 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSABER: Data-Driven Motion Planner for Autonomously Navigating Heterogeneous Robots
Aug 03, 2021
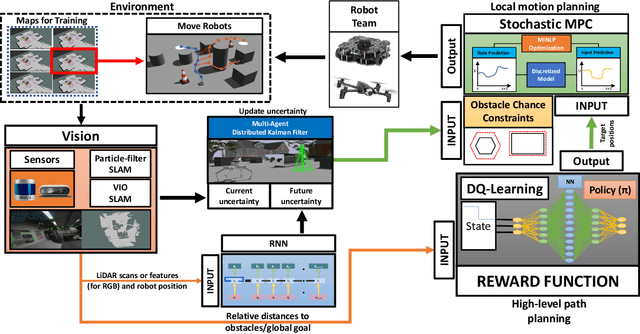
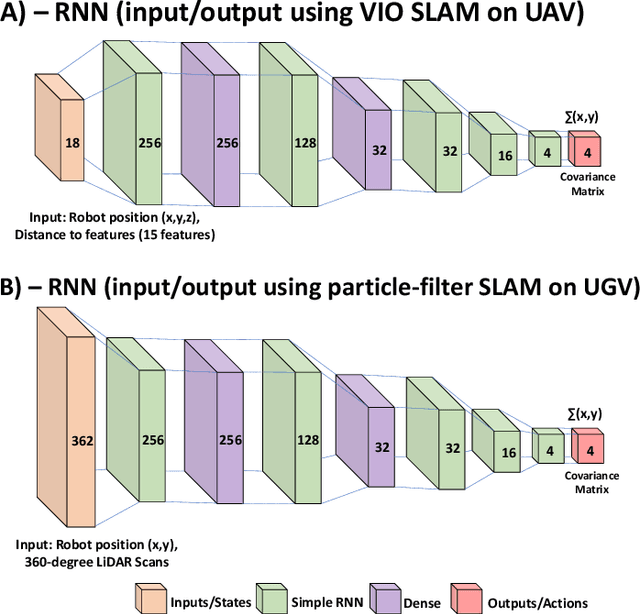
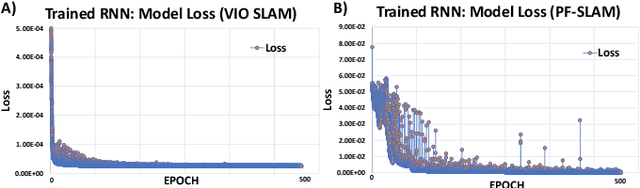
We present an end-to-end online motion planning framework that uses a data-driven approach to navigate a heterogeneous robot team towards a global goal while avoiding obstacles in uncertain environments. First, we use stochastic model predictive control (SMPC) to calculate control inputs that satisfy robot dynamics, and consider uncertainty during obstacle avoidance with chance constraints. Second, recurrent neural networks are used to provide a quick estimate of future state uncertainty considered in the SMPC finite-time horizon solution, which are trained on uncertainty outputs of various simultaneous localization and mapping algorithms. When two or more robots are in communication range, these uncertainties are then updated using a distributed Kalman filtering approach. Lastly, a Deep Q-learning agent is employed to serve as a high-level path planner, providing the SMPC with target positions that move the robots towards a desired global goal. Our complete methods are demonstrated on a ground and aerial robot simultaneously (code available at: https://github.com/AlexS28/SABER).
Learning Hierarchical Graph Neural Networks for Image Clustering
Jul 17, 2021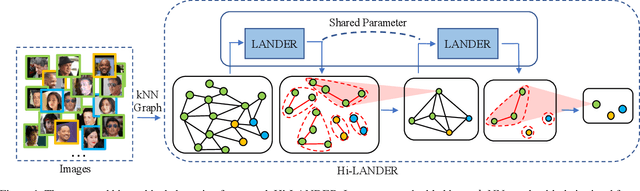
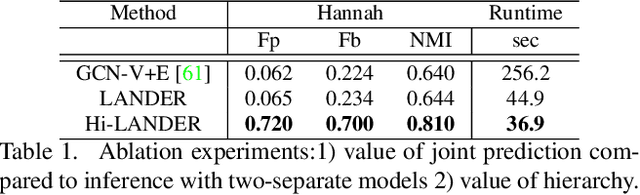
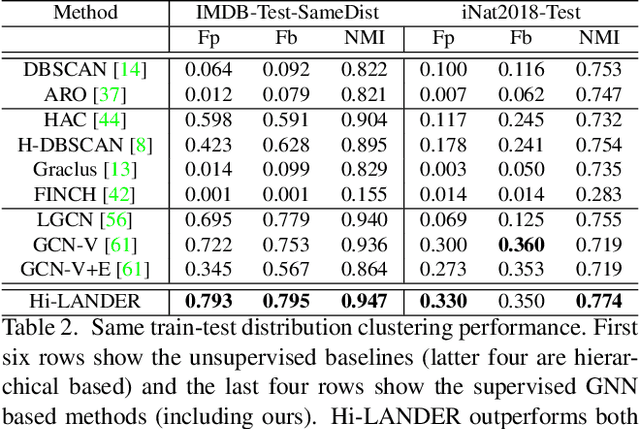
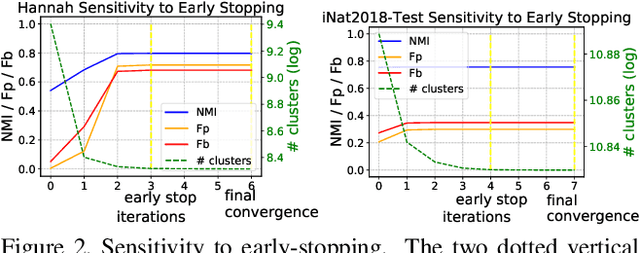
We propose a hierarchical graph neural network (GNN) model that learns how to cluster a set of images into an unknown number of identities using a training set of images annotated with labels belonging to a disjoint set of identities. Our hierarchical GNN uses a novel approach to merge connected components predicted at each level of the hierarchy to form a new graph at the next level. Unlike fully unsupervised hierarchical clustering, the choice of grouping and complexity criteria stems naturally from supervision in the training set. The resulting method, Hi-LANDER, achieves an average of 54% improvement in F-score and 8% increase in Normalized Mutual Information (NMI) relative to current GNN-based clustering algorithms. Additionally, state-of-the-art GNN-based methods rely on separate models to predict linkage probabilities and node densities as intermediate steps of the clustering process. In contrast, our unified framework achieves a seven-fold decrease in computational cost. We release our training and inference code at https://github.com/dmlc/dgl/tree/master/examples/pytorch/hilander.
Representation Consolidation for Training Expert Students
Jul 16, 2021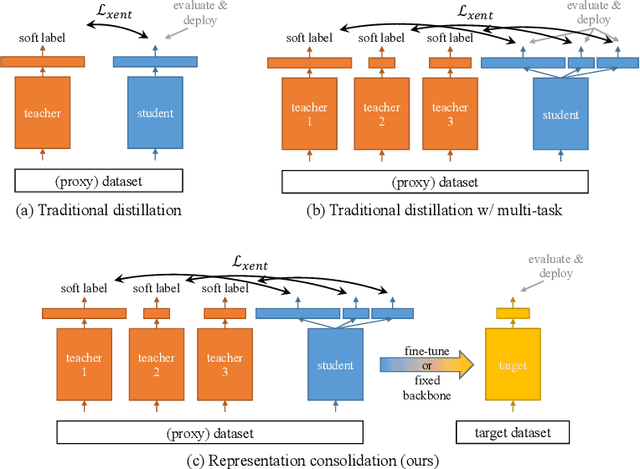

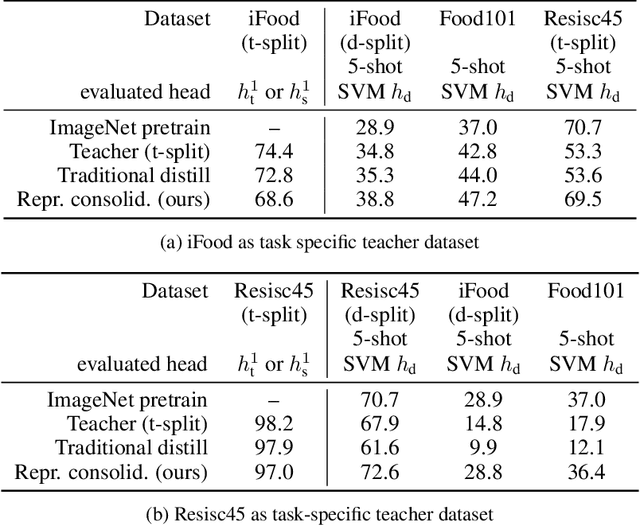

Traditionally, distillation has been used to train a student model to emulate the input/output functionality of a teacher. A more useful goal than emulation, yet under-explored, is for the student to learn feature representations that transfer well to future tasks. However, we observe that standard distillation of task-specific teachers actually *reduces* the transferability of student representations to downstream tasks. We show that a multi-head, multi-task distillation method using an unlabeled proxy dataset and a generalist teacher is sufficient to consolidate representations from task-specific teacher(s) and improve downstream performance, outperforming the teacher(s) and the strong baseline of ImageNet pretrained features. Our method can also combine the representational knowledge of multiple teachers trained on one or multiple domains into a single model, whose representation is improved on all teachers' domain(s).
Long Short-Term Transformer for Online Action Detection
Jul 07, 2021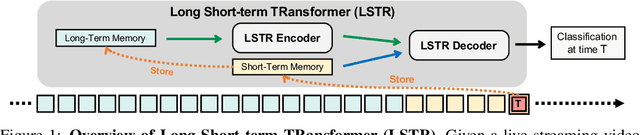
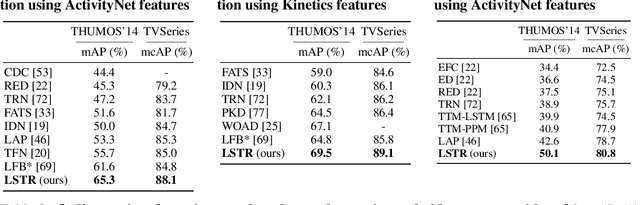
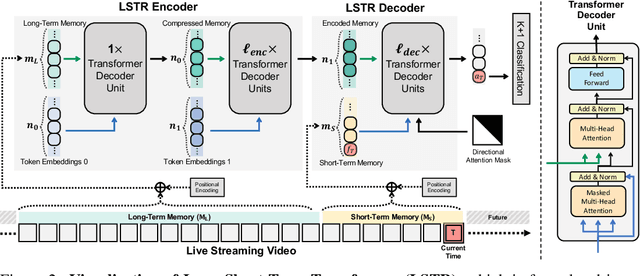
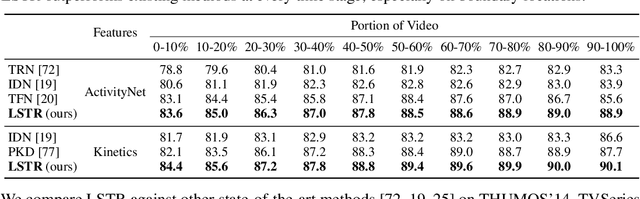
In this paper, we present Long Short-term TRansformer (LSTR), a new temporal modeling algorithm for online action detection, by employing a long- and short-term memories mechanism that is able to model prolonged sequence data. It consists of an LSTR encoder that is capable of dynamically exploiting coarse-scale historical information from an extensively long time window (e.g., 2048 long-range frames of up to 8 minutes), together with an LSTR decoder that focuses on a short time window (e.g., 32 short-range frames of 8 seconds) to model the fine-scale characterization of the ongoing event. Compared to prior work, LSTR provides an effective and efficient method to model long videos with less heuristic algorithm design. LSTR achieves significantly improved results on standard online action detection benchmarks, THUMOS'14, TVSeries, and HACS Segment, over the existing state-of-the-art approaches. Extensive empirical analysis validates the setup of the long- and short-term memories and the design choices of LSTR.
Scene Uncertainty and the Wellington Posterior of Deterministic Image Classifiers
Jun 25, 2021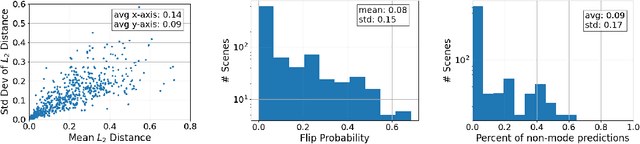
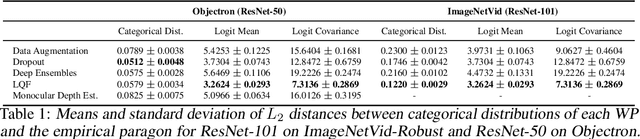
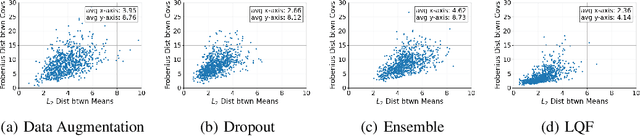
We propose a method to estimate the uncertainty of the outcome of an image classifier on a given input datum. Deep neural networks commonly used for image classification are deterministic maps from an input image to an output class. As such, their outcome on a given datum involves no uncertainty, so we must specify what variability we are referring to when defining, measuring and interpreting "confidence." To this end, we introduce the Wellington Posterior, which is the distribution of outcomes that would have been obtained in response to data that could have been generated by the same scene that produced the given image. Since there are infinitely many scenes that could have generated the given image, the Wellington Posterior requires induction from scenes other than the one portrayed. We explore alternate methods using data augmentation, ensembling, and model linearization. Additional alternatives include generative adversarial networks, conditional prior networks, and supervised single-view reconstruction. We test these alternatives against the empirical posterior obtained by inferring the class of temporally adjacent frames in a video. These developments are only a small step towards assessing the reliability of deep network classifiers in a manner that is compatible with safety-critical applications.
Dynamically Grown Generative Adversarial Networks
Jun 16, 2021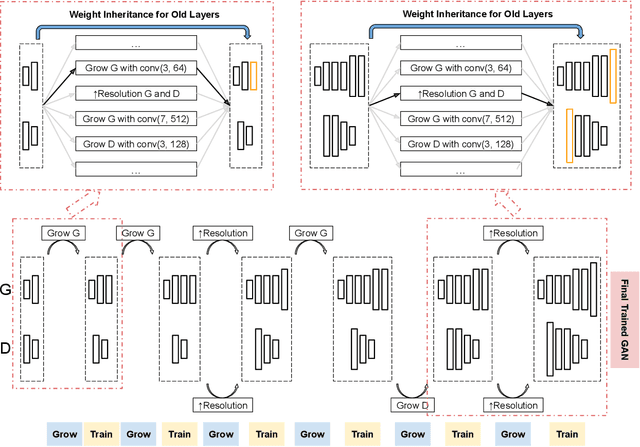
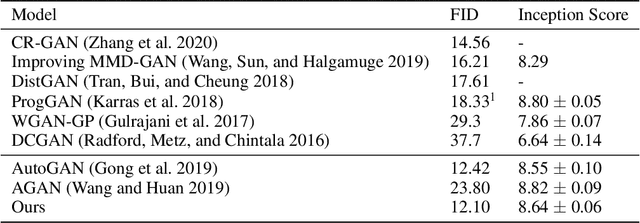


Recent work introduced progressive network growing as a promising way to ease the training for large GANs, but the model design and architecture-growing strategy still remain under-explored and needs manual design for different image data. In this paper, we propose a method to dynamically grow a GAN during training, optimizing the network architecture and its parameters together with automation. The method embeds architecture search techniques as an interleaving step with gradient-based training to periodically seek the optimal architecture-growing strategy for the generator and discriminator. It enjoys the benefits of both eased training because of progressive growing and improved performance because of broader architecture design space. Experimental results demonstrate new state-of-the-art of image generation. Observations in the search procedure also provide constructive insights into the GAN model design such as generator-discriminator balance and convolutional layer choices.
Harnessing Unrecognizable Faces for Face Recognition
Jun 08, 2021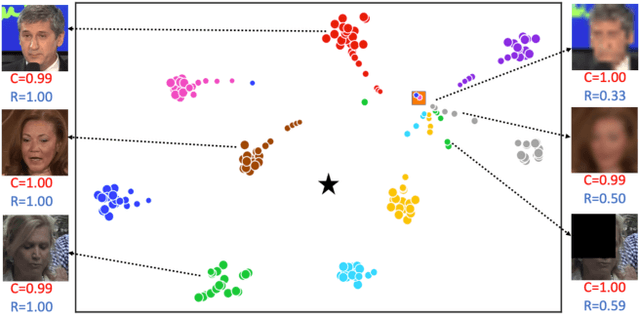
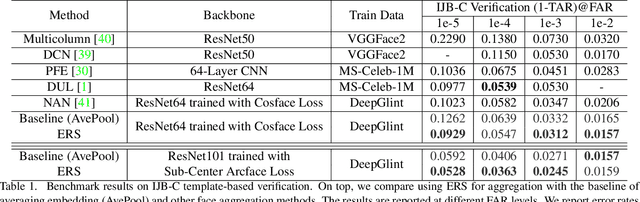

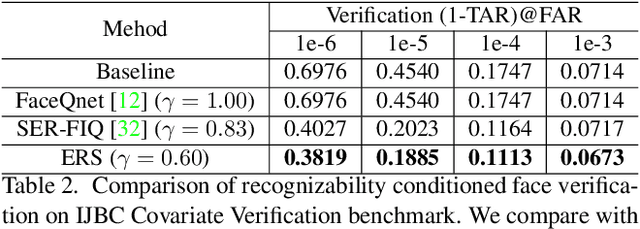
The common implementation of face recognition systems as a cascade of a detection stage and a recognition or verification stage can cause problems beyond failures of the detector. When the detector succeeds, it can detect faces that cannot be recognized, no matter how capable the recognition system. Recognizability, a latent variable, should therefore be factored into the design and implementation of face recognition systems. We propose a measure of recognizability of a face image that leverages a key empirical observation: an embedding of face images, implemented by a deep neural network trained using mostly recognizable identities, induces a partition of the hypersphere whereby unrecognizable identities cluster together. This occurs regardless of the phenomenon that causes a face to be unrecognizable, it be optical or motion blur, partial occlusion, spatial quantization, poor illumination. Therefore, we use the distance from such an "unrecognizable identity" as a measure of recognizability, and incorporate it in the design of the over-all system. We show that accounting for recognizability reduces error rate of single-image face recognition by 58% at FAR=1e-5 on the IJB-C Covariate Verification benchmark, and reduces verification error rate by 24% at FAR=1e-5 in set-based recognition on the IJB-C benchmark.
An Adaptive Framework for Learning Unsupervised Depth Completion
Jun 06, 2021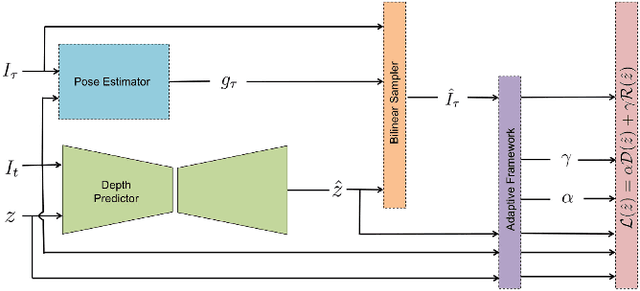

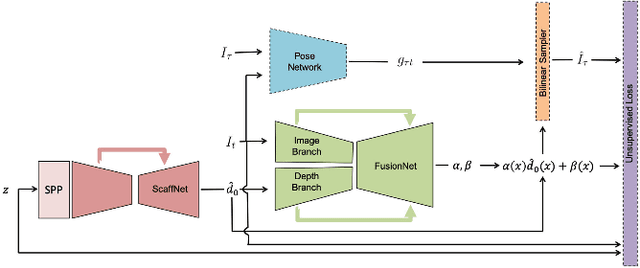
We present a method to infer a dense depth map from a color image and associated sparse depth measurements. Our main contribution lies in the design of an annealing process for determining co-visibility (occlusions, disocclusions) and the degree of regularization to impose on the model. We show that regularization and co-visibility are related via the fitness (residual) of model to data and both can be unified into a single framework to improve the learning process. Our method is an adaptive weighting scheme that guides optimization by measuring the residual at each pixel location over each training step for (i) estimating a soft visibility mask and (ii) determining the amount of regularization. We demonstrate the effectiveness our method by applying it to several recent unsupervised depth completion methods and improving their performance on public benchmark datasets, without incurring additional trainable parameters or increase in inference time. Code available at: https://github.com/alexklwong/adaframe-depth-completion.
Learning Topology from Synthetic Data for Unsupervised Depth Completion
Jun 06, 2021
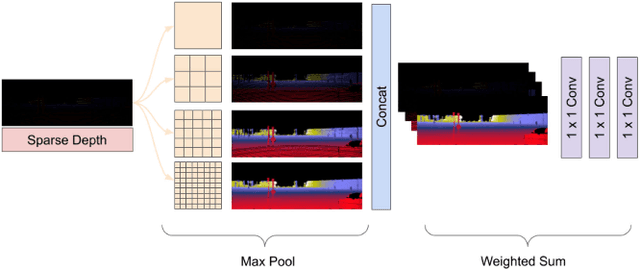

We present a method for inferring dense depth maps from images and sparse depth measurements by leveraging synthetic data to learn the association of sparse point clouds with dense natural shapes, and using the image as evidence to validate the predicted depth map. Our learned prior for natural shapes uses only sparse depth as input, not images, so the method is not affected by the covariate shift when attempting to transfer learned models from synthetic data to real ones. This allows us to use abundant synthetic data with ground truth to learn the most difficult component of the reconstruction process, which is topology estimation, and use the image to refine the prediction based on photometric evidence. Our approach uses fewer parameters than previous methods, yet, achieves the state of the art on both indoor and outdoor benchmark datasets. Code available at: https://github.com/alexklwong/learning-topology-synthetic-data.
Compatibility-aware Heterogeneous Visual Search
May 13, 2021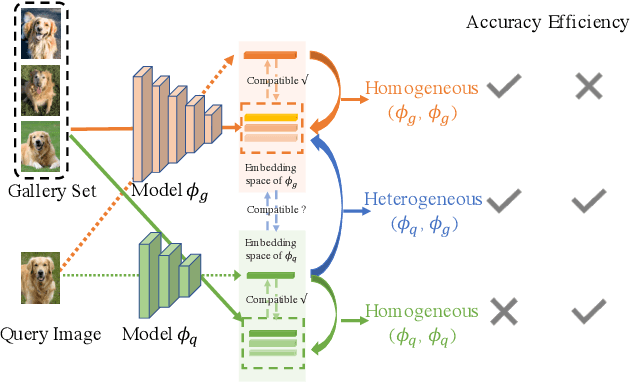

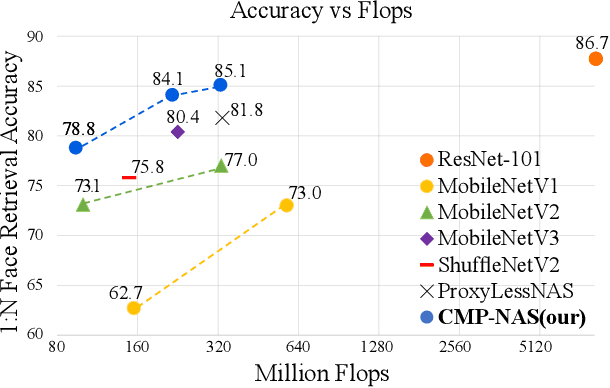
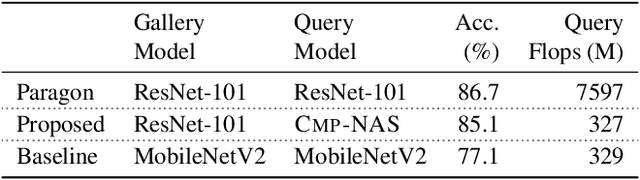
We tackle the problem of visual search under resource constraints. Existing systems use the same embedding model to compute representations (embeddings) for the query and gallery images. Such systems inherently face a hard accuracy-efficiency trade-off: the embedding model needs to be large enough to ensure high accuracy, yet small enough to enable query-embedding computation on resource-constrained platforms. This trade-off could be mitigated if gallery embeddings are generated from a large model and query embeddings are extracted using a compact model. The key to building such a system is to ensure representation compatibility between the query and gallery models. In this paper, we address two forms of compatibility: One enforced by modifying the parameters of each model that computes the embeddings. The other by modifying the architectures that compute the embeddings, leading to compatibility-aware neural architecture search (CMP-NAS). We test CMP-NAS on challenging retrieval tasks for fashion images (DeepFashion2), and face images (IJB-C). Compared to ordinary (homogeneous) visual search using the largest embedding model (paragon), CMP-NAS achieves 80-fold and 23-fold cost reduction while maintaining accuracy within 0.3% and 1.6% of the paragon on DeepFashion2 and IJB-C respectively.