 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Image Captioning with Context-Object Split Latent Spaces
Nov 02, 2020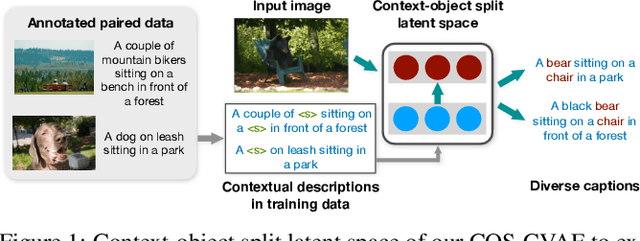

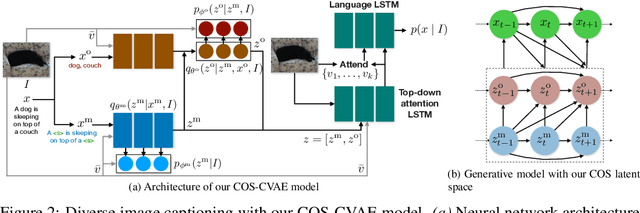
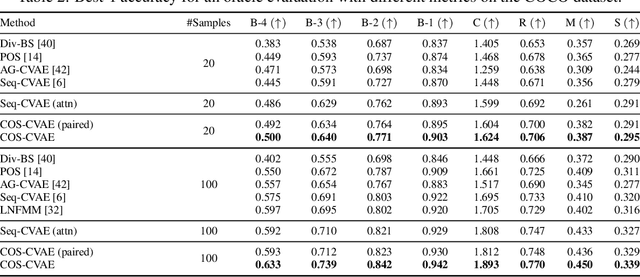
Diverse image captioning models aim to learn one-to-many mappings that are innate to cross-domain datasets, such as of images and texts. Current methods for this task are based on generative latent variable models, e.g. VAEs with structured latent spaces. Yet, the amount of multimodality captured by prior work is limited to that of the paired training data -- the true diversity of the underlying generative process is not fully captured. To address this limitation, we leverage the contextual descriptions in the dataset that explain similar contexts in different visual scenes. To this end, we introduce a novel factorization of the latent space, termed context-object split, to model diversity in contextual descriptions across images and texts within the dataset. Our framework not only enables diverse captioning through context-based pseudo supervision, but extends this to images with novel objects and without paired captions in the training data. We evaluate our COS-CVAE approach on the standard COCO dataset and on the held-out COCO dataset consisting of images with novel objects, showing significant gains in accuracy and diversity.
MOTChallenge: A Benchmark for Single-camera Multiple Target Tracking
Oct 15, 2020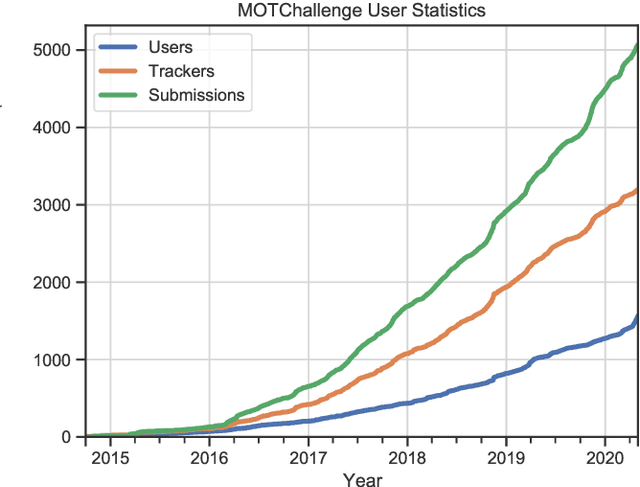
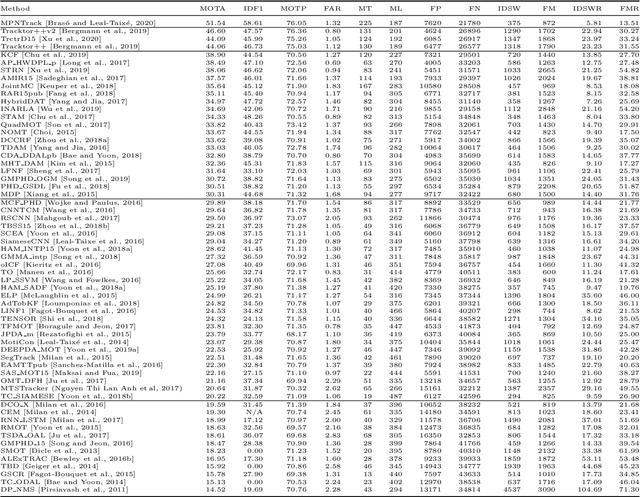

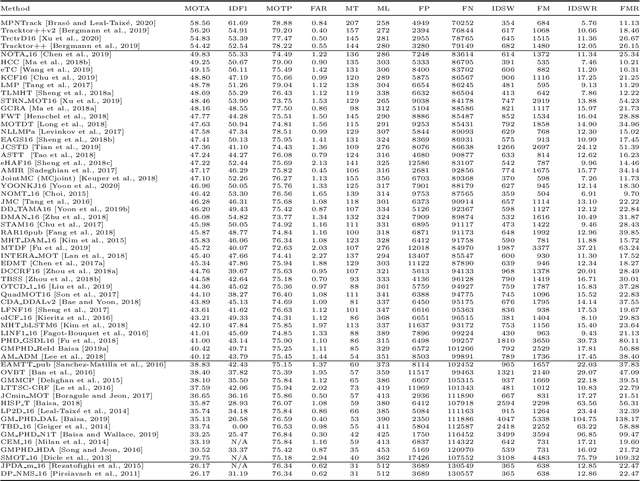
Standardized benchmarks have been crucial in pushing the performance of computer vision algorithms, especially since the advent of deep learning. Although leaderboards should not be over-claimed, they often provide the most objective measure of performance and are therefore important guides for research. We present MOTChallenge, a benchmark for single-camera Multiple Object Tracking (MOT) launched in late 2014, to collect existing and new data, and create a framework for the standardized evaluation of multiple object tracking methods. The benchmark is focused on multiple people tracking, since pedestrians are by far the most studied object in the tracking community, with applications ranging from robot navigation to self-driving cars. This paper collects the first three releases of the benchmark: (i) MOT15, along with numerous state-of-the-art results that were submitted in the last years, (ii) MOT16, which contains new challenging videos, and (iii) MOT17, that extends MOT16 sequences with more precise labels and evaluates tracking performance on three different object detectors. The second and third release not only offers a significant increase in the number of labeled boxes but also provide labels for multiple object classes beside pedestrians, as well as the level of visibility for every single object of interest. We finally provide a categorization of state-of-the-art trackers and a broad error analysis. This will help newcomers understand the related work and research trends in the MOT community, and hopefully shred some light into potential future research directions.
Planning on the fast lane: Learning to interact using attention mechanisms in path integral inverse reinforcement learning
Jul 11, 2020
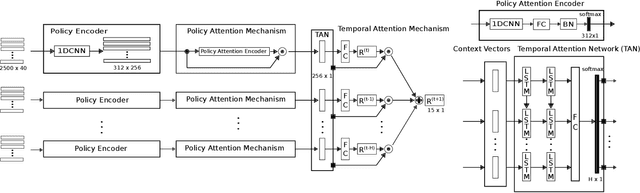
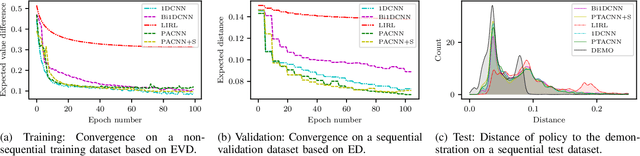
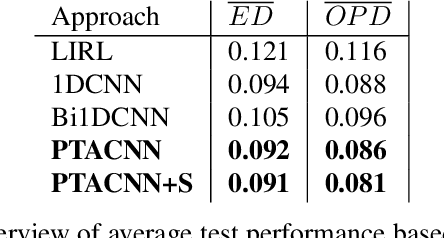
General-purpose trajectory planning algorithms for automated driving utilize complex reward functions to perform a combined optimization of strategic, behavioral, and kinematic features. The specification and tuning of a single reward function is a tedious task and does not generalize over a large set of traffic situations. Deep learning approaches based on path integral inverse reinforcement learning have been successfully applied to predict local situation-dependent reward functions using features of a set of sampled driving policies. Sample-based trajectory planning algorithms are able to approximate a spatio-temporal subspace of feasible driving policies that can be used to encode the context of a situation. However, the interaction with dynamic objects requires an extended planning horizon, which requires sequential context modeling. In this work, we are concerned with the sequential reward prediction over an extended time horizon. We present a neural network architecture that uses a policy attention mechanism to generate a low-dimensional context vector by concentrating on trajectories with a human-like driving style. Besides, we propose a temporal attention mechanism to identify context switches and allow for stable adaptation of rewards. We evaluate our results on complex simulated driving situations, including other vehicles. Our evaluation shows that our policy attention mechanisms learns to focus on collision free policies in the configuration space. Furthermore, the temporal attention mechanism learns persistent interaction with other vehicles over an extended planning horizon.
LR-CNN: Local-aware Region CNN for Vehicle Detection in Aerial Imagery
May 28, 2020
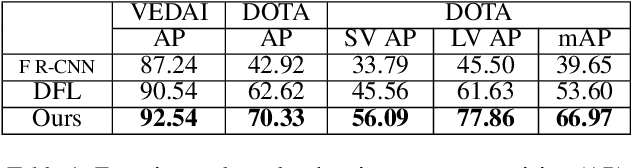
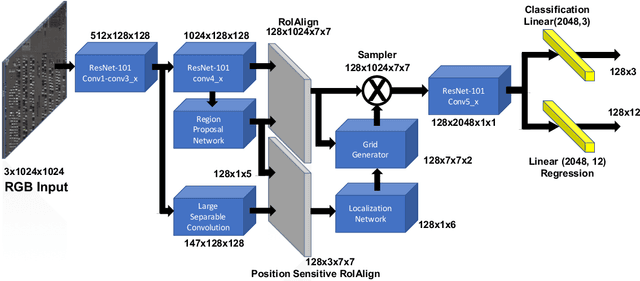
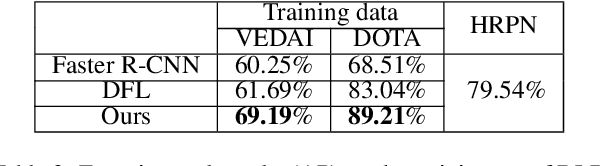
State-of-the-art object detection approaches such as Fast/Faster R-CNN, SSD, or YOLO have difficulties detecting dense, small targets with arbitrary orientation in large aerial images. The main reason is that using interpolation to align RoI features can result in a lack of accuracy or even loss of location information. We present the Local-aware Region Convolutional Neural Network (LR-CNN), a novel two-stage approach for vehicle detection in aerial imagery. We enhance translation invariance to detect dense vehicles and address the boundary quantization issue amongst dense vehicles by aggregating the high-precision RoIs' features. Moreover, we resample high-level semantic pooled features, making them regain location information from the features of a shallower convolutional block. This strengthens the local feature invariance for the resampled features and enables detecting vehicles in an arbitrary orientation. The local feature invariance enhances the learning ability of the focal loss function, and the focal loss further helps to focus on the hard examples. Taken together, our method better addresses the challenges of aerial imagery. We evaluate our approach on several challenging datasets (VEDAI, DOTA), demonstrating a significant improvement over state-of-the-art methods. We demonstrate the good generalization ability of our approach on the DLR 3K dataset.
Single-Stage Semantic Segmentation from Image Labels
May 16, 2020
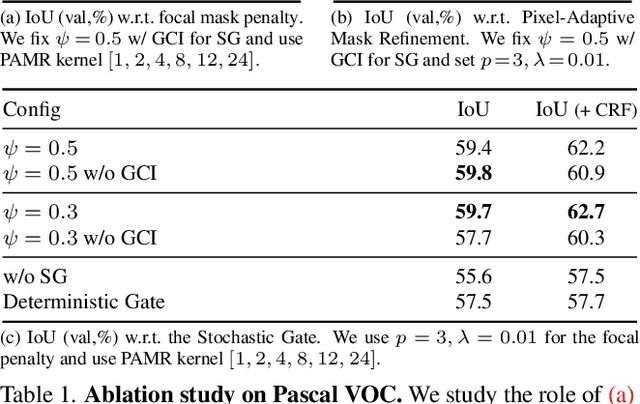

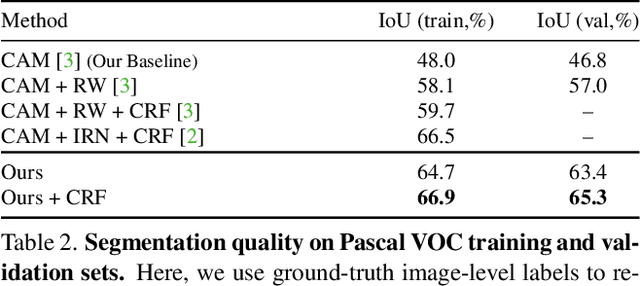
Recent years have seen a rapid growth in new approaches improving the accuracy of semantic segmentation in a weakly supervised setting, i.e. with only image-level labels available for training. However, this has come at the cost of increased model complexity and sophisticated multi-stage training procedures. This is in contrast to earlier work that used only a single stage $-$ training one segmentation network on image labels $-$ which was abandoned due to inferior segmentation accuracy. In this work, we first define three desirable properties of a weakly supervised method: local consistency, semantic fidelity, and completeness. Using these properties as guidelines, we then develop a segmentation-based network model and a self-supervised training scheme to train for semantic masks from image-level annotations in a single stage. We show that despite its simplicity, our method achieves results that are competitive with significantly more complex pipelines, substantially outperforming earlier single-stage methods.
Self-Supervised Monocular Scene Flow Estimation
Apr 15, 2020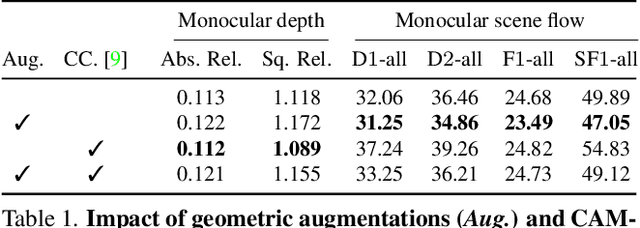
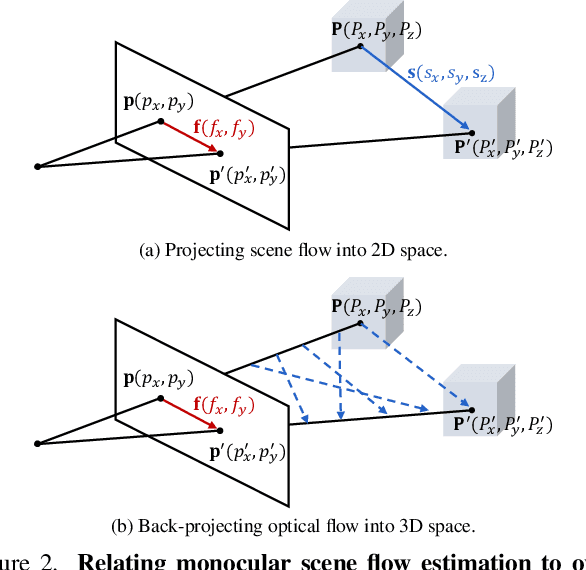
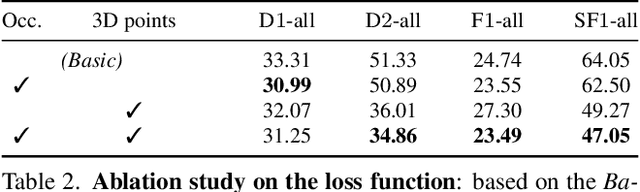
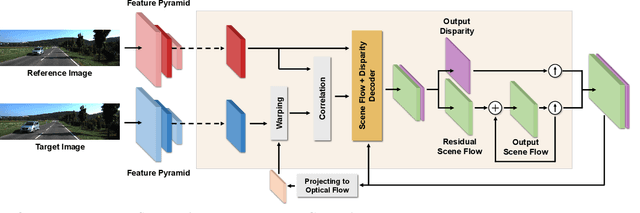
Scene flow estimation has been receiving increasing attention for 3D environment perception. Monocular scene flow estimation -- obtaining 3D structure and 3D motion from two temporally consecutive images -- is a highly ill-posed problem, and practical solutions are lacking to date. We propose a novel monocular scene flow method that yields competitive accuracy and real-time performance. By taking an inverse problem view, we design a single convolutional neural network (CNN) that successfully estimates depth and 3D motion simultaneously from a classical optical flow cost volume. We adopt self-supervised learning with 3D loss functions and occlusion reasoning to leverage unlabeled data. We validate our design choices, including the proxy loss and augmentation setup. Our model achieves state-of-the-art accuracy among unsupervised/self-supervised learning approaches to monocular scene flow, and yields competitive results for the optical flow and monocular depth estimation sub-tasks. Semi-supervised fine-tuning further improves the accuracy and yields promising results in real-time.
Normalizing Flows with Multi-Scale Autoregressive Priors
Apr 08, 2020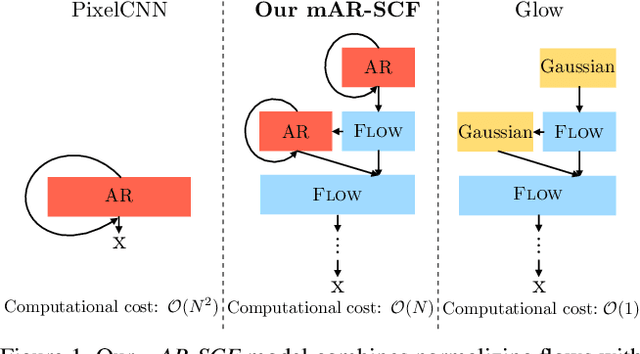
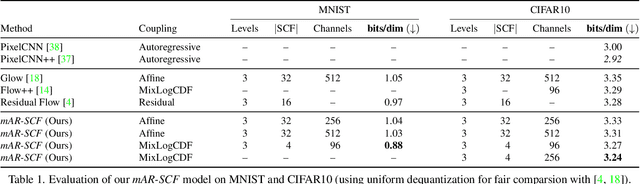
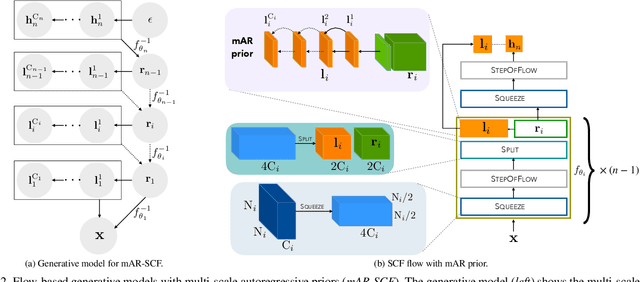
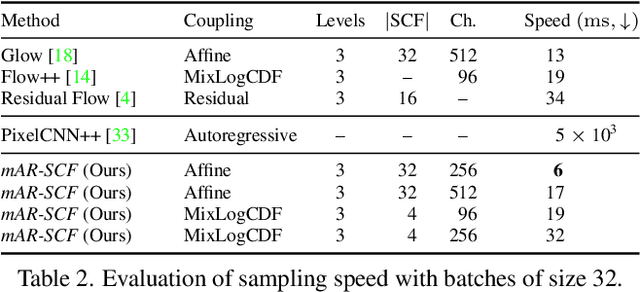
Flow-based generative models are an important class of exact inference models that admit efficient inference and sampling for image synthesis. Owing to the efficiency constraints on the design of the flow layers, e.g. split coupling flow layers in which approximately half the pixels do not undergo further transformations, they have limited expressiveness for modeling long-range data dependencies compared to autoregressive models that rely on conditional pixel-wise generation. In this work, we improve the representational power of flow-based models by introducing channel-wise dependencies in their latent space through multi-scale autoregressive priors (mAR). Our mAR prior for models with split coupling flow layers (mAR-SCF) can better capture dependencies in complex multimodal data. The resulting model achieves state-of-the-art density estimation results on MNIST, CIFAR-10, and ImageNet. Furthermore, we show that mAR-SCF allows for improved image generation quality, with gains in FID and Inception scores compared to state-of-the-art flow-based models.
Optical Flow Estimation in the Deep Learning Age
Apr 06, 2020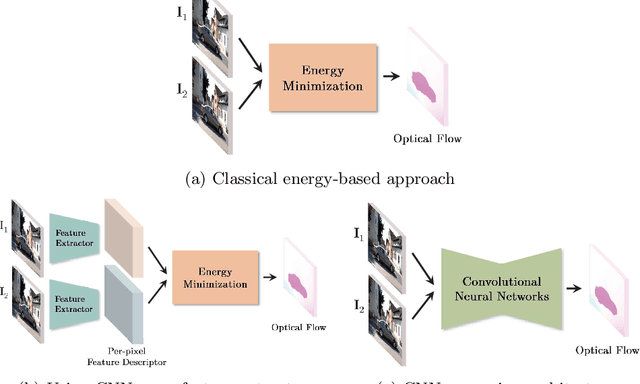
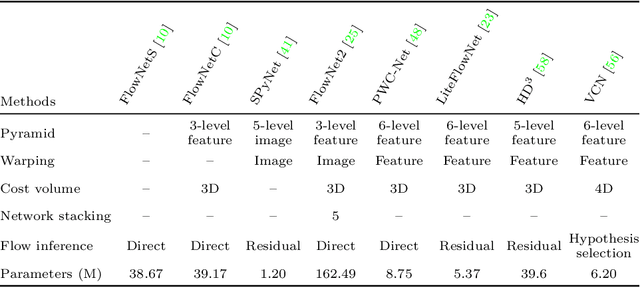
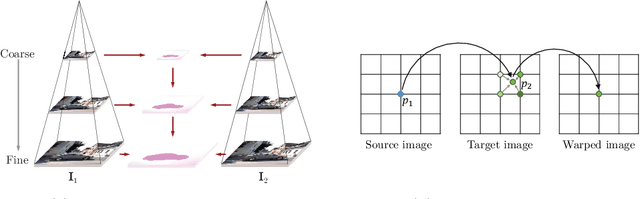
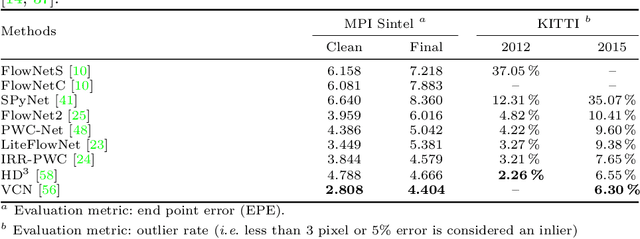
Akin to many subareas of computer vision, the recent advances in deep learning have also significantly influenced the literature on optical flow. Previously, the literature had been dominated by classical energy-based models, which formulate optical flow estimation as an energy minimization problem. However, as the practical benefits of Convolutional Neural Networks (CNNs) over conventional methods have become apparent in numerous areas of computer vision and beyond, they have also seen increased adoption in the context of motion estimation to the point where the current state of the art in terms of accuracy is set by CNN approaches. We first review this transition as well as the developments from early work to the current state of CNNs for optical flow estimation. Alongside, we discuss some of their technical details and compare them to recapitulate which technical contribution led to the most significant accuracy improvements. Then we provide an overview of the various optical flow approaches introduced in the deep learning age, including those based on alternative learning paradigms (e.g., unsupervised and semi-supervised methods) as well as the extension to the multi-frame case, which is able to yield further accuracy improvements.
Probabilistic Pixel-Adaptive Refinement Networks
Mar 31, 2020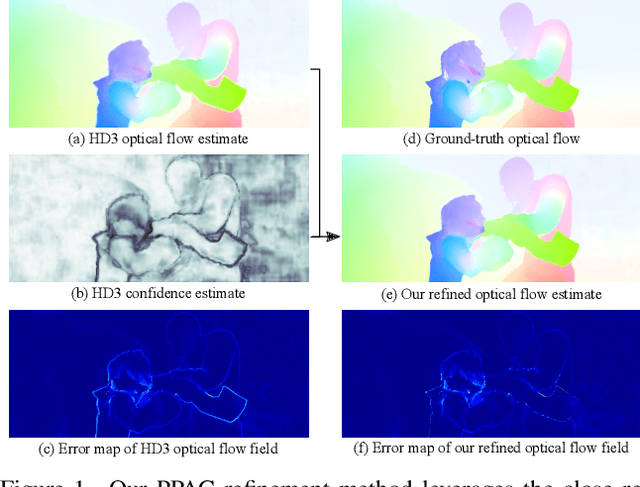
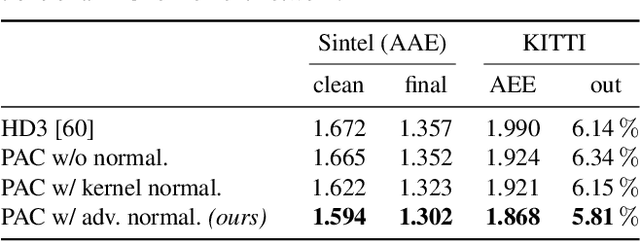
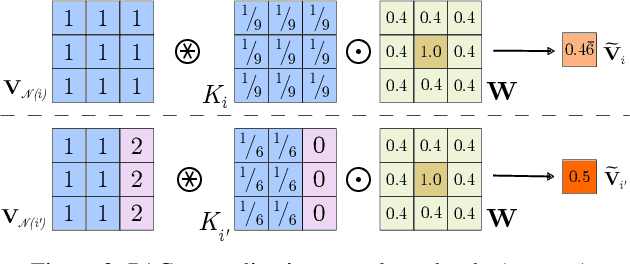
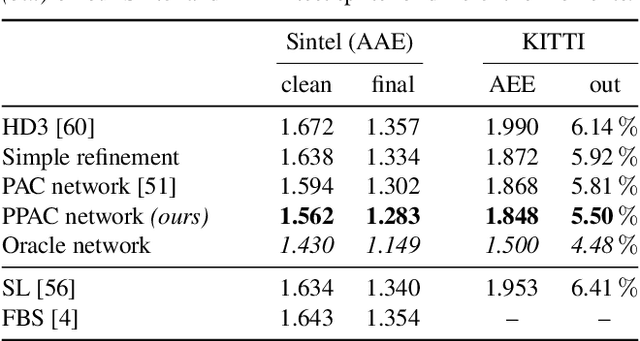
Encoder-decoder networks have found widespread use in various dense prediction tasks. However, the strong reduction of spatial resolution in the encoder leads to a loss of location information as well as boundary artifacts. To address this, image-adaptive post-processing methods have shown beneficial by leveraging the high-resolution input image(s) as guidance data. We extend such approaches by considering an important orthogonal source of information: the network's confidence in its own predictions. We introduce probabilistic pixel-adaptive convolutions (PPACs), which not only depend on image guidance data for filtering, but also respect the reliability of per-pixel predictions. As such, PPACs allow for image-adaptive smoothing and simultaneously propagating pixels of high confidence into less reliable regions, while respecting object boundaries. We demonstrate their utility in refinement networks for optical flow and semantic segmentation, where PPACs lead to a clear reduction in boundary artifacts. Moreover, our proposed refinement step is able to substantially improve the accuracy on various widely used benchmarks.
MOT20: A benchmark for multi object tracking in crowded scenes
Mar 19, 2020
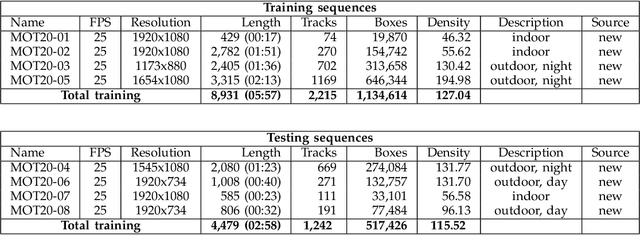

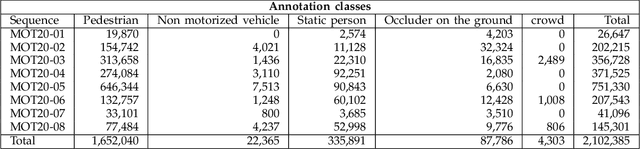
Standardized benchmarks are crucial for the majority of computer vision applications. Although leaderboards and ranking tables should not be over-claimed, benchmarks often provide the most objective measure of performance and are therefore important guides for research. The benchmark for Multiple Object Tracking, MOTChallenge, was launched with the goal to establish a standardized evaluation of multiple object tracking methods. The challenge focuses on multiple people tracking, since pedestrians are well studied in the tracking community, and precise tracking and detection has high practical relevance. Since the first release, MOT15, MOT16, and MOT17 have tremendously contributed to the community by introducing a clean dataset and precise framework to benchmark multi-object trackers. In this paper, we present our MOT20benchmark, consisting of 8 new sequences depicting very crowded challenging scenes. The benchmark was presented first at the 4thBMTT MOT Challenge Workshop at the Computer Vision and Pattern Recognition Conference (CVPR) 2019, and gives to chance to evaluate state-of-the-art methods for multiple object tracking when handling extremely crowded scenarios.