 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoreSpeech: Knowledge Distillation based Conditional Diffusion Model for Noise-robust Expressive TTS
Nov 04, 2022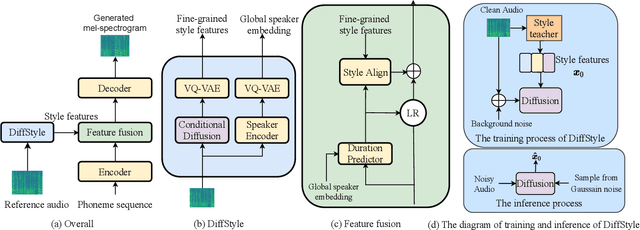
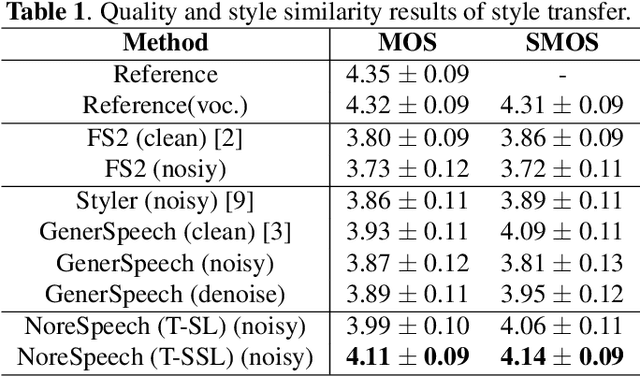

Expressive text-to-speech (TTS) can synthesize a new speaking style by imiating prosody and timbre from a reference audio, which faces the following challenges: (1) The highly dynamic prosody information in the reference audio is difficult to extract, especially, when the reference audio contains background noise. (2) The TTS systems should have good generalization for unseen speaking styles. In this paper, we present a \textbf{no}ise-\textbf{r}obust \textbf{e}xpressive TTS model (NoreSpeech), which can robustly transfer speaking style in a noisy reference utterance to synthesized speech. Specifically, our NoreSpeech includes several components: (1) a novel DiffStyle module, which leverages powerful probabilistic denoising diffusion models to learn noise-agnostic speaking style features from a teacher model by knowledge distillation; (2) a VQ-VAE block, which maps the style features into a controllable quantized latent space for improving the generalization of style transfer; and (3) a straight-forward but effective parameter-free text-style alignment module, which enables NoreSpeech to transfer style to a textual input from a length-mismatched reference utterance. Experiments demonstrate that NoreSpeech is more effective than previous expressive TTS models in noise environments. Audio samples and code are available at: \href{http://dongchaoyang.top/NoreSpeech\_demo/}{http://dongchaoyang.top/NoreSpeech\_demo/}
Speaker Identity Preservation in Dysarthric Speech Reconstruction by Adversarial Speaker Adaptation
Feb 18, 2022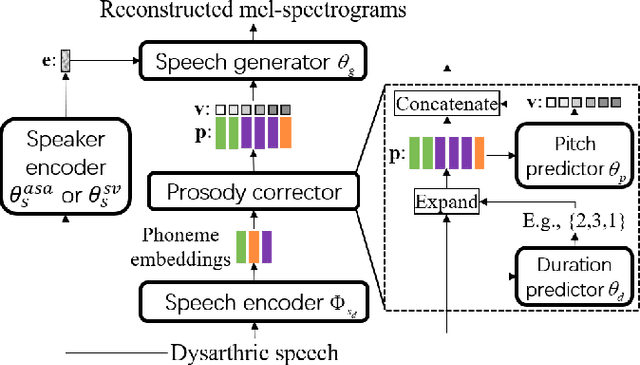
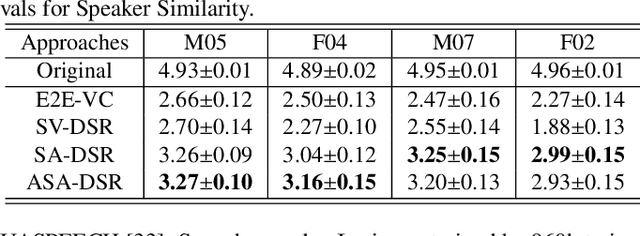
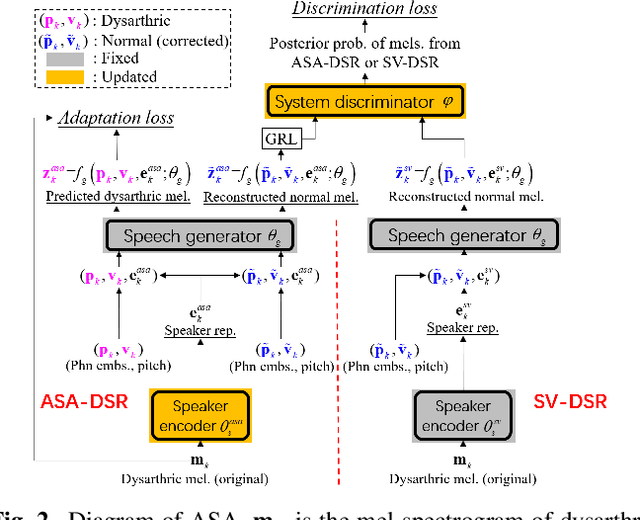
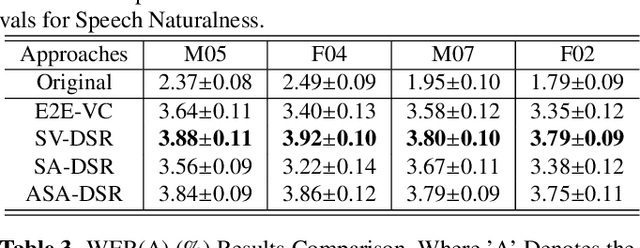
Dysarthric speech reconstruction (DSR), which aims to improve the quality of dysarthric speech, remains a challenge, not only because we need to restore the speech to be normal, but also must preserve the speaker's identity. The speaker representation extracted by the speaker encoder (SE) optimized for speaker verification has been explored to control the speaker identity. However, the SE may not be able to fully capture the characteristics of dysarthric speakers that are previously unseen. To address this research problem, we propose a novel multi-task learning strategy, i.e., adversarial speaker adaptation (ASA). The primary task of ASA fine-tunes the SE with the speech of the target dysarthric speaker to effectively capture identity-related information, and the secondary task applies adversarial training to avoid the incorporation of abnormal speaking patterns into the reconstructed speech, by regularizing the distribution of reconstructed speech to be close to that of reference speech with high quality. Experiments show that the proposed approach can achieve enhanced speaker similarity and comparable speech naturalness with a strong baseline approach. Compared with dysarthric speech, the reconstructed speech achieves 22.3% and 31.5% absolute word error rate reduction for speakers with moderate and moderate-severe dysarthria respectively. Our demo page is released here: https://wendison.github.io/ASA-DSR-demo/
DiffGAN-TTS: High-Fidelity and Efficient Text-to-Speech with Denoising Diffusion GANs
Jan 28, 2022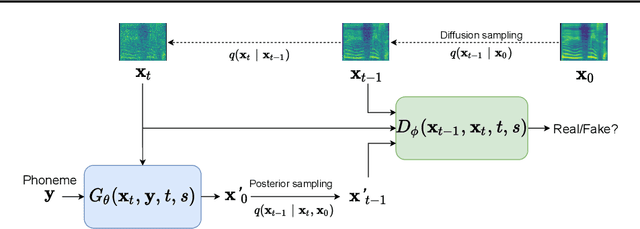
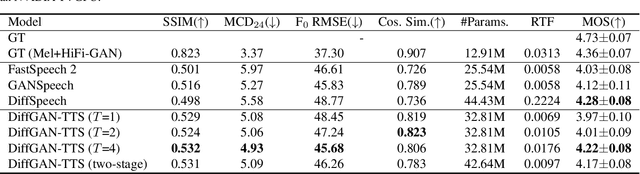
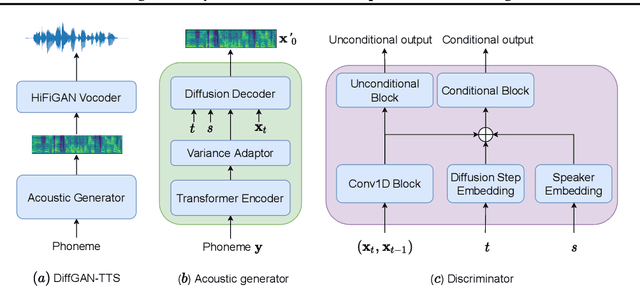
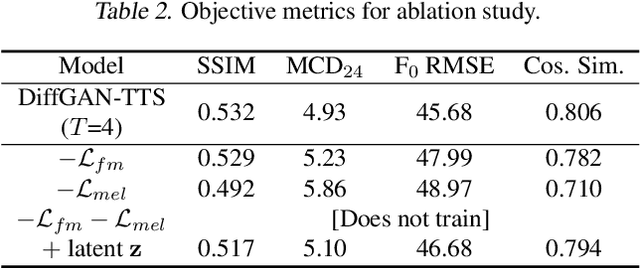
Denoising diffusion probabilistic models (DDPMs) are expressive generative models that have been used to solve a variety of speech synthesis problems. However, because of their high sampling costs, DDPMs are difficult to use in real-time speech processing applications. In this paper, we introduce DiffGAN-TTS, a novel DDPM-based text-to-speech (TTS) model achieving high-fidelity and efficient speech synthesis. DiffGAN-TTS is based on denoising diffusion generative adversarial networks (GANs), which adopt an adversarially-trained expressive model to approximate the denoising distribution. We show with multi-speaker TTS experiments that DiffGAN-TTS can generate high-fidelity speech samples within only 4 denoising steps. We present an active shallow diffusion mechanism to further speed up inference. A two-stage training scheme is proposed, with a basic TTS acoustic model trained at stage one providing valuable prior information for a DDPM trained at stage two. Our experiments show that DiffGAN-TTS can achieve high synthesis performance with only 1 denoising step.
Meta-Voice: Fast few-shot style transfer for expressive voice cloning using meta learning
Nov 14, 2021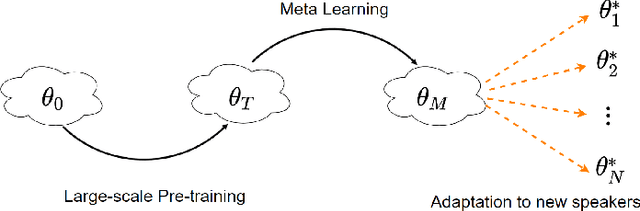
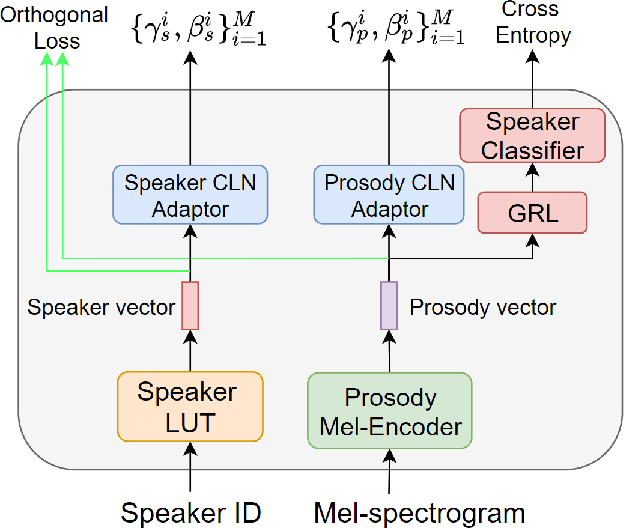
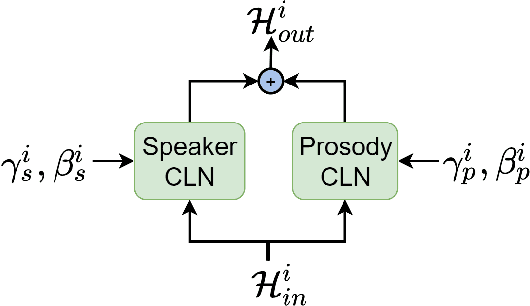
The task of few-shot style transfer for voice cloning in text-to-speech (TTS) synthesis aims at transferring speaking styles of an arbitrary source speaker to a target speaker's voice using very limited amount of neutral data. This is a very challenging task since the learning algorithm needs to deal with few-shot voice cloning and speaker-prosody disentanglement at the same time. Accelerating the adaptation process for a new target speaker is of importance in real-world applications, but even more challenging. In this paper, we approach to the hard fast few-shot style transfer for voice cloning task using meta learning. We investigate the model-agnostic meta-learning (MAML) algorithm and meta-transfer a pre-trained multi-speaker and multi-prosody base TTS model to be highly sensitive for adaptation with few samples. Domain adversarial training mechanism and orthogonal constraint are adopted to disentangle speaker and prosody representations for effective cross-speaker style transfer. Experimental results show that the proposed approach is able to conduct fast voice cloning using only 5 samples (around 12 second speech data) from a target speaker, with only 100 adaptation steps. Audio samples are available online.
Referee: Towards reference-free cross-speaker style transfer with low-quality data for expressive speech synthesis
Sep 08, 2021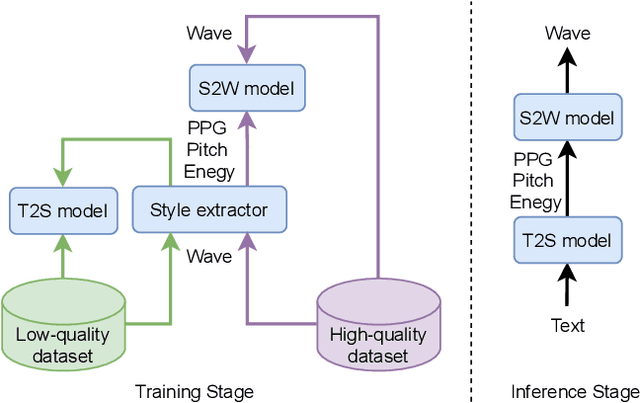
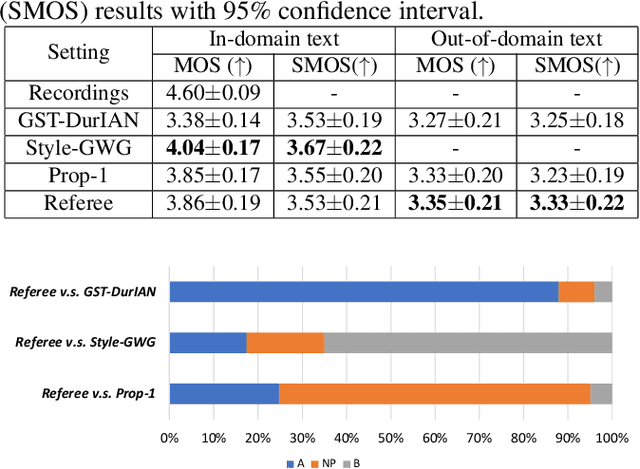
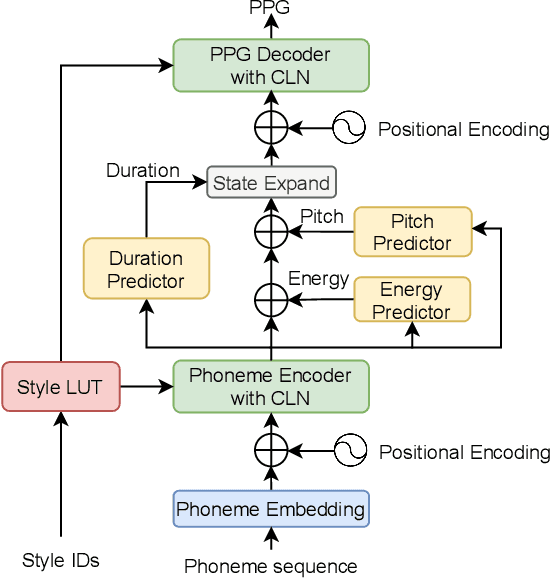
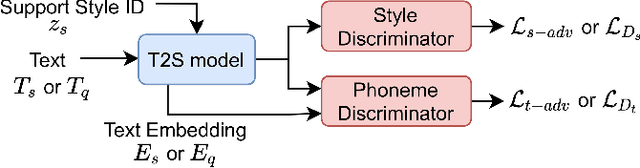
Cross-speaker style transfer (CSST) in text-to-speech (TTS) synthesis aims at transferring a speaking style to the synthesised speech in a target speaker's voice. Most previous CSST approaches rely on expensive high-quality data carrying desired speaking style during training and require a reference utterance to obtain speaking style descriptors as conditioning on the generation of a new sentence. This work presents Referee, a robust reference-free CSST approach for expressive TTS, which fully leverages low-quality data to learn speaking styles from text. Referee is built by cascading a text-to-style (T2S) model with a style-to-wave (S2W) model. Phonetic PosteriorGram (PPG), phoneme-level pitch and energy contours are adopted as fine-grained speaking style descriptors, which are predicted from text using the T2S model. A novel pretrain-refinement method is adopted to learn a robust T2S model by only using readily accessible low-quality data. The S2W model is trained with high-quality target data, which is adopted to effectively aggregate style descriptors and generate high-fidelity speech in the target speaker's voice. Experimental results are presented, showing that Referee outperforms a global-style-token (GST)-based baseline approach in CSST.
ASR-GLUE: A New Multi-task Benchmark for ASR-Robust Natural Language Understanding
Aug 30, 2021
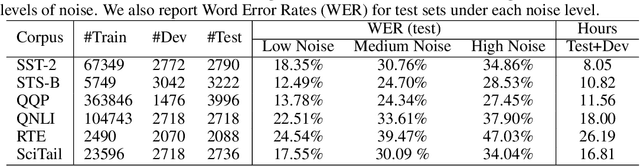
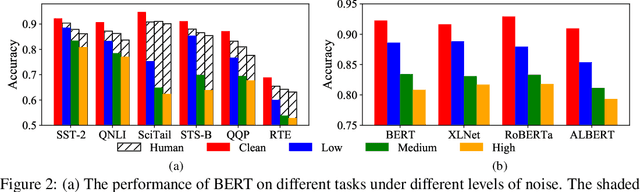

Language understanding in speech-based systems have attracted much attention in recent years with the growing demand for voice interface applications. However, the robustness of natural language understanding (NLU) systems to errors introduced by automatic speech recognition (ASR) is under-examined. %To facilitate the research on ASR-robust general language understanding, In this paper, we propose ASR-GLUE benchmark, a new collection of 6 different NLU tasks for evaluating the performance of models under ASR error across 3 different levels of background noise and 6 speakers with various voice characteristics. Based on the proposed benchmark, we systematically investigate the effect of ASR error on NLU tasks in terms of noise intensity, error type and speaker variants. We further purpose two ways, correction-based method and data augmentation-based method to improve robustness of the NLU systems. Extensive experimental results and analysises show that the proposed methods are effective to some extent, but still far from human performance, demonstrating that NLU under ASR error is still very challenging and requires further research.
DiffSVC: A Diffusion Probabilistic Model for Singing Voice Conversion
May 28, 2021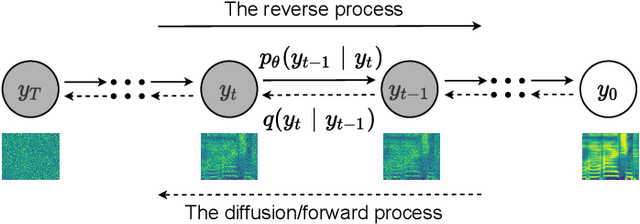
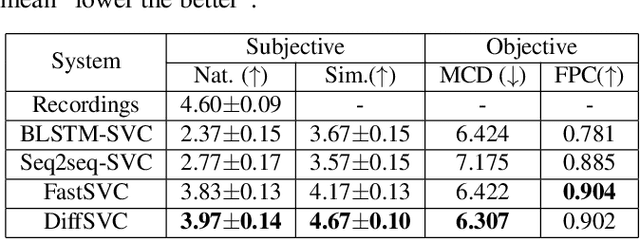
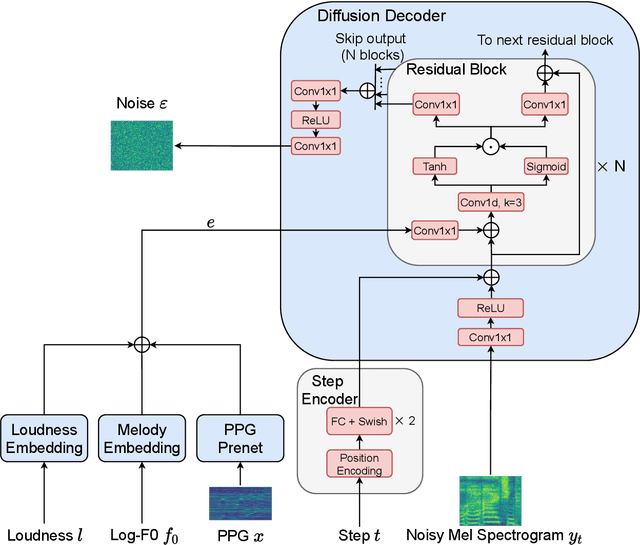
Singing voice conversion (SVC) is one promising technique which can enrich the way of human-computer interaction by endowing a computer the ability to produce high-fidelity and expressive singing voice. In this paper, we propose DiffSVC, an SVC system based on denoising diffusion probabilistic model. DiffSVC uses phonetic posteriorgrams (PPGs) as content features. A denoising module is trained in DiffSVC, which takes destroyed mel spectrogram produced by the diffusion/forward process and its corresponding step information as input to predict the added Gaussian noise. We use PPGs, fundamental frequency features and loudness features as auxiliary input to assist the denoising process. Experiments show that DiffSVC can achieve superior conversion performance in terms of naturalness and voice similarity to current state-of-the-art SVC approaches.
VARA-TTS: Non-Autoregressive Text-to-Speech Synthesis based on Very Deep VAE with Residual Attention
Feb 12, 2021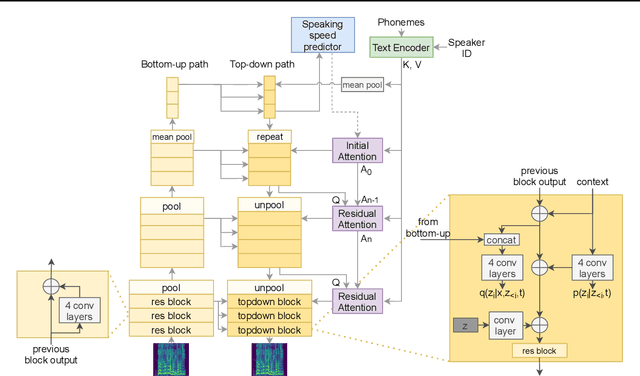
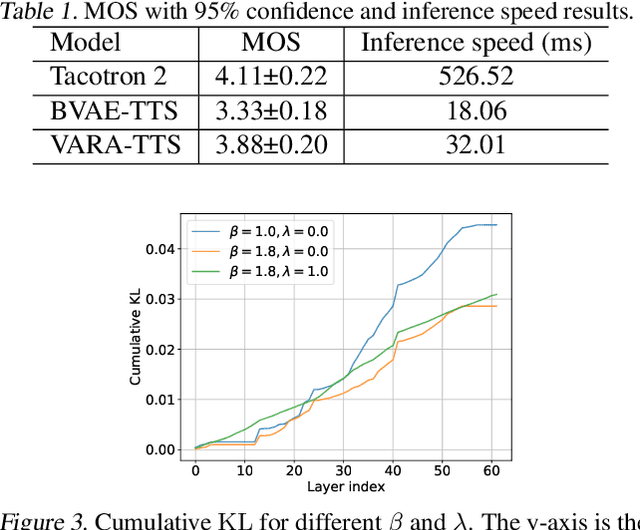

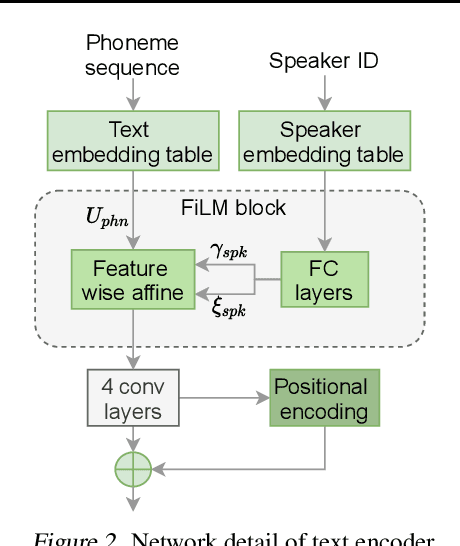
This paper proposes VARA-TTS, a non-autoregressive (non-AR) text-to-speech (TTS) model using a very deep Variational Autoencoder (VDVAE) with Residual Attention mechanism, which refines the textual-to-acoustic alignment layer-wisely. Hierarchical latent variables with different temporal resolutions from the VDVAE are used as queries for residual attention module. By leveraging the coarse global alignment from previous attention layer as an extra input, the following attention layer can produce a refined version of alignment. This amortizes the burden of learning the textual-to-acoustic alignment among multiple attention layers and outperforms the use of only a single attention layer in robustness. An utterance-level speaking speed factor is computed by a jointly-trained speaking speed predictor, which takes the mean-pooled latent variables of the coarsest layer as input, to determine number of acoustic frames at inference. Experimental results show that VARA-TTS achieves slightly inferior speech quality to an AR counterpart Tacotron 2 but an order-of-magnitude speed-up at inference; and outperforms an analogous non-AR model, BVAE-TTS, in terms of speech quality.
Any-to-Many Voice Conversion with Location-Relative Sequence-to-Sequence Modeling
Sep 06, 2020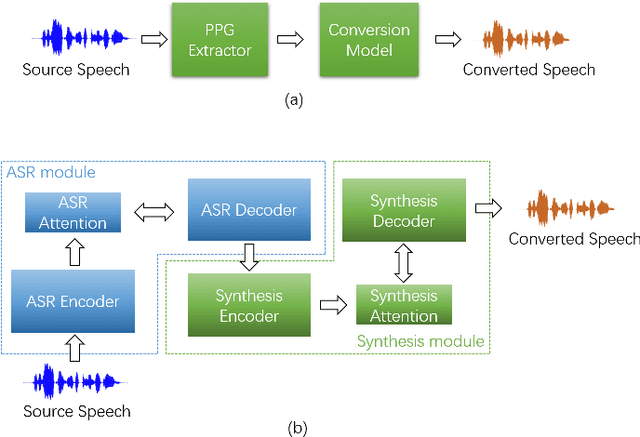
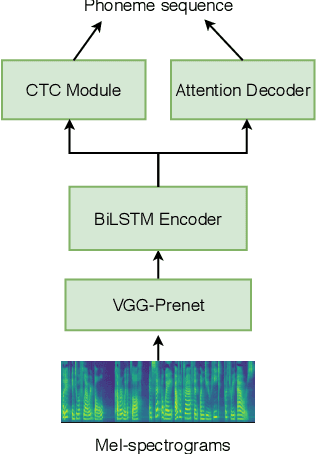
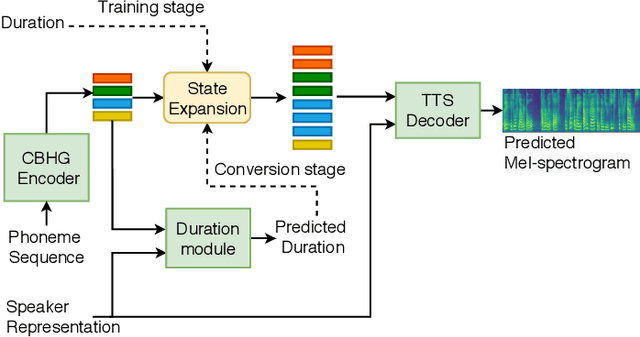
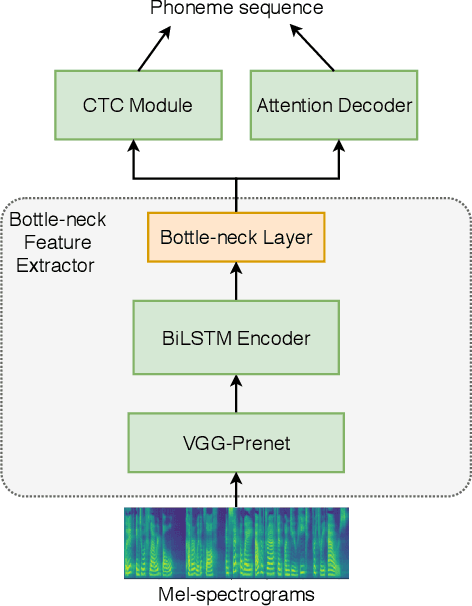
This paper proposes an any-to-many location-relative, sequence-to-sequence (seq2seq) based, non-parallel voice conversion approach. In this approach, we combine a bottle-neck feature extractor (BNE) with a seq2seq based synthesis module. During the training stage, an encoder-decoder based hybrid connectionist-temporal-classification-attention (CTC-attention) phoneme recognizer is trained, whose encoder has a bottle-neck layer. A BNE is obtained from the phoneme recognizer and is utilized to extract speaker-independent, dense and rich linguistic representations from spectral features. Then a multi-speaker location-relative attention based seq2seq synthesis model is trained to reconstruct spectral features from the bottle-neck features, conditioning on speaker representations for speaker identity control in the generated speech. To mitigate the difficulties of using seq2seq based models to align long sequences, we down-sample the input spectral feature along the temporal dimension and equip the synthesis model with a discretized mixture of logistic (MoL) attention mechanism. Since the phoneme recognizer is trained with large speech recognition data corpus, the proposed approach can conduct any-to-many voice conversion. Objective and subjective evaluations shows that the proposed any-to-many approach has superior voice conversion performance in terms of both naturalness and speaker similarity. Ablation studies are conducted to confirm the effectiveness of feature selection and model design strategies in the proposed approach. The proposed VC approach can readily be extended to support any-to-any VC (also known as one/few-shot VC), and achieve high performance according to objective and subjective evaluations.
Defense against adversarial attacks on spoofing countermeasures of ASV
Mar 06, 2020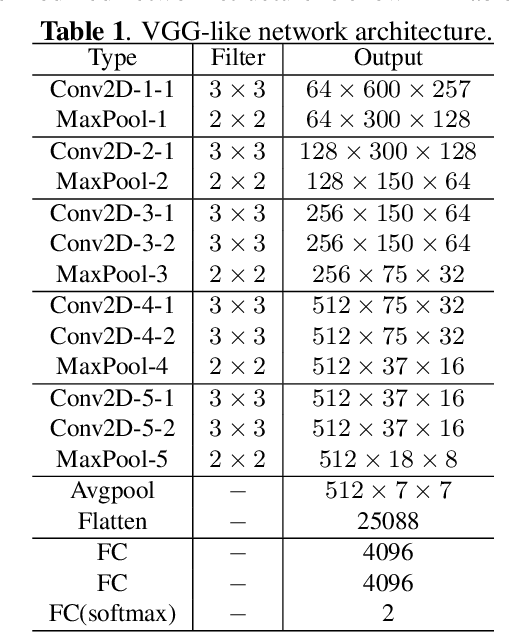

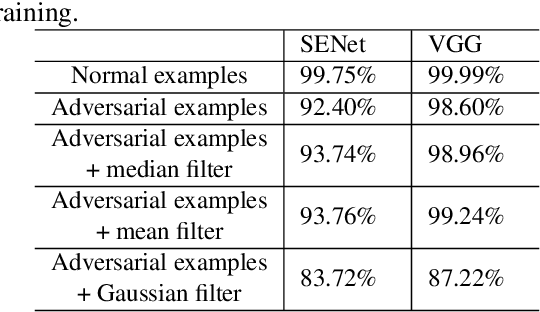
Various forefront countermeasure methods for automatic speaker verification (ASV) with considerable performance in anti-spoofing are proposed in the ASVspoof 2019 challenge. However, previous work has shown that countermeasure models are vulnerable to adversarial examples indistinguishable from natural data. A good countermeasure model should not only be robust against spoofing audio, including synthetic, converted, and replayed audios; but counteract deliberately generated examples by malicious adversaries. In this work, we introduce a passive defense method, spatial smoothing, and a proactive defense method, adversarial training, to mitigate the vulnerability of ASV spoofing countermeasure models against adversarial examples. This paper is among the first to use defense methods to improve the robustness of ASV spoofing countermeasure models under adversarial attacks. The experimental results show that these two defense methods positively help spoofing countermeasure models counter adversarial examples.