 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIQ-Learn: Inverse soft-Q Learning for Imitation
Jun 23, 2021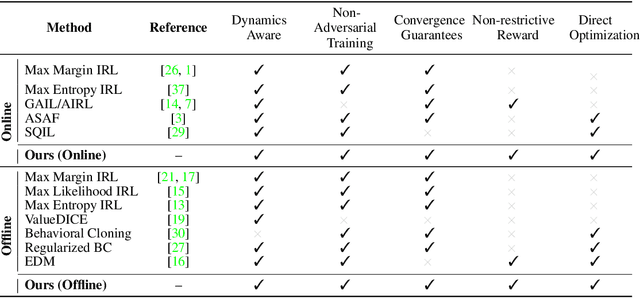
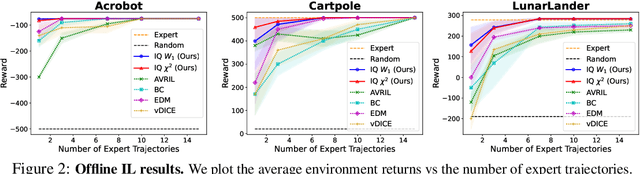
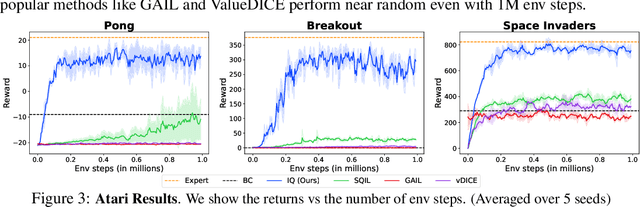
In many sequential decision-making problems (e.g., robotics control, game playing, sequential prediction), human or expert data is available containing useful information about the task. However, imitation learning (IL) from a small amount of expert data can be challenging in high-dimensional environments with complex dynamics. Behavioral cloning is a simple method that is widely used due to its simplicity of implementation and stable convergence but doesn't utilize any information involving the environment's dynamics. Many existing methods that exploit dynamics information are difficult to train in practice due to an adversarial optimization process over reward and policy approximators or biased, high variance gradient estimators. We introduce a method for dynamics-aware IL which avoids adversarial training by learning a single Q-function, implicitly representing both reward and policy. On standard benchmarks, the implicitly learned rewards show a high positive correlation with the ground-truth rewards, illustrating our method can also be used for inverse reinforcement learning (IRL). Our method, Inverse soft-Q learning (IQ-Learn) obtains state-of-the-art results in offline and online imitation learning settings, surpassing existing methods both in the number of required environment interactions and scalability in high-dimensional spaces.
Spatial-Temporal Super-Resolution of Satellite Imagery via Conditional Pixel Synthesis
Jun 22, 2021
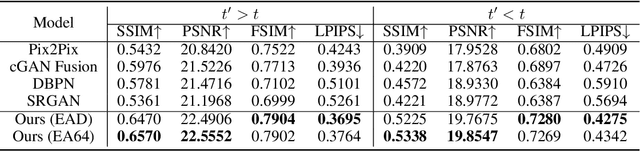
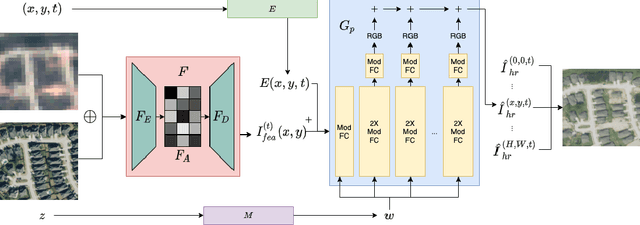

High-resolution satellite imagery has proven useful for a broad range of tasks, including measurement of global human population, local economic livelihoods, and biodiversity, among many others. Unfortunately, high-resolution imagery is both infrequently collected and expensive to purchase, making it hard to efficiently and effectively scale these downstream tasks over both time and space. We propose a new conditional pixel synthesis model that uses abundant, low-cost, low-resolution imagery to generate accurate high-resolution imagery at locations and times in which it is unavailable. We show that our model attains photo-realistic sample quality and outperforms competing baselines on a key downstream task -- object counting -- particularly in geographic locations where conditions on the ground are changing rapidly.
Temporal Predictive Coding For Model-Based Planning In Latent Space
Jun 14, 2021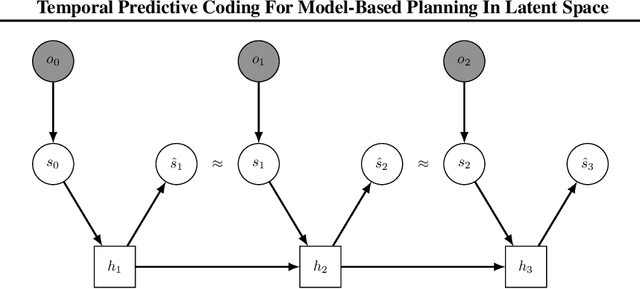
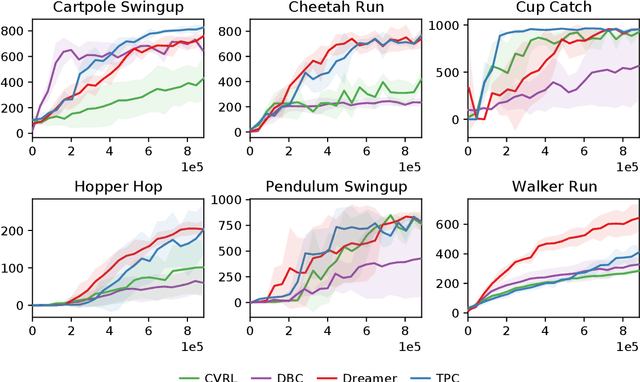
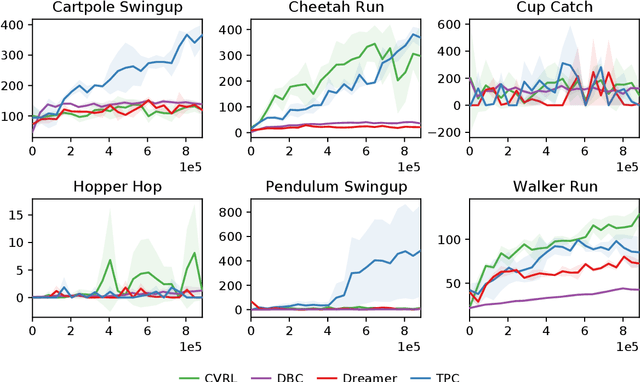
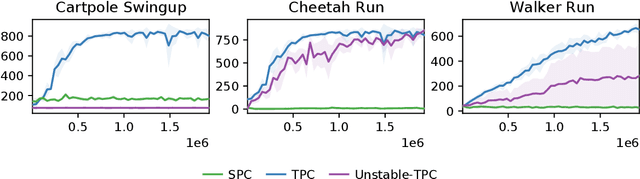
High-dimensional observations are a major challenge in the application of model-based reinforcement learning (MBRL) to real-world environments. To handle high-dimensional sensory inputs, existing approaches use representation learning to map high-dimensional observations into a lower-dimensional latent space that is more amenable to dynamics estimation and planning. In this work, we present an information-theoretic approach that employs temporal predictive coding to encode elements in the environment that can be predicted across time. Since this approach focuses on encoding temporally-predictable information, we implicitly prioritize the encoding of task-relevant components over nuisance information within the environment that are provably task-irrelevant. By learning this representation in conjunction with a recurrent state space model, we can then perform planning in latent space. We evaluate our model on a challenging modification of standard DMControl tasks where the background is replaced with natural videos that contain complex but irrelevant information to the planning task. Our experiments show that our model is superior to existing methods in the challenging complex-background setting while remaining competitive with current state-of-the-art models in the standard setting.
D2C: Diffusion-Denoising Models for Few-shot Conditional Generation
Jun 12, 2021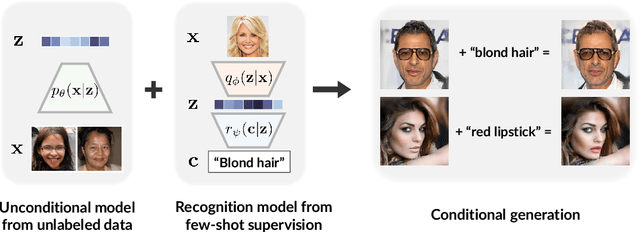
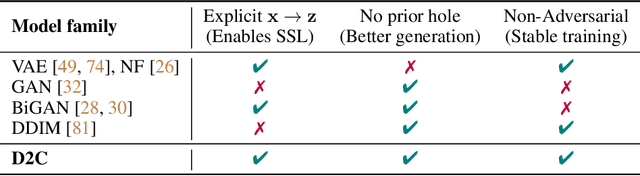
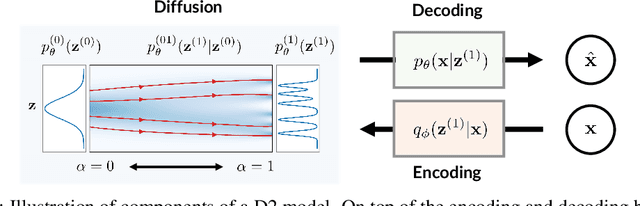
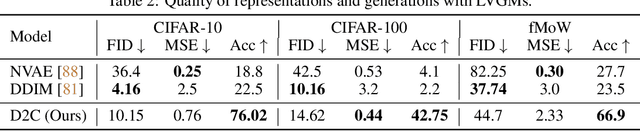
Conditional generative models of high-dimensional images have many applications, but supervision signals from conditions to images can be expensive to acquire. This paper describes Diffusion-Decoding models with Contrastive representations (D2C), a paradigm for training unconditional variational autoencoders (VAEs) for few-shot conditional image generation. D2C uses a learned diffusion-based prior over the latent representations to improve generation and contrastive self-supervised learning to improve representation quality. D2C can adapt to novel generation tasks conditioned on labels or manipulation constraints, by learning from as few as 100 labeled examples. On conditional generation from new labels, D2C achieves superior performance over state-of-the-art VAEs and diffusion models. On conditional image manipulation, D2C generations are two orders of magnitude faster to produce over StyleGAN2 ones and are preferred by 50% - 60% of the human evaluators in a double-blind study.
Improving Compositionality of Neural Networks by Decoding Representations to Inputs
Jun 01, 2021
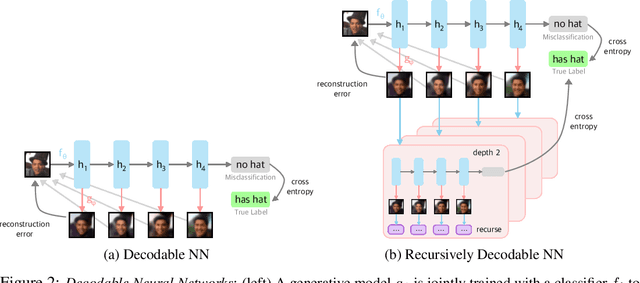
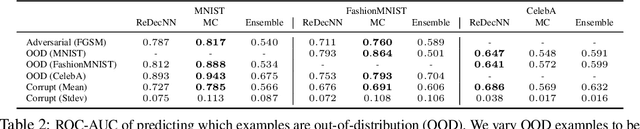

In traditional software programs, we take for granted how easy it is to debug code by tracing program logic from variables back to input, apply unit tests and assertion statements to block erroneous behavior, and compose programs together. But as the programs we write grow more complex, it becomes hard to apply traditional software to applications like computer vision or natural language. Although deep learning programs have demonstrated strong performance on these applications, they sacrifice many of the functionalities of traditional software programs. In this paper, we work towards bridging the benefits of traditional and deep learning programs by jointly training a generative model to constrain neural network activations to "decode" back to inputs. Doing so enables practitioners to probe and track information encoded in activation(s), apply assertion-like constraints on what information is encoded in an activation, and compose separate neural networks together in a plug-and-play fashion. In our experiments, we demonstrate applications of decodable representations to out-of-distribution detection, adversarial examples, calibration, and fairness -- while matching standard neural networks in accuracy.
Bayesian Algorithm Execution: Estimating Computable Properties of Black-box Functions Using Mutual Information
Apr 19, 2021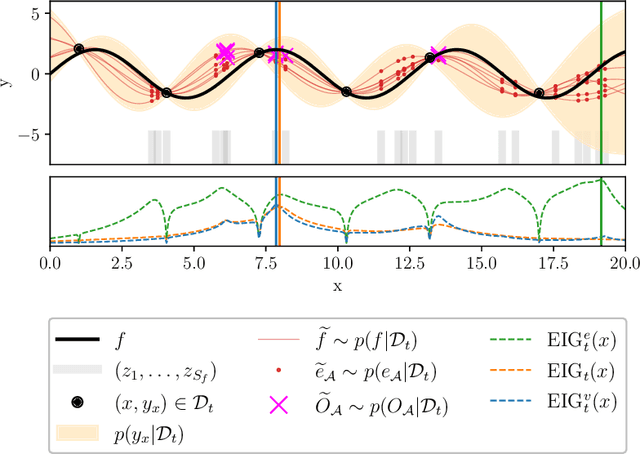

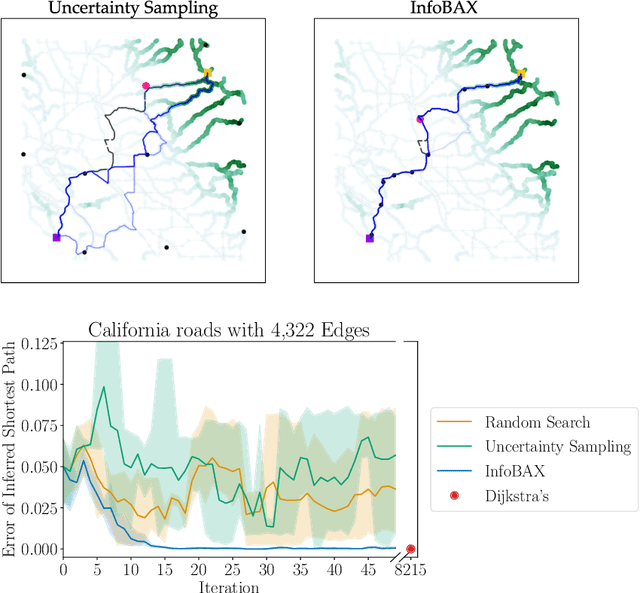
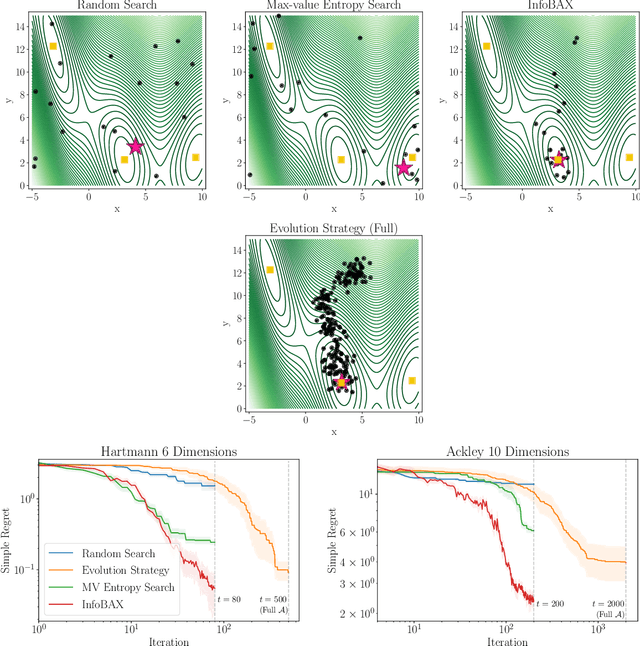
In many real world problems, we want to infer some property of an expensive black-box function f, given a budget of T function evaluations. One example is budget constrained global optimization of f, for which Bayesian optimization is a popular method. Other properties of interest include local optima, level sets, integrals, or graph-structured information induced by f. Often, we can find an algorithm A to compute the desired property, but it may require far more than T queries to execute. Given such an A, and a prior distribution over f, we refer to the problem of inferring the output of A using T evaluations as Bayesian Algorithm Execution (BAX). To tackle this problem, we present a procedure, InfoBAX, that sequentially chooses queries that maximize mutual information with respect to the algorithm's output. Applying this to Dijkstra's algorithm, for instance, we infer shortest paths in synthetic and real-world graphs with black-box edge costs. Using evolution strategies, we yield variants of Bayesian optimization that target local, rather than global, optima. On these problems, InfoBAX uses up to 500 times fewer queries to f than required by the original algorithm. Our method is closely connected to other Bayesian optimal experimental design procedures such as entropy search methods and optimal sensor placement using Gaussian processes.
On the Critical Role of Conventions in Adaptive Human-AI Collaboration
Apr 07, 2021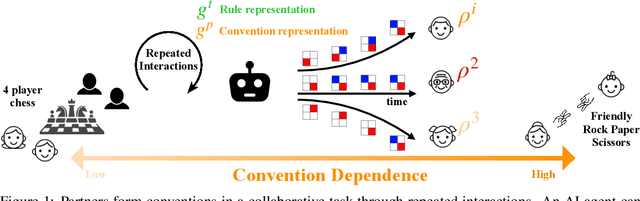
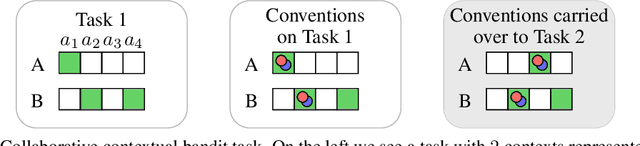
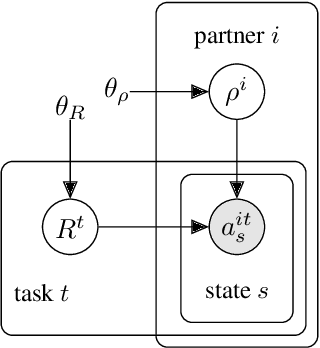
Humans can quickly adapt to new partners in collaborative tasks (e.g. playing basketball), because they understand which fundamental skills of the task (e.g. how to dribble, how to shoot) carry over across new partners. Humans can also quickly adapt to similar tasks with the same partners by carrying over conventions that they have developed (e.g. raising hand signals pass the ball), without learning to coordinate from scratch. To collaborate seamlessly with humans, AI agents should adapt quickly to new partners and new tasks as well. However, current approaches have not attempted to distinguish between the complexities intrinsic to a task and the conventions used by a partner, and more generally there has been little focus on leveraging conventions for adapting to new settings. In this work, we propose a learning framework that teases apart rule-dependent representation from convention-dependent representation in a principled way. We show that, under some assumptions, our rule-dependent representation is a sufficient statistic of the distribution over best-response strategies across partners. Using this separation of representations, our agents are able to adapt quickly to new partners, and to coordinate with old partners on new tasks in a zero-shot manner. We experimentally validate our approach on three collaborative tasks varying in complexity: a contextual multi-armed bandit, a block placing task, and the card game Hanabi.
Improved Autoregressive Modeling with Distribution Smoothing
Mar 28, 2021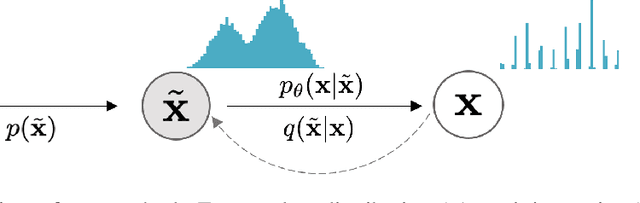


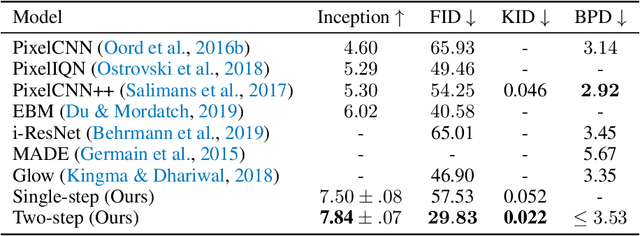
While autoregressive models excel at image compression, their sample quality is often lacking. Although not realistic, generated images often have high likelihood according to the model, resembling the case of adversarial examples. Inspired by a successful adversarial defense method, we incorporate randomized smoothing into autoregressive generative modeling. We first model a smoothed version of the data distribution, and then reverse the smoothing process to recover the original data distribution. This procedure drastically improves the sample quality of existing autoregressive models on several synthetic and real-world image datasets while obtaining competitive likelihoods on synthetic datasets.
Anytime Sampling for Autoregressive Models via Ordered Autoencoding
Feb 23, 2021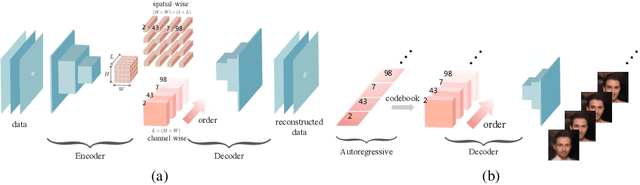

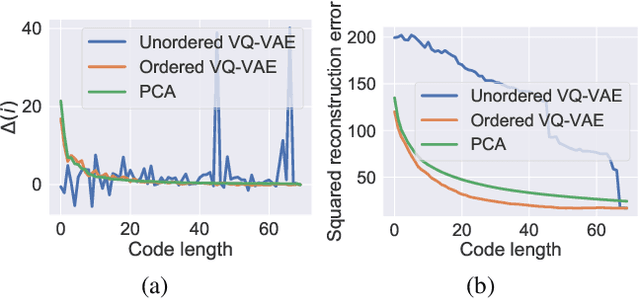
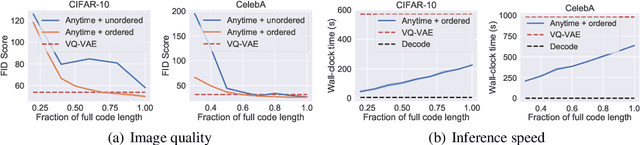
Autoregressive models are widely used for tasks such as image and audio generation. The sampling process of these models, however, does not allow interruptions and cannot adapt to real-time computational resources. This challenge impedes the deployment of powerful autoregressive models, which involve a slow sampling process that is sequential in nature and typically scales linearly with respect to the data dimension. To address this difficulty, we propose a new family of autoregressive models that enables anytime sampling. Inspired by Principal Component Analysis, we learn a structured representation space where dimensions are ordered based on their importance with respect to reconstruction. Using an autoregressive model in this latent space, we trade off sample quality for computational efficiency by truncating the generation process before decoding into the original data space. Experimentally, we demonstrate in several image and audio generation tasks that sample quality degrades gracefully as we reduce the computational budget for sampling. The approach suffers almost no loss in sample quality (measured by FID) using only 60\% to 80\% of all latent dimensions for image data. Code is available at https://github.com/Newbeeer/Anytime-Auto-Regressive-Model .
Localized Calibration: Metrics and Recalibration
Feb 22, 2021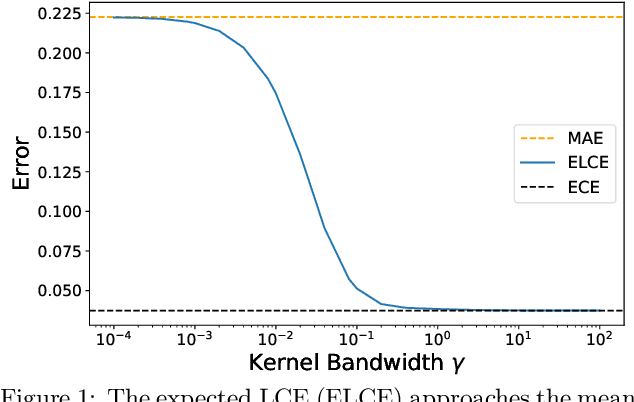
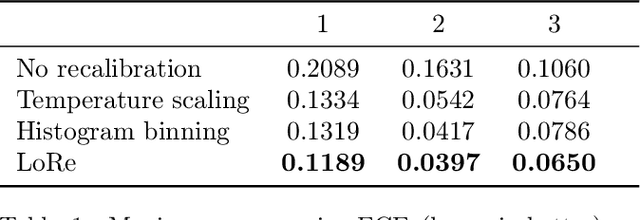
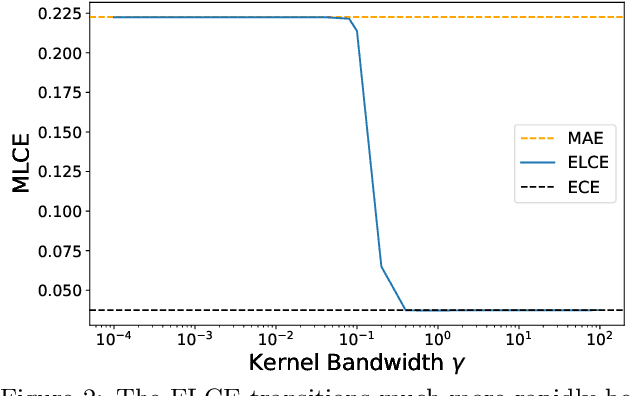
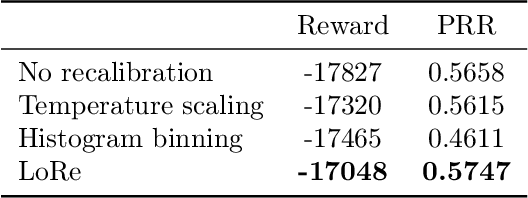
Probabilistic classifiers output confidence scores along with their predictions, and these confidence scores must be well-calibrated (i.e. reflect the true probability of an event) to be meaningful and useful for downstream tasks. However, existing metrics for measuring calibration are insufficient. Commonly used metrics such as the expected calibration error (ECE) only measure global trends, making them ineffective for measuring the calibration of a particular sample or subgroup. At the other end of the spectrum, a fully individualized calibration error is in general intractable to estimate from finite samples. In this work, we propose the local calibration error (LCE), a fine-grained calibration metric that spans the gap between fully global and fully individualized calibration. The LCE leverages learned features to automatically capture rich subgroups, and it measures the calibration error around each individual example via a similarity function. We then introduce a localized recalibration method, LoRe, that improves the LCE better than existing recalibration methods. Finally, we show that applying our recalibration method improves decision-making on downstream tasks.