 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsicAvatar: Physically Based Inverse Rendering of Dynamic Humans from Monocular Videos via Explicit Ray Tracing
Dec 08, 2023



We present IntrinsicAvatar, a novel approach to recovering the intrinsic properties of clothed human avatars including geometry, albedo, material, and environment lighting from only monocular videos. Recent advancements in human-based neural rendering have enabled high-quality geometry and appearance reconstruction of clothed humans from just monocular videos. However, these methods bake intrinsic properties such as albedo, material, and environment lighting into a single entangled neural representation. On the other hand, only a handful of works tackle the problem of estimating geometry and disentangled appearance properties of clothed humans from monocular videos. They usually achieve limited quality and disentanglement due to approximations of secondary shading effects via learned MLPs. In this work, we propose to model secondary shading effects explicitly via Monte-Carlo ray tracing. We model the rendering process of clothed humans as a volumetric scattering process, and combine ray tracing with body articulation. Our approach can recover high-quality geometry, albedo, material, and lighting properties of clothed humans from a single monocular video, without requiring supervised pre-training using ground truth materials. Furthermore, since we explicitly model the volumetric scattering process and ray tracing, our model naturally generalizes to novel poses, enabling animation of the reconstructed avatar in novel lighting conditions.
ResFields: Residual Neural Fields for Spatiotemporal Signals
Sep 06, 2023



Neural fields, a category of neural networks trained to represent high-frequency signals, have gained significant attention in recent years due to their impressive performance in modeling complex 3D data, especially large neural signed distance (SDFs) or radiance fields (NeRFs) via a single multi-layer perceptron (MLP). However, despite the power and simplicity of representing signals with an MLP, these methods still face challenges when modeling large and complex temporal signals due to the limited capacity of MLPs. In this paper, we propose an effective approach to address this limitation by incorporating temporal residual layers into neural fields, dubbed ResFields, a novel class of networks specifically designed to effectively represent complex temporal signals. We conduct a comprehensive analysis of the properties of ResFields and propose a matrix factorization technique to reduce the number of trainable parameters and enhance generalization capabilities. Importantly, our formulation seamlessly integrates with existing techniques and consistently improves results across various challenging tasks: 2D video approximation, dynamic shape modeling via temporal SDFs, and dynamic NeRF reconstruction. Lastly, we demonstrate the practical utility of ResFields by showcasing its effectiveness in capturing dynamic 3D scenes from sparse sensory inputs of a lightweight capture system.
Synthesizing Diverse Human Motions in 3D Indoor Scenes
May 23, 2023



We present a novel method for populating 3D indoor scenes with virtual humans that can navigate the environment and interact with objects in a realistic manner. Existing approaches rely on high-quality training sequences that capture a diverse range of human motions in 3D scenes. However, such motion data is costly, difficult to obtain and can never cover the full range of plausible human-scene interactions in complex indoor environments. To address these challenges, we propose a reinforcement learning-based approach to learn policy networks that predict latent variables of a powerful generative motion model that is trained on a large-scale motion capture dataset (AMASS). For navigating in a 3D environment, we propose a scene-aware policy training scheme with a novel collision avoidance reward function. Combined with the powerful generative motion model, we can synthesize highly diverse human motions navigating 3D indoor scenes, meanwhile effectively avoiding obstacles. For detailed human-object interactions, we carefully curate interaction-aware reward functions by leveraging a marker-based body representation and the signed distance field (SDF) representation of the 3D scene. With a number of important training design schemes, our method can synthesize realistic and diverse human-object interactions (e.g.,~sitting on a chair and then getting up) even for out-of-distribution test scenarios with different object shapes, orientations, starting body positions, and poses. Experimental results demonstrate that our approach outperforms state-of-the-art human-scene interaction synthesis frameworks in terms of both motion naturalness and diversity. Video results are available on the project page: https://zkf1997.github.io/DIMOS.
GMD: Controllable Human Motion Synthesis via Guided Diffusion Models
May 21, 2023



Denoising diffusion models have shown great promise in human motion synthesis conditioned on natural language descriptions. However, it remains a challenge to integrate spatial constraints, such as pre-defined motion trajectories and obstacles, which is essential for bridging the gap between isolated human motion and its surrounding environment. To address this issue, we propose Guided Motion Diffusion (GMD), a method that incorporates spatial constraints into the motion generation process. Specifically, we propose an effective feature projection scheme that largely enhances the coherency between spatial information and local poses. Together with a new imputation formulation, the generated motion can reliably conform to spatial constraints such as global motion trajectories. Furthermore, given sparse spatial constraints (e.g. sparse keyframes), we introduce a new dense guidance approach that utilizes the denoiser of diffusion models to turn a sparse signal into denser signals, effectively guiding the generation motion to the given constraints. The extensive experiments justify the development of GMD, which achieves a significant improvement over state-of-the-art methods in text-based motion generation while being able to control the synthesized motions with spatial constraints.
Probabilistic Human Mesh Recovery in 3D Scenes from Egocentric Views
Apr 12, 2023



Automatic perception of human behaviors during social interactions is crucial for AR/VR applications, and an essential component is estimation of plausible 3D human pose and shape of our social partners from the egocentric view. One of the biggest challenges of this task is severe body truncation due to close social distances in egocentric scenarios, which brings large pose ambiguities for unseen body parts. To tackle this challenge, we propose a novel scene-conditioned diffusion method to model the body pose distribution. Conditioned on the 3D scene geometry, the diffusion model generates bodies in plausible human-scene interactions, with the sampling guided by a physics-based collision score to further resolve human-scene inter-penetrations. The classifier-free training enables flexible sampling with different conditions and enhanced diversity. A visibility-aware graph convolution model guided by per-joint visibility serves as the diffusion denoiser to incorporate inter-joint dependencies and per-body-part control. Extensive evaluations show that our method generates bodies in plausible interactions with 3D scenes, achieving both superior accuracy for visible joints and diversity for invisible body parts. The code will be available at https://sanweiliti.github.io/egohmr/egohmr.html.
Dynamic Point Fields
Apr 06, 2023Recent years have witnessed significant progress in the field of neural surface reconstruction. While the extensive focus was put on volumetric and implicit approaches, a number of works have shown that explicit graphics primitives such as point clouds can significantly reduce computational complexity, without sacrificing the reconstructed surface quality. However, less emphasis has been put on modeling dynamic surfaces with point primitives. In this work, we present a dynamic point field model that combines the representational benefits of explicit point-based graphics with implicit deformation networks to allow efficient modeling of non-rigid 3D surfaces. Using explicit surface primitives also allows us to easily incorporate well-established constraints such as-isometric-as-possible regularisation. While learning this deformation model is prone to local optima when trained in a fully unsupervised manner, we propose to additionally leverage semantic information such as keypoint dynamics to guide the deformation learning. We demonstrate our model with an example application of creating an expressive animatable human avatar from a collection of 3D scans. Here, previous methods mostly rely on variants of the linear blend skinning paradigm, which fundamentally limits the expressivity of such models when dealing with complex cloth appearances such as long skirts. We show the advantages of our dynamic point field framework in terms of its representational power, learning efficiency, and robustness to out-of-distribution novel poses.
Factor Fields: A Unified Framework for Neural Fields and Beyond
Feb 02, 2023



We present Factor Fields, a novel framework for modeling and representing signals. Factor Fields decomposes a signal into a product of factors, each of which is represented by a neural or regular field representation operating on a coordinate transformed input signal. We show that this decomposition yields a unified framework that generalizes several recent signal representations including NeRF, PlenOxels, EG3D, Instant-NGP, and TensoRF. Moreover, the framework allows for the creation of powerful new signal representations, such as the Coefficient-Basis Factorization (CoBaFa) which we propose in this paper. As evidenced by our experiments, CoBaFa leads to improvements over previous fast reconstruction methods in terms of the three critical goals in neural signal representation: approximation quality, compactness and efficiency. Experimentally, we demonstrate that our representation achieves better image approximation quality on 2D image regression tasks, higher geometric quality when reconstructing 3D signed distance fields and higher compactness for radiance field reconstruction tasks compared to previous fast reconstruction methods. Besides, our CoBaFa representation enables generalization by sharing the basis across signals during training, enabling generalization tasks such as image regression with sparse observations and few-shot radiance field reconstruction.
HARP: Personalized Hand Reconstruction from a Monocular RGB Video
Dec 30, 2022



We present HARP (HAnd Reconstruction and Personalization), a personalized hand avatar creation approach that takes a short monocular RGB video of a human hand as input and reconstructs a faithful hand avatar exhibiting a high-fidelity appearance and geometry. In contrast to the major trend of neural implicit representations, HARP models a hand with a mesh-based parametric hand model, a vertex displacement map, a normal map, and an albedo without any neural components. As validated by our experiments, the explicit nature of our representation enables a truly scalable, robust, and efficient approach to hand avatar creation. HARP is optimized via gradient descent from a short sequence captured by a hand-held mobile phone and can be directly used in AR/VR applications with real-time rendering capability. To enable this, we carefully design and implement a shadow-aware differentiable rendering scheme that is robust to high degree articulations and self-shadowing regularly present in hand motion sequences, as well as challenging lighting conditions. It also generalizes to unseen poses and novel viewpoints, producing photo-realistic renderings of hand animations performing highly-articulated motions. Furthermore, the learned HARP representation can be used for improving 3D hand pose estimation quality in challenging viewpoints. The key advantages of HARP are validated by the in-depth analyses on appearance reconstruction, novel-view and novel pose synthesis, and 3D hand pose refinement. It is an AR/VR-ready personalized hand representation that shows superior fidelity and scalability.
3D Segmentation of Humans in Point Clouds with Synthetic Data
Dec 09, 2022Segmenting humans in 3D indoor scenes has become increasingly important with the rise of human-centered robotics and AR/VR applications. In this direction, we explore the tasks of 3D human semantic-, instance- and multi-human body-part segmentation. Few works have attempted to directly segment humans in point clouds (or depth maps), which is largely due to the lack of training data on humans interacting with 3D scenes. We address this challenge and propose a framework for synthesizing virtual humans in realistic 3D scenes. Synthetic point cloud data is attractive since the domain gap between real and synthetic depth is small compared to images. Our analysis of different training schemes using a combination of synthetic and realistic data shows that synthetic data for pre-training improves performance in a wide variety of segmentation tasks and models. We further propose the first end-to-end model for 3D multi-human body-part segmentation, called Human3D, that performs all the above segmentation tasks in a unified manner. Remarkably, Human3D even outperforms previous task-specific state-of-the-art methods. Finally, we manually annotate humans in test scenes from EgoBody to compare the proposed training schemes and segmentation models.
ARAH: Animatable Volume Rendering of Articulated Human SDFs
Oct 18, 2022
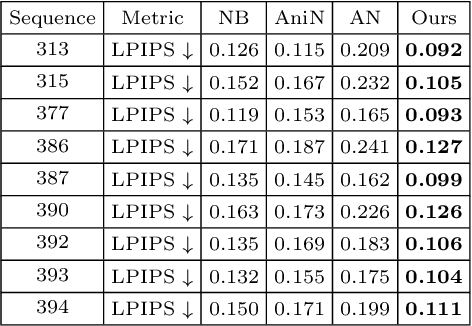
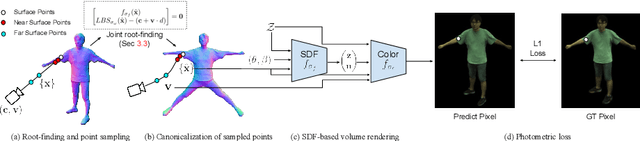
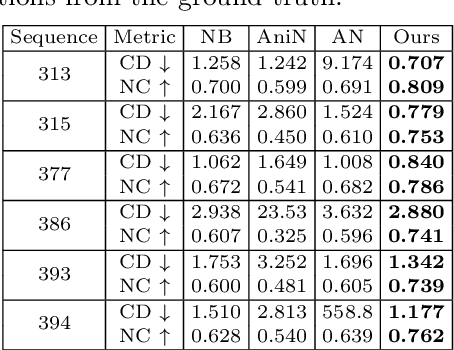
Combining human body models with differentiable rendering has recently enabled animatable avatars of clothed humans from sparse sets of multi-view RGB videos. While state-of-the-art approaches achieve realistic appearance with neural radiance fields (NeRF), the inferred geometry often lacks detail due to missing geometric constraints. Further, animating avatars in out-of-distribution poses is not yet possible because the mapping from observation space to canonical space does not generalize faithfully to unseen poses. In this work, we address these shortcomings and propose a model to create animatable clothed human avatars with detailed geometry that generalize well to out-of-distribution poses. To achieve detailed geometry, we combine an articulated implicit surface representation with volume rendering. For generalization, we propose a novel joint root-finding algorithm for simultaneous ray-surface intersection search and correspondence search. Our algorithm enables efficient point sampling and accurate point canonicalization while generalizing well to unseen poses. We demonstrate that our proposed pipeline can generate clothed avatars with high-quality pose-dependent geometry and appearance from a sparse set of multi-view RGB videos. Our method achieves state-of-the-art performance on geometry and appearance reconstruction while creating animatable avatars that generalize well to out-of-distribution poses beyond the small number of training poses.