 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden in plain sight: VLMs overlook their visual representations
Jun 09, 2025Language provides a natural interface to specify and evaluate performance on visual tasks. To realize this possibility, vision language models (VLMs) must successfully integrate visual and linguistic information. Our work compares VLMs to a direct readout of their visual encoders to understand their ability to integrate across these modalities. Across a series of vision-centric benchmarks (e.g., depth estimation, correspondence), we find that VLMs perform substantially worse than their visual encoders, dropping to near-chance performance. We investigate these results through a series of analyses across the entire VLM: namely 1) the degradation of vision representations, 2) brittleness to task prompt, and 3) the language model's role in solving the task. We find that the bottleneck in performing these vision-centric tasks lies in this third category; VLMs are not effectively using visual information easily accessible throughout the entire model, and they inherit the language priors present in the LLM. Our work helps diagnose the failure modes of open-source VLMs, and presents a series of evaluations useful for future investigations into visual understanding within VLMs.
What Makes for a Good Stereoscopic Image?
Dec 30, 2024



With rapid advancements in virtual reality (VR) headsets, effectively measuring stereoscopic quality of experience (SQoE) has become essential for delivering immersive and comfortable 3D experiences. However, most existing stereo metrics focus on isolated aspects of the viewing experience such as visual discomfort or image quality, and have traditionally faced data limitations. To address these gaps, we present SCOPE (Stereoscopic COntent Preference Evaluation), a new dataset comprised of real and synthetic stereoscopic images featuring a wide range of common perceptual distortions and artifacts. The dataset is labeled with preference annotations collected on a VR headset, with our findings indicating a notable degree of consistency in user preferences across different headsets. Additionally, we present iSQoE, a new model for stereo quality of experience assessment trained on our dataset. We show that iSQoE aligns better with human preferences than existing methods when comparing mono-to-stereo conversion methods.
When Does Perceptual Alignment Benefit Vision Representations?
Oct 14, 2024



Humans judge perceptual similarity according to diverse visual attributes, including scene layout, subject location, and camera pose. Existing vision models understand a wide range of semantic abstractions but improperly weigh these attributes and thus make inferences misaligned with human perception. While vision representations have previously benefited from alignment in contexts like image generation, the utility of perceptually aligned representations in more general-purpose settings remains unclear. Here, we investigate how aligning vision model representations to human perceptual judgments impacts their usability across diverse computer vision tasks. We finetune state-of-the-art models on human similarity judgments for image triplets and evaluate them across standard vision benchmarks. We find that aligning models to perceptual judgments yields representations that improve upon the original backbones across many downstream tasks, including counting, segmentation, depth estimation, instance retrieval, and retrieval-augmented generation. In addition, we find that performance is widely preserved on other tasks, including specialized out-of-distribution domains such as in medical imaging and 3D environment frames. Our results suggest that injecting an inductive bias about human perceptual knowledge into vision models can contribute to better representations.
Data-Centric AI Governance: Addressing the Limitations of Model-Focused Policies
Sep 25, 2024



Current regulations on powerful AI capabilities are narrowly focused on "foundation" or "frontier" models. However, these terms are vague and inconsistently defined, leading to an unstable foundation for governance efforts. Critically, policy debates often fail to consider the data used with these models, despite the clear link between data and model performance. Even (relatively) "small" models that fall outside the typical definitions of foundation and frontier models can achieve equivalent outcomes when exposed to sufficiently specific datasets. In this work, we illustrate the importance of considering dataset size and content as essential factors in assessing the risks posed by models both today and in the future. More broadly, we emphasize the risk posed by over-regulating reactively and provide a path towards careful, quantitative evaluation of capabilities that can lead to a simplified regulatory environment.
Evaluating Multiview Object Consistency in Humans and Image Models
Sep 10, 2024



We introduce a benchmark to directly evaluate the alignment between human observers and vision models on a 3D shape inference task. We leverage an experimental design from the cognitive sciences which requires zero-shot visual inferences about object shape: given a set of images, participants identify which contain the same/different objects, despite considerable viewpoint variation. We draw from a diverse range of images that include common objects (e.g., chairs) as well as abstract shapes (i.e., procedurally generated `nonsense' objects). After constructing over 2000 unique image sets, we administer these tasks to human participants, collecting 35K trials of behavioral data from over 500 participants. This includes explicit choice behaviors as well as intermediate measures, such as reaction time and gaze data. We then evaluate the performance of common vision models (e.g., DINOv2, MAE, CLIP). We find that humans outperform all models by a wide margin. Using a multi-scale evaluation approach, we identify underlying similarities and differences between models and humans: while human-model performance is correlated, humans allocate more time/processing on challenging trials. All images, data, and code can be accessed via our project page.
OpenStreetView-5M: The Many Roads to Global Visual Geolocation
Apr 29, 2024



Determining the location of an image anywhere on Earth is a complex visual task, which makes it particularly relevant for evaluating computer vision algorithms. Yet, the absence of standard, large-scale, open-access datasets with reliably localizable images has limited its potential. To address this issue, we introduce OpenStreetView-5M, a large-scale, open-access dataset comprising over 5.1 million geo-referenced street view images, covering 225 countries and territories. In contrast to existing benchmarks, we enforce a strict train/test separation, allowing us to evaluate the relevance of learned geographical features beyond mere memorization. To demonstrate the utility of our dataset, we conduct an extensive benchmark of various state-of-the-art image encoders, spatial representations, and training strategies. All associated codes and models can be found at https://github.com/gastruc/osv5m.
FeatUp: A Model-Agnostic Framework for Features at Any Resolution
Mar 15, 2024



Deep features are a cornerstone of computer vision research, capturing image semantics and enabling the community to solve downstream tasks even in the zero- or few-shot regime. However, these features often lack the spatial resolution to directly perform dense prediction tasks like segmentation and depth prediction because models aggressively pool information over large areas. In this work, we introduce FeatUp, a task- and model-agnostic framework to restore lost spatial information in deep features. We introduce two variants of FeatUp: one that guides features with high-resolution signal in a single forward pass, and one that fits an implicit model to a single image to reconstruct features at any resolution. Both approaches use a multi-view consistency loss with deep analogies to NeRFs. Our features retain their original semantics and can be swapped into existing applications to yield resolution and performance gains even without re-training. We show that FeatUp significantly outperforms other feature upsampling and image super-resolution approaches in class activation map generation, transfer learning for segmentation and depth prediction, and end-to-end training for semantic segmentation.
A Vision Check-up for Language Models
Jan 03, 2024



What does learning to model relationships between strings teach large language models (LLMs) about the visual world? We systematically evaluate LLMs' abilities to generate and recognize an assortment of visual concepts of increasing complexity and then demonstrate how a preliminary visual representation learning system can be trained using models of text. As language models lack the ability to consume or output visual information as pixels, we use code to represent images in our study. Although LLM-generated images do not look like natural images, results on image generation and the ability of models to correct these generated images indicate that precise modeling of strings can teach language models about numerous aspects of the visual world. Furthermore, experiments on self-supervised visual representation learning, utilizing images generated with text models, highlight the potential to train vision models capable of making semantic assessments of natural images using just LLMs.
DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data
Jun 26, 2023Current perceptual similarity metrics operate at the level of pixels and patches. These metrics compare images in terms of their low-level colors and textures, but fail to capture mid-level similarities and differences in image layout, object pose, and semantic content. In this paper, we develop a perceptual metric that assesses images holistically. Our first step is to collect a new dataset of human similarity judgments over image pairs that are alike in diverse ways. Critical to this dataset is that judgments are nearly automatic and shared by all observers. To achieve this we use recent text-to-image models to create synthetic pairs that are perturbed along various dimensions. We observe that popular perceptual metrics fall short of explaining our new data, and we introduce a new metric, DreamSim, tuned to better align with human perception. We analyze how our metric is affected by different visual attributes, and find that it focuses heavily on foreground objects and semantic content while also being sensitive to color and layout. Notably, despite being trained on synthetic data, our metric generalizes to real images, giving strong results on retrieval and reconstruction tasks. Furthermore, our metric outperforms both prior learned metrics and recent large vision models on these tasks.
Model-Agnostic Explainability for Visual Search
Feb 28, 2021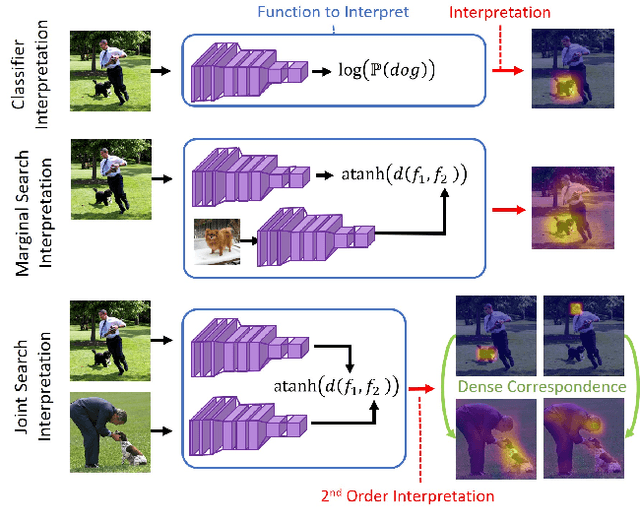
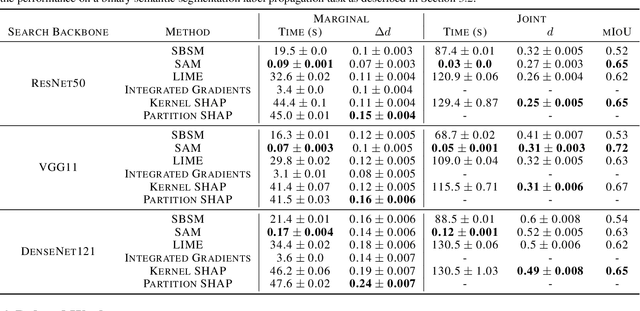


What makes two images similar? We propose new approaches to generate model-agnostic explanations for image similarity, search, and retrieval. In particular, we extend Class Activation Maps (CAMs), Additive Shapley Explanations (SHAP), and Locally Interpretable Model-Agnostic Explanations (LIME) to the domain of image retrieval and search. These approaches enable black and grey-box model introspection and can help diagnose errors and understand the rationale behind a model's similarity judgments. Furthermore, we extend these approaches to extract a full pairwise correspondence between the query and retrieved image pixels, an approach we call "joint interpretations". Formally, we show joint search interpretations arise from projecting Harsanyi dividends, and that this approach generalizes Shapley Values and The Shapley-Taylor indices. We introduce a fast kernel-based method for estimating Shapley-Taylor indices and empirically show that these game-theoretic measures yield more consistent explanations for image similarity architectures.