 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeedNet: A Foundation Model-Based Global-to-Local AI Approach for Real-Time Weed Species Identification and Classification
May 25, 2025



Early identification of weeds is essential for effective management and control, and there is growing interest in automating the process using computer vision techniques coupled with AI methods. However, challenges associated with training AI-based weed identification models, such as limited expert-verified data and complexity and variability in morphological features, have hindered progress. To address these issues, we present WeedNet, the first global-scale weed identification model capable of recognizing an extensive set of weed species, including noxious and invasive plant species. WeedNet is an end-to-end real-time weed identification pipeline and uses self-supervised learning, fine-tuning, and enhanced trustworthiness strategies. WeedNet achieved 91.02% accuracy across 1,593 weed species, with 41% species achieving 100% accuracy. Using a fine-tuning strategy and a Global-to-Local approach, the local Iowa WeedNet model achieved an overall accuracy of 97.38% for 85 Iowa weeds, most classes exceeded a 90% mean accuracy per class. Testing across intra-species dissimilarity (developmental stages) and inter-species similarity (look-alike species) suggests that diversity in the images collected, spanning all the growth stages and distinguishable plant characteristics, is crucial in driving model performance. The generalizability and adaptability of the Global WeedNet model enable it to function as a foundational model, with the Global-to-Local strategy allowing fine-tuning for region-specific weed communities. Additional validation of drone- and ground-rover-based images highlights the potential of WeedNet for integration into robotic platforms. Furthermore, integration with AI for conversational use provides intelligent agricultural and ecological conservation consulting tools for farmers, agronomists, researchers, land managers, and government agencies across diverse landscapes.
Out-of-distribution detection algorithms for robust insect classification
May 02, 2023Deep learning-based approaches have produced models with good insect classification accuracy; Most of these models are conducive for application in controlled environmental conditions. One of the primary emphasis of researchers is to implement identification and classification models in the real agriculture fields, which is challenging because input images that are wildly out of the distribution (e.g., images like vehicles, animals, humans, or a blurred image of an insect or insect class that is not yet trained on) can produce an incorrect insect classification. Out-of-distribution (OOD) detection algorithms provide an exciting avenue to overcome these challenge as it ensures that a model abstains from making incorrect classification prediction of non-insect and/or untrained insect class images. We generate and evaluate the performance of state-of-the-art OOD algorithms on insect detection classifiers. These algorithms represent a diversity of methods for addressing an OOD problem. Specifically, we focus on extrusive algorithms, i.e., algorithms that wrap around a well-trained classifier without the need for additional co-training. We compared three OOD detection algorithms: (i) Maximum Softmax Probability, which uses the softmax value as a confidence score, (ii) Mahalanobis distance-based algorithm, which uses a generative classification approach; and (iii) Energy-Based algorithm that maps the input data to a scalar value, called energy. We performed an extensive series of evaluations of these OOD algorithms across three performance axes: (a) \textit{Base model accuracy}: How does the accuracy of the classifier impact OOD performance? (b) How does the \textit{level of dissimilarity to the domain} impact OOD performance? and (c) \textit{Data imbalance}: How sensitive is OOD performance to the imbalance in per-class sample size?
Adjustment Criteria for Recovering Causal Effects from Missing Data
Aug 13, 2019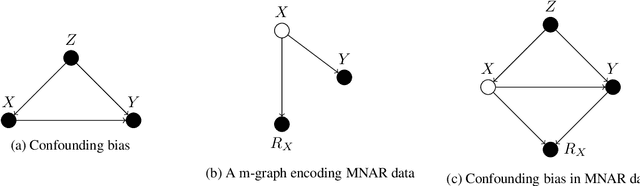

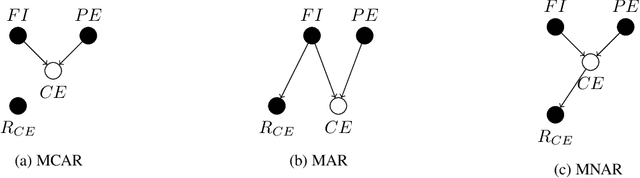
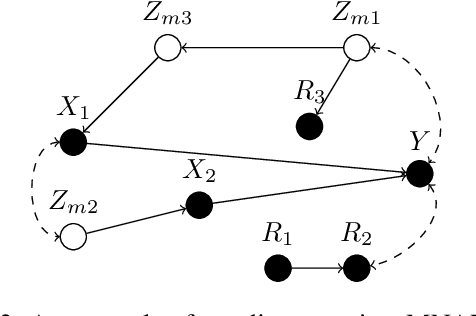
Confounding bias, missing data, and selection bias are three common obstacles to valid causal inference in the data sciences. Covariate adjustment is the most pervasive technique for recovering casual effects from confounding bias. In this paper, we introduce a covariate adjustment formulation for controlling confounding bias in the presence of missing-not-at-random data and develop a necessary and sufficient condition for recovering causal effects using the adjustment. We also introduce an adjustment formulation for controlling both confounding and selection biases in the presence of missing data and develop a necessary and sufficient condition for valid adjustment. Furthermore, we present an algorithm that lists all valid adjustment sets and an algorithm that finds a valid adjustment set containing the minimum number of variables, which are useful for researchers interested in selecting adjustment sets with desired properties.