to expand the abbreviations into full-phrase options by leveraging conversation context with the power of pretrained large language models (LLMs). Through zero-shot, few-shot, and fine-tuning experiments on four public conversation datasets, we show that for replies to the initial turn of a dialog, an LLM with 64B parameters is able to exactly expand over 70% of phrases with abbreviation length up to 10, leading to an effective keystroke saving rate of up to about 77% on these exact expansions. Including a small amount of context in the form of a single conversation turn more than doubles abbreviation expansion accuracies compared to having no context, an effect that is more pronounced for longer phrases. Additionally, the robustness of models against typo noise can be enhanced through fine-tuning on noisy data.
TRILLsson: Distilled Universal Paralinguistic Speech Representations
Mar 20, 2022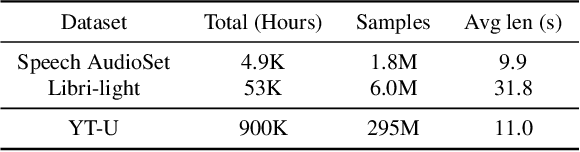
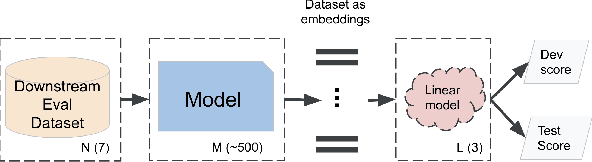
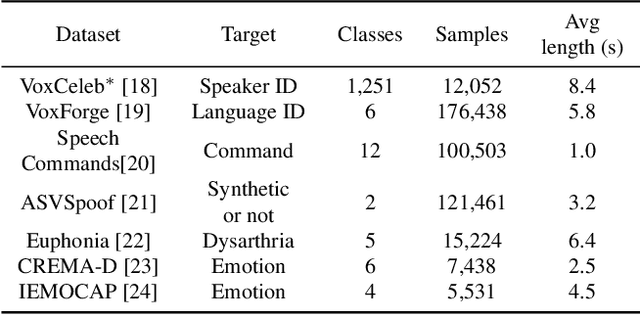
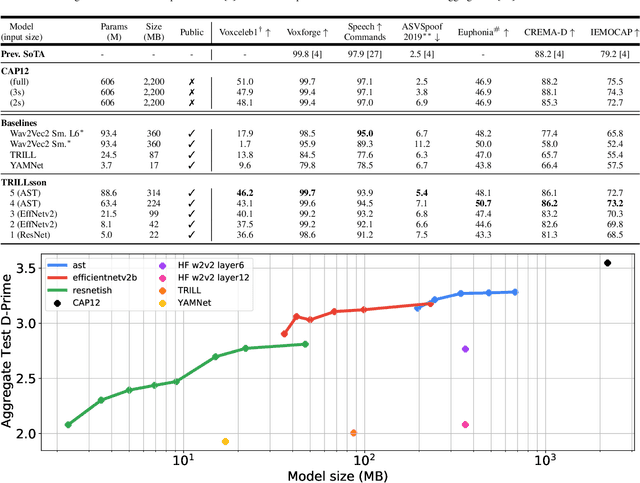
Recent advances in self-supervision have dramatically improved the quality of speech representations. However, deployment of state-of-the-art embedding models on devices has been restricted due to their limited public availability and large resource footprint. Our work addresses these issues by publicly releasing a collection of paralinguistic speech models that are small and near state-of-the-art performance. Our approach is based on knowledge distillation, and our models are distilled on public data only. We explore different architectures and thoroughly evaluate our models on the Non-Semantic Speech (NOSS) benchmark. Our largest distilled model is less than 15% the size of the original model (314MB vs 2.2GB), achieves over 96% the accuracy on 6 of 7 tasks, and is trained on 6.5% the data. The smallest model is 1% in size (22MB) and achieves over 90% the accuracy on 6 of 7 tasks. Our models outperform the open source Wav2Vec 2.0 model on 6 of 7 tasks, and our smallest model outperforms the open source Wav2Vec 2.0 on both emotion recognition tasks despite being 7% the size.
Using a Cross-Task Grid of Linear Probes to Interpret CNN Model Predictions On Retinal Images
Jul 23, 2021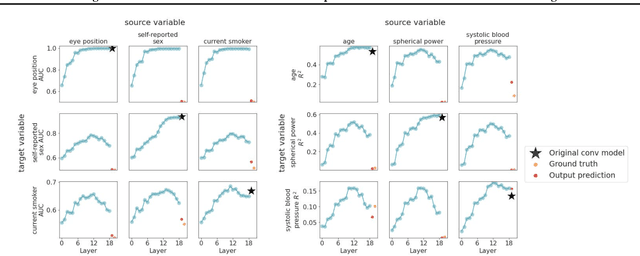
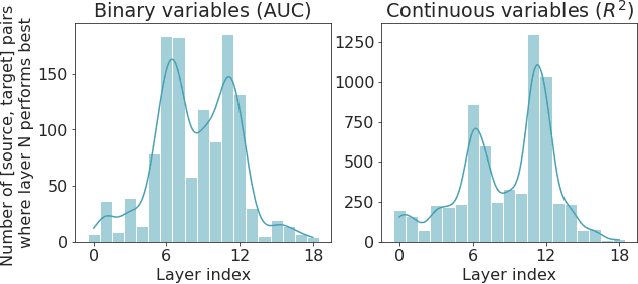
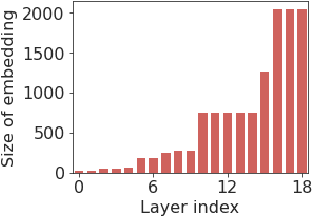
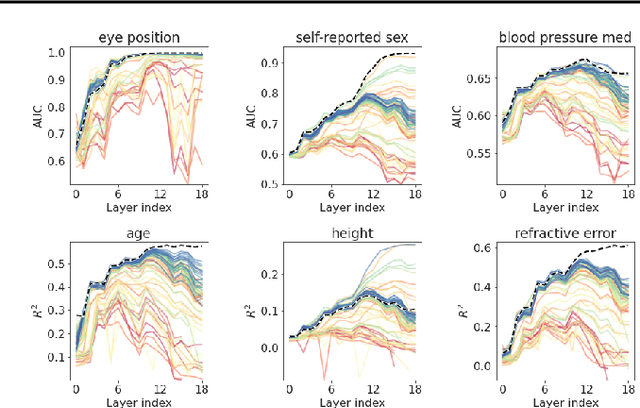
We analyze a dataset of retinal images using linear probes: linear regression models trained on some "target" task, using embeddings from a deep convolutional (CNN) model trained on some "source" task as input. We use this method across all possible pairings of 93 tasks in the UK Biobank dataset of retinal images, leading to ~164k different models. We analyze the performance of these linear probes by source and target task and by layer depth. We observe that representations from the middle layers of the network are more generalizable. We find that some target tasks are easily predicted irrespective of the source task, and that some other target tasks are more accurately predicted from correlated source tasks than from embeddings trained on the same task.
Comparing Supervised Models And Learned Speech Representations For Classifying Intelligibility Of Disordered Speech On Selected Phrases
Jul 08, 2021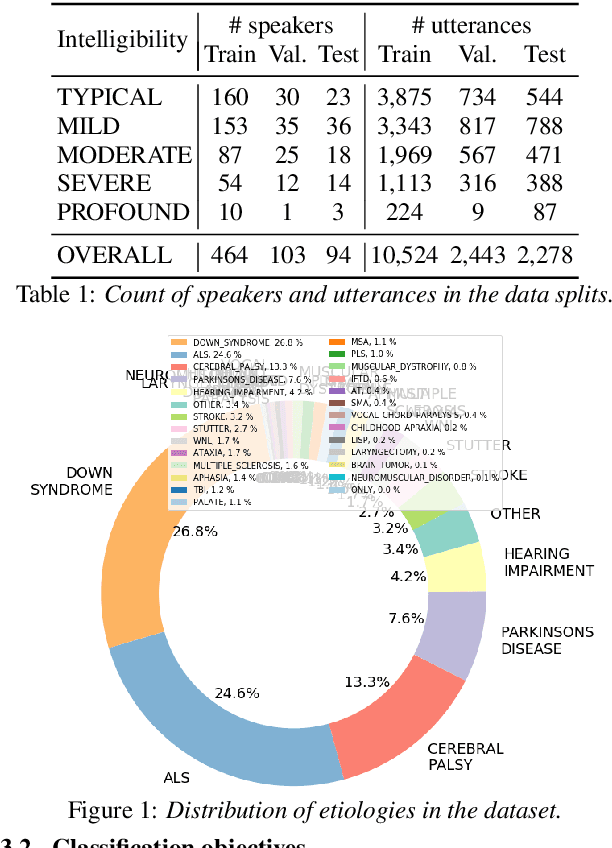
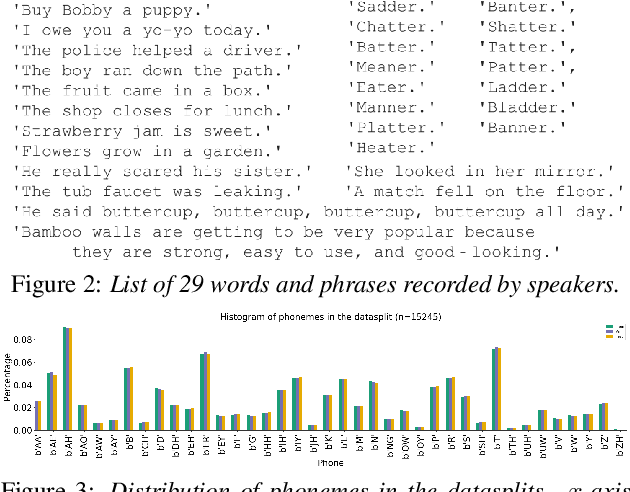
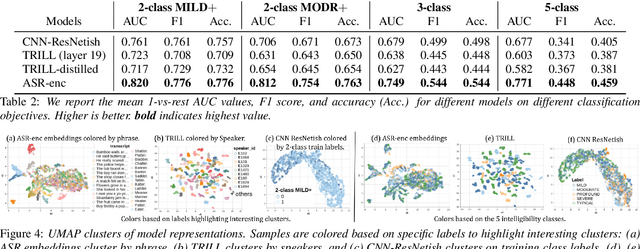
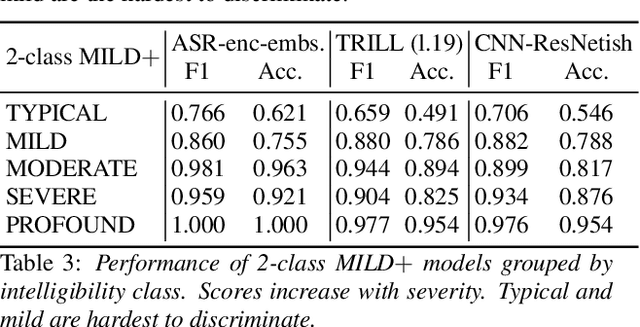
Automatic classification of disordered speech can provide an objective tool for identifying the presence and severity of speech impairment. Classification approaches can also help identify hard-to-recognize speech samples to teach ASR systems about the variable manifestations of impaired speech. Here, we develop and compare different deep learning techniques to classify the intelligibility of disordered speech on selected phrases. We collected samples from a diverse set of 661 speakers with a variety of self-reported disorders speaking 29 words or phrases, which were rated by speech-language pathologists for their overall intelligibility using a five-point Likert scale. We then evaluated classifiers developed using 3 approaches: (1) a convolutional neural network (CNN) trained for the task, (2) classifiers trained on non-semantic speech representations from CNNs that used an unsupervised objective [1], and (3) classifiers trained on the acoustic (encoder) embeddings from an ASR system trained on typical speech [2]. We found that the ASR encoder's embeddings considerably outperform the other two on detecting and classifying disordered speech. Further analysis shows that the ASR embeddings cluster speech by the spoken phrase, while the non-semantic embeddings cluster speech by speaker. Also, longer phrases are more indicative of intelligibility deficits than single words.
Guided Integrated Gradients: An Adaptive Path Method for Removing Noise
Jun 17, 2021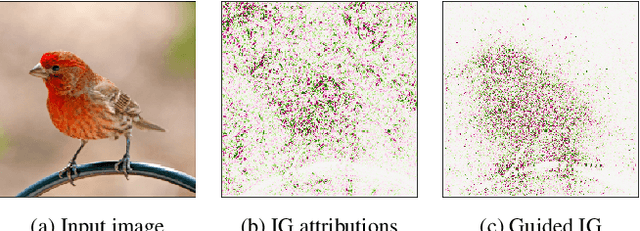
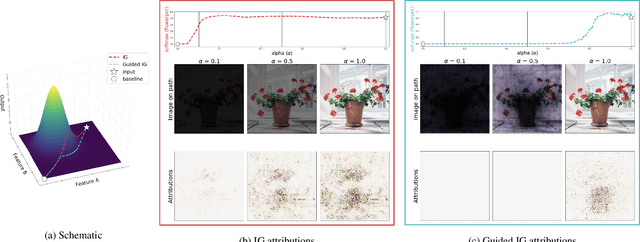
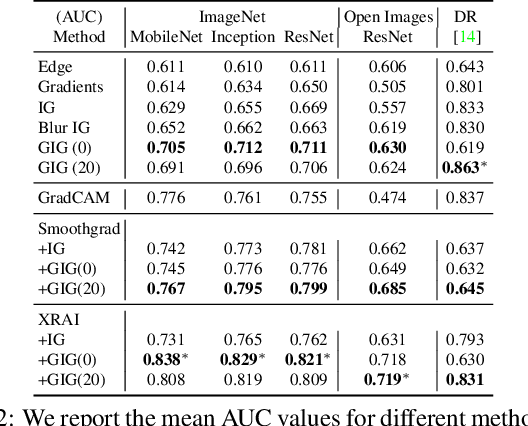
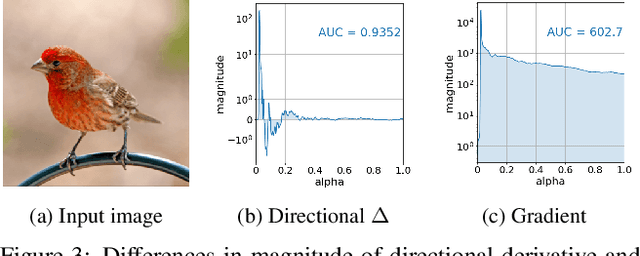
Integrated Gradients (IG) is a commonly used feature attribution method for deep neural networks. While IG has many desirable properties, the method often produces spurious/noisy pixel attributions in regions that are not related to the predicted class when applied to visual models. While this has been previously noted, most existing solutions are aimed at addressing the symptoms by explicitly reducing the noise in the resulting attributions. In this work, we show that one of the causes of the problem is the accumulation of noise along the IG path. To minimize the effect of this source of noise, we propose adapting the attribution path itself -- conditioning the path not just on the image but also on the model being explained. We introduce Adaptive Path Methods (APMs) as a generalization of path methods, and Guided IG as a specific instance of an APM. Empirically, Guided IG creates saliency maps better aligned with the model's prediction and the input image that is being explained. We show through qualitative and quantitative experiments that Guided IG outperforms other, related methods in nearly every experiment.
* 13 pages, 11 figures, for implementation sources see https://github.com/PAIR-code/saliency
Predicting Risk of Developing Diabetic Retinopathy using Deep Learning
Aug 10, 2020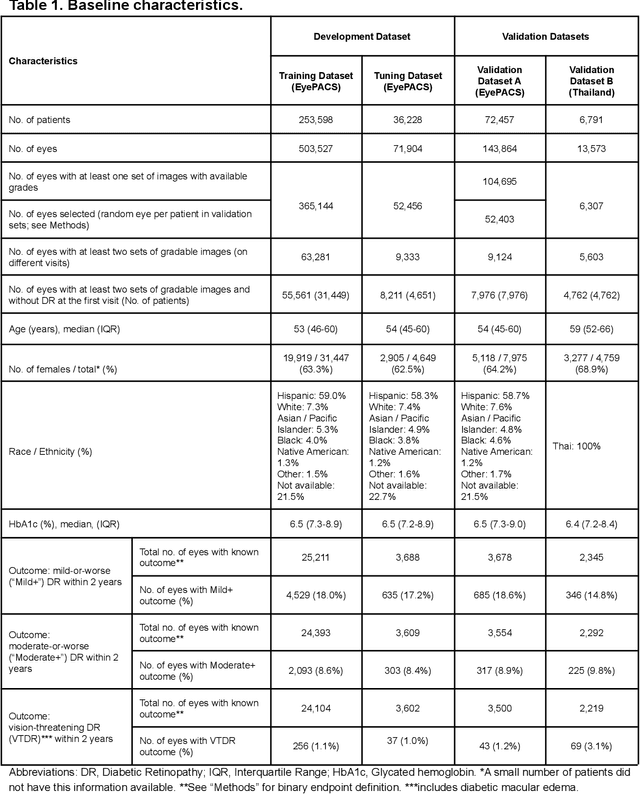
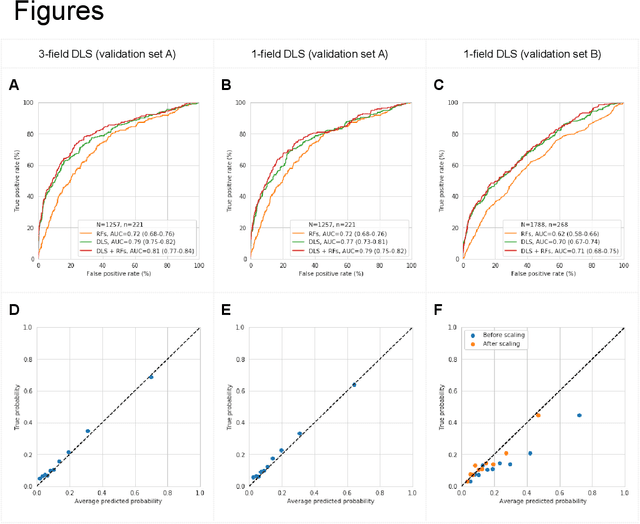
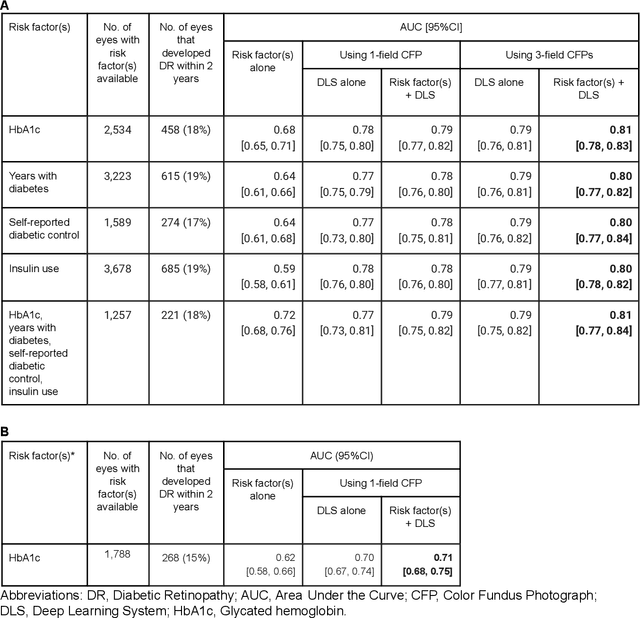
Diabetic retinopathy (DR) screening is instrumental in preventing blindness, but faces a scaling challenge as the number of diabetic patients rises. Risk stratification for the development of DR may help optimize screening intervals to reduce costs while improving vision-related outcomes. We created and validated two versions of a deep learning system (DLS) to predict the development of mild-or-worse ("Mild+") DR in diabetic patients undergoing DR screening. The two versions used either three-fields or a single field of color fundus photographs (CFPs) as input. The training set was derived from 575,431 eyes, of which 28,899 had known 2-year outcome, and the remaining were used to augment the training process via multi-task learning. Validation was performed on both an internal validation set (set A; 7,976 eyes; 3,678 with known outcome) and an external validation set (set B; 4,762 eyes; 2,345 with known outcome). For predicting 2-year development of DR, the 3-field DLS had an area under the receiver operating characteristic curve (AUC) of 0.79 (95%CI, 0.78-0.81) on validation set A. On validation set B (which contained only a single field), the 1-field DLS's AUC was 0.70 (95%CI, 0.67-0.74). The DLS was prognostic even after adjusting for available risk factors (p<0.001). When added to the risk factors, the 3-field DLS improved the AUC from 0.72 (95%CI, 0.68-0.76) to 0.81 (95%CI, 0.77-0.84) in validation set A, and the 1-field DLS improved the AUC from 0.62 (95%CI, 0.58-0.66) to 0.71 (95%CI, 0.68-0.75) in validation set B. The DLSs in this study identified prognostic information for DR development from CFPs. This information is independent of and more informative than the available risk factors.