 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-aware Speaker Diarization for Multi-channel Multi-party Meeting
Sep 24, 2022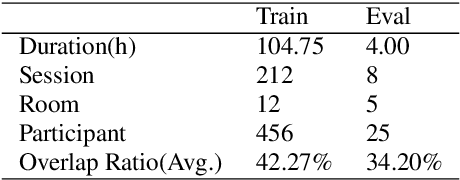
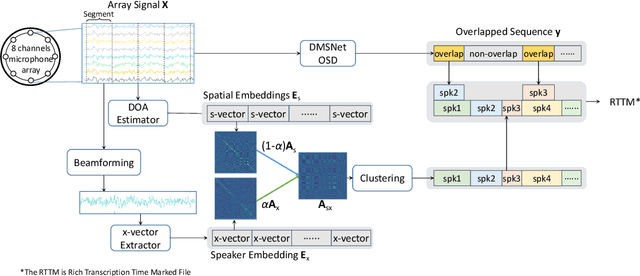

This paper describes a spatial-aware speaker diarization system for the multi-channel multi-party meeting. The diarization system obtains direction information of speaker by microphone array. Speaker spatial embedding is generated by xvector and s-vector derived from superdirective beamforming (SDB) which makes the embedding more robust. Specifically, we propose a novel multi-channel sequence-to-sequence neural network architecture named discriminative multi-stream neural network (DMSNet) which consists of attention superdirective beamforming (ASDB) block and Conformer encoder. The proposed ASDB is a self-adapted channel-wise block that extracts the latent spatial features of array audios by modeling interdependencies between channels. We explore DMSNet to address overlapped speech problem on multi-channel audio and achieve 93.53% accuracy on evaluation set. By performing DMSNet based overlapped speech detection (OSD) module, the diarization error rate (DER) of cluster-based diarization system decrease significantly from 13.45% to 7.64%.
A Ligand-and-structure Dual-driven Deep Learning Method for the Discovery of Highly Potent GnRH1R Antagonist to treat Uterine Diseases
Jul 23, 2022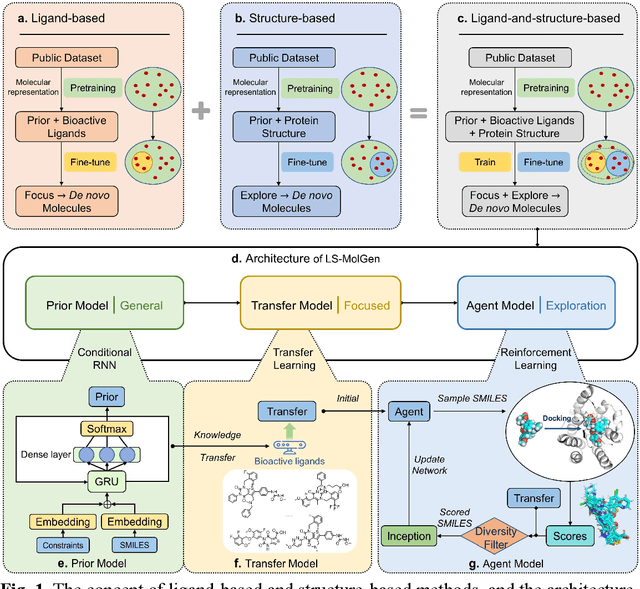
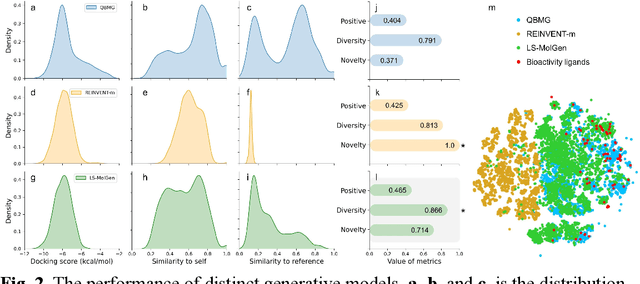
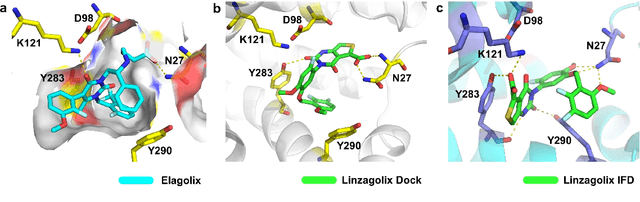
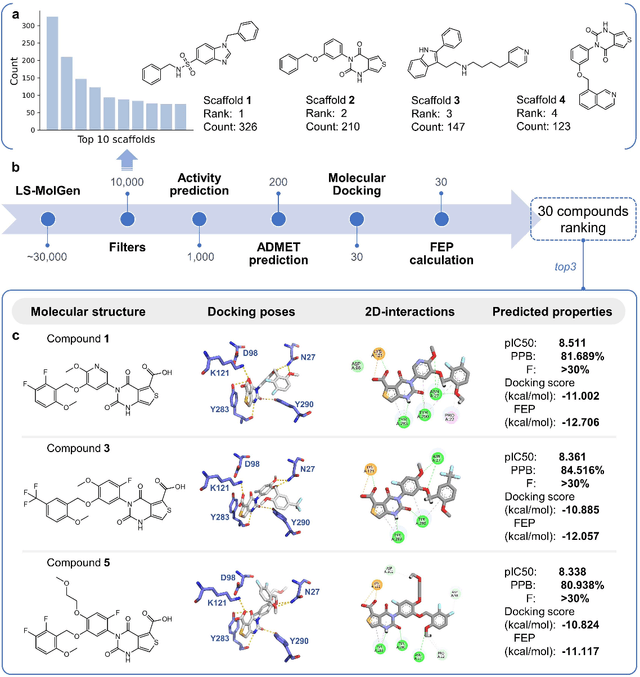
Gonadotrophin-releasing hormone receptor (GnRH1R) is a promising therapeutic target for the treatment of uterine diseases. To date, several GnRH1R antagonists are available in clinical investigation without satisfying multiple property constraints. To fill this gap, we aim to develop a deep learning-based framework to facilitate the effective and efficient discovery of a new orally active small-molecule drug targeting GnRH1R with desirable properties. In the present work, a ligand-and-structure combined model, namely LS-MolGen, was firstly proposed for molecular generation by fully utilizing the information on the known active compounds and the structure of the target protein, which was demonstrated by its superior performance than ligand- or structure-based methods separately. Then, a in silico screening including activity prediction, ADMET evaluation, molecular docking and FEP calculation was conducted, where ~30,000 generated novel molecules were narrowed down to 8 for experimental synthesis and validation. In vitro and in vivo experiments showed that three of them exhibited potent inhibition activities (compound 5 IC50 = 0.856 nM, compound 6 IC50 = 0.901 nM, compound 7 IC50 = 2.54 nM) against GnRH1R, and compound 5 performed well in fundamental PK properties, such as half-life, oral bioavailability, and PPB, etc. We believed that the proposed ligand-and-structure combined molecular generative model and the whole computer-aided workflow can potentially be extended to similar tasks for de novo drug design or lead optimization.
An Interpretable Federated Learning-based Network Intrusion Detection Framework
Jan 10, 2022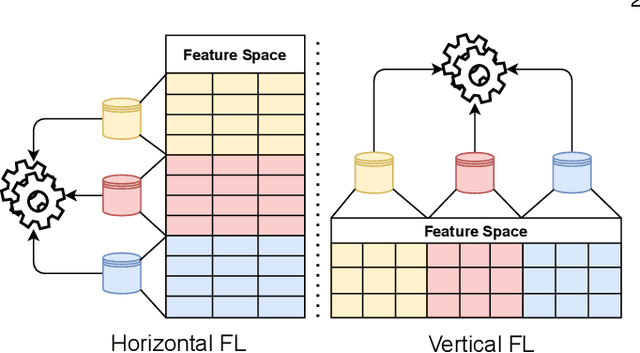
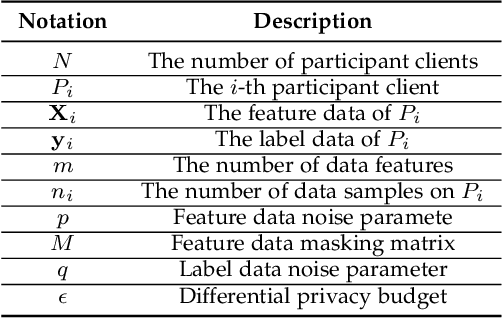
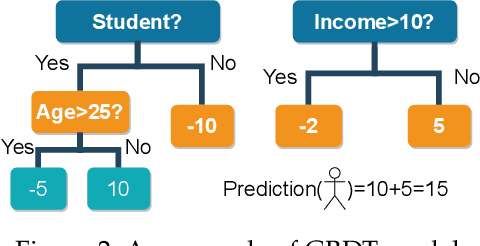
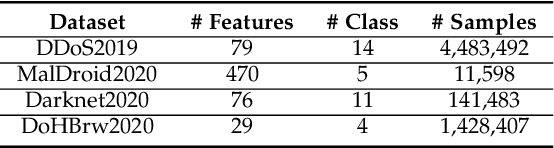
Learning-based Network Intrusion Detection Systems (NIDSs) are widely deployed for defending various cyberattacks. Existing learning-based NIDS mainly uses Neural Network (NN) as a classifier that relies on the quality and quantity of cyberattack data. Such NN-based approaches are also hard to interpret for improving efficiency and scalability. In this paper, we design a new local-global computation paradigm, FEDFOREST, a novel learning-based NIDS by combining the interpretable Gradient Boosting Decision Tree (GBDT) and Federated Learning (FL) framework. Specifically, FEDFOREST is composed of multiple clients that extract local cyberattack data features for the server to train models and detect intrusions. A privacy-enhanced technology is also proposed in FEDFOREST to further defeat the privacy of the FL systems. Extensive experiments on 4 cyberattack datasets of different tasks demonstrate that FEDFOREST is effective, efficient, interpretable, and extendable. FEDFOREST ranks first in the collaborative learning and cybersecurity competition 2021 for Chinese college students.
Dynamic Differential-Privacy Preserving SGD
Nov 15, 2021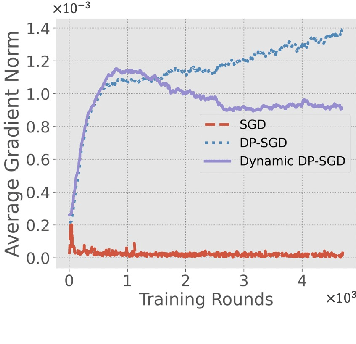
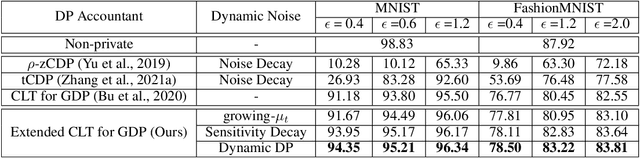
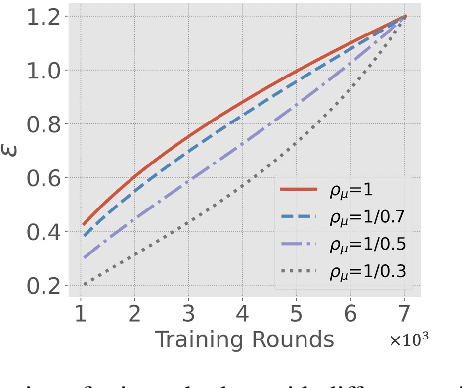
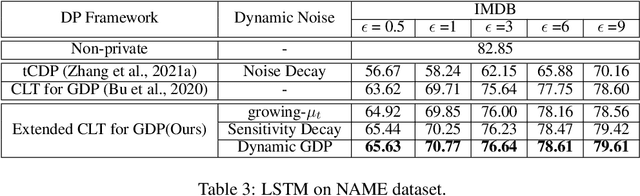
Differentially-Private Stochastic Gradient Descent (DP-SGD) prevents training-data privacy breaches by adding noise to the clipped gradient during SGD training to satisfy the differential privacy (DP) definition. On the other hand, the same clipping operation and additive noise across training steps results in unstable updates and even a ramp-up period, which significantly reduces the model's accuracy. In this paper, we extend the Gaussian DP central limit theorem to calibrate the clipping value and the noise power for each individual step separately. We, therefore, are able to propose the dynamic DP-SGD, which has a lower privacy cost than the DP-SGD during updates until they achieve the same target privacy budget at a target number of updates. Dynamic DP-SGD, in particular, improves model accuracy without sacrificing privacy by gradually lowering both clipping value and noise power while adhering to a total privacy budget constraint. Extensive experiments on a variety of deep learning tasks, including image classification, natural language processing, and federated learning, show that the proposed dynamic DP-SGD algorithm stabilizes updates and, as a result, significantly improves model accuracy in the strong privacy protection region when compared to DP-SGD.
An Integrated Framework for Two-pass Personalized Voice Trigger
Jun 30, 2021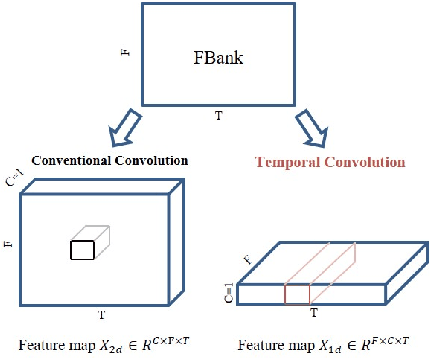
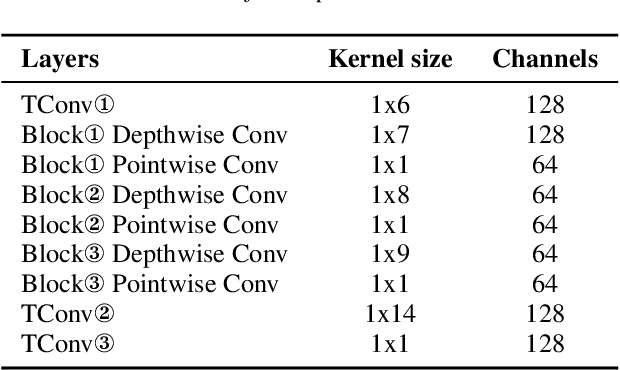
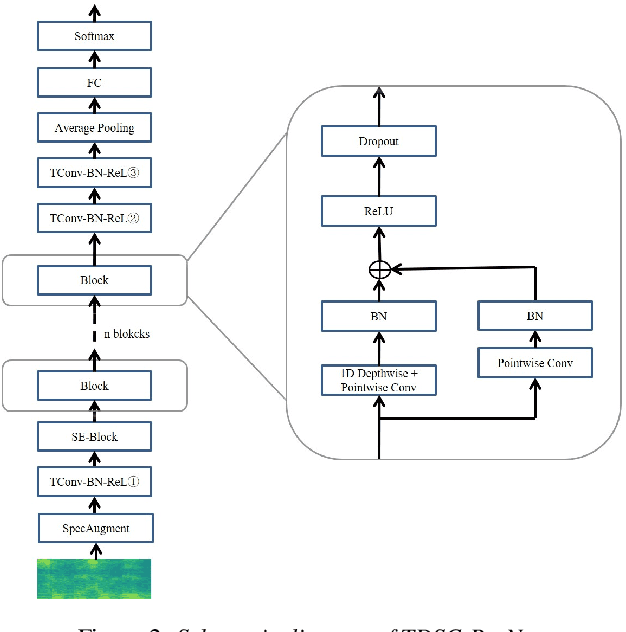
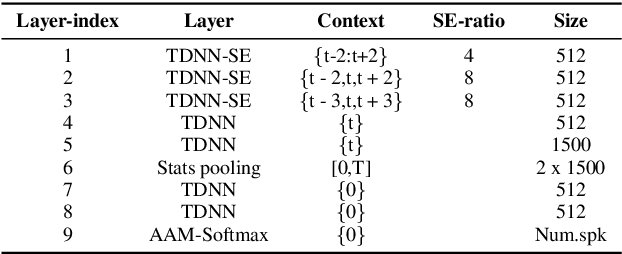
In this paper, we present the XMUSPEECH system for Task 1 of 2020 Personalized Voice Trigger Challenge (PVTC2020). Task 1 is a joint wake-up word detection with speaker verification on close talking data. The whole system consists of a keyword spotting (KWS) sub-system and a speaker verification (SV) sub-system. For the KWS system, we applied a Temporal Depthwise Separable Convolution Residual Network (TDSC-ResNet) to improve the system's performance. For the SV system, we proposed a multi-task learning network, where phonetic branch is trained with the character label of the utterance, and speaker branch is trained with the label of the speaker. Phonetic branch is optimized with connectionist temporal classification (CTC) loss, which is treated as an auxiliary module for speaker branch. Experiments show that our system gets significant improvements compared with baseline system.
Crop Height and Plot Estimation from Unmanned Aerial Vehicles using 3D LiDAR
Oct 30, 2019


In this paper, we present techniques to measure crop heights using a 3D LiDAR mounted on an Unmanned Aerial Vehicle (UAV). Knowing the height of plants is crucial to monitor their overall health and growth cycles, especially for high-throughput plant phenotyping. We present a methodology for extracting plant heights from 3D LiDAR point clouds, specifically focusing on row-crop environments. The key steps in our algorithm are clustering of LiDAR points to semi-automatically detect plots, local ground plane estimation, and height estimation. The plot detection uses a k--means clustering algorithm followed by a voting scheme to find the bounding boxes of individual plots. We conducted a series of experiments in controlled and natural settings. Our algorithm was able to estimate the plant heights in a field with 112 plots within +-5.36%. This is the first such dataset for 3D LiDAR from an airborne robot over a wheat field. The developed code can be found on the GitHub repository located at https://github.com/hsd1121/PointCloudProcessing.
Bottleneck Supervised U-Net for Pixel-wise Liver and Tumor Segmentation
Oct 16, 2018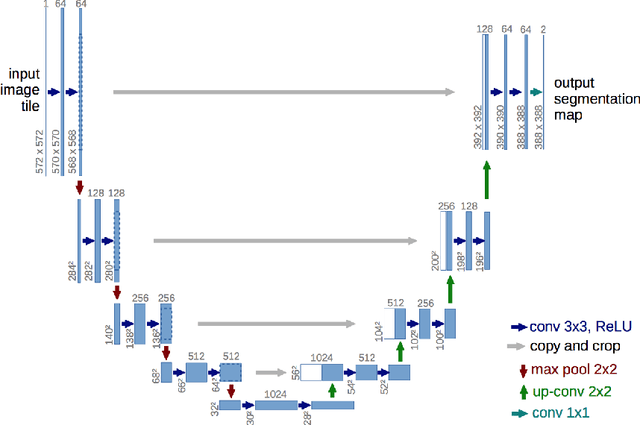
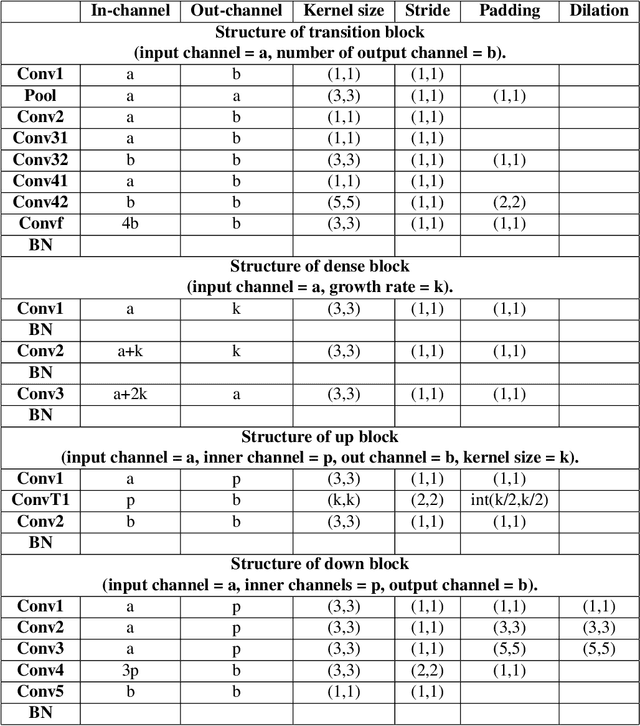
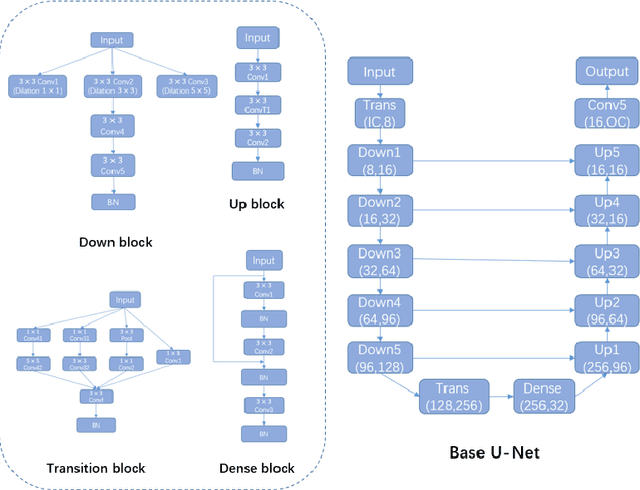
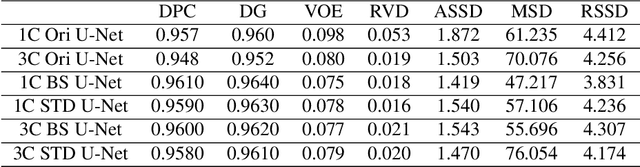
Convolutional neural network (CNN) has been widely used for image processing tasks.In this paper we design a bottleneck supervised U-Net model and apply it to liver and tumor segmentation. Taking an image as input, the model outputs segmented images of the same size, each pixel of which takes value from 1 to K where K is the number of classes to be segmented. The innovations of this paper are two-fold: first we design a novel U-Net structure which include dense block and inception block as the base U-Net; second we design a double U-Net architecture based on the base U-Net and includes an encoding U-Net and a segmentation U-Net. The encoding U-Net is first trained to encode the labels, then the encodings are used to supervise the bottleneck of the segmentation U-Net. While training the segmentation U-Net, a weighted average of dice loss(for the final output) and MSE loss(for the bottleneck) is used as the overall loss function. This approach can help retain the hidden features of input images. The model is applied to a liver tumor 3D CT scan dataset to conduct liver and tumor segmentation sequentially. Experimental results indicate bottleneck supervised U-Net can accomplish segmentation tasks effectively with better performance in controlling shape distortion, reducing false positive and false negative, besides accelerating convergence. Besides, this model has good generalization for further improvement.